






在寒假里,我开始接触到了深度学习,对深度学习里面涉及到的知识点很感兴趣,也希望能在未来的研究生生活中确立为自己的研究方向。
为此,我利用假期时间自学了python的基本操作,并学习了:
一.基本的回归任务
我认为回归任务的重点应该在数据的处理上,不同的数据集有不同的处理方式,
1.(你用什么方式处理的?你是如何挑选需要的特征的?)
当我在做新冠人数预测的数据集时:
1.发现有地区相关的参数值可以使用one-hot的处理方式,
2.对于时间的处理可以将日期格式表示为观测的第几天或者第几个月,
3.而部分参数值如[人数基数]的参数值较大,会对loss产生较大的影响,因此可以采用归一化,
4.当参数值过高时也可以采用selectbest函数
【原理:通过给特征进行打分,然后从高到底选取特征,要用到皮尔森系数和单变量线性回归,皮尔森系数可以表明y与各个特征的相关度单变量线性回归可以用来表明特征的回归效果】
而在训练中为了提高训练效果,我也尝试了不同的训练技巧,得到了不同的结果。
2.(你加入了什么训练技巧,他们的原理是什么)
神经网络固有的两个缺点即费时和容易过拟合,而通常解决过拟合的方式就是用多个模型(即增大数据量)去训练,但是会特别费时,Dropout和L1与L2的正则化的出现很好的可以解决这个问题。
I.DROPOUT
开篇明义,dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
每次做完dropout,相当于从原始的网络中找到一个更瘦的网络。没有添加Dropout的网络是需要对网络的每一个节点进行学习的,而添加了Dropout之后的网络层只需要对该层中没有被Mask掉的节点进行训练,其目的是为了解决过拟合问题
(为什么能解决过拟合问题?)
【Dropout的意思是:每次训练时随机忽略一部分神经元,这些神经元dropped-out了。换句话讲,这些神经元在正向传播时对下游的启动影响被忽略,反向传播时也不会更新权重。通过dropout使网络对某个神经元的权重变化更不敏感,增加泛化能力,减少过拟合。从根本上让神经网络没机会过度依赖】
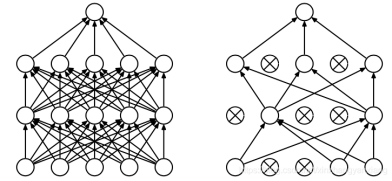
由于dropout让每个神经元有概率消失,因此模型无法给予某个神经元过高的权值,从而降低了依赖度,解决了过拟合
II.L1 L2 正则化
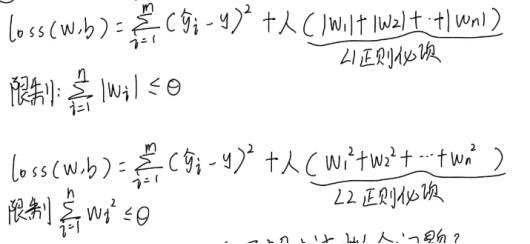
由于出现了正则化项对于loss的影响,从而使权值w被动变小
1.(为什么能解决过拟合问题?)
加入了L1正则化和L2正则化后,模型更换了新的损失计算方式,在每次梯度回传的过程中,都会降低w的取值范围,实现了参数的稀疏,从而降低了模型的复杂度,从而解决了过拟合问题。
1)实现参数的稀疏有什么好处吗?
一个好处是可以简化模型,避免过拟合。因为一个模型中真正重要的参数可能并不多,如果考虑所有的参数起作用,那么可以对训练数据可以预测的很好,但是对测试数据表现性能极差。另一个好处是参数变少可以使整个模型获得更好的可解释性。
2)参数值越小代表模型越简单吗?
越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括一些异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反映了在这个区间里的导数很大,而只有较大的参数值才能产生较大的导数。因此复杂的模型,其参数值会比较大。
2.(为什么只限制w,不限制b?)
w会影响波动的范围,而b只能影响曲线高度
3.(L1和L2正则化的区别)
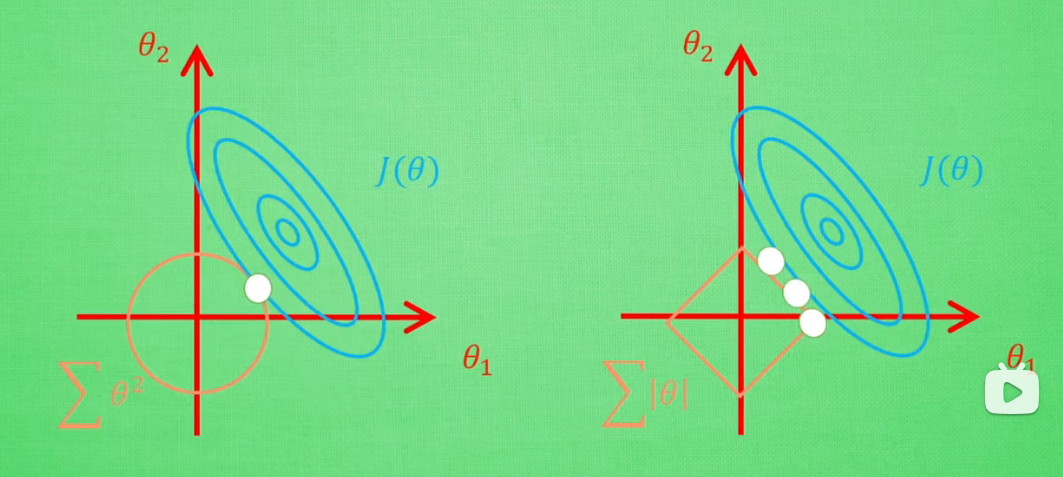
假设α=1,则L1为正方形,L2为圆形
如图,在正则项范围内有交叉点,使loss在可控范围内,找到在满足α的前提下loss的最低点,实现了参数的稀释,避免了过拟合
二.分类任务
我利用寒假期间,在一个分类的数据集上尝试了不同的模型。
(谈谈对不同模型的理解)
I.AlexNet模型
1.ReLU激活函数的引入
采用修正线性单元(ReLU)的深度卷积神经网络训练时间更短。而时间开销是进行模型训练过程中很重要的考量因素之一。同时,ReLU有效防止了过拟合现象的出现。
2.层叠池化操作
以往池化的大小PoolingSize与步长stride一般是相等的,例如:图像大小为256*256,PoolingSize=2×2,stride=2,这样可以使图像或是FeatureMap大小缩小一倍变为128,此时池化过程没有发生层叠。但是AlexNet采用了层叠池化操作,即PoolingSize > stride。这种操作非常像卷积操作,可以使相邻像素间产生信息交互和保留必要的联系。论文中也证明,此操作可以有效防止过拟合的发生。
3.Dropout操作
Dropout操作会将概率小于0.5的每个隐层神经元的输出设为0,即去掉了一些神经节点,达到防止过拟合。那些“失活的”神经元不再进行前向传播并且不参与反向传播。这个技术减少了复杂的神经元之间的相互影响。在论文中,也验证了此方法的有效性。
4.网络层数的增加
与原始的LeNet相比,AlexNet网络结构更深,LeNet为5层,AlexNet为8层。在随后的神经网络发展过程中,AlexNet逐渐让研究人员认识到网络深度对性能的巨大影响。当然,这种思考的重要节点出现在VGG网络,但是很显然从AlexNet为起点就已经开始了这项工作。
II.VGG模型
通过堆叠多个 3*3 的卷积核来代替大尺度卷积核(减少所需的参数)
可以通过堆叠两个 3*3 的卷积核来代替 5*5 的卷积核;堆叠三个 3*3 的卷积核来代替 7*7 的卷积核。虽然用了小的卷积核来替换大的卷积核,但并不会影响感受野,即感受野是相同的。
III.ResNet模型
1.提出了 residual 模块
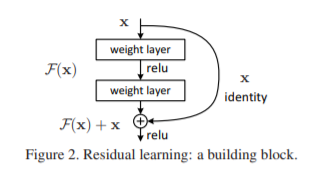
核心思想
论文发现神经网络并不是层数越深越好,在进行一些较浅层的东西时精度较高,那么不应该在深层时精度降低,但是实验发现随着层数越深,能提取到的特征越模糊,精度越低,因此提出了Residual learning.
Residual learning核心思想为利用输入值x与输出的预测值相加(预测值经过了正常的卷积和rule规划)为真正的输出值,降低了每层的损失,同时并没有增加过大的计算量,反而越深越精准,那么如果我的输出维度和输入维度不一样呢?
有两种解决方法:
进行空白无意义的填充
进行1 * 1 卷积,在不改变空间维度的前提下改变通道维度
(1*1卷积为什么可行)
在一个相对特征数量较少的对象上,特征较为稀疏,既然是稀疏的那么就可以进行压缩,所造成的损失也会更低。
2.使用 Batch Normalization (BN) 加速训练(丢弃了之前学的几个网络结构使用的 Dropout)
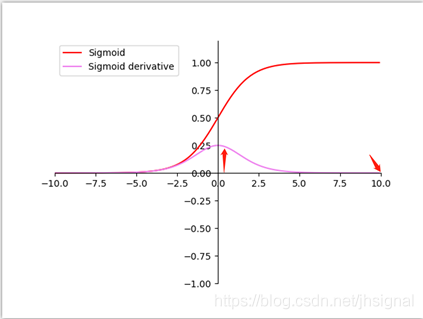
我们在图像预处理过程中通常会对图像进行标准化处理,也就是image normalization,使得每张输入图片的数据分布能够统均值为u,方差为h的分布。这样能够加速网络的收敛。但是当一张图片输入到神经网络经过卷积计算之后,这个分布就不会满足刚才经过image normalization操作之后的分布了,可能适应了新的数据分布规律,这个时候将数据接入激活函数中,很可能一些新的数据会落入激活函数的饱和区,导致神经网络训练的梯度消失,如下图所示当feature map的数据为10的时候,就会落入饱和区,影响网络的训练效果。这个时候我们引入Batch Normalization的目的就是使我们卷积以后的feature map满足均值为0,方差为1的分布规律。在接入激活函数就不会发生这样的情况。
3.超深的网络结构(突破了1000层)
1.Residual learning解决了深层精度不够的问题,经过实验验证,反而深度更高,精度越高。
2.1*1的卷积为不断调整维度不同的问题提供了解决方法。
三.自然语言处理
(我对自然语言处理很感兴趣, 我将来想做这个方向。
所以提前学习了self-attention并且使用Bert处理了情感分类任务。)
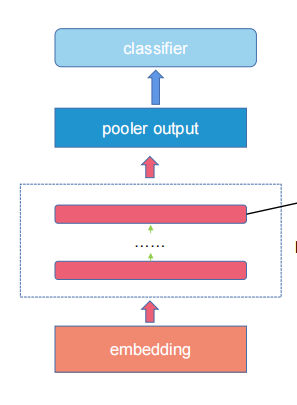
Bert的总体结构














 1261
1261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









