






Transformer 是一种神经网络架构,它从根本上改变了人工智能的方法。Transformer 于 2017 年在开创性论文“Attention is All You Need”中首次引入,此后成为深度学习模型的首选架构,为 OpenAI 的 **GPT、**Meta 的 Llama 和 Google 的 Gemini 等文本生成模型提供支持。除了文本,Transformer 还应用于音频生成、图像识别、蛋白质结构预测,甚至玩游戏,展示了它在众多领域的多功能性。
对于初学者而言,它的确有一定的难度。但是佐治亚理工学院和 IBM 研究院的几位研究人员联合开发了一款名为Transformer Explainer的开源工具。这款基于网页的交互式可视化工具非常适合非专业人士使用,它能有效地帮助用户理解 Transformer 模型的复杂结构以及背后的数学运算。
可视化网址:网站:https://poloclub.github.io/transformer-explainer/
unsetunsetTransformer 架构unsetunset
每个文本生成 Transformer 都由以下三个关键组件组成:
-
Embedding: 文本输入被划分为更小的单元,称为标记,可以是单词或子词。这些标记被转换为称为嵌入向量的数字向量,用于捕获单词的语义。
-
Transformer Block:处理和转换输入数据的模型。每个区块包括:
-
Attention Mechanism:Transformer 块的核心组件。它允许标记与其他标记通信,捕获上下文信息和单词之间的关系。
-
MLP (Multilayer Perceptron) Layer:一个独立对每个令牌进行操作的前馈网络。虽然注意力层的目标是在 Token 之间路由信息,但 MLP 的目标是优化每个 Token 的表示。
-
Output Probabilities:最终的线性层和 softmax 层将处理的嵌入转换为概率,使模型能够预测序列中的下一个标记。
unsetunsetEmbeddingunsetunset
假设您想使用 Transformer 模型生成文本。您添加如下所示的提示:“Data visualization empowers users to” .此输入需要转换为模型可以理解和处理的格式。这就是 embedding 的用武之地:它将文本转换为模型可以使用的数字表示形式。要将提示转换为嵌入,我们需要
-
1) 对输入进行分词;
-
2) 获取分词嵌入;
-
3) 添加位置信息;
-
4) 最后将分词和位置编码相加以获得最终的嵌入。

1)分词化
分词是将输入文本分解为更小、更易于管理的片段(称为分词)的过程。这些标记可以是单词或子词。“Data” 和 “visualization” 这两个词对应于唯一的标记,而 “empowers” 这个词则分为两个标记。令牌的完整词汇表是在训练模型之前决定的:GPT-2 的词汇表有 50,257 个唯一的令牌。现在,我们已经将输入文本拆分为具有不同 ID 的标记,我们可以从嵌入中获取它们的向量表示。
2)分词嵌入
GPT-2 Small 将词汇表中的每个标记表示为 768 维向量;向量的维度取决于模型。这些嵌入向量存储在形状为 (50,257, 768) 的矩阵中,包含大约 3900 万个参数!这个广泛的矩阵允许模型为每个标记分配语义含义。
3)位置编码
Embedding 层还对有关输入提示中每个标记位置的信息进行编码。不同的模型使用不同的方法进行位置编码。GPT-2 从头开始训练自己的位置编码矩阵,将其直接集成到训练过程中。
4)最终嵌入
最后,我们将 token 和 positional encoding 相加,得到最终的 embedding 表示。这种组合表示形式捕获了标记的语义含义及其在 Importing 序列中的位置。
unsetunsetTransformer Blockunsetunset
Transformer 的处理核心在于 Transformer 模块,它由多头自注意力和多层感知器层组成。大多数模型由多个这样的块组成,这些块一个接一个地按顺序堆叠。代币表示形式通过层不断演变,从第一个区块到第 12 个区块,使模型能够建立对每个代币的复杂理解。这种分层方法导致 input 的更高阶表示。
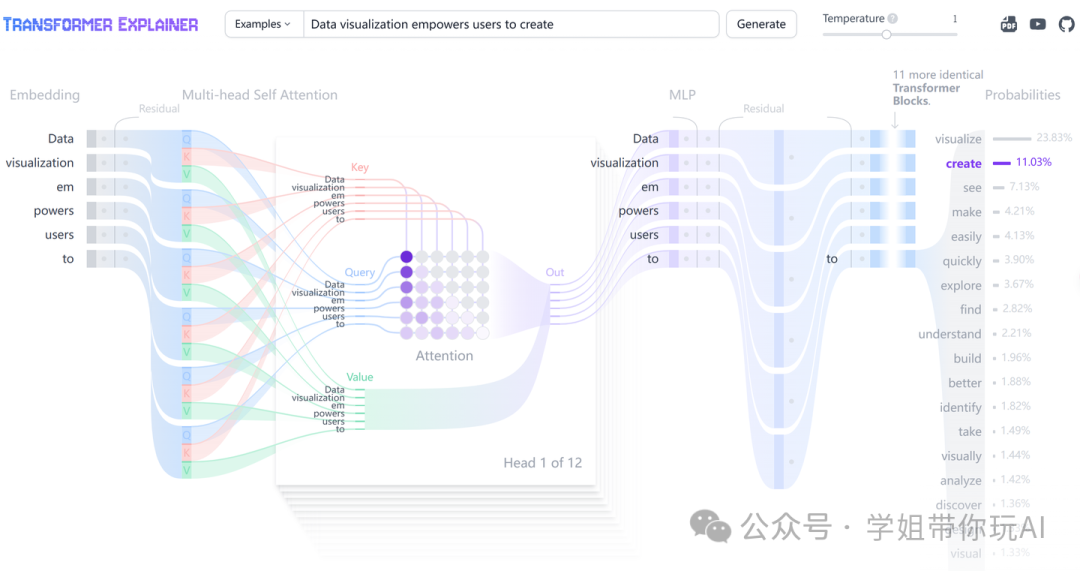
Multi-Head Self-Attention
自我注意机制使模型能够专注于输入序列的相关部分,从而能够捕获数据中的复杂关系和依赖关系。让我们看看这种自我关注是如何逐步计算的。
1)查询、键和值矩阵
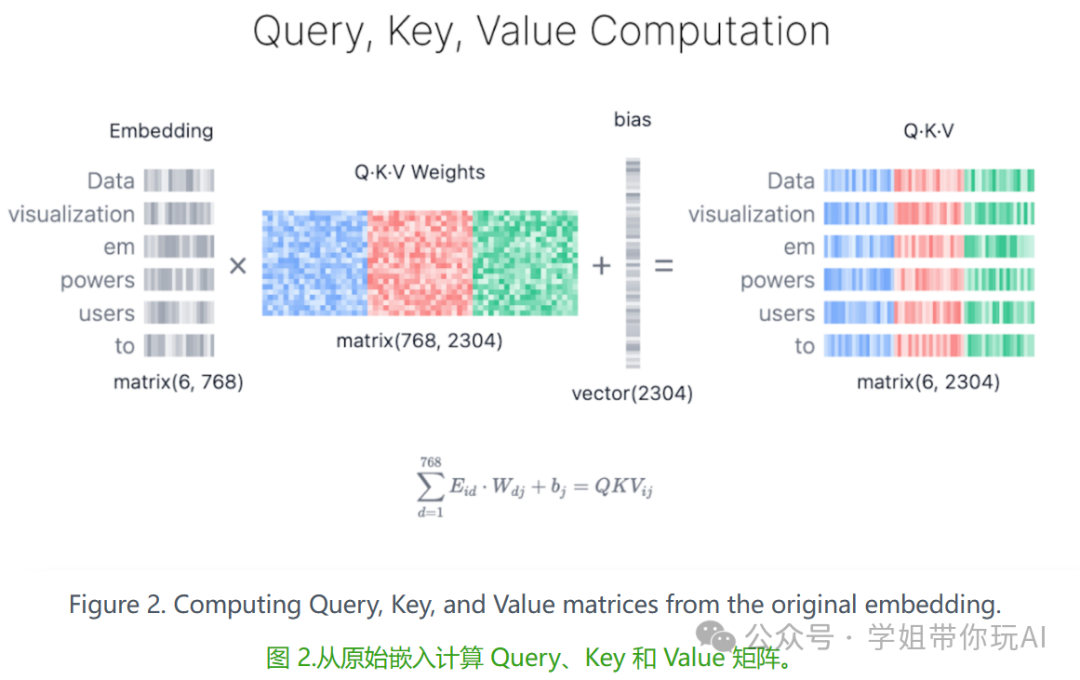
每个标记的嵌入向量都转换为三个向量:查询 (Q)、键 (K) 和值 (V)。这些向量是通过将输入嵌入矩阵与学习的 Q、K 和 V 的权重矩阵相乘而得出的。下面是一个 Web 搜索类比,可以帮助我们在这些矩阵背后建立一些直觉:
-
查询 (Q) 是您在搜索引擎栏中键入的搜索文本。这是您要_“查找更多信息”_的令牌。
-
键 (K) 是搜索结果窗口中每个网页的标题。它表示查询可以处理的可能令牌。
-
值 (V) 是显示的网页的实际内容。将适当的搜索词 (Query) 与相关结果 (Key) 匹配后,我们希望获取最相关页面的内容 (Value)。
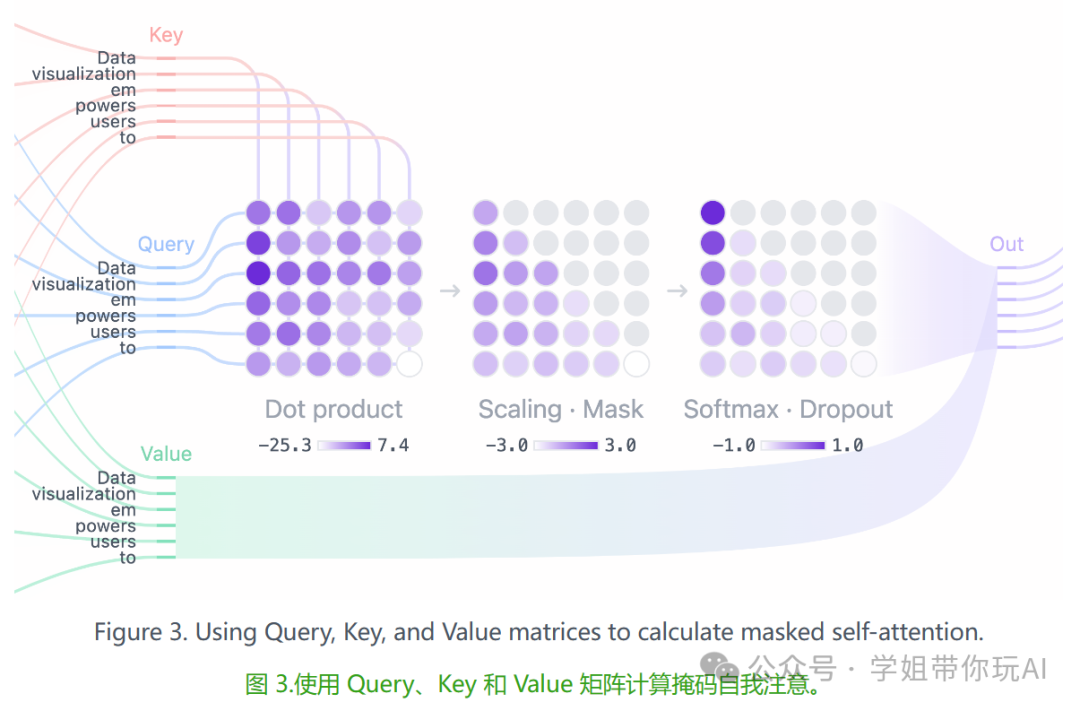
2)Masked Self-Attention
Masked self-attention允许模型通过关注输入的相关部分来生成序列,同时阻止访问未来的标记。
-
注意力得分:Query 和 Key 矩阵的点积确定每个查询与每个键的对齐方式,从而生成一个反映所有输入标记之间关系的方阵。
-
Masking:将掩码应用于注意力矩阵的上三角形,以防止模型访问未来的标记,并将这些值设置为负无穷大。该模型需要学习如何在不“窥视”未来的情况下预测下一个代币。
-
Softmax:掩码后,注意力分数由 softmax 运算转换为概率,该运算采用每个注意力分数的指数。矩阵的每一行总和为 1,并指示其左侧的所有其他标记的相关性。
3)输出
该模型使用掩蔽的自我注意分数,并将其与 Value 矩阵相乘,以获得自我注意机制的最终输出。GPT-2 有 12 个自我注意头,每个头捕获代币之间的不同关系。这些头的输出是串联的,并通过线性投影传递。
Multi-Layer Perceptron
在多个自我注意力头捕获到输入标记之间的不同关系后,连接的输出通过多层感知器 (MLP) 层以增强模型的表示能力。MLP 模块由两个线性变换组成,中间有一个 GELU 激活函数。第一个线性变换将输入的维数从 768 增加到 3072 四倍。第二次线性变换将维数减小回原始大小 768,确保后续层接收到一致维度的输入。与自我注意机制不同,MLP 独立处理令牌,并简单地将它们从一个表示映射到另一个表示。

unsetunsetOutput Probabilitiesunsetunset
在通过所有 Transformer 模块处理完输入后,输出将通过最终的线性层,为代币预测做好准备。该层将最终表示投影到 50,257 维空间中,其中词汇表中的每个标记都有一个对应的值,称为 logit。任何词元都可以是下一个词,因此这个过程允许我们简单地根据它们成为下一个词的可能性对这些词元进行排序。然后,我们应用 softmax 函数将 logits 转换为总和 1 的概率分布。这将允许我们根据其可能性对下一个 token 进行采样。
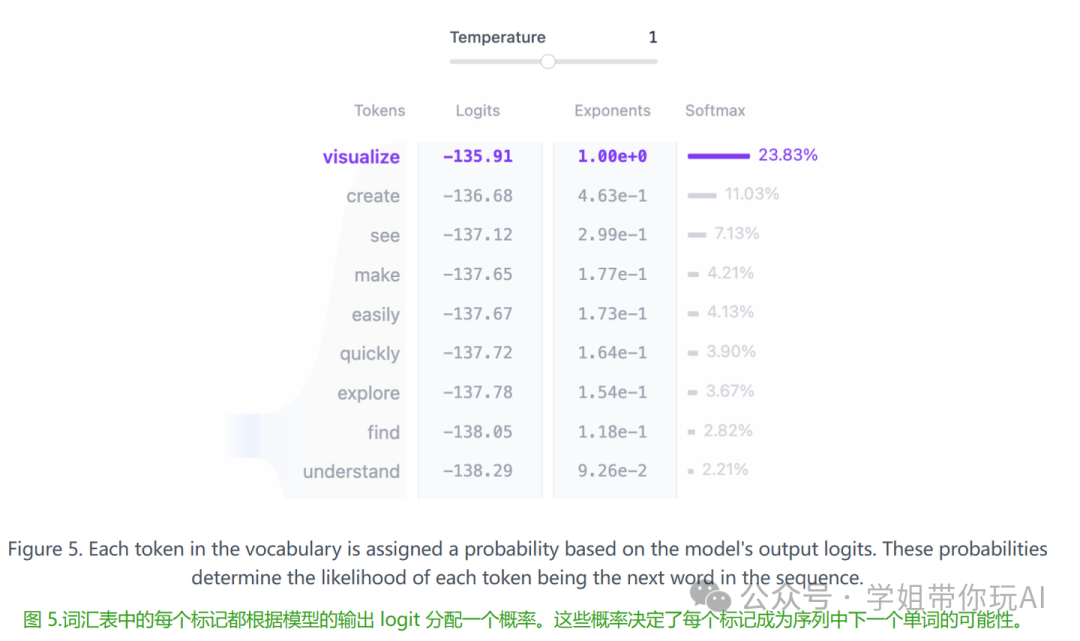
最后一步是通过从此分布中采样来生成下一个标记温度超参数在此过程中起着关键作用。从数学上讲,这是一个非常简单的操作:模型输出 logit 简单地除以温度:
-
temperature = 1:将 logits 除以 1 对 softmax 输出没有影响。 -
temperature < 1:较低的温度通过锐化概率分布使模型更具置信度和确定性,从而产生更可预测的输出。 -
temperature > 1:温度越高,概率分布越柔和,生成的文本就越随机——有些人称之为模型_“创造力_”。
调整温度,看看如何在确定性和多样化输出之间取得平衡!
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









