






📚 引言:从"炼丹"到数据驱动的蜕变
在上一篇《深度学习笔记:超萌玩转卷积神经网络(CNN)(炼丹续篇)》中,我们用"炼丹"比喻了CNN模型的调参过程(👉点击回顾炼丹秘籍)。但正如炼丹需要丹炉与药材,深度学习的"炼丹炉"是模型架构,而"药材"正是数据集!今天,我们就来拆解那些让CNN模型"功力大增"的经典数据集,看看它们如何与卷积层、池化层、全连接层等"招式"配合,实现从"入门到精通"的跨越。
🏆 王者级数据集:ImageNet(CNN的"武林大会")

(图:ImageNet中包含的2万+类别样本,从动物到建筑应有尽有)
🔍 核心价值
- 规模碾压:1400万张全尺寸标注图像,覆盖2.2万个类别,堪称"图像界的百科全书"。
- 算法试金石:每年举办的ILSVRC竞赛(如AlexNet、ResNet的成名战)让ImageNet成为CNN模型的"华山论剑"之地。
- 预训练利器:大多数现代CNN模型(如ResNet50、EfficientNet)都会先在ImageNet上预训练,再迁移到其他任务。
🌀 与CNN的联动
- 卷积核的"见多识广":ImageNet的多样性让CNN学会提取从纹理到形状的通用特征。
- 迁移学习的基石:用ImageNet预训练的模型在医疗影像、自动驾驶等小数据集上微调,效果远超随机初始化。
🧪 合理性检验数据集:CIFAR10/100 & MNIST(CNN的"入门考")
🔸 CIFAR10/100:小而美的"新秀赛场"

(图:CIFAR10的10个类别,32×32像素的"马赛克"画风)
- 数据集简介
- CIFAR-10:有5万张训练图像,1万张测试图像,10个类别、每个类别有6千张图像,图像大小32×32。
- CIFAR-100:有5万张训练图像,1万张测试图像,100个类别、每个类别有6百张图像,图像大小32×32。
- 特点:
- 32×32像素的"低分辨率"挑战CNN的鲁棒性。
- CIFAR100的100个精细类别(如"玫瑰""郁金香")考验模型区分能力。
- 作用:
- 快速验证新架构(如MobileNet)在小数据上的表现。
- 对比不同优化器(Adam vs SGD)的效果。
🔸 MNIST:手写数字的"Hello World"
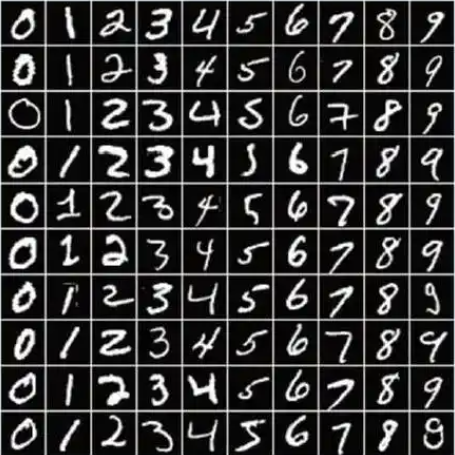
(图:MNIST的黑白数字,CNN入门必刷题)
- 数据集简介
- MNIST(Modified National Institute of Standards and Technology)是一个经典的手写数字图像数据集,包含60,000张训练图像和10,000张测试图像
- 每张图像是28x28像素的灰度图(单通道)
- 每张图像对应一个0到9的数字标签,表示图像中的手写数字。
- 为什么它"简单"却不可或缺?
- 28×28像素的极简结构,适合新手调试CNN代码(如验证卷积核滑动是否正确)。
- 通过MNIST实现99%+的准确率,才能证明CNN实现无误(否则需检查梯度爆炸/消失等问题)。
🖼️ 细分领域数据集:Caltech & Pascal VOC(CNN的"专业赛道")
🔸 Caltech 101/256:从"百物图"到"千物志"
- 数据集简介:
- Caltech 101:发布于2004年,是早期用于物体分类的经典数据集。包括101个类别和1个背景类(共102类)。每个类别有31到800张图像,总计约9144张图像。图像尺寸和分辨率不统一,需手动调整。
- Caltech 256:发布于2007年,是Caltech 101的扩展版本。包含257个类别(256个物体类别+1个背景类别)。每个类别至少有80张图像,总计约30607张图像。图像尺寸和分辨率更丰富,适合更复杂的分类任务。
- 价值:
- 101/256个类别的层次化标注,适合研究少样本学习(Few-shot Learning)。
- 相比ImageNet,Caltech的图像背景更简单,适合聚焦目标检测任务。
🔸 Pascal VOC:分割与分类的"全能考场"
- 为什么它是CNN的"必修课"?
- 同时提供目标检测(Bounding Box)和语义分割(Pixel-level)标注。
- 经典模型如Faster R-CNN、Mask R-CNN均在此数据集上"刷榜"。
📈 数据集与CNN的"化学反应"
| 数据集 | CNN挑战 | 模型适配建议 |
|---|---|---|
| ImageNet | 超大类别的泛化能力 | 使用ResNet、EfficientNet等深层网络 |
| CIFAR10/100 | 小分辨率下的特征提取 | 轻量化模型(如MobileNet) |
| MNIST | 极简结构下的梯度传播 | 验证CNN基础实现(如卷积+池化层) |
| Caltech 256 | 少样本学习与背景干扰 | 结合数据增强(如随机裁剪) |
| Pascal VOC | 多任务学习(检测+分割) | 使用Mask R-CNN等一体化架构 |
💡 实战建议:如何选择你的"炼丹药材"?
- 新手村:从MNIST+CIFAR10起步,快速验证CNN代码。
- 进阶赛:在Caltech 256上测试少样本学习能力,或用Pascal VOC挑战多任务。
- 王者局:用ImageNet预训练模型,结合迁移学习解决实际业务问题。
🚀 结语:数据驱动的AI未来
正如炼丹需要"天材地宝",深度学习的突破离不开高质量数据集的支撑。从MNIST的"入门试炼"到ImageNet的"巅峰对决",这些数据集不仅是模型的"训练场",更是推动AI技术进化的"燃料"。下一次当你调整CNN的超参数时,不妨想想:你正在用怎样的"药材",炼制属于你的AI"灵丹"?
📌 互动话题:你在项目中用过哪些数据集?欢迎在评论区分享你的"炼丹心得"!
延伸阅读:
希望这篇文章能帮你打通数据集与CNN的"任督二脉"!如果需要具体数据集的代码示例(如用PyTorch加载CIFAR10),欢迎留言告诉我~ 😉

















 1966
1966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









