







基于 YOLOv12 的车牌颜色识别与车型和车身颜色识别任务,涉及图像分类、目标检测和深度学习模型的应用。本文将从原理、框架、训练和推理等方面进行介绍,并提供实现该任务所需的关键代码。

1. 原理
YOLO(You Only Look Once)系列模型是目前目标检测任务中最为高效且实时的模型之一。YOLOv12(假设是 YOLO 系列的一个版本,YOLO 系列每次更新都强化了检测精度和速度)基于卷积神经网络(CNN),能够在单次前向推理中同时进行物体检测和分类,具有快速推理的优势,适用于实时应用。
对于车牌颜色识别、车型和车身颜色识别任务,YOLOv12可以通过以下几个步骤实现:
- 车牌颜色识别:通过目标检测算法定位车牌区域,然后根据车牌区域的颜色进行分类。
- 车型识别:模型需要识别车牌区域附近的车的类型,通常包括轿车、SUV、卡车等类别。
- 车身颜色识别:车身的颜色也是目标检测任务中的一个类别,需要通过车牌区域周围的车身区域进行分类。
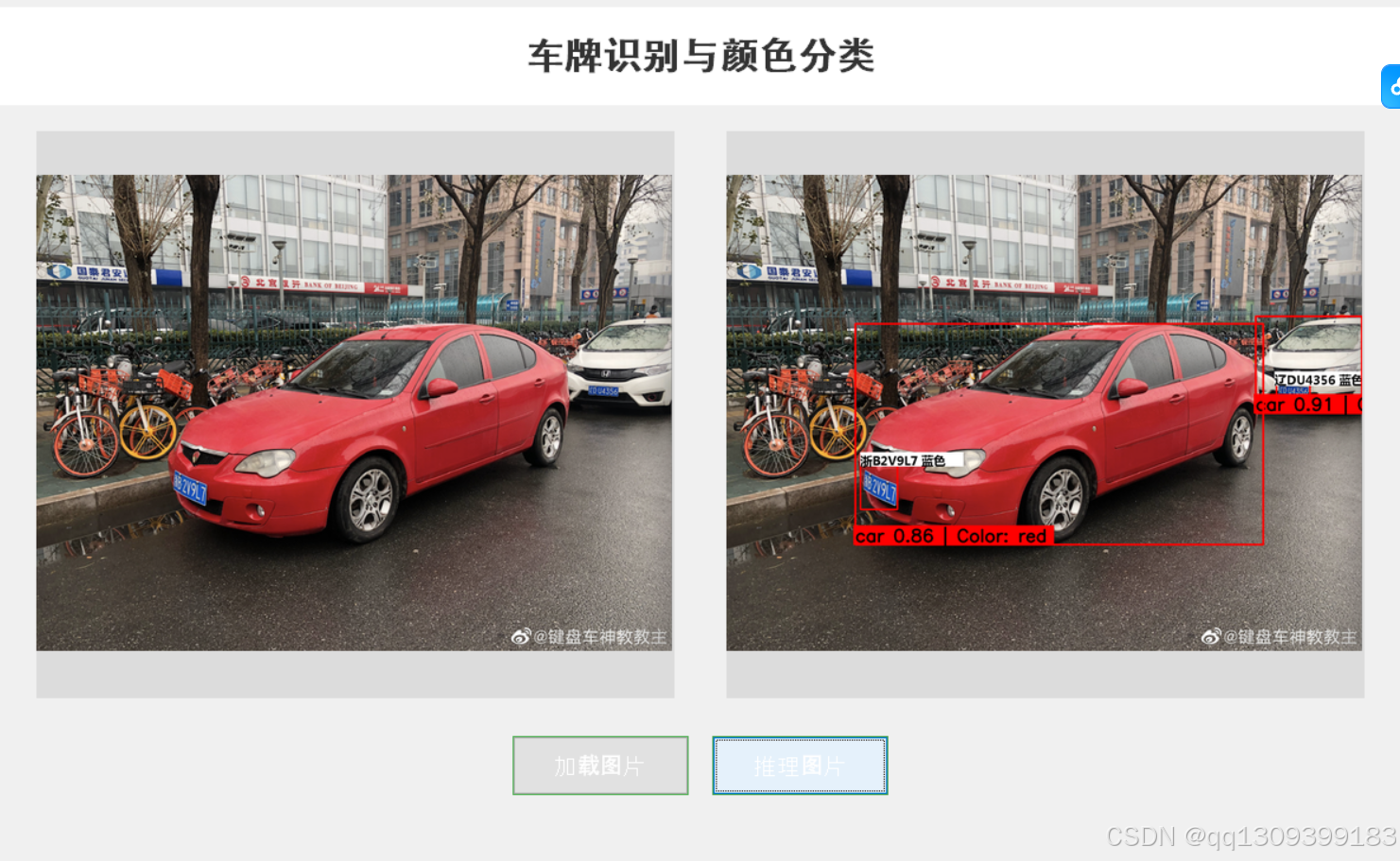
该任务的框架通常包含以下几个主要步骤:
- 数据准备:收集并标注车牌、车型和车身颜色数据。数据集需要包括车牌颜色、车型分类和车身颜色标签。
- 数据增强:在训练过程中使用数据增强技术(如裁剪、旋转、平移等)来增加模型的泛化能力。
- 训练:基于 YOLOv12 模型进行训练,使用标注好的车牌颜色、车型和车身颜色数据集。
- 推理:通过训练好的模型,进行实时的车牌颜色识别、车型识别和车身颜色识别。

3. 训练
在训练模型之前,需要配置好 YOLOv12 模型,并进行必要的数据预处理。假设我们使用 PyTorch 进行训练,首先需要安装相关的依赖包:
pip install torch torchvision yolov5
3.1 数据集处理
数据集应该包括车牌颜色、车型和车身颜色的标签。每张图片需要标注出车牌的位置和车身颜色、车型标签。数据集的标注格式通常是 YOLO 标准的格式,即每个对象用一个矩阵表示:[class_id, x_center, y_center, width, height]。
3.2 配置 YOLOv12
假设 YOLOv12 是继承自 YOLOv5 的架构,我们可以使用以下代码来配置训练参数:
import torch
from yolov5 import YOLOv5
# 加载 YOLOv12 模型
model = YOLOv5('yolov12.pt') # 你需要提供训练好的 yolov12 权重文件
# 配置训练数据和超参数
train_data = 'path_to_train_data'
val_data = 'path_to_val_data'
# 设置训练超参数
params = {
'epochs': 50,
'batch_size': 16,
'img_size': 640,
'data': 'data.yaml', # 数据配置文件,定义了类别和路径
'weights': 'yolov12.pt',
'device': 'cuda', # 使用GPU训练
}
# 开始训练
model.train(data=train_data, epochs=params['epochs'], batch_size=params['batch_size'], imgsz=params['img_size'])
3.3 训练过程
训练过程中,模型会进行多次前向和反向传播,更新网络中的权重以最小化损失函数。训练过程中,我们可以监控训练集和验证集的损失,以确保模型的收敛。
4. 推理
训练完成后,我们可以使用训练好的模型进行推理,识别车牌颜色、车型和车身颜色。推理过程分为以下几个步骤:
- 加载模型:加载训练好的 YOLOv12 权重。
- 图像预处理:对输入图像进行预处理,包括归一化、调整尺寸等。
- 进行推理:将处理后的图像输入到模型中,得到车牌区域、车型和车身颜色的预测结果。
- 后处理:对模型的输出进行后处理,筛选出可信度高的检测结果。
4.1 关键代码
import torch
import cv2
import numpy as np
# 加载训练好的模型
model = YOLOv5('yolov12.pt') # yolov12 权重路径
# 输入图像路径
image_path = 'test_image.jpg'
# 读取图像
img = cv2.imread(image_path)
# 预处理图像(调整大小,归一化等)
img_resized = cv2.resize(img, (640, 640))
# 使用模型进行推理
results = model(img_resized)
# 获取推理结果
boxes = results.xywh[0] # 获得预测的边界框(x_center, y_center, width, height)
confidences = results.conf[0] # 获得预测的置信度
class_ids = results.class[0] # 获得预测的类别ID
# 输出检测结果
for i, box in enumerate(boxes):
x, y, w, h = box
confidence = confidences[i]
class_id = class_ids[i]
# 如果置信度高于某个阈值,则认为是有效预测
if confidence > 0.5:
print(f"车牌位置: {x}, {y}, {w}, {h}, 置信度: {confidence}, 类别ID: {class_id}")
# 可视化检测框
cv2.rectangle(img, (int(x-w/2), int(y-h/2)), (int(x+w/2), int(y+h/2)), (0, 255, 0), 2)
# 显示检测结果
cv2.imshow('Detection Result', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
5. 总结
基于 YOLOv12 进行车牌颜色识别与车型和车身颜色识别的任务,核心的流程包括数据预处理、模型训练和推理过程。YOLOv12 在实时检测任务中展现出了强大的性能,能够在单次推理中同时完成车牌检测、车型识别与车身颜色识别。
通过这种方式,可以实现高效的车牌识别与车辆分类任务,适用于智能交通、停车场管理等多个实际场景。


















 2848
2848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









