








文章目录
原文链接
Abstract
本文研究了掩码自编码器(MAE)在概念上的简单扩展到基于视频的时空表征学习。
我们发现我们的MAE方法可以在几乎没有时空归纳偏差的情况下学习强表示(除了补丁和位置嵌入),并且时空不可知的随机掩蔽表现最好
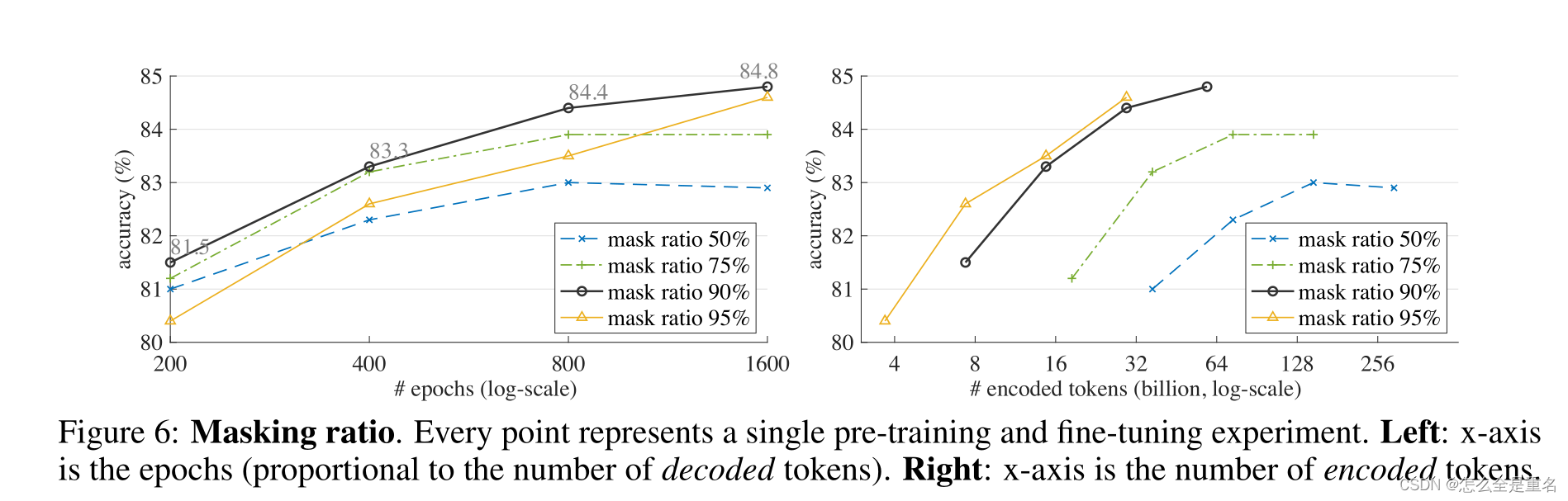
我们观察到最优掩蔽比高达90%(图像上为75%)
我们观察到MAE可以在很大程度上优于监督预训练
Introduction
为了统一方法论,针对特定问题引入更少的领域知识(“更少的归纳偏差”),这促使模型几乎只从数据中学习有用的知识。
MAE预训练极大地提高了泛化性能
在Kinetics-400数据集上,比从零开始提高了ViT-Large 13%的精度,并且它需要训练的时间更少
自然图像的信息冗余度比语言图像高,因此最优掩蔽比更高
我们的MAE预训练可以大大优于有监督的预训练
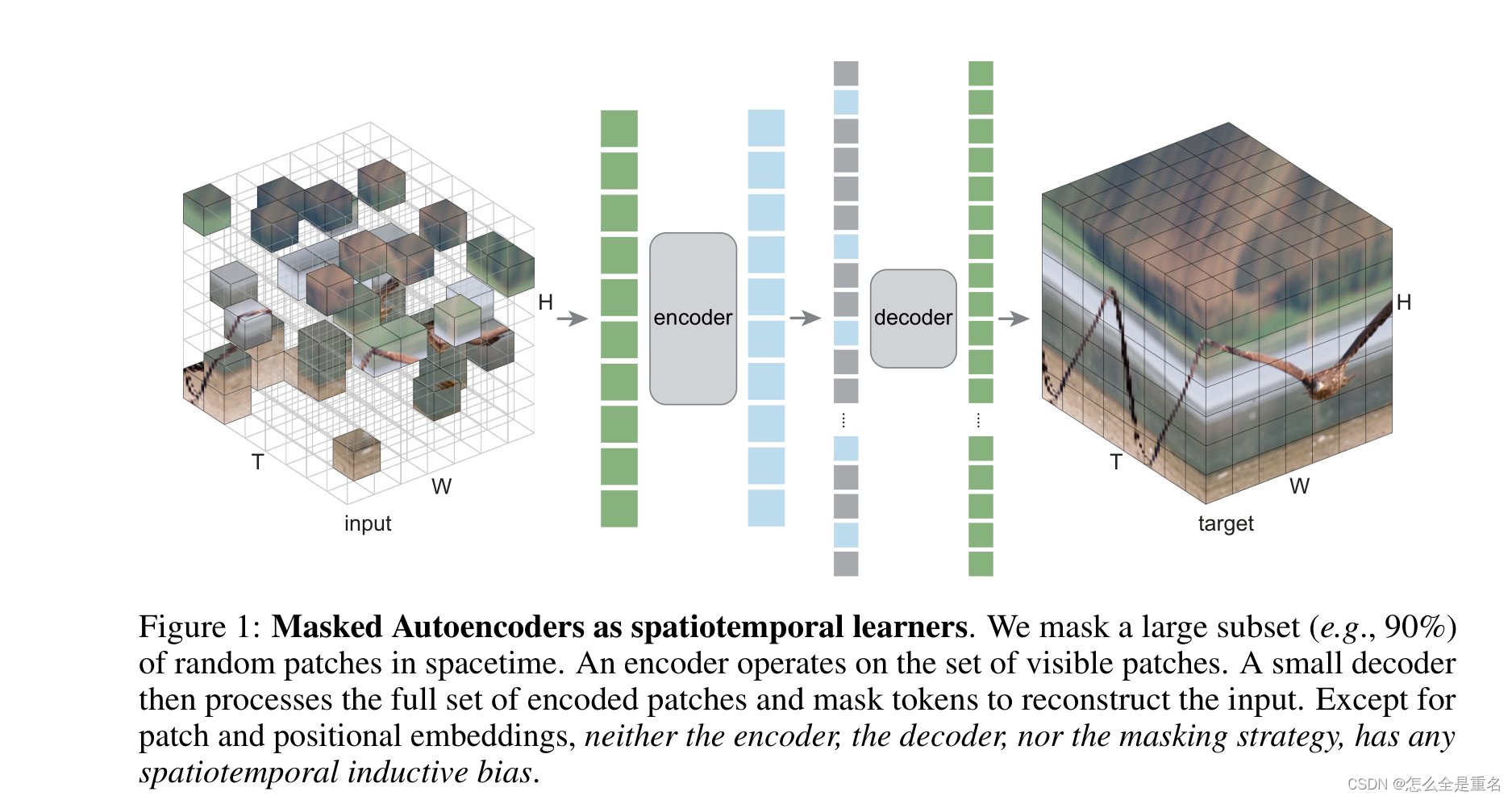
Related Work
经验表明,高掩蔽比对图像任务至关重要

- original video (top)
- masked video (middle)
- MAE output (bottom)

a:与时空无关的随机抽样
b:仅空间随机抽样,广播到所有时间步长
c:仅时间随机抽样,广播到所有空间位置
d:基于快的采样
我们的自动编码方法在像素上操作,它更简单,并且不需要额外的数据或标记器上的领域知识。
重要的是,我们的方法大大提高了学习的效率。
实际的加速对于视频相关的研究至关重要,因为视频相关的研究通常规模更大,更耗时。
Method
我们的方法是将MAE简单地扩展到时空数据
我们的目标是在一个通用和统一的框架下开发该方法,并尽可能少地使用领域知识
Patch embedding
根据原始ViT,将视频片段在时空上划分为一个不重叠的带补丁的规则网格,再经过linear projection和位置嵌入,patch和posttional embeding是唯一具有时空感知的过程
Masking
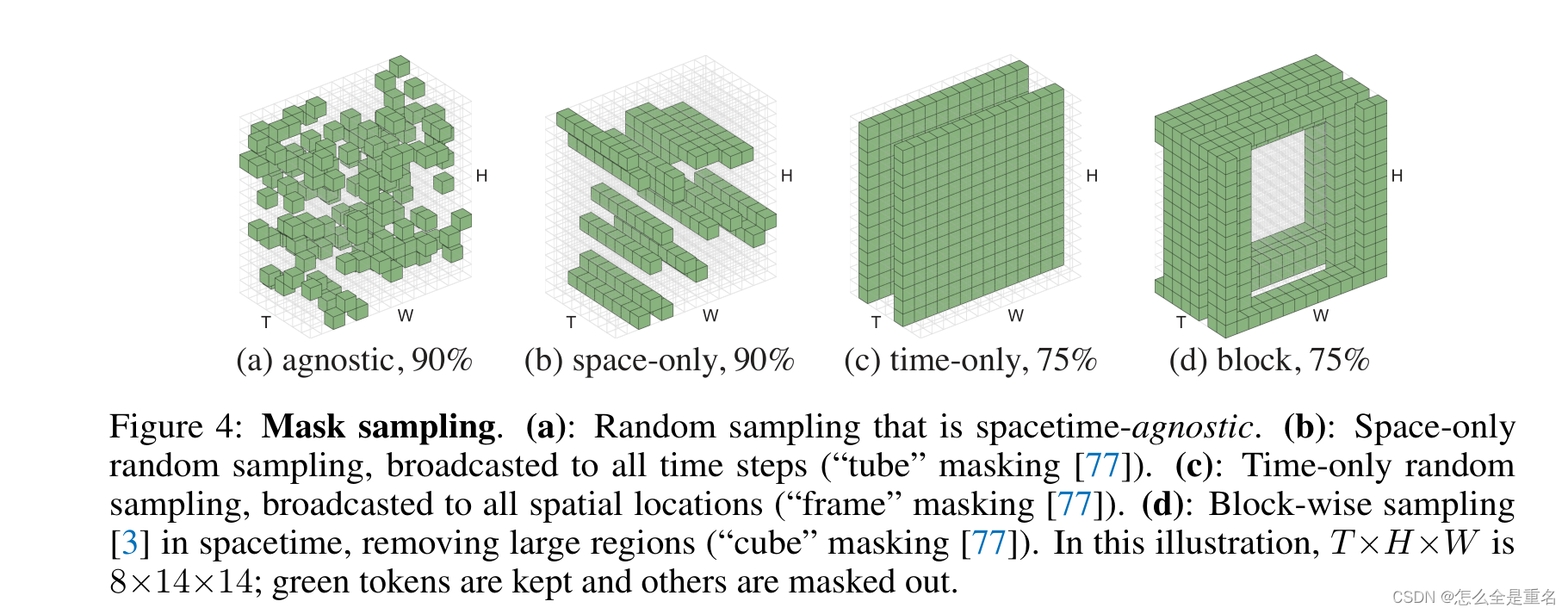
最佳掩蔽比与数据的信息冗余度有关
我们观察到的最佳掩蔽比为90%。
Autoencoding
• encoder采用vanilla ViT,decoder采用比encoder小的vanilla ViT,大约1/20
• 原则上可以简单地预测一个完整的时空patch(t×16×16),但我们发现预测patch的单个时间片(16×16)就足够了,这使预测层的大小保持可控;
• 训练损失函数是预测与其目标之间的均方误差(MSE),在未知patch上取平均值
Implementation
Data pre-processing
我们的默认输入大小是16帧,每帧224×224像素(即16×224×224),从原始视频中采样16帧,采样时间步长为4,随机采样起始帧。
我们的MAE预训练计算速度非常快,数据加载成为我们设置中支配运行时间的新瓶颈
Architecture
encoder and decoder都是采用vanilla ViT结构,且encoder采用可分离位置embedding
Settings
我们使用AdamW优化器批大小为512,通过端到端微调来评估预训练质量
Experiments
Performance
MAE预训练加上微调比从头开始训练更准确、更快
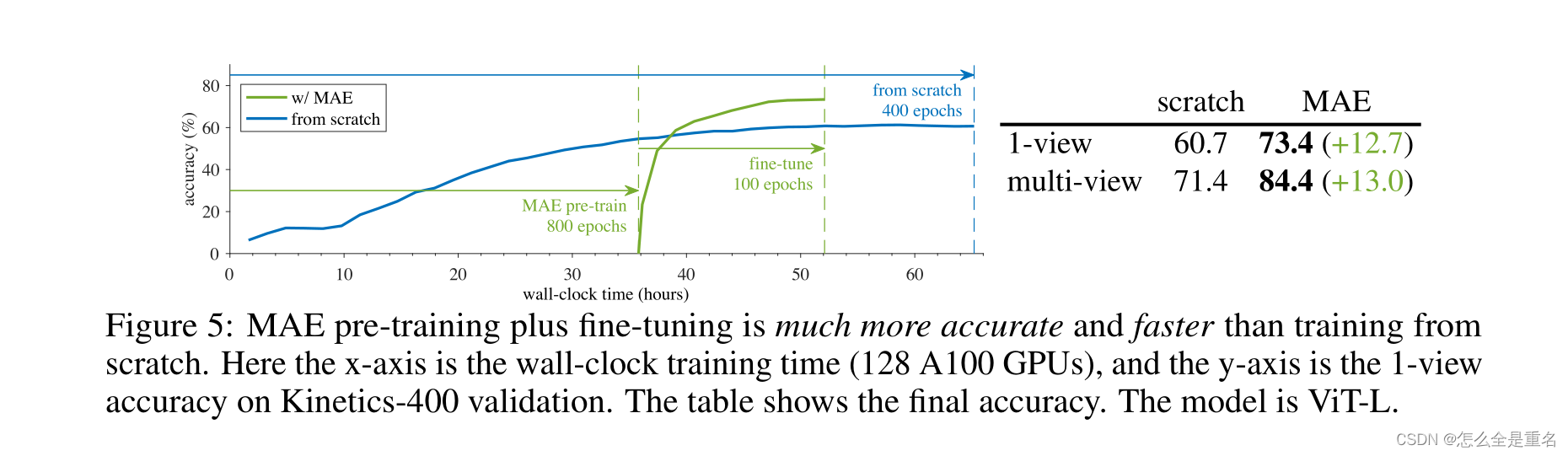
MAE预训练速度快,因为它的编码器只应用在可见patch的稀疏集上,没有mask token

Ablation experiments
90%的ratio效果最好,如果训练时间够长95%的ratio表现会出奇的好

Mask sampling:与时空无关的采样效果最好
Reconstruction target:使用per-patch归一化的pixel作为重建目标最好
Data augmentation:空间增强是没必要的
Repeated sampling:采用4倍的Repeated sampling表现最佳
Decoder width/depth:在dim 512 和4 block时表现最佳
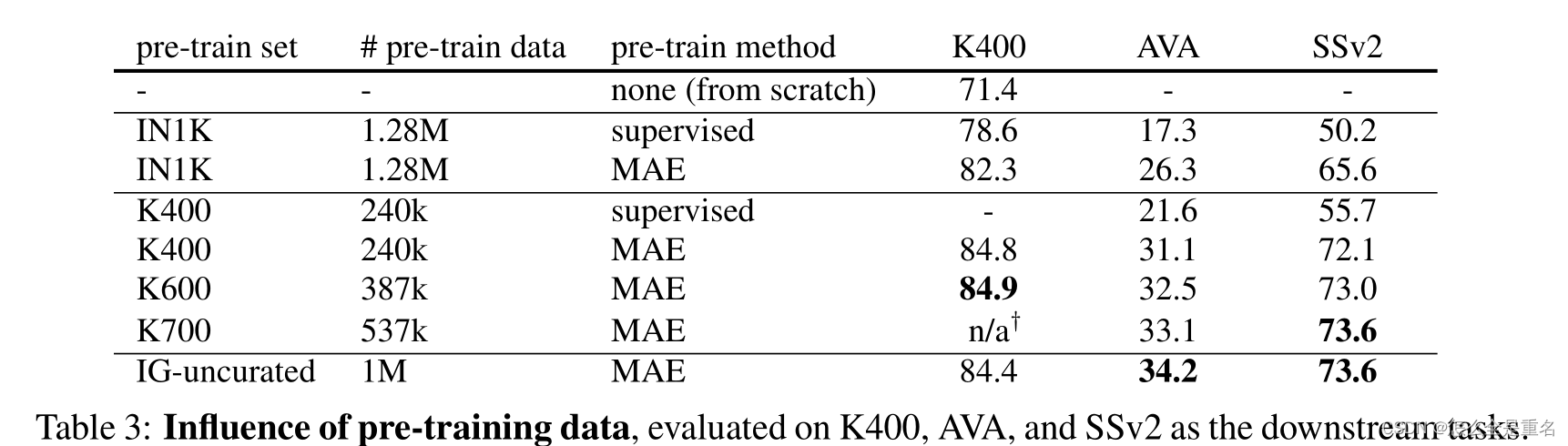
Influence of Data
Transfer learning ablation
在视频上进行MAE预训练对这些视频任务非常有益
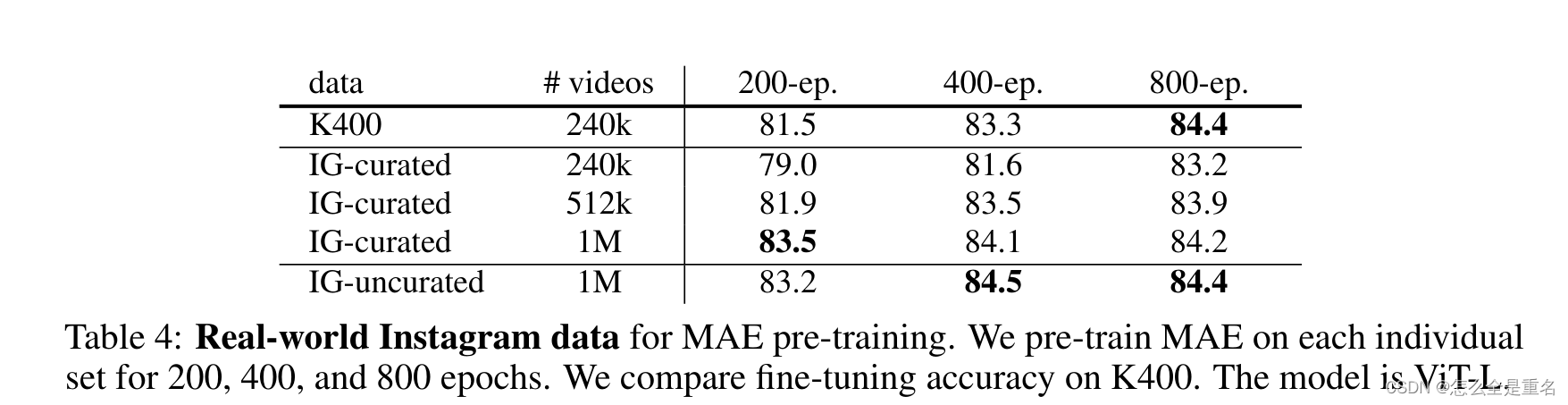
Real-world data
随着数据集的增大,IG-curated表现优于K400预训练
Conclusion
(i)我们发现用最小的领域知识或归纳偏差学习强表示是可能的
(ii) masking ratio是一般掩蔽自编码方法的一个重要因素,其最优值可能取决于数据的性质(语言、图片、视频等)
(iii)我们报告了对真实世界、未经整理的数据进行预训练的令人鼓舞的结果
仍存在的问题:
我们所探索的数据规模比对应的语言要小几个数量级,虽然我们的方法在很大程度上提高了自监督学习的效率,但高维视频数据仍然是扩展的主要挑战














 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









