



各位技术小伙伴们,上回咱们聊了RNN家族里的“记忆大师”LSTM,这回它的“轻量级”好兄弟GRU(Gated Recurrent Unit,门控循环单元)也来凑热闹啦!GRU就像是LSTM的简化版,同样擅长处理序列数据,但结构更简单,计算效率更高。话不多说,咱们赶紧来认识一下这位新朋友吧!
👨👩👧👦 GRU和LSTM:本是同根生的“简化版”
要说GRU,就不得不先提它的“老大哥”LSTM。LSTM凭借强大的记忆能力和三个门(输入门、遗忘门、输出门)在序列数据处理领域大放异彩。但是呢,LSTM的结构相对复杂,计算量也大,有时候就像一辆豪华跑车,虽然性能卓越,但油耗也不低。👇点击了解LSTM工作原理
这时候,GRU就闪亮登场了!它就像是LSTM的“简化版”跑车,保留了LSTM的核心功能——处理长期依赖关系,但去掉了输出门,把遗忘门和输入门合并成了一个更新门(Update Gate),还新增了一个重置门(Reset Gate)。这样一来,GRU的结构就更简单了,计算效率也更高了。
🔍 GRU的原理:简化版的“记忆管理机制”
GRU之所以能在简化结构的同时保持强大的性能,是因为它内部有一套精妙的“简化版记忆管理机制”。简单来说,GRU通过两个门(更新门、重置门)来控制信息的流动和更新。
- 更新门(Update Gate):这个门就像是LSTM中的遗忘门和输入门的结合体,它决定了当前时刻的输入信息有多少可以更新到记忆中,以及之前存储的信息有多少应该被保留下来。
- 重置门(Reset Gate):这个门决定了之前存储的信息有多少应该被“重置”或“忽略”,从而在当前时刻只考虑与当前输入相关的信息。
通过这两个门的协同工作,GRU就能像变魔术一样,在简化结构的同时保持强大的记忆能力!
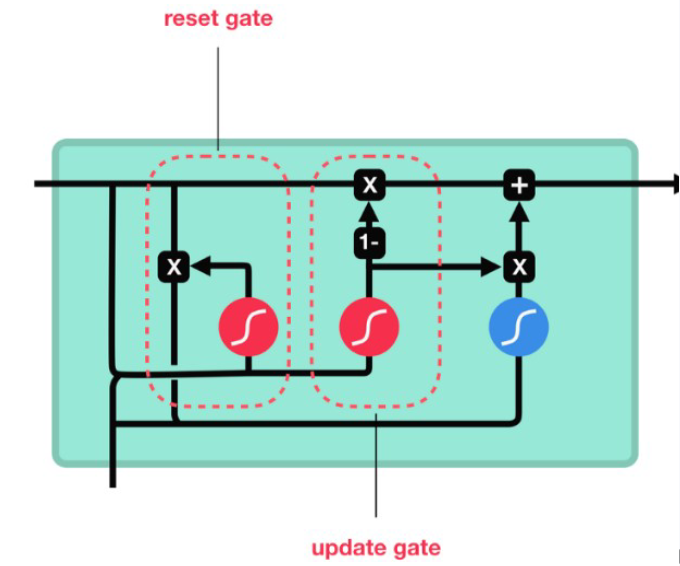
(看,这就是GRU的一个记忆单元,里面藏着两个门,还有一条“记忆主线”)
🌟 GRU的特点:轻量级、高效、灵活
- 轻量级:相比LSTM,GRU的结构更简单,参数更少,计算效率更高。
- 高效:由于去掉了输出门,GRU在训练过程中能更快地收敛,减少计算时间。
- 灵活:GRU同样可以根据不同的任务需求,调整门的阈值,从而控制信息的流动和更新。
🌈 GRU的应用场景:轻量级“记忆大师”的舞台
GRU这么厉害,当然也要在各个领域大展身手啦!下面就给大家举几个例子:
📝 文本分类与情感分析
想不想让机器也学会读懂文本的情感?GRU就能做到!通过处理文本序列数据,GRU可以捕捉到文本中的情感倾向和语义信息,从而实现文本分类和情感分析。比如,分析用户评论是正面还是负面,或者判断一篇新闻文章的主题类别。
🎧 语音识别与合成
在语音识别和合成领域,GRU也能派上用场。通过处理语音信号的时间序列数据,GRU可以帮助机器更准确地识别语音内容,或者生成更自然的语音合成效果。
📊 股票价格预测
在股票价格预测等金融领域,GRU同样能展现出其强大的性能。通过处理历史股票价格数据的时间序列,GRU可以捕捉到价格变化的趋势和规律,从而给出更准确的预测结果。
🤖 机器人路径规划
在机器人路径规划领域,GRU也能帮助机器人更好地理解环境、规划最优路径。通过处理传感器采集到的序列数据,GRU可以让机器人更智能地避开障碍物,到达目标位置。
💻 代码实战:用Python实现一个简单的GRU
说了这么多,咱们也来动手实践一下吧!下面是一个使用Python和Keras库实现简单GRU模型的例子,用于预测正弦波序列的下一个值(和LSTM的例子类似,但这次我们用GRU来试试)。
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import GRU, Dense
# 生成正弦波数据(与LSTM例子相同)
def generate_sine_wave(seq_length, num_samples):
x = np.linspace(0, 4 * np.pi, seq_length * num_samples)
y = np.sin(x)
return y.reshape(num_samples, seq_length, 1)
# 参数设置
seq_length = 50 # 序列长度
num_samples = 1000 # 样本数量
# 生成数据
data = generate_sine_wave(seq_length, num_samples)
# 划分训练集和测试集
train_size = int(num_samples * 0.8)
X_train, y_train = data[:train_size, :-1], data[:train_size, -1]
X_test, y_test = data[train_size:, :-1], data[train_size:, -1]
# 构建GRU模型
model = Sequential([
GRU(50, activation='relu', input_shape=(seq_length - 1, 1)),
Dense(1)
])
# 编译模型
model.compile(optimizer='adam', loss='mse')
# 训练模型
model.fit(X_train, y_train, epochs=100, verbose=0)
# 预测并可视化结果
predictions = model.predict(X_test)
plt.figure(figsize=(12, 6))
plt.plot(y_test, label='True Values')
plt.plot(predictions, label='Predictions')
plt.legend()
plt.show()运行这段代码,你就能看到一个简单的GRU模型如何学习并预测正弦波序列的下一个值啦!是不是觉得GRU也很厉害呢?
🎉 结语
好啦,今天关于GRU的分享就到这里啦!相信通过这篇文章,你已经对GRU有了更深入的了解。GRU就像是LSTM的“轻量级”好兄弟,凭借其简化的结构和高效的性能,在序列数据处理领域也能大放异彩。如果你也对序列数据处理感兴趣,不妨动手试试GRU吧!说不定你也能用它创造出一些有趣的应用呢!
最后,别忘了点赞、收藏、转发哦!咱们下期再见啦!👋

















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









