






 本文介绍了处理器乱序执行的核心机制,包括Buffer的作用、指令调度、保留站、指令顺序提交和重排缓冲区。通过去耦合和抗波动,乱序执行能提高处理器效率,但引入了精确中断和投机执行错误的问题。顺序提交策略解决了这些问题,确保指令正确提交。高端处理器通常采用这种复杂但高效的机制。
本文介绍了处理器乱序执行的核心机制,包括Buffer的作用、指令调度、保留站、指令顺序提交和重排缓冲区。通过去耦合和抗波动,乱序执行能提高处理器效率,但引入了精确中断和投机执行错误的问题。顺序提交策略解决了这些问题,确保指令正确提交。高端处理器通常采用这种复杂但高效的机制。
1. Buffer的作用——去耦合
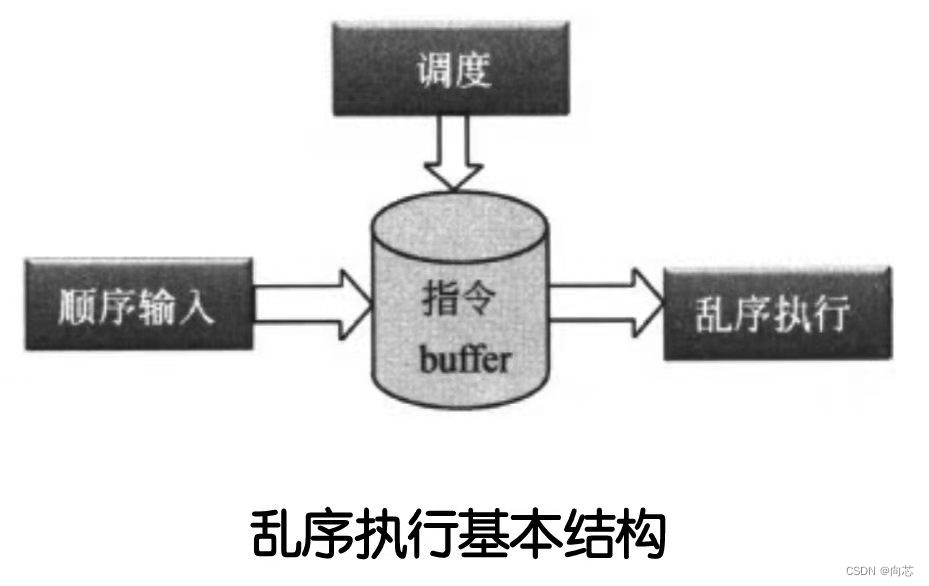
在顺序执行内核中,指令依次流经各个流水线单元,不需要进行缓存,而为了要能乱序执行,首先需要一个Buffer来缓存还没有执行的指令,然后在这个Buffer中去调度指令的执行顺序。乱序执行内核的基本模型如下:
Buffer两大功能:
(1)去耦合
(2)抗波动
2. 指令调度
调度器:
处理器的乱序执行内核需要一个调度器,分析指令间的相关性,分析指令什么时候开始执行。
指令什么时候开始执行:
经过寄存器重命名后,目的寄存器总是新的,因此只需关注原操作数是否准备好即可。所以,指令能否开始执行,依赖于两个条件:
(1)是否有空闲的功能单元去执行这条指令;
(2)该指令的源操作数是否已经准备好。
只有满足这两个要求,指令就可以去执行,而不需要等待前面的指令完成。这样处理器就完成了乱序调度及并行调度。
以经过寄存器重命名的指令为例进行说明:
(1)处理器会记录指令源操作数的准备状态。当指令1完成后,处理器会通知所有依赖F5的指令,F5已经准备好了,指令2需要的两个源操作数F5和F2都已准备好,它就被发送到指令的执行队列中去执行。
(2)如果指令3也可以准备执行,若处理器中有多个加法单元,指令2和指令3就可以同时执行。
(3)在这个调度的例子中,5条指令4个Cycle就可以完成,而使用顺序内核,则需要5个Cycle。

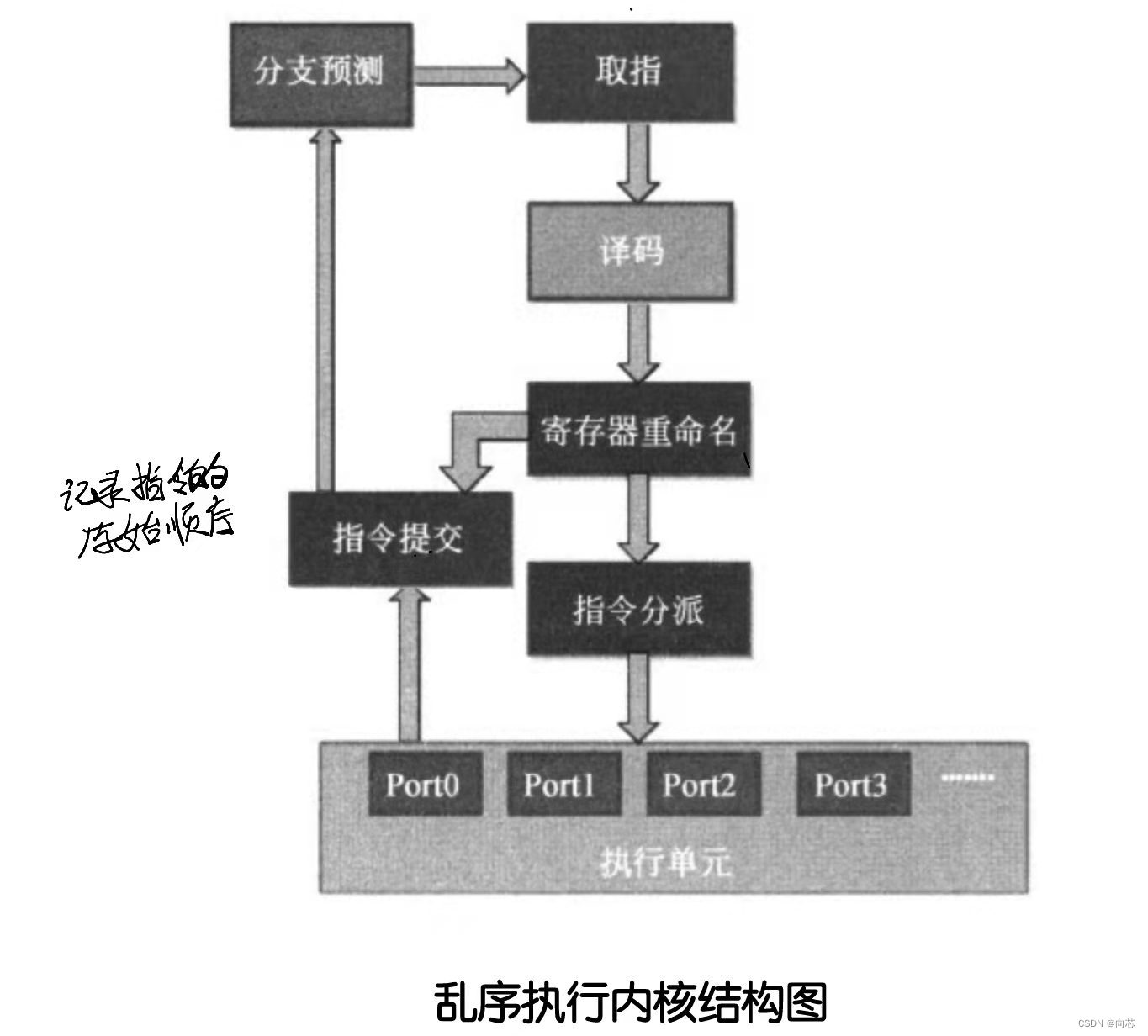
保留站(Reservation Station)
处理器内部需要一个Buffer来缓存指令,以供乱序调度,这个Buffer就是保留站(Reservation Station),完成寄存器重命名后的指令被放置在保留站中,等到操作数和功能单元都准备好时,保留站中的指令就被分派出去执行。
2. 指令的顺序提交
背景:
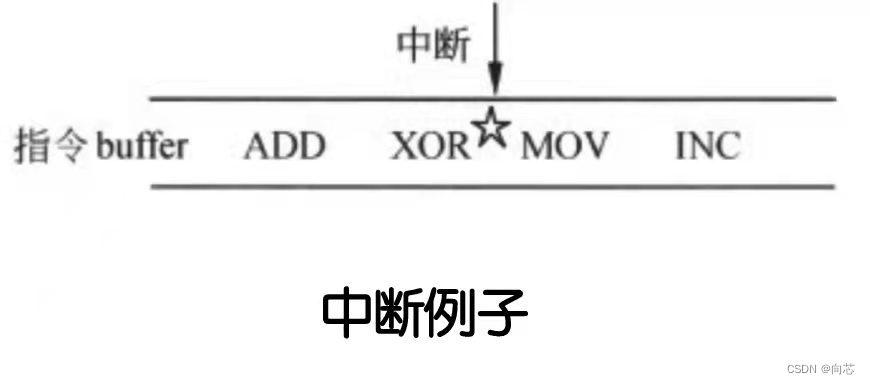
在指令的执行过程中,通常会有中断和异常产生,如在下面的这个例子中:
XOR指令执行后,来了一个中断,中断处理一般都是将处理器的ISA寄存器压栈,执行中断服务程序,然后再退回来执行后面的指令。
问题:
精确中断要求中断前的指令都执行,中断后的指令都没有执行,而在乱序执行内核中,MOV、INC指令有可能提前到XOR前面执行,那么怎么来实现精确中断呢?
解决方案:
在指令乱序执行之后,再加一个步骤:指令顺序提交。乱序执行后,指令的结果虽然出来了,但是这个结果并没有立即提交到ISA寄存器中,而且先缓存起来,只有当前指令前面的指令提交后,这条指令才能提交。
指令的顺序提交也能解决投机执行出错的问题,如下图所示
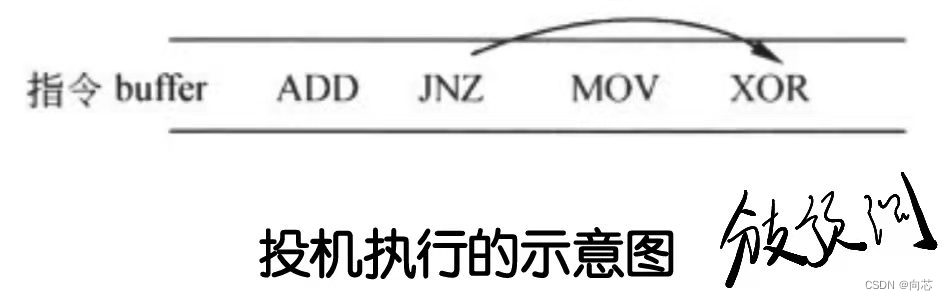
分支预测单元预测到JNZ跳转到XOR处执行,乱序执行让XOR指令在ADD前面执行,不过天有不测风云,处理器执行到JNZ时,发现分支预测单元预测错了,实际上应该执行的是MOV这个分支,使用顺序提交策略,JNZ后面指令的结果都没有提交,可以直接抛弃,重新开始执行MOV这条路径即可。
重排缓冲区(Reoder Buffer,简称ROB)
为了实现指令的顺序提交,处理器内部使用了一个Buffer,叫做重排缓冲区。每条完成寄存器重命名的指令都要送到ROB中,ROB中的指令按照初始顺序存放,指令经乱序执行后,只是修改了处理器内部的物理寄存器,并没有修改处理器的ISA(汇编指令能看到的寄存器),指令在提交时,按照ROB中的顺序,顺序地修改处理器的ISA寄存器。
4. 乱序执行总结
指令乱序执行步骤:
顺序发射 → 乱序执行 → 顺序提交
其他说明:
乱序执行比顺序执行需要耗费更多处理器资源,通常只有高端处理器才会使用。


















 65
65

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











