






 本文探讨了Q值(预期回报估计)和策略(概率分布)在强化学习和蒙特卡洛树搜索(MCTS)中的关键角色。Q值用于评估动作的预期效果,策略指导搜索过程并根据Q值调整。两者在MCTS中相互影响,共同优化搜索策略以最大化预期回报。
本文探讨了Q值(预期回报估计)和策略(概率分布)在强化学习和蒙特卡洛树搜索(MCTS)中的关键角色。Q值用于评估动作的预期效果,策略指导搜索过程并根据Q值调整。两者在MCTS中相互影响,共同优化搜索策略以最大化预期回报。
Q值(预期回报)和P(概率分布)在强化学习和MCTS中共同作用于指导搜索过程和制定策略以最大化预期回报。
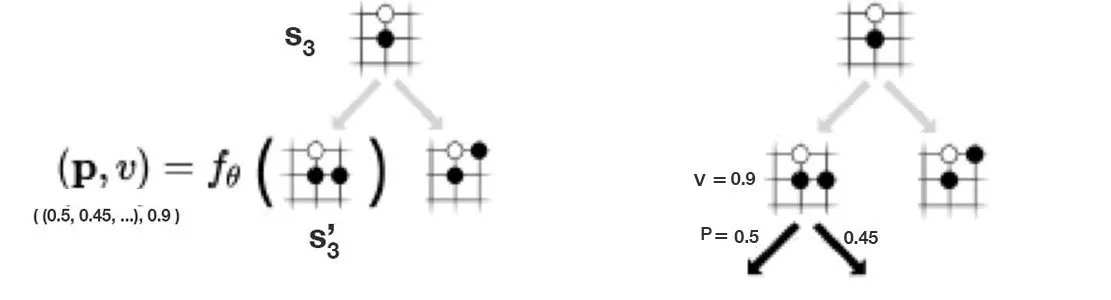
Q 值(Q-Value)
- 定义:在强化学习和MCTS的上下文中,
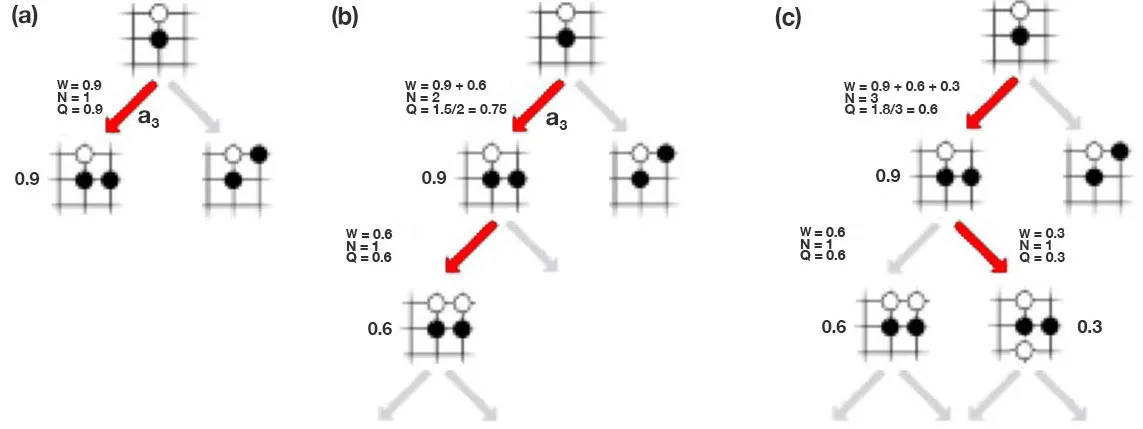
Q值通常用来表示在给定状态下采取某个特定动作后所获得的预期回报(reward)。这是通过多次模拟从当前状态开始到结束状态,并对这些模拟的回报进行平均来估计的。 - 作用:
Q值用于评估在当前状态下执行特定动作的“好坏”。 - 更新:每次通过模拟获得新的回报时,
Q值会根据新的信息进行更新,通常是通过加权平均或增量式更新来实现的。
P 值(或 π,策略 Policy)
- 定义:
P(或π)代表策略,即在给定状态下选择动作的概率分布。在MCTS中,这通常表示为每个可能动作的选择概率。 - 作用:策略指导搜索过程,在搜索树的每个节点上决定应该优先探索哪些动作。良好的策略应该在探索未尝试过的动作和利用已知高回报动作之间找到平衡。
- 更新:策略的更新通常是通过增加那些在过去产生高回报的动作的选择概率来实现的。这可以通过诸如上置信界(UCB)等算法来完成,该算法在选择下一个要探索的节点时同时考虑
Q值和探索次数。
区别和联系
- 区别:在MCTS的上下文中,
Q值是一个与特定的状态-动作对相关联的预期回报的估计;而P(或π)是一个概率分布,描述了在给定状态下选择不同动作的可能性。 - 联系:在MCTS中,
Q值和P(或π)是紧密相关的。策略P用于决定在搜索过程中选择哪些动作进行探索,而Q值则提供了这些动作的质量评估。策略的更新通常会考虑Q值的信息,以便在未来更好地指导搜索。因此,Q值和P(或π)在MCTS中是相互依赖、相互影响的。

















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









