







 ACMMM2020会议上提出了一种名为MISA的多模态情感分析框架,旨在弥合不同模态之间的表示差距。MISA通过学习模态不变和模态特有表示来促进有效的融合。模型包含两个子空间学习,一个用于捕捉共性,另一个用于捕获模态独特性。通过Transformer进行模态融合,并采用相似性损失、差异损失、重构损失和任务损失进行联合训练。实验结果显示该方法在多模态情感分析任务上表现出色。
ACMMM2020会议上提出了一种名为MISA的多模态情感分析框架,旨在弥合不同模态之间的表示差距。MISA通过学习模态不变和模态特有表示来促进有效的融合。模型包含两个子空间学习,一个用于捕捉共性,另一个用于捕获模态独特性。通过Transformer进行模态融合,并采用相似性损失、差异损失、重构损失和任务损失进行联合训练。实验结果显示该方法在多模态情感分析任务上表现出色。
文章目录
1.前言
**ACM MM 2020 **
多模式情感分析是一个活跃的研究领域,它利用多模态信号对用户生成的视频进行情感理解。 然而,信号的异质性造成了分布模态的差距。
在本文中,我们旨在学习有效的模态表示,以帮助融合过程。 我们提出了一个新颖的框架MISA,该框架将每个模态投影到两个不同的子空间。 第一个子空间是模态不变的,其中跨模态的表示学习它们的共性并减少模态差距。
第二个子空间是特定于模态的,它对每个模态是私有的,并捕获其特征。 这些表示提供了多模态数据的整体特征,该特征用于融合来进行预测。
模型图如下:
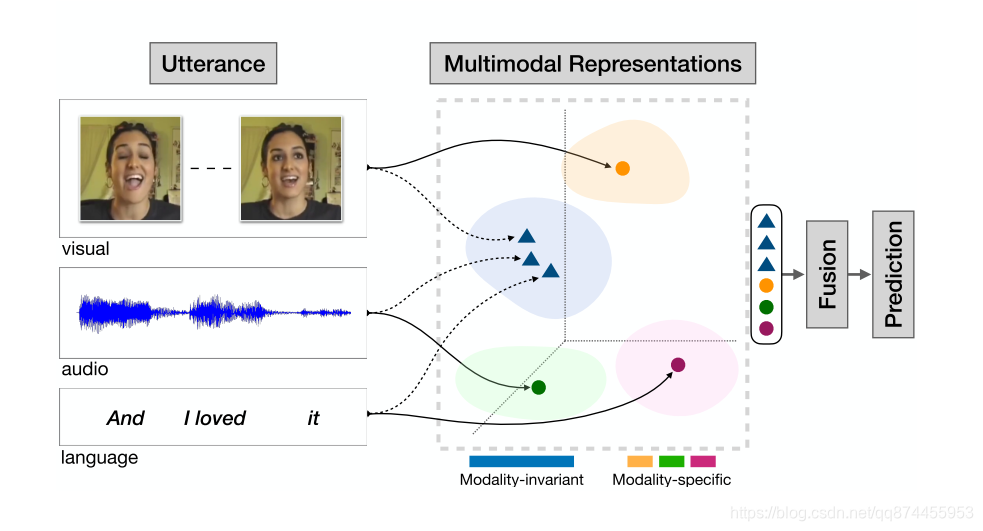
2.模型结构
模型具体结构如图:
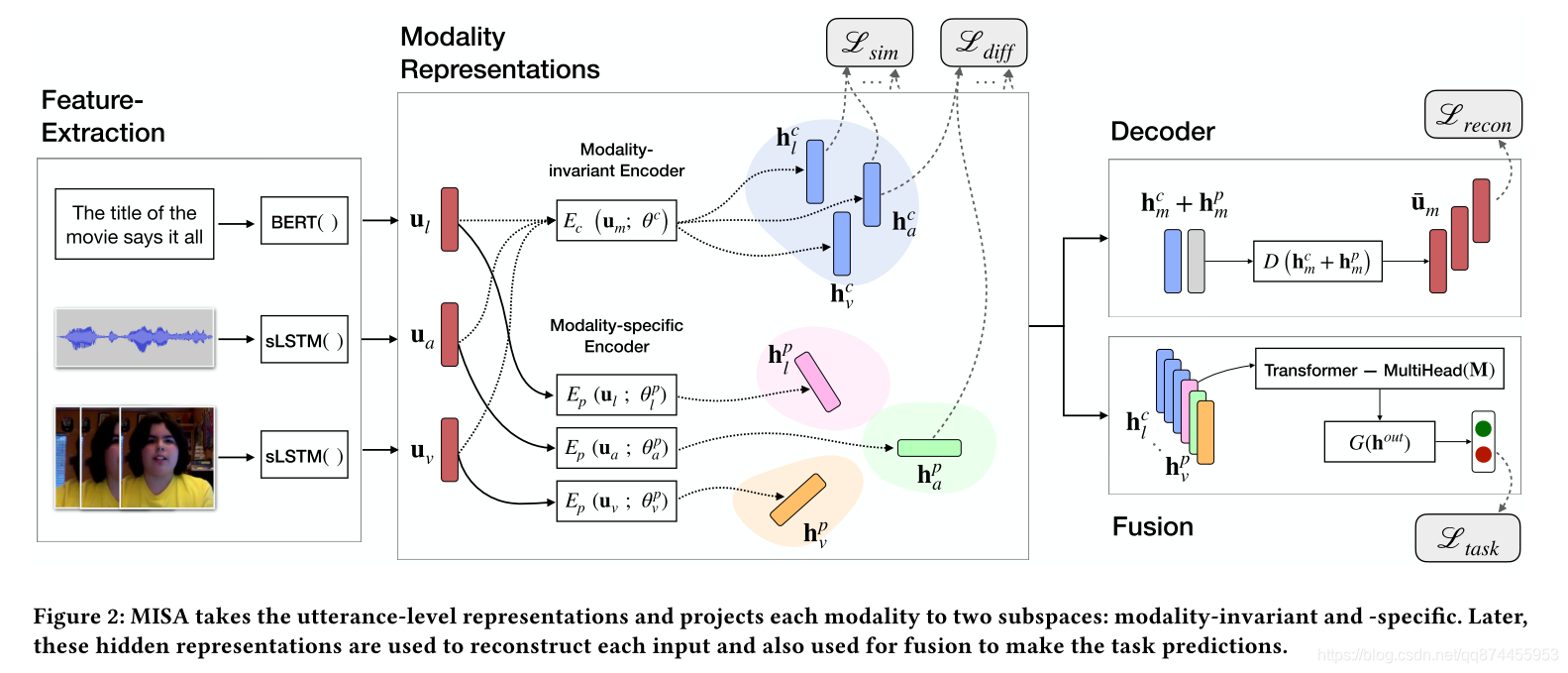
2.1 Modality Representation Learning
2.1.1 Utterance-level Representations
每一个模态 都提取出序列特征, 我们把这个seq 通过一个LSTM, 并且LSTM的 最后一个隐层接一个全连接映射到同一维度
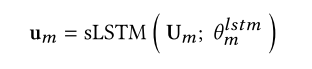
2.1.2 Modality-Invariant and -Specific Representations
我们把同一个特征 映射到两个不同的特征空间中, 一个是模态不变特征, 一个是模态特有特征。
作者认为 模态不变 和 模态特有特征 提供了有效融合所必需的整体特征。 学习这些表示是其工作的主要目标。
主要通过auto encoder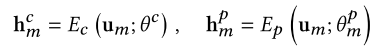
2.2 Modality Fusion
用Transformer 的encoder 结构
把我们之前提取的6个特征变成一个seq
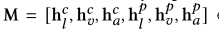
2.3 Learning
损失函数包括
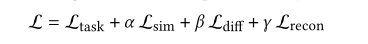
2.3.1 Similarity Loss
最小化相似性损失可减少每种模态的共享表示之间的差异。
我们使用中心距误差
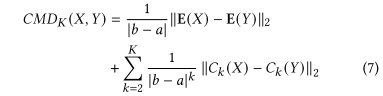
loss 定义如下:
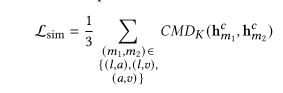
- 我们选择CMD而不是KL散度或MMD,因为CMD是一种流行的度量,且无需花费昂贵的距离和核矩阵计算
2.3.2 Difference Loss
这种损失是为了确保模态不变和模态特有的表示捕获输入的不同方面。
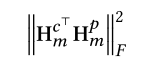
用的是Frobenius 范数来算两个 矩阵的 相关性

最终diff loss 定义如下
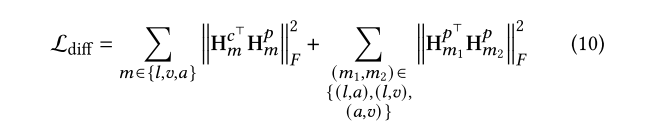
模态间的diff 和 模态内的 diff 都计算进去了
2.3.3 Reconstruction Loss
此损失主要是限制encoder 损失太多信息了
定义如下
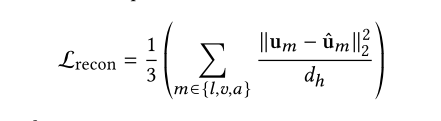
其中
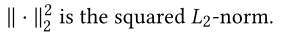
2.3.4 Task Loss
这个就是我们下游任务的预测损失了
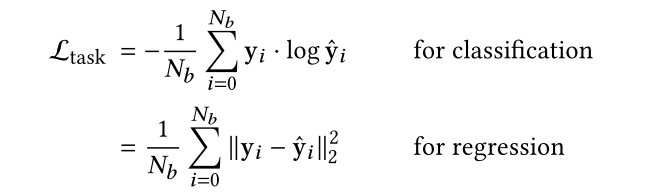
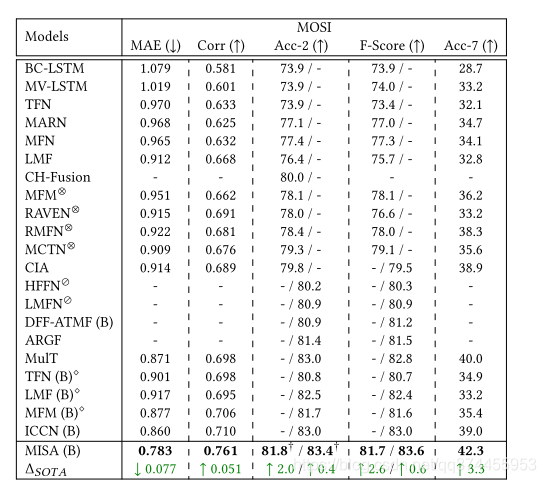
3. 实验
效果挺好

















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









