







1,受限玻尔兹曼机,思想似乎是源自于热力学,因为有一个玻尔兹曼分布律的东西,具体还没学习,不过可见机器学习中不同学科的思想融合,往往是idea/innovation 的发源地。
2,想迅速入门,受知乎指引看了Hugo Larochelle在YouTube上的神经网络课第五章的Restricted Boltzmann machine. 在[5.2]中讲到了P(h|x)的条件概率的推导,感觉不错,截图如下:

然后就可以很容易地推出隐层是可见层的logistic函数了:
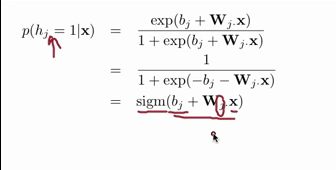
接着,不知道怎么和local markov property扯上关系了,截图放这里:

[5.3]接着讲
先回顾RBM的定义(因为我自己不太记得了,以便连着看):

冒出一个free energy的概念:

推导:
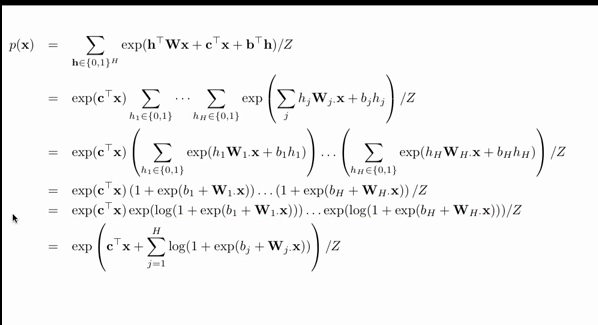
换汤不换药,但是能更清晰地看到各个参数是怎么影响到最后的p(x)的,能对以后的学习过程获得更多insight:

[5.3] over!
[5.4] 开始讲怎么train RBM了

上图中的Loss function选择的是负对数似然函数,其实就是要最大化可见层数据的出现概率,至于为什么要选择负对数似然函数,从一个博客上看到一个解释:
“这里顺便解释一下为什么大家都喜欢负对数似然而不是直接最大化似然,其实如果你有一台可以表示任何数值的超级计算机,那么取不取对数真的没什么关系,但是现实中的计算机表示能力有限,N个训练样本似然乘积很小很小,小到计算机都无法表示了,所以最好取log,概率的和不会有这样的问题;另外,在优化理论中,优化问题的标准形式就是最小化某个目标函数,所以最好加个负号,最小化负对数似然。”
使用随机梯度下降算法,对
θ
求偏导得到的那两项乍一看没看明白(其中的第二项很难计算),但是在“《受限玻尔兹曼机简介》张春霞etc.“中找到了相关的推导,还是很好懂(其中的一些文字也有助于理解),截图如下:




继续说(8)式对
θ
求偏导得到的两项:
其中第一项比较好计算,具体原因,比如说我们让
θ
(注意:
θ
是模型参数的抽象化表征,可以是W, a, b的任何一个)代表权重矩阵
W ij
,观察最后那张截图可以发现,第一项成了
<v i h j > data
<script id="MathJax-Element-20" type="math/tex">
_{data}</script> 意思是
v i h j
期望,只需要求
v i h j
在全部数据集上的平均值即可,而第二项计算却涉及到v,h的全部
2 |v|+|h|
种组合,计算量非常大(基本不可解)。
正是为了解决这个问题,Hinton等人于2002年提出了一种高效的学习算法——contrastive divergence算法
(核心感觉就是Gibbs采样,用采样来approximate先前的第二项,不过还没认真学那篇论文):

[5.4]最后的两页ppt:


对这两页的解释是:算法的目的就是要尽量降低在data上的能量(等同于增加其出现的概率),增加在噪声上的能量? 不太懂。。。但是,又从先前那个博客看到一个解释(那位兄台做的挺好的):
式子的第一项称为positive phrase,通过减小对应的FreeEnergy增大训练样本的概率;第二项是negative phrase,作用是增大对应的FreeEnergy来减小模型产生的样本的概率。这句话不难理解,因为两项分别是往 FreeEnergy(x) 的梯度下降和 FreeEnergy(x ~ ) 的梯度上升方向改变。这也符合最大似然标准,在训练样本上有较大的似然而在其他样本上概率较小。从分类的角度来看,训练样本是正样本,而模型样本是负样本(Negative samples)。
[5.5]RBM-contrastive divergence (parameter update),具体讲CD算法的参数更新,其实在前面我贴出来的几张来自“《受限玻尔兹曼机简介》张春霞etc.“的截图已经有了(最后一张图的三个偏导),但是这里再“多此一举”的写一遍,可以看到具体公式的来由,并加深印象。视频课程中主要是对权重矩阵 W ij 的参数更新做了一个介绍:
回顾一下目标函数和随机梯度下降的求导公式:

玻尔兹曼能量函数关于
W ij
求偏导,并且矢量化(表示成向量内积的形式,见图片左下角,图片右下角给出了h 的定义,是一个概率向量):

于是得到W矩阵的更新规则,注意到
h(x ~ )x ~ T
体现出CD算法的Gibbs采样:

以W矩阵为例,其他参数更新也类似,那么就可以写出整个CD算法的伪代码了:

最后说到了Gibbs采样的次数问题,K取得越大,估计值就会越接近期望值(虽然原因我也不知道,不好意思,Gibbs采样还没认真学)。但是实际上,预训练或者目的只是想利用神经网络extract the feature,那么K=1就足够好了:

以上就是CD算法的一个简单总结。
[5.5] over!
[5.6]讲一个CD算法的变种——Persistent CD














 30万+
30万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









