









在文本数据集的构建过程中,数据预处理至关重要。该阶段的主要目标是剔除数据集中的噪声、冗余信息、无关数据,以及潜在有害内容。不合适的数据元素可能对语言模型的训练效果产生不利影响。本节将系统地探讨各种数据预处理策略,旨在提升数据集的整体质量。下图展示了 LLMs预训练所使用数据的预处理流程。
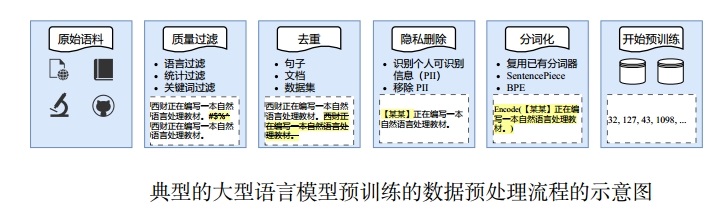
LLMs的预训练数据预处理流程主要涵盖质量过滤(Quality Filtering)、去重(De-duplication)、隐私删除(Privacy Redaction)及分词化(Tokenization)等四个关键步骤。
1.质量过滤
质量过滤的主要目的是剔除低质量数据,确保训练集的可靠性和模型性能的有效性。作为数据预处理流程的一部分,质量过滤对于提升 LLMs预训练阶段的训练质量和减少模型偏见具有关键作用。
常见的质量过滤方法包括基于分类器的方法和基于启发式的方法。
(1)基于分类器的方法
这种方法利用一个针对高质量文本训练的分类器来识别和排除低质量的数据。该分类器通常使用从高质量数据源(例如维基百科)精选的数据作为正样本,将待评估数据作为负样本,进而训练一个二分类器,该分类器生成评分用于衡量每个数据实例的质量。然而,这种方法存在局限性。它可能不慎过滤掉方言、口语和社会文本中的高质量信息,从而引入预训练语料库的偏见,限制数据多样性。
(2)基于启发式的方法
这种方法通过设计一系列规则或策略来识别和删除低质量的数据,这些规则或策略基于对数据特性的理解和分析,可以提高数据的质量和可用性。启发式规则通常包括:语言过滤、指标过滤、统计过滤、关键词过滤。
2.去重
语料库中重复的数据元素可能削减数据整体的多样性,并导致模型训练不稳定。去重通常在三个层次上进行:句子级、文档级和数据集级。句子级去重的目的是消除包含重复词语和短语的句子,以防止在模型训练中引入冗余模式。在文档级,主要通过比较文档间的表面特征(例如词语和 n-gram 的重叠)来识别和删除重复或高度相似的文档。数据集级去重主要是为了防止训练集和评估集之间的数据重叠,避免数据污染。综合这三个层次的去重策略,可以有效提升模型的训练质。在这个过程中,一般可以采用 MinHash 和 SimHash等算法检测文本之间的相似度。
3.隐私删除
由于预训练文本数据主要来源于网络,可能涉及敏感或个人信息的用户生成内容,因此存在隐私泄露风险。为解决这一问题,必须从预训练语料库中去除个人可识别信息(PII)。一种有效的方法是使用基于规则的方法进行检测和删除,例如通过关键词检测来识别并移除姓名、地址和电话号码等 PII。此外,有研究表明,语言模型对隐私攻击的脆弱性也与预训练语料库中重复的PII 数据有关。
4. 分词化
分词化是将原始文本分解为一系列单独的词元,以供后续的语言模型训练使用。可以直接使用现有分词器,如 GPT-2 的分词器用于 OPT 和 GPT-3,而当语料库涵盖多个领域、语言和格式时,专门针对预训练语料库定制的分词器可能带来更多优势。例如,近期的 LM研究中, SentencePiece被用于开发专门为预训练语料库设计的分词器。字节对编码(BPE)算法是多语言语料库常用的分词算法,被应用在 GPT-2 和 LLaMA 等模型中。除了上述的关键步骤之外,还有一些实用技术可以用在数据预处理中,包括
(1)编码检测:尽管大部分在线文档均以 UTF-8 编码,也有少量文档采用其他编码(如 GB2312),因此有必要进行编码检测并实现转码转化;
(2)语言检测:在采集数据的过程中,可以使用 pycld2等工具识别自然语言的种类;
(3)数据标准化:包括拼写修正和移除停用词等。特别地,为了构建简体中文语料,常常需要将繁体中文文本转换成简体中文。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









