






在过去近两年中,AI发展速度超过任何历史时期,基于大模型的各类应用已经渗透到了各行各业中,很多企业都在积极探索如何利用大模型提高公司运营管理的能效。
阿里云 CTO 周靖人也说过““当下企业应用大模型存在三种范式:一是对大模型开箱即用,二是对大模型进行微调和持续训练,三是基于模型开发应用,其中最典型的需求是RAG”
但是如果以企业私有化角度来说,部署大模型或者RAG等系统,_就大__模型开箱即用这点还远远没有达到,_尤其在多异构GPU调度管理的情况下。一个企业级、私有化LLM服务平台如果能够达到开箱即用的条件,至少具备以下两点:
-
GPU调度和管理: 企业级LLM服务平台应具备支持不同型号和品牌的GPU,能够识别并利用各种GPU的特性,动态分配GPU资源的能力,根据任务的需要和优先级自动分配GPU资源,以优化资源利用率。同时能够监控GPU的使用情况,并在多个GPU之间平衡负载,防止某些GPU过载而其他GPU空闲。
-
多种大模型管理和监控: 支持快速部署 RAG 系统和 AI Agent 系统所需的各种关键模型,能够监控模型的运行性能,包括响应时间、吞吐量等关键指标。并提供统一认证和高可用负载均衡的 OpenAI 兼容 API。
所以,今天介绍的就是这样的一个开源企业级LLM服务平台-GPUStack
01
—
GPUStack 介绍
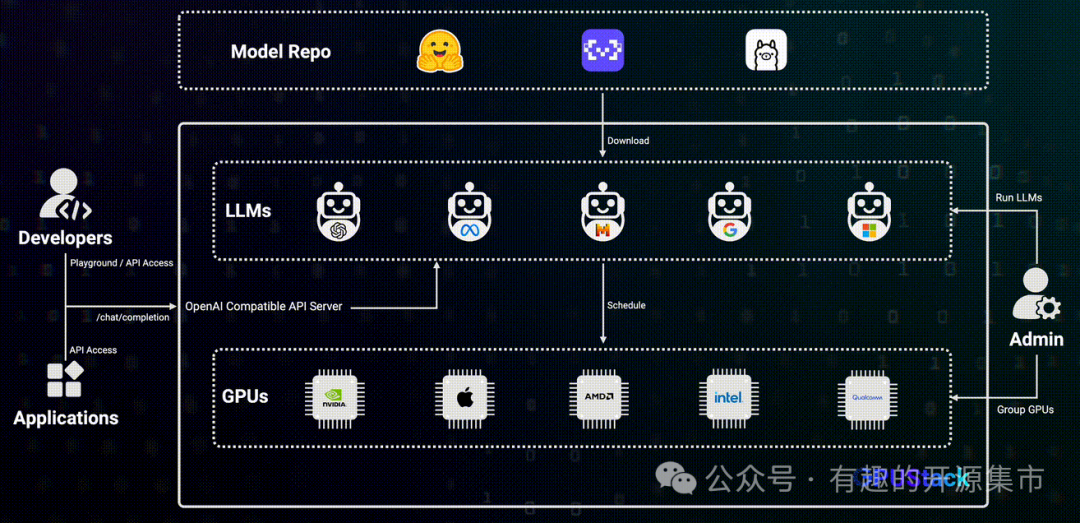
****一个开源的GPU集群管理和自动化部署大模型的LLM服务平台,支持紧凑调度、分散调度、标签调度、指定 GPU 调度等各种调度策略,用户无需手动干预即可自动分配合适的 GPU 资源来自动化运行各种大模型,并兼容OpenAI API。同时支持GPU性能监控以及Token使用和速率指标,帮助用户优化资源使用并提高效率。
重点是采用 Apache-2.0 license****,遵循协议可免费商用!****

🏠 项目信息
#github地址``https://github.com/gpustack/gpustack``#项目地址``https://gpustack.ai/
🚀功能特性
-
异构GPU支持: GPUStack支持异构GPU资源,包括Nvidia、Apple Metal、华为昇腾和摩尔线程等各种类型的GPU/NPU
-
多推理后端支持: 支持vLLM和llama-box (llama.cpp)推理后端,以满足生产性能需求和多平台兼容性
-
多平台支持:GPUStack覆盖Linux、Windows和macOS平台,支持amd64和arm64架构
-
多模型类型支持: 支持LLM文本模型、VLM多模态模型、Embedding文本嵌入模型和Reranker重排序模型等
-
多模型仓库支持: 支持从HuggingFace、Ollama Library、ModelScope和私有模型仓库部署模型
-
丰富的自动/手动调度策略: 支持紧凑调度、分散调度、指定Worker标签调度、指定GPU调度等策略分布式推理:GPUStack支持跨主机的多个GPU上自动运行大模型
-
CPU推理: 支持GPU&CPU混合推理和纯CPU推理两种模式,以便在GPU资源不足时使用CPU运行大模型
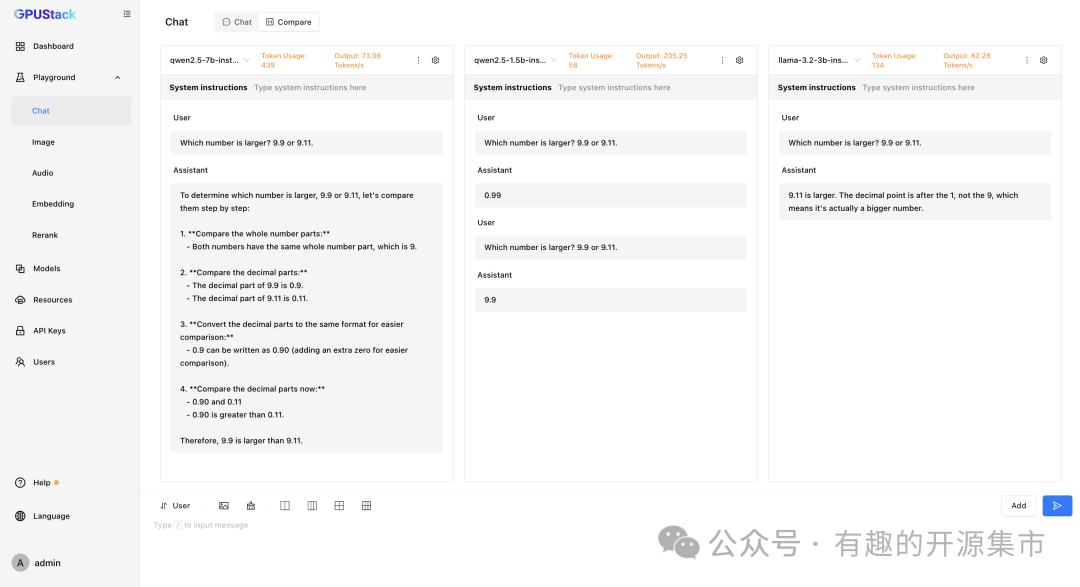
多模型对比: GPUStack的Playground提供了多模型对比视图,可以对比不同模型的问答内容和性能数据
GPU和LLM观测指标: 提供全面的性能、利用率、状态监控和使用数据指标,以评估GPU和LLM的利用情况
-
推理引擎版本管理: 支持为每个模型固定任意推理引擎版本
离线支持: 支持离线安装、离线容器镜像及离线部署本地模型
02
—
GPUStack 安装
需要 Python 3.10 ~ Python 3.12,并提前安装好GPU驱动!
- Linux 或 macOS (使用国内源加速):
curl -sfL https://get.gpustack.ai | INSTALL_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple sh -s - --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
- Windows (使用国内源加速):
$env:INSTALL_INDEX_URL = "https://pypi.tuna.tsinghua.edu.cn/simple"
Invoke-Expression "& { $((Invoke-WebRequest -Uri 'https://get.gpustack.ai' -UseBasicParsing).Content) } -- --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
当看到以下输出时,说明已经成功部署并启动了 GPUStack:
[INFO] Install complete.
GPUStack UI is available at http://localhost.
Default username is 'admin'.
To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'.
CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)
按照脚本的输出指引,拿到登录 GPUStack 的初始密码。
- 在 Linux 或 macOS 上执行:
cat /var/lib/gpustack/initial_admin_password
- 在 Windows 上执行:
Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustack\initial_admin_password") -Raw
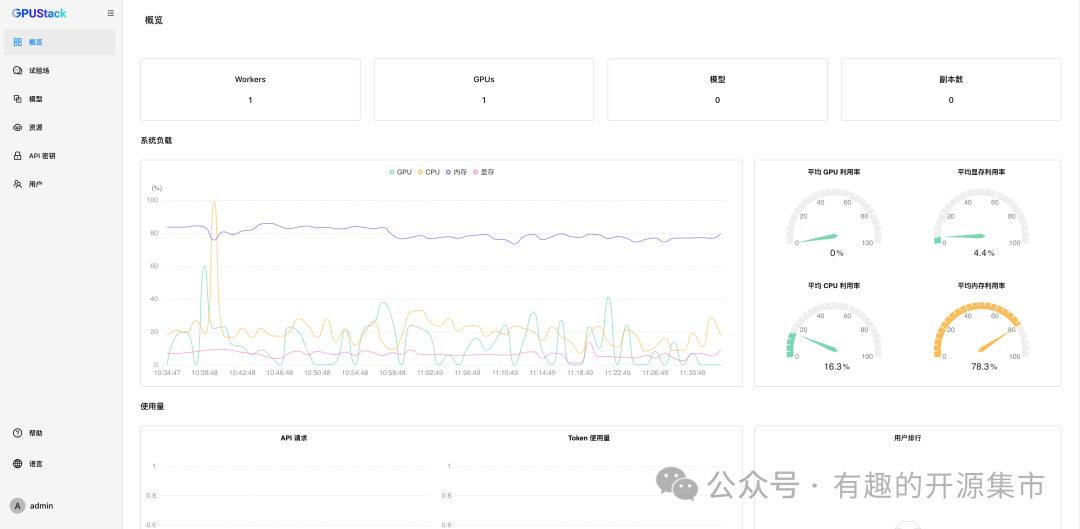
在浏览器访问 GPUStack UI,用户名 admin,密码为上面获得的初始密码。重新设置密码后,进入 GPUStack:
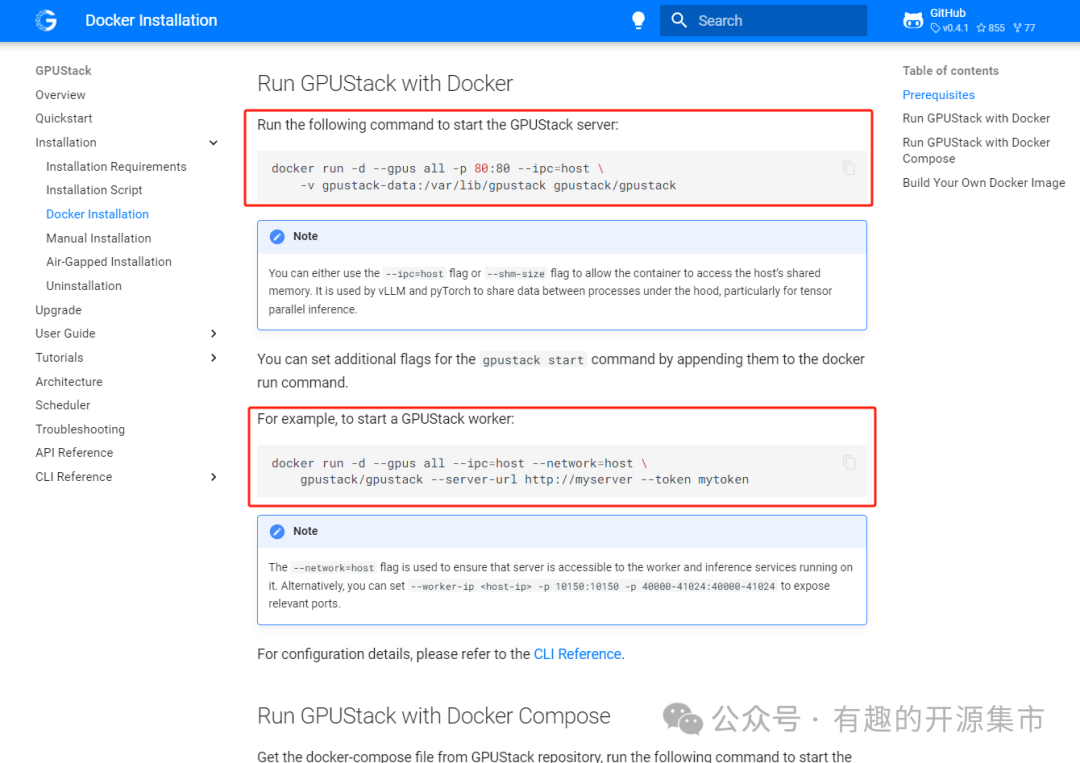
当然,如果喜欢Docker部署的同学,官方也提供了详细的Docker部署说明文档:
#docker部署说明``https://docs.gpustack.ai/latest/installation/docker-installation/
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

03
—
纳管异构 GPU 资源
GPUStack 可以调度管理多台设备的 GPU 资源,通过以下步骤来纳管这些 :
- 获取认证Token:
在GPUStack Server节点执行命令以获取用于添加Worker节点的认证Token。
#对于Linux或macOS系统,使用命令:
cat /var/lib/gpustack/token
#对于Windows系统,使用命令:
Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustack\token") -Raw
- 添加Worker节点:
拿到Token后,在其他节点上运行以下命令以添加Worker到GPUStack,从而纳管这些节点的GPU资源。
#需要将http://YOUR_IP_ADDRESS替换为你的GPUStack访问地址,将YOUR_TOKEN替换为获取的认证Token。
#对于Linux或macOS系统,使用命令:
curl -sfL https://get.gpustack.ai | sh - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
#对于Windows系统,使用命令:
Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
通过以上简单的操作步骤,就可以纳管多台GPU设备了,界面上可以直接使用。
04
—
GPUStack 展示
1、模型管理
GPUStack 的 Models页面统一管理大型语言模型。GPUStack 中的模型包含一个或多个模型实例的副本。在部署时,GPUStack 会根据模型元数据自动计算模型实例的资源需求,并相应地将它们调度给可用的工作线程。
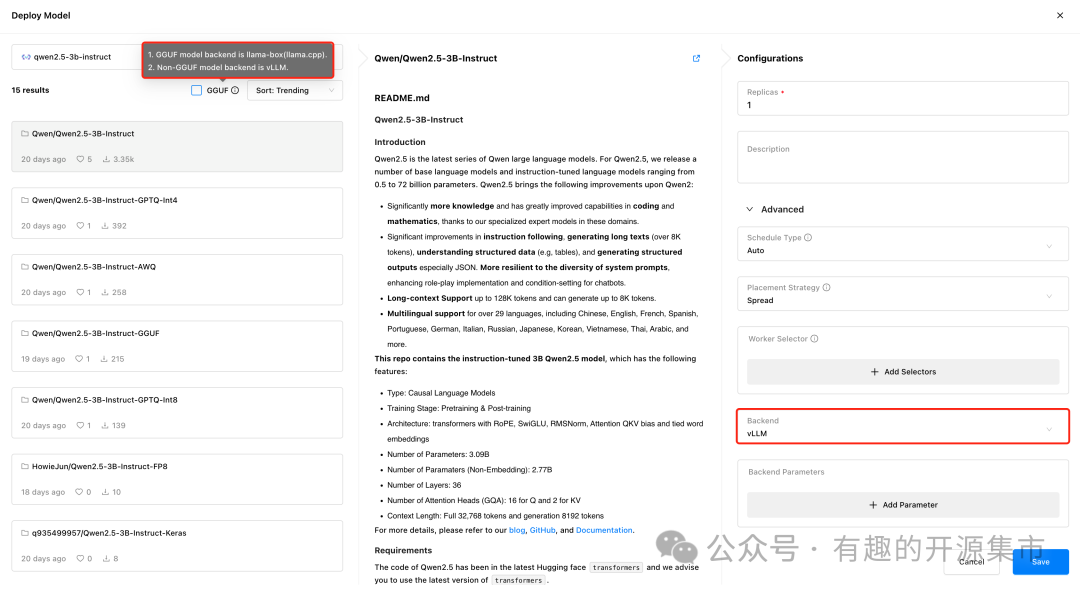
具体包含以下:
- 多模态模型
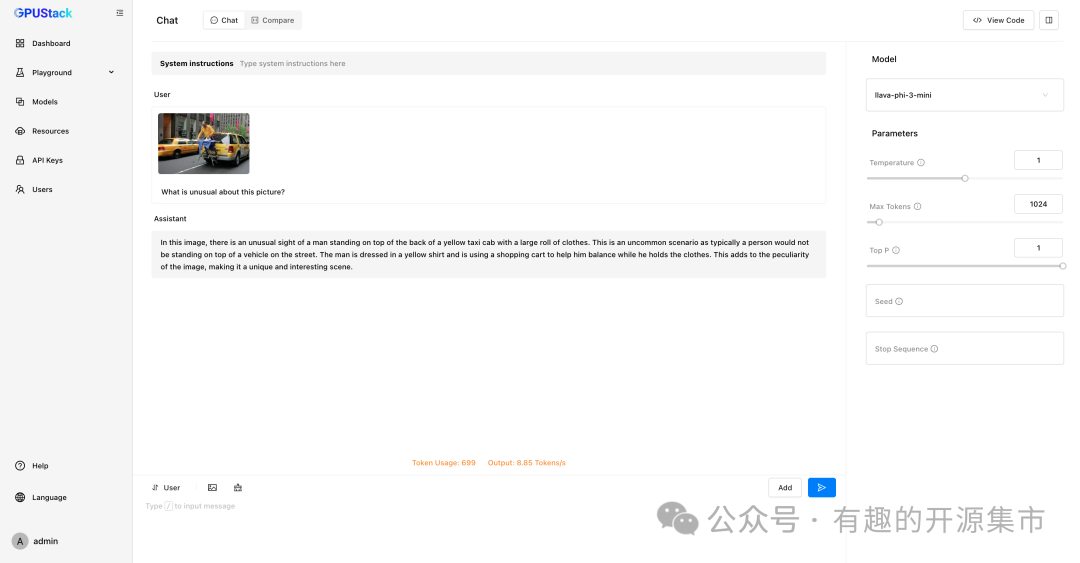
GPUStack 可以部署各种多模态模型,例如 Llama3.2-Vision、Pixtral、Qwen2-VL、LLaVA、InternVL2 等等,用于图像识别等任务,在 Playground 试验场中可以调测模型验证效果。
- Embedding 文本嵌入模型
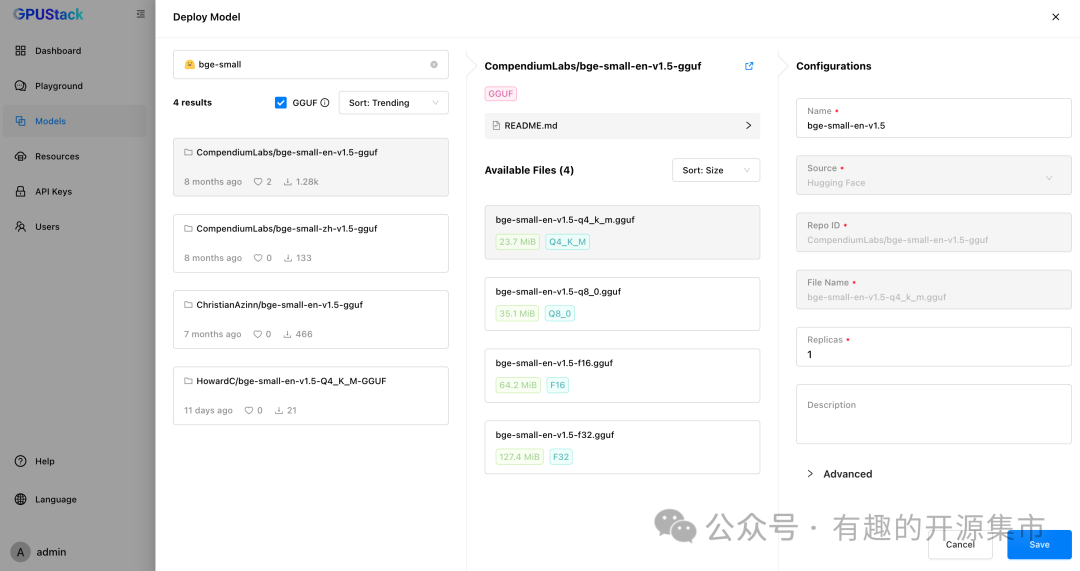
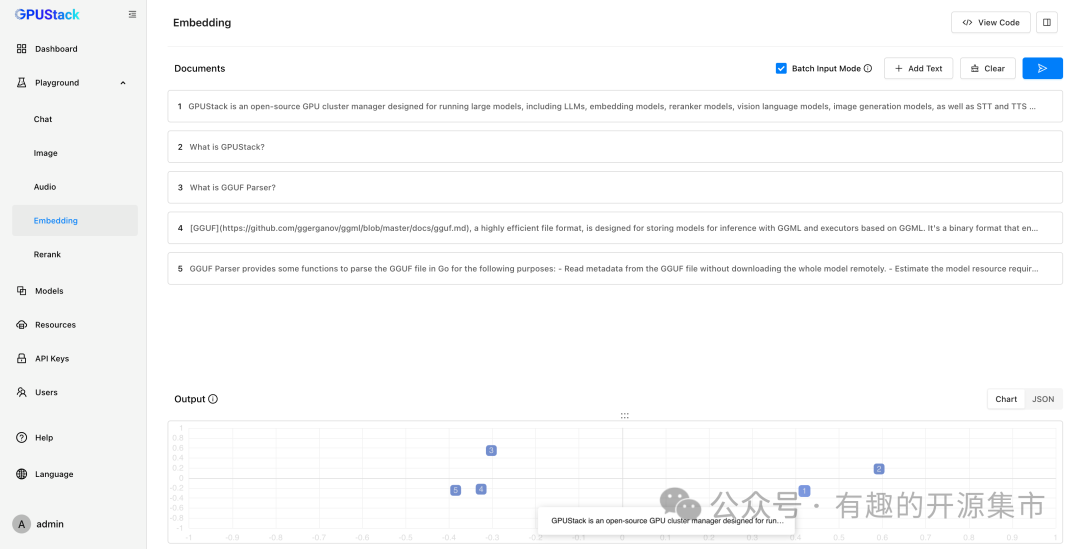
GPUStack 的 Playground 可以对 Embedding 模型进行调测。
- Rerank 重排模型
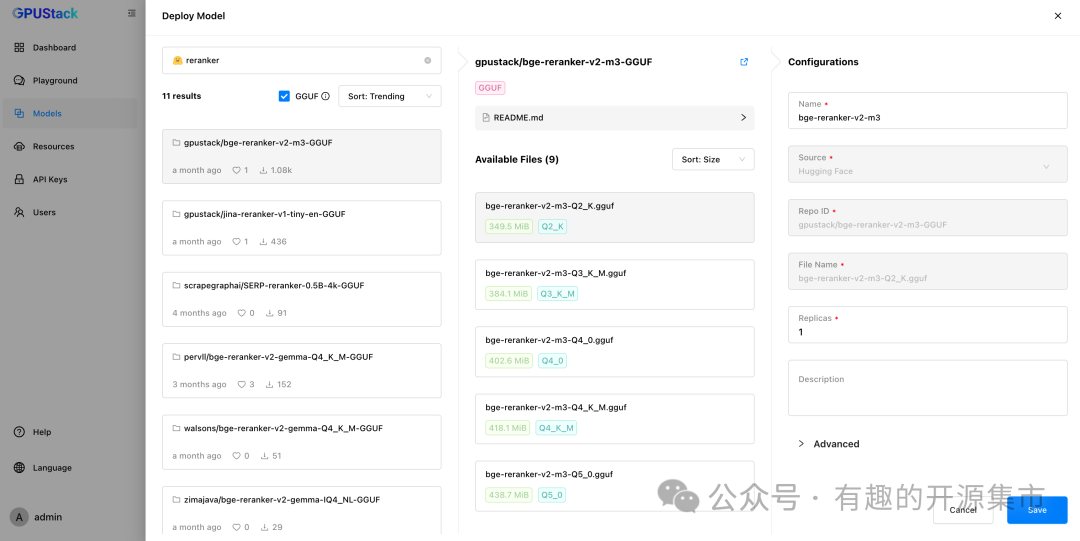
Playground 可以对 Rerank 模型进行调测,提供直观的重排结果展示,用户可以通过结果判断模型对输入的理解和排序的准确性。
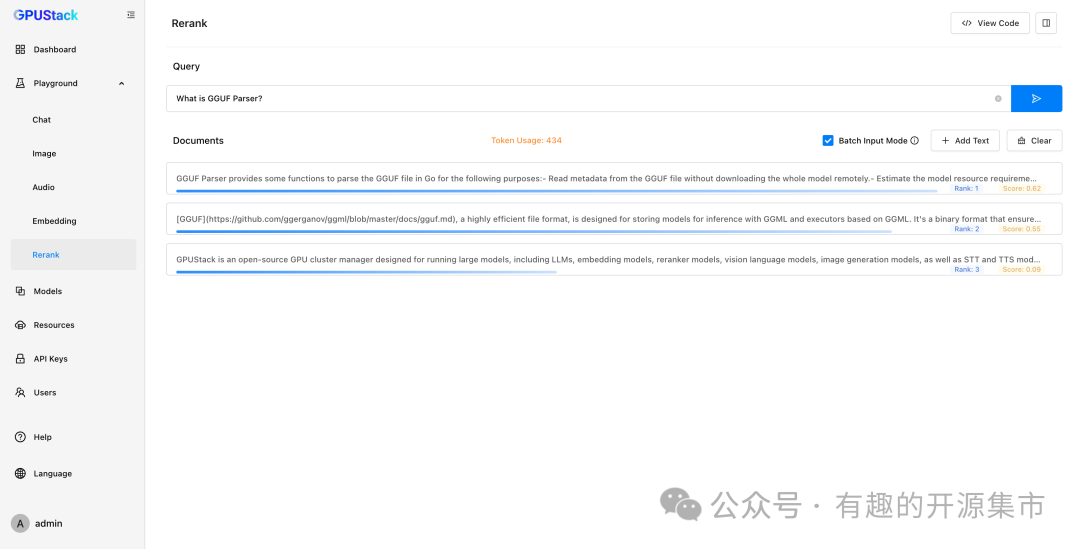
- 文生图模型
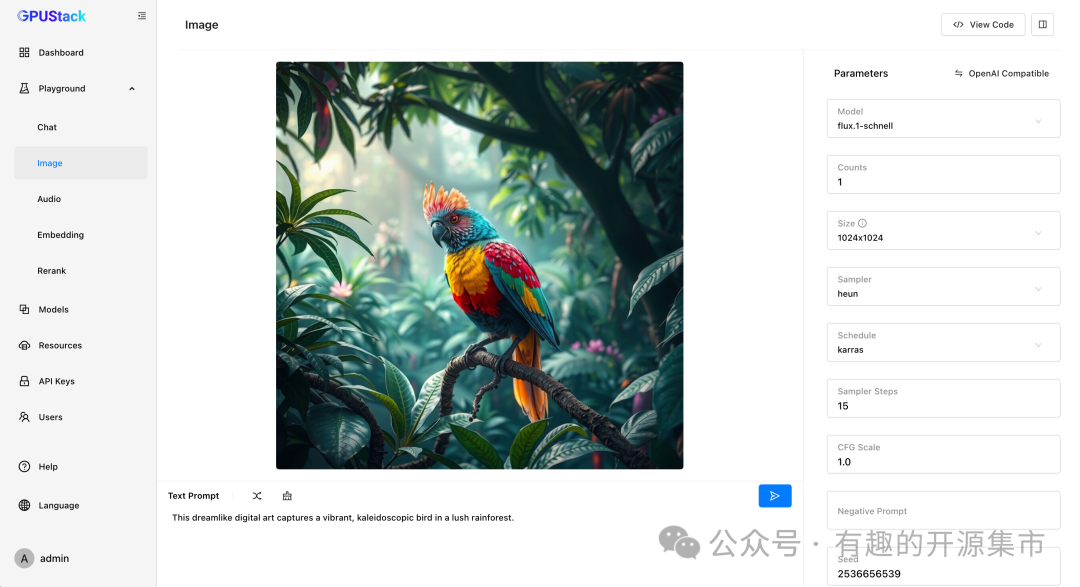
GPUStack 可以开箱即用地部署 Stable Diffusion 和 FLUX 等文生图模型。并提供了 Playground 试验场供开发者调测图像生成的效果,从而试验不同模型的最佳实践参数配置。
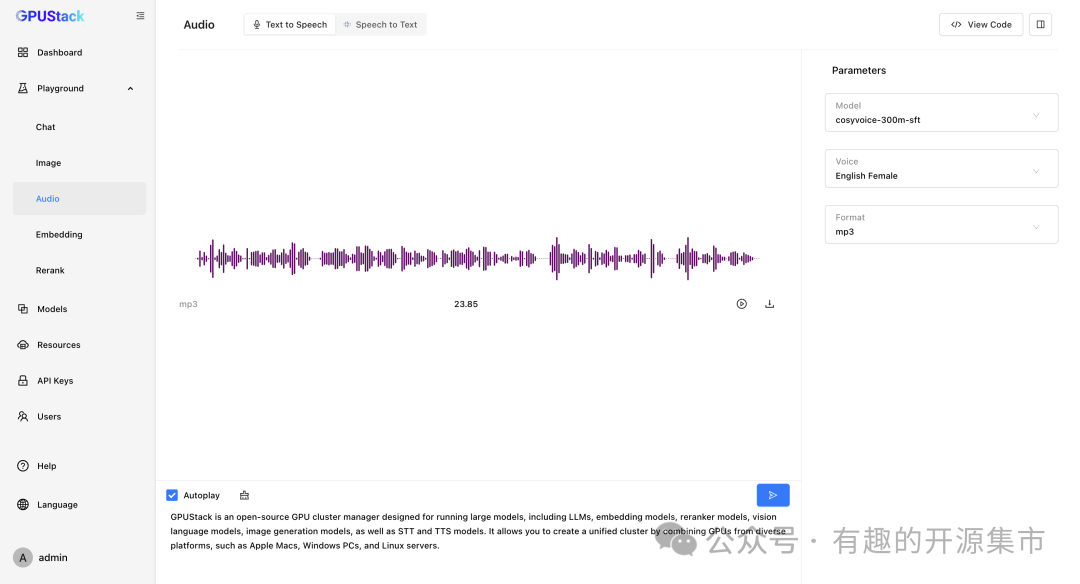
- Text-to-Speech(TTS)文本转语音模型
GPUStack 可以在 NVIDIA GPU 或 CPU 上部署 Text-to-Speech(TTS)文本转语音模型,并提供了 Playground 试验场供开发者调测文本转语音的效果。
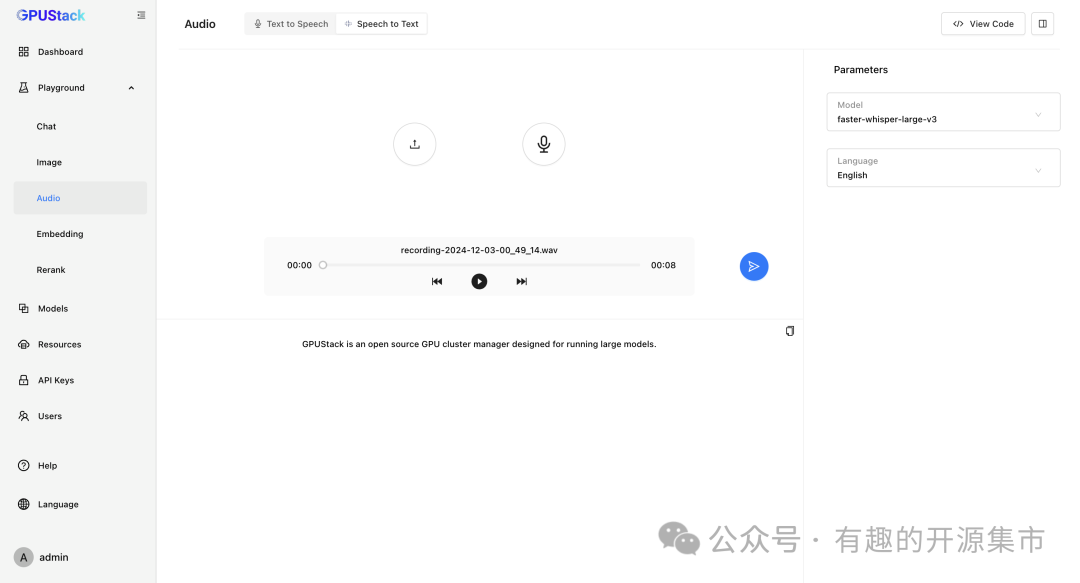
- Speech-to-Text(STT)语音转文本模型
GPUStack 可以在 NVIDIA GPU 或 CPU 上部署 Speech-to-Text(STT)语音转文本模型,并提供了 Playground 试验场供开发者调测语音转文本的效果。
2、Playground能力
GPUStack 在 Playground 中提供了模型调测的能力,还支持多模型对比视图,可以同时对比多个模型的问答内容和性能数据,以评估不同模型、不同权重、不同 Prompt 参数、不同量化、不同 GPU、不同推理后端的模型推理表现。
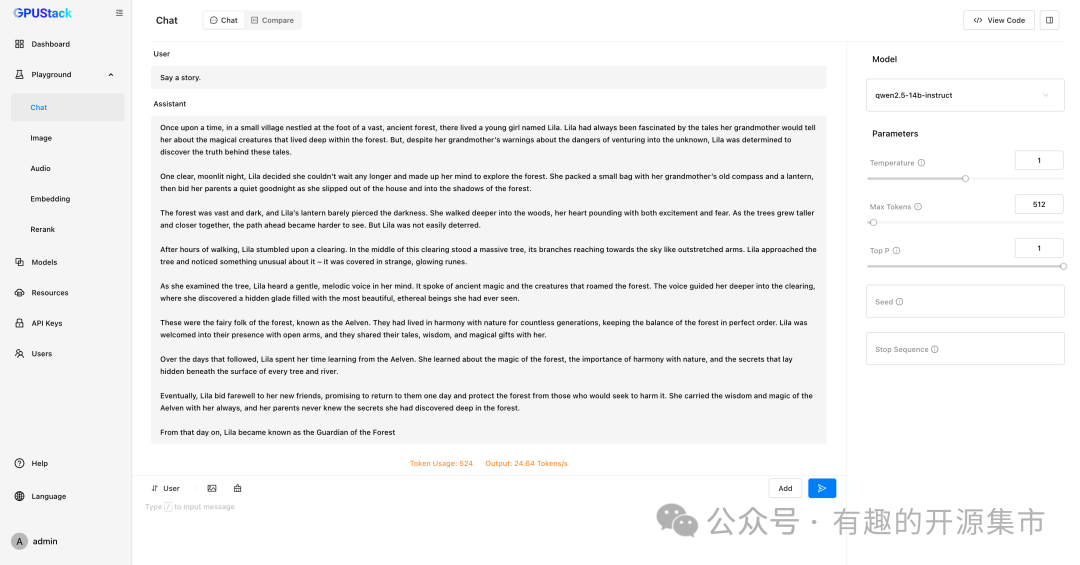
如果 RAG 系统或 AI Agent 系统集成,GPUStack 提供了 OpenAI 兼容的 API,可以通过 View Code 查看动态生成的 API 调用代码示例。
04
—
最后
综上所述,可见 GPUStack 是一个为大模型而生的开源GPU集群管理器,提供了一个企业级的LLM即服务平台,支持异构GPU资源管理、多模型类型和推理引擎,以及灵活的调度策略,非常适合需要高性能、高可用性和数据隐私保护的企业级AI应用开发和部署。如果你也感兴趣的话,不妨试试吧!
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1893
1893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}