




 本文详细阐述了受限玻尔兹曼机(RBMs)的基础概念、结构、学习方法以及在深度学习领域的应用。从能量函数、分布函数到模型学习流程,深入解析了RBMs的核心原理,并探讨了Gibbs采样、对比学习加速训练等关键技术。通过实例和数学推导,读者能够全面掌握RBMs的工作机制及其在数据拟合和特征学习中的优势。
本文详细阐述了受限玻尔兹曼机(RBMs)的基础概念、结构、学习方法以及在深度学习领域的应用。从能量函数、分布函数到模型学习流程,深入解析了RBMs的核心原理,并探讨了Gibbs采样、对比学习加速训练等关键技术。通过实例和数学推导,读者能够全面掌握RBMs的工作机制及其在数据拟合和特征学习中的优势。
一、序
关于RBMs的文章已经有不少了,但是很多资料我在阅读的时候仍然对细节有一些疑惑。在查阅学习了大牛的视频、论文之后,很多问题豁然开朗,且在本文中记录下我对RBMs的粗浅了解。首先从玻尔兹曼机和限制玻尔兹曼机的结构和定义开始:
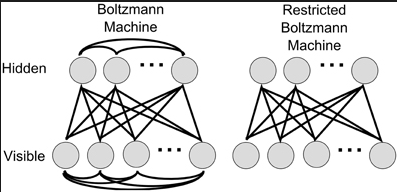
二、Boltmann Machines:
玻尔兹曼机(Boltmann Machines)的能量函数(Energy function)是:
分布函数:
其中分母Z学名叫做partition function
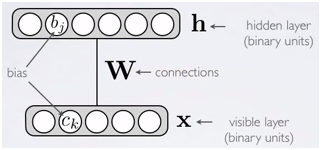
三、Restricted Boltmann Machines:
限制玻尔兹曼机(Restricted Boltmann Machines,简称RBMs)的能量函数(Energy function)是:
分布函数:
能量函数的能量越小,分布函数相应的概率就越大。
玻尔兹曼机和限制玻尔兹曼机都属于基于能量的模型(Energy-Based Models),从模型图和公式中很容易看出两者的区别:玻尔兹曼机隐含层(和可见层)处于同一层的任意两个节点之间有一条连线;而限制玻尔兹曼机同层变量之间是相互独立的。只要有足够的隐单元,限制玻尔兹曼机可以表示任意的离散分布,玻尔兹曼机的表示能力则更强一些。另一方面,限制玻尔兹曼机比玻尔兹曼机更容易训练。
四、模型学习:
训练RBMs就是学习能量函数的过程,变量中只有输入
x
是已知的。
Free Energy:
为了后面计算公式的简洁,首先引入Free Energy这个概念:
例如:如果
hi∈{0,1}
:
给定参数和 x 就可以很容易的计算出Free Energy的值,不依赖于隐单元 h 的具体取值。
梯度方法进行优化:
用梯度算法学习RBMs模型参数
θ
(
θ
包括
W,c,b
),目标函数是
P(x)
(这里是梯度上升,因为要求的是似然的极大值)。
P(x)
取对数求偏导:
对数似然梯度(log-likelihood gradient):
∂logP(x)∂θ 是对 ∂logP(x)∂W,∂logP(x)∂c,∂logP(x)∂b 的统一表示,编写代码时需要分别求偏导。求偏导都没有太大难度,其中 ∂E(x,h)∂W=∂−h⊤Wx∂W=−hx⊤ 。
很多文章里喜欢写成负对数似然梯度(negative log-likelihood gradient)的形式,
−logP(x)
就应该用梯度下降方法来更新参数了:
训练集上的平均负对数似然梯度等于:
P^ 是训练集对应的分布, P 是模型分布,
式子的第一项称为positive phrase,通过减小对应的FreeEnergy增大训练样本的概率;第二项是negative phrase,作用是增大对应的FreeEnergy来减小模型产生的样本的概率。句话不难理解,因为两项分别是往 FreeEnergy(x) 的梯度下降和 FreeEnergy(x~) 的梯度上升方向改变。这也符合最大似然标准,在训练样本上有较大的似然而在其他样本上概率较小。从分类的角度来看,训练样本是正样本,而模型样本是负样本(Negative samples)。
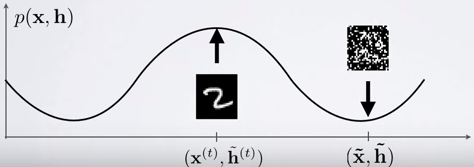
把训练样本代入求均值即可得到梯度公式的第一项
EP^[∂FreeEnergy(x)∂θ]
的值,第二项
EP[∂FreeEnergy(x~)∂θ]
计算模型分布上的期望,这就比较困难了,因为这需要取遍所有可能的
x
的值。所以接下来我们就需要用到MCMC 采样来近似估计了。用MCMC采样得到的一组样本来近似估计整体的样本分布,梯度公式第二项在采样得到的样本上求近似期望(平均值)得到估计值。在实际中,常用Gibbs采样,Gibbs 采样是MCMC 算法的一种。用Gibbs从模型分布中采样n个样本,然后负对数似然梯度在训练集上的期望就可以近似为:
最后,简要概括一下RBMs模型学习方法的步骤:(1)、求偏导,(2)、采样,(3)、估计负对数似然梯度,(4)、梯度下降方法更新参数。
五、Gibbs采样:
对RBMs模型来说, Gibbs主要有两个作用:一是估计negative log-likelihood gradient;二是在训练完模型之后(如DBN,DBN是由多个RBMs叠加而成的),用Gibbs进行采样,可以看到模型对数据的拟合以及网络中间隐含层的抽象效果。
在RBMs模型训练过程中,Gibbs就是用来对negative log-likelihood gradient进行估计的。Gibbs采样分两个小步对
(x,h)
进行采样,第一步固定
x
对
h
进行采样,第二步固定
h
对
x
进行采样,交替进行直到收敛:
因为在训练过程中,训练模型分布会逐渐逼近训练样本分布,所以第一步可以从训练样本的分布 P^ 抽取样本作为 x1 。如果第一步直接从模型 P 中采样,Gibbs采样会迅速收敛。
例如:假设 Gibbs采样主要是根据条件分布迭代进行采样的,所以在采样之前要先推导出条件分布公式。 如果
hj∈{0,1}
,可以得到:
类似的: 如果
xj∈{0,1}
,可以得到: Contrastive Divergence可以加快RBMs的训练速度,随机选择一个训练样本初始化
x1
,并且每一次迭代只用一个模型样本来估计negative log-likelihood gradient,而不是等到MCMC采样收敛后求期望。 k-step Contrastive Divergence(CD-k):MCMC采样k步
x1,x2,...,xk+1
, 用
xk+1
估计negative log-likelihood gradient。当k=1时,就能得到比较好的近似(DBN等pre-training k取1就够用了),k增大可以得到更好的效果。Contrastive Divergence的一种理解是在训练样本
x1
附近的局部区域内估计negative log-likelihood gradient。 借用一下大神Bengio的文章”Learning Deep Architectures for AI”的算法描述: CD只在附近的局部区域取Negative Sample来估计negative log-likelihood gradient,很难取到其它极值区域的样本,Persistent CD可以在一定程度上解决这个问题。Persistent CD的思想很简单,它与CD的区别仅仅在与:用上一次迭代得到的
xk+1
(即Negative Sample)作为这次迭代的初始值来初始化
x1
。PS:Persistent CD是2008年Tijmen发表在ICML上的文章。 [1].Youtube上Hugo Larochelle的视频讲解:https://www.youtube.com/user/hugolarochelle/videos [2].DeepLearning tutorial:http://deeplearning.net/tutorial/rbm.html [3].LSIA:http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations [4].Yoshua Bengio:Learning Deep Architectures for AI条件分布:
六、Contrastive Divergence:

Persistent CD:
七、参考资料:

















 1599
1599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









