






起薪4万的AI产品经理,ChatGPT底层实现原理怎么能不懂?
1、Transformer
Transformer模型在普通的编码器—解码器结构基础上做了升级,它的编码端是由多个编码器串联构成的,而解码端同样由多个解码器构成,如下图所示:
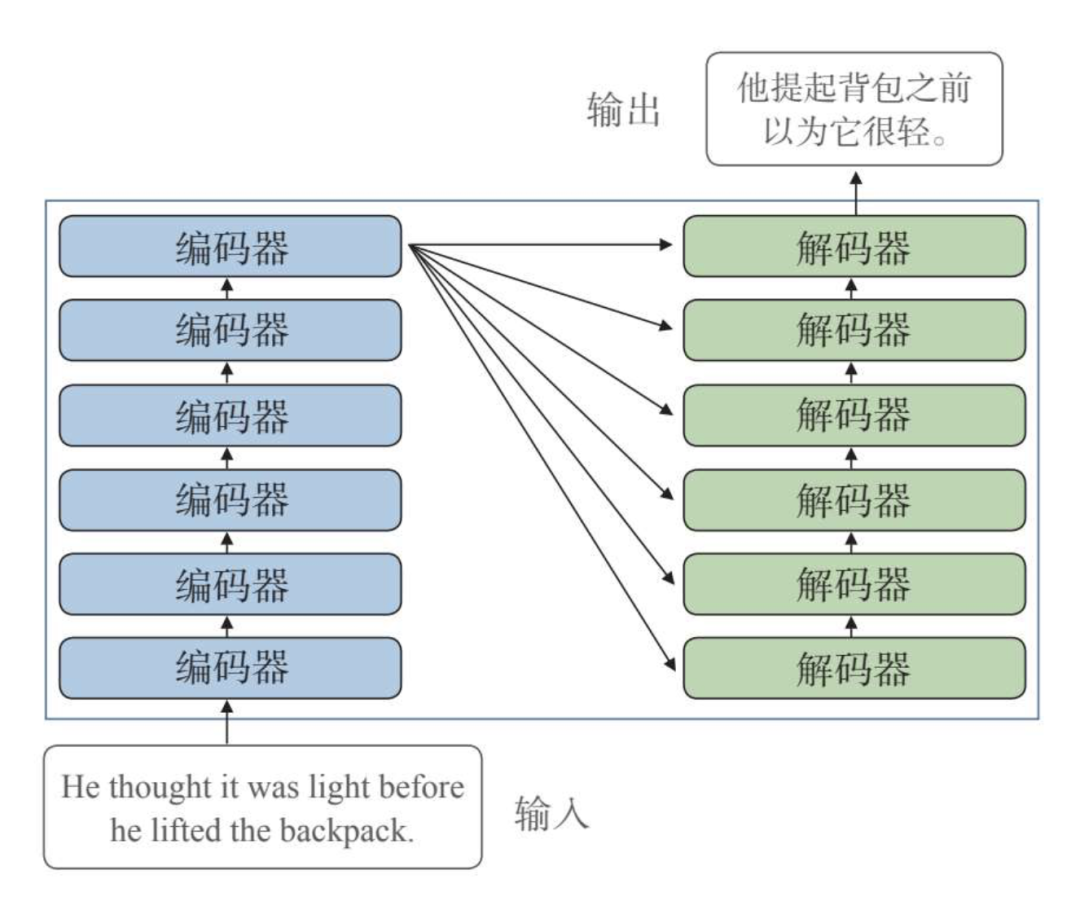
它同时也在输入编码和自注意力方面做了优化,例如采用多头注意力机制、引入位置编码机制等等,能够识别更复杂的语言情况,从而能够处理更为复杂的任务。
首先看编码器部分。Transformer模型的每个编码器有两个主要部分:自注意力机制和前馈神经网络。
自注意力机制通过计算前一个编码器的输入编码之间的相关性权重,来输出新的编码。之后前馈神经网络对每个新的编码进行进一步处理,然后将这些处理后的编码作为下一个编码器或解码器的输入。
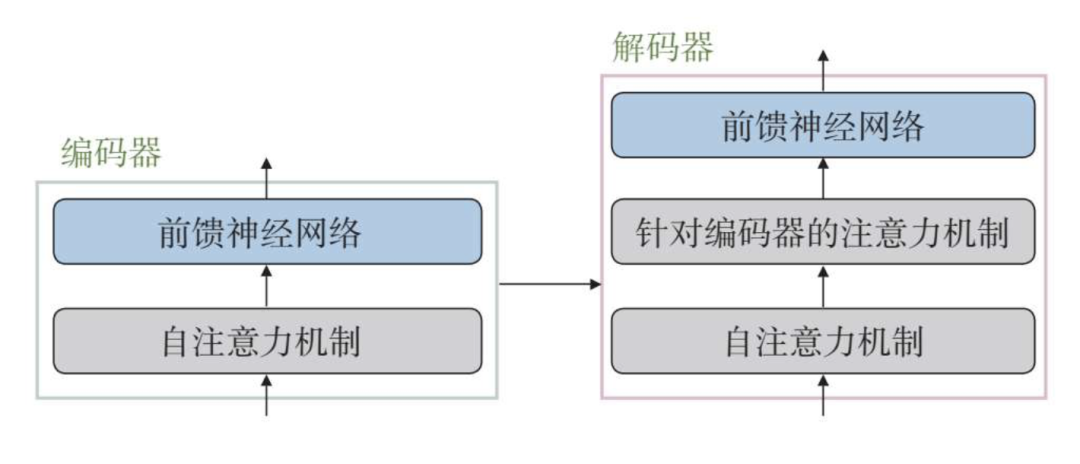
之后是解码器部分。解码器部分也由多个解码器组成,每个解码器有三个主要部分:自注意力机制、针对编码器的注意力机制和前馈神经网络。
可以看到,解码器和编码器类似,但多了一个针对编码器的注意力机制,它从最后一个编码器生成的编码中获取相关信息。
最后一个解码器之后一般对接最终的线性变换和归一化层,用于生成最后的序列结果。
注意力方面,Transformer采用的是多头注意力。
简单点说,不同标记相互之间的注意力通过多个注意力头来实现,而多个注意力头针对标记之间的相关性来计算注意力权重,如下图所示:
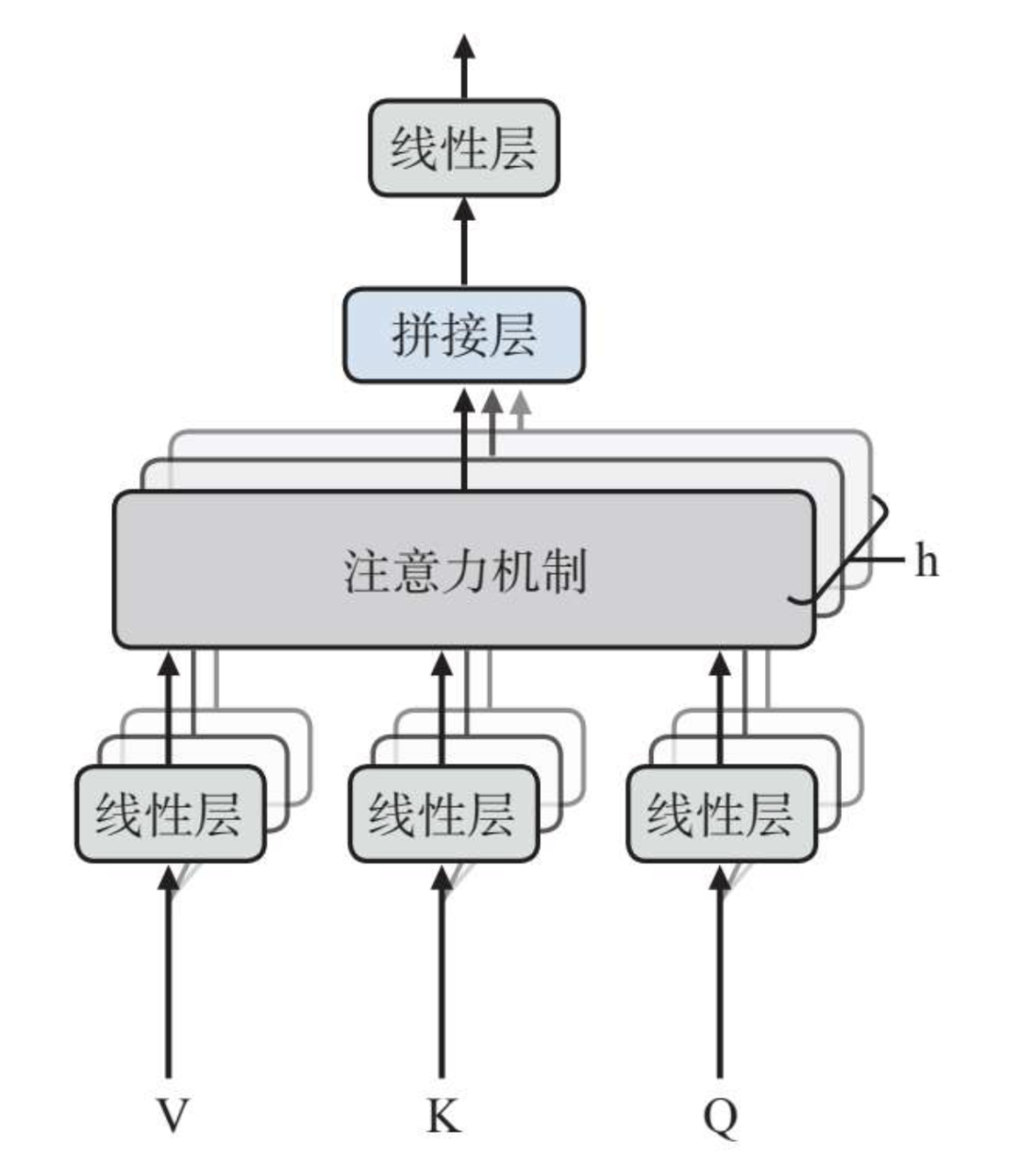
如在一个句子中,某个注意力头主要关注上一个单词和下一个单词的关系,而另一个注意力头就会把关注点放在句子中动词和其对应宾语的关系上。
而在实际操作中,这些注意力头的计算都是同步进行的,这样整体反应速度就会加快。这些注意力头的计算完成以后会被拼接在一起,由最终的前馈神经网络层进行处理后输出。
为了便于理解,我们来看这样一个例子:“The monkey ate the banana quickly and it looks hungry.”(猴子快速地吃了香蕉,它看起来很饿。)
这句话中的“it”指的是什么?是“banana”还是“monkey”?这对人类来说是一个简单的问题,但对模型来说却没有那么简单,即便使用了自注意力机制,也无法避免误差,但是引入多头注意力机制就能很好地解决这个问题。
在多头注意力机制中,其中一个编码器对单词“it”进行编码时,可能更专注于“monkey”,而另一个编码器的结果可能认为“it”和“banana”之间的关联性更强,这种情况下模型最后输出的结果较大可能会出现偏差。
这时候多头注意力机制就发挥了作用,有其他更多编码器注意到“hungry”,通过多个编码结果的加权组合,最终单词“hungry”的出现将导致“it”与“monkey”之间产生更大的关联性,也就最大限度上消除了语义理解上的偏差。
位置编码机制也是Transformer特有的。
在输入的时候,加上位置编码的作用在于计算时不但要知道注意力聚焦在哪个单词上面,还需要知道单词之间的相对位置关系。
例如:“She bought a book and a pen.”(她买了书和笔。)这句话中的两个“a”修饰的是什么?是“book”还是“pen”?
意思是“一本”还是“一支”?这对人类来说也是一个简单的问题,但对模型来说却比较困难,如果只使用自注意力机制,可能会忽略两个“a”和它们后面名词之间的关系,而只关注“a”和其他单词之间的相关性。
引入位置编码就能很好地解决这个问题。通过加入位置编码信息,每个单词都会被加上一个表示它在序列中位置的向量。这样,在计算相关性时,模型不仅能够考虑单词之间的语义相关性,还能够考虑单词之间的位置相关性,也就能够更准确地理解句子中每个单词所指代或修饰的对象。
通过引入多头注意力机制、位置编码等方式,Transformer有了最大限度理解语义并输出相应回答的能力,这也为后续GPT模型这种大规模预训练模型的出现奠定了基础。
2、GPT系列模型
GPT属于典型的“**预训练+微调”**两阶段模型。
一般的神经网络在进行训练时,先对网络中的参数进行随机初始化,再利用算法不断优化模型参数。
而GPT的训练方式是,模型参数不再是随机初始化的,而是使用大量通用数据进行“预训练”,得到一套模型参数;然后用这套参数对模型进行初始化,再利用少量特定领域的数据进行训练,这个过程即为“微调”。
预训练属于迁移学习的一种。
预训练语言模型把自然语言处理带入了一个新的阶段——通过大数据预训练加小数据微调,自然语言处理任务的解决无须再依赖大量的人工调参。
GPT系列的模型结构秉承了不断堆叠Transformer的思想,将Transformer作为特征抽取器,使用超大的训练语料库、超多的模型参数以及超强的计算资源来进行训练,并通过不断提升训练语料的规模和质量,提升网络的参数数量,完成迭代更新。
GPT模型的更新迭代也证明了,通过不断提升模型容量和语料规模,模型的能力是可以不断完善的。
相较于GPT-1,GPT-2不仅增加了训练数据的数量、提高了训练数据的质量,而且能够直接用无监督(即不需标注样本)的方法来做下游任务。
GPT-3则是用“45TB(万亿字节)的训练数据,175B(1750亿个)参数的参数量”这样的数据量把模型规模做到了极致。这也使得GPT-3模型无须或者使用极少量的样本进行微调就能完成特定领域的自然语言处理任务。
并且在很多数据集上直接超过了经过精心调整的微调模型的效果,这样在节省模型训练时间的同时,特定领域中需要大量标注语料的问题也迎刃而解。
ChatGPT是在GPT-3.5模型基础上的微调模型。
在此基础上,ChatGPT采用了全新的训练方式——“从人类反馈中强化学习”。
通过这种方式的训练,模型在语义理解方面展现出了前所未有的智能。如下图所示,ChatGPT的训练分为三个步骤。
第一步,通过人工标注的方式生成微调****模型。
标注团队首先准备一定数量的提示词样本,一部分由标注团队自行准备,另一部分来自OpenAI现有的数据积累。
然后,他们对这些样本进行了标注,其实就是人工对这些提示词输出了对应的答复,从而构成了**“提示词—答复对**”这样的数据集。最后用这些数据集来微调GPT-3.5,得到一个微调模型。
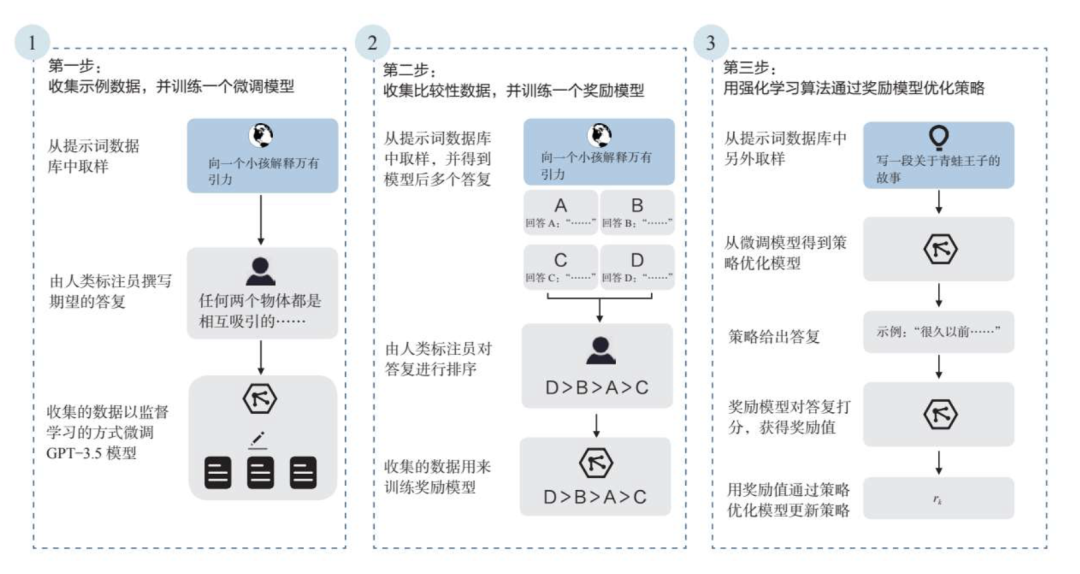
第二步,训练一个可以评价答复满意度的奖励模型。
同样准备一个提示词样本集,让第一步得到的模型来对其进行答复。对于每个提示词,要求模型输出多个答复。
标注团队需要做的工作,就是将每个提示词的答复进行排序,这其中隐含了人类对模型输出效果的预期,以此形成了新的标注数据集,最终用来训练奖励模型。
通过这个奖励模型,可以对模型的答复进行打分,也就为模型的答复提供了评价标准。
第三步,利用第二步训练好的奖励模型,通过强化学习算法来优化答复策略。
这里采用的是一种策略优化模型,它会根据正在采取的行动和收到的奖励不断调整当前策略。
具体来说,首先准备一个提示词样本集,对其中的提示词进行答复,然后利用第二步训练好的奖励模型去对该答复进行打分,根据打分结果调整答复策略。在此过程中,人工已经不再参与,而是利用“AI训练AI”的方式进行策略的更新。最终重复这个过程多次之后,就能得到一个答复质量更好的策略。
就是经过这样一步步的训练,ChatGPT逐渐成形,一经问世,其优秀的自然语言处理能力就获得了全世界的瞩目。
2024年5月OpenAI发布了更为强大的GPT-4o,但ChatGPT在自然语言处理领域依然具有里程碑式的意义。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









