









文章目录
一 摘要
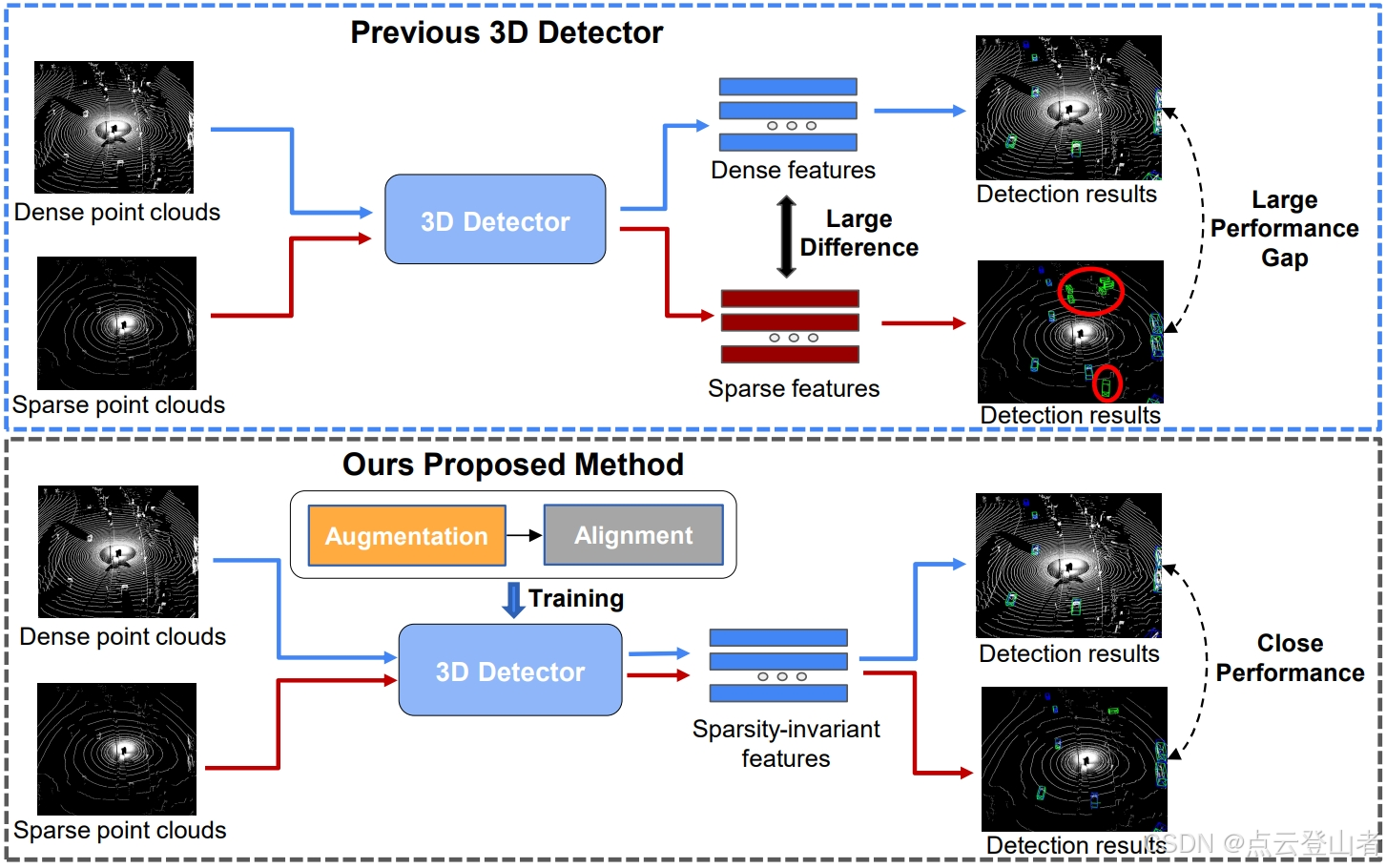
在自动驾驶中,3D 目标检测对于准确识别和跟踪目标至关重要。尽管针对这项任务的各种技术不断发展,但其中大多数技术都存在一个明显的缺点——在检测未见过域中的对象时,它们的性能会大幅下降。在本文中,提出了一种提高单个域上 3D 目标检测泛化能力的方法。主要专注于从单个源域泛化到具有不同传感器配置和场景分布的目标域。为了从单个源域中学习稀疏性不变特征,作者选择性地将源数据采样到特定的光束,使用由当前检测器确定的置信度分数来确定对检测器至关重要的密度。随后,采用师生框架来对齐不同点云密度的鸟瞰图 (BEV) 特征。还利用特征内容对齐 (FCA) 和基于图形的嵌入关系对齐 (GERA) 来指示检测器与域无关。广泛的实验表明,与其他基线相比,本文的方法表现出卓越的泛化能力。此外,文章方法甚至优于某些可以适配目标域数据的域自适应方法。
二 资源
文章:Improving Generalization Ability for 3D Object Detection by Learning Sparsity-invariant Features
日期:2025
三 内容
1)摘要
在自动驾驶中,3D 目标检测对于准确识别和跟踪目标至关重要。尽管针对这项任务的各种技术不断发展,但其中大多数技术都存在一个明显的缺点——在检测未见过域中的对象时,它们的性能会大幅下降。在本文中,提出了一种提高单个域上 3D 目标检测泛化能力的方法。主要专注于从单个源域泛化到具有不同传感器配置和场景分布的目标域。为了从单个源域中学习稀疏性不变特征,作者选择性地将源数据采样到特定的光束,使用由当前检测器确定的置信度分数来确定对检测器至关重要的密度。随后,采用师生框架来对齐不同点云密度的鸟瞰图 (BEV) 特征。还利用特征内容对齐 (FCA) 和基于图形的嵌入关系对齐 (GERA) 来指示检测器与域无关。广泛的实验表明,与其他基线相比,本文的方法表现出卓越的泛化能力。此外,文章方法甚至优于某些可以适配目标域数据的域自适应方法。
2)创新点
①提出了一种提高单源域上 3D 目标检测泛化能力的方法。
②引入了一种增强策略,根据探测器的置信度将点云下采样到特定的稀疏度。
③开发了基于图的嵌入关系对齐以及特征内容对齐,以保持域不变表示学习的高级关系和低级内容的一致性。
④广泛的实验表明,文章方法在泛化方面优于所有基线。此外,它还可以与 UDA 技术兼容,从而在目标域上实现更好的性能。
3)算法结构
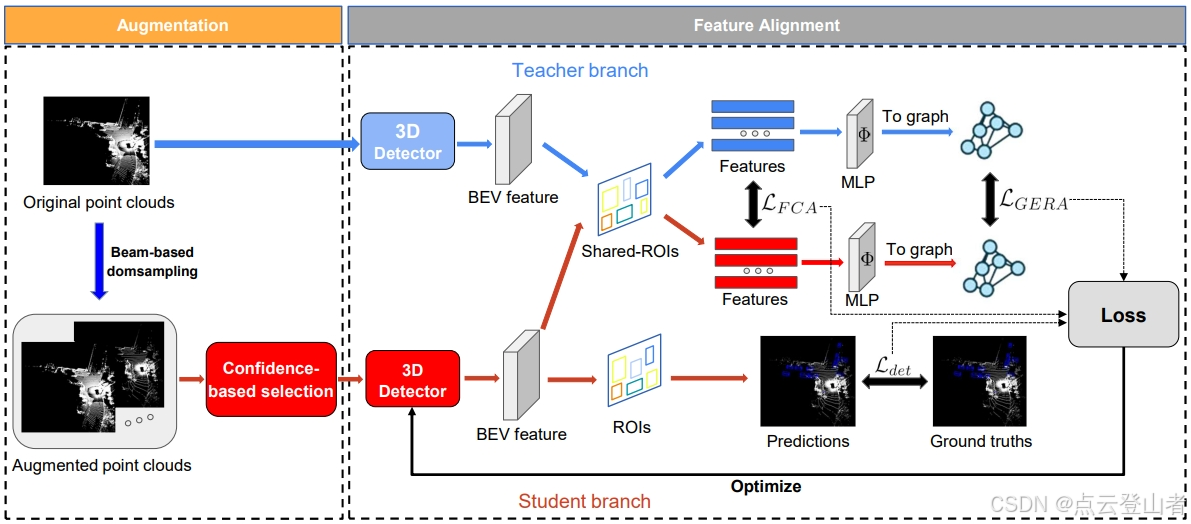
最初,将原始点云下采样为各种密度,然后根据探测器的置信度选择一个。为了了解与域无关的特征,将特征内容对齐 (FCA) 应用于每个共享感兴趣区域 (ROI) 的 BEV 特征,以对齐低级内容一致性。随后,编码特征受到基于图的嵌入关系对齐 (GERA) 的约束,以保持高水平的关系一致性。蓝色和红色流分别说明了教师和学生模型的处理管道。
A 点云下采样
从单个源域学习可泛化特征是一项具有挑战性的任务,因为文章只能在相同传感器配置和相似场景分布下捕获的点云中获取知识。为了应对这一挑战,可以利用文章对 LiDAR 传感器的先验知识来模拟各种密度的点云 。
a1 基于线束的下采样
首先,将笛卡儿积坐标转换为球面坐标:
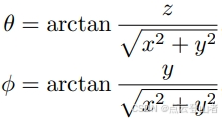
其中,θ和![]() 分别为天顶角和方位角。利用已知的激光雷达线束先验信息,使用kmeans算法对天顶角θ进行线束聚类,使用为每个 LiDAR 线束获得的标签,将原始点云下采样为对应于不同线束束的特定类型的点云变得简单明了。
分别为天顶角和方位角。利用已知的激光雷达线束先验信息,使用kmeans算法对天顶角θ进行线束聚类,使用为每个 LiDAR 线束获得的标签,将原始点云下采样为对应于不同线束束的特定类型的点云变得简单明了。
a2 基于置信度的采样结果选择
在将原始点云下采样为具有不同密度的点云后,需要一种策略来选择其中一个点云。文章观察到,随机选择一个可能会导致各种密度下的性能不平衡。这是因为随机选择有时可能导致选择模型已经熟悉的密度,从而使模型偏离泛化的预期目标。为了解决这个问题,文章提出了基于置信度的选择,以选择对当前探测器最重要的密度。给定原始点云 Ps 和增强点云集Pa,文章可以在Pa上推断文章的探测器,通过计算每个预测对象与实际结果之间的交并比 (IoU) 来获得第 i 个增强点云的匹配对象,其中 Na 是匹配对象的数量。请注意,匹配过程将每个预测对象与具有最大 IoU 的 ground truth 对象相关联。基于匹配的对象集合,文章可以使用以下方程计算每个增强数据的置信度:
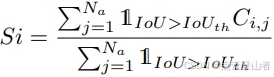
其中,![]() 代表第i个增强点云中第j个对象的置信度。
代表第i个增强点云中第j个对象的置信度。![]() 是第i个增强点云对应的最终置信度分数。IoU代表对象的交并比,IoUth代表阈值。为了在各种密度的数量和置信度之间取得平衡,文章还根据文章已经为每种光束类型选择的数据比例对置信度得分 Si 进行了加权。随后,文章选择得分最低的增强点云作为文章的增强域。下图说明了文章基于置信度的选择策略的管道。
是第i个增强点云对应的最终置信度分数。IoU代表对象的交并比,IoUth代表阈值。为了在各种密度的数量和置信度之间取得平衡,文章还根据文章已经为每种光束类型选择的数据比例对置信度得分 Si 进行了加权。随后,文章选择得分最低的增强点云作为文章的增强域。下图说明了文章基于置信度的选择策略的管道。
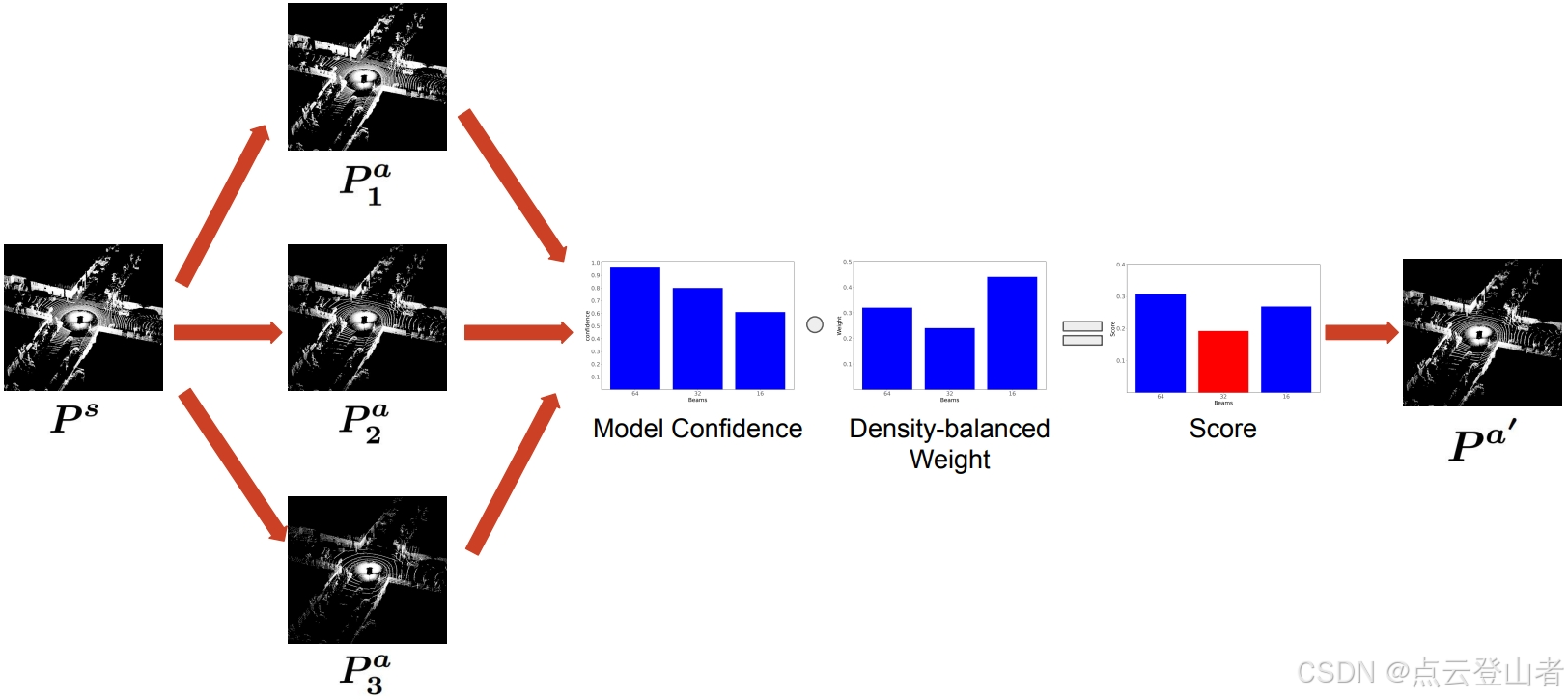
在增强域和原始域中,文章采用师生框架进行稀疏不变特征学习。为了确保文章的教师模型在原始域上的准确性并指导学生模型在各种密度水平上泛化,文章将原始数据提供给教师模型,将增强数据提供给学生模型。请注意,初始教师模型和学生模型是使用文章建议的增强在原始源域上进行预训练的。
B FCA
采用 student-teacher 框架的目的是训练检测器学习域不变特征。由于原始域和增强域之间的唯一区别是 LiDAR 线束数,因此使用原始数据馈送的教师模型和使用增强数据馈送的学生模型生成的特征应该相似。为此,文章可以直接将 student detector 和 teacher detector 之间的特征内容对齐。给定学生和教师模型生成的 BEV 特征,文章使用共享 ROI 映射从两组 BEV 特征中提取实例提示特征。这会产生学生实例提示特征![]() 和教师实例提示功能
和教师实例提示功能![]() ,其中 Nr 是区域提示的数量。H 和 W 表示区域提示框的高度和宽度,M 是特征维度。然后,文章可以通过以下公式轻松对齐这些实例提案功能:
,其中 Nr 是区域提示的数量。H 和 W 表示区域提示框的高度和宽度,M 是特征维度。然后,文章可以通过以下公式轻松对齐这些实例提案功能:
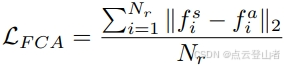
其中,![]() 和
和![]() 分别是Fs和Fa的第i个特征值。
分别是Fs和Fa的第i个特征值。
C GERA
通过采用特征内容对齐,文章强制模型生成相似的特征,而不管密度如何变化。但是,每个实例提示特征对之间的关系保持一致也很重要,因为文章只更改了原始点云的线束类型。
为了衡量成对关系的差异,文章可以将每个提案的特征转换为全连接图。这使文章能够专注于分别计算由 student 实例提示特征和 teacher 实例提示特征构建的两个图之间的边缘差异。为了从实例提示特征构建一个图,文章首先将三维特征 fs_i 和 fa_i 转换为一维嵌入,方法是将它们通过多感知层 (MLP) 来捕获每个提示的高级含义。这里,fs_i 和 fa_i 分别代表上面提到的 Fs 和 Fa 的第 i 个特征。然后构建图形,其中 edges 表示嵌入之间的余弦相似性。该过程可以描述为:
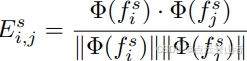
其中 Es_i,j 表示教师的第 i 个嵌入和第 j 个嵌入之间的边缘,Φ是用于从三维特征中提取高级嵌入的 MLP。
给定教师和学生的边 Es_i,j 和 Ea_i,j,然后文章利用 Gromov-Wasserstein 差异 来定义文章基于图的嵌入关系对齐损失,如以下方程:
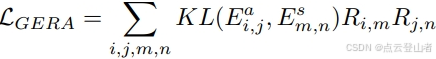
其中 KL 表示 Kullback-Leibler 散度,用于测量图形之间边的距离。R 是关系矩阵,表示每个提案之间的差值。
除了完全匹配的边缘对之外,包含相似实例提案的边缘对之间的关系也应在图形中保持一致。为了解决这个问题,文章最初通过计算每个实例提示框之间的中心、大小和方向的差异来构建一个差异矩阵。然后,差异矩阵 D 公式化如下:
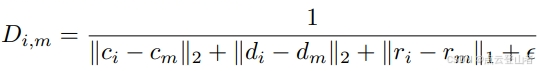
其中,c, d, r分别为中心、大小和方向,![]() 为差异值,用于避免分母出现0值。
为差异值,用于避免分母出现0值。
计算完差异矩阵后,关系矩阵可定义为:
![]()
其中 I 是单位矩阵,保留完全匹配的边缘对的权重,λ 控制差异矩阵的重要性。
D 总体损失函数
在师生框架中,文章冻结了教师模型的参数,而学生模型的参数则由原始检测损失 L_det、特征内容对齐损失 L_FCA 和基于图的嵌入关系对齐损失 L_GERA 进行更新。这可以表示为以下公式:
![]()
其中 α 和 β 是用于平衡两个对齐的超参数。
通过这两个对齐方式,文章的目标是指导学生检测器对齐低级内容以及增强域和原始域之间的高级关系,以进行稀疏不变特征学习。
4)实验
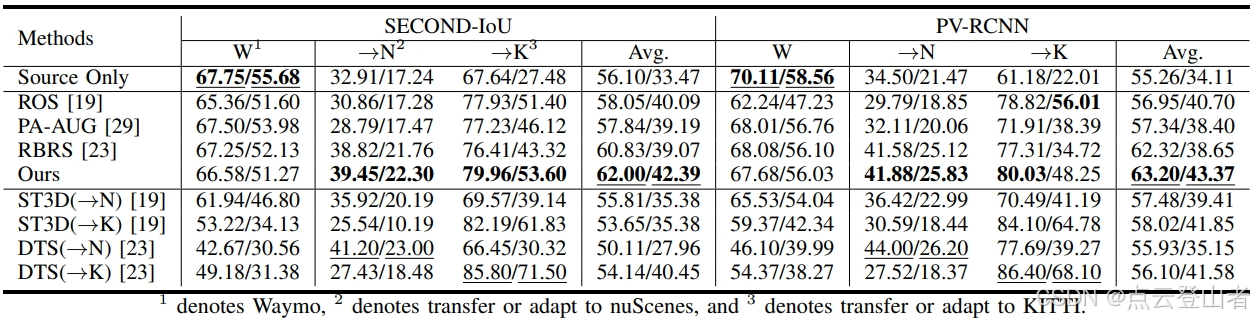
上表表示,使用两种不同的检测主干的 Waymo 数据集的泛化结果。报告的 AP 是 KITTI 的中等情况和其他数据集的总体结果。所有基线的最佳分数用下划线标出,而不包括域适应 (DA) 方法的最佳分数以粗体表示。
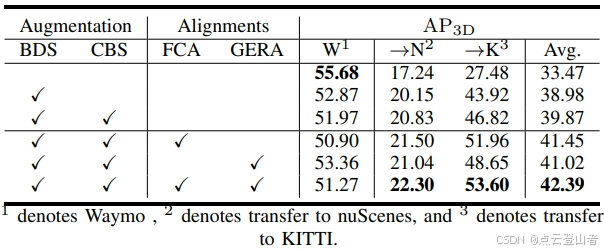
上表表示消融研究。BDS 是指基于波束的下采样,而 CBS 是基于置信度的选择策略。最佳分数以粗体显示。
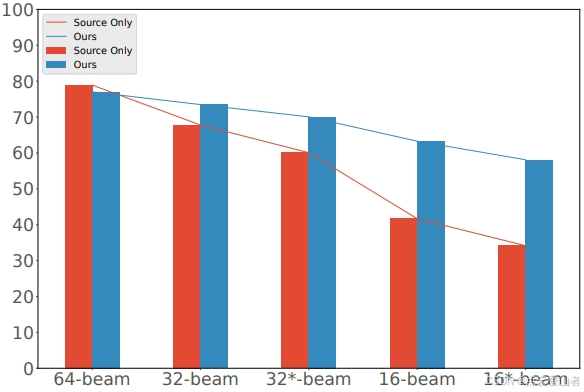
KITTI 数据集在各种点云密度下的性能。Source Only (仅源) 表示在其他低线束验证集上对在原始数据集(64 光束)上训练的模型进行直接评估。Ours 表示检测器是使用所提出的方法进行训练的。
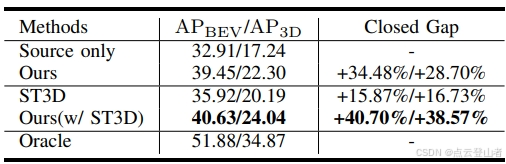
Waymo→nuScenes 设置的域适配。最佳分数以粗体表示。
5)结论
在本文中,文章提出了一种方法来增强基于 LiDAR 的 3D 目标检测的泛化能力,使探测器对点云密度的变化更加鲁棒。文章引入了基于置信度的下采样,以根据置信度分数模拟各种密度下的点云。文章还采用了学生-教师框架和文章提出的对齐损失,以保持低级内容的一致性和高级关系的一致性。广泛的实验表明,与其他基线相比,文章的方法表现出更好的泛化能力。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











