







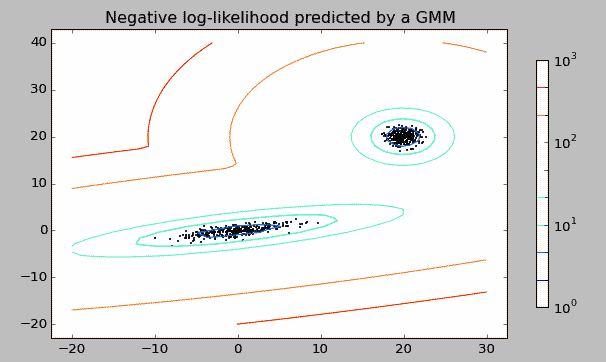
高斯混合模型,如下图是一个观测数据集,数据集明显分为两个聚集核心,我们通过两个单一的高斯模型混合成一个复杂模型来拟合数据。这就是一个混合高斯模型。而求解这个混合高斯模型的参数所使用的算法就是最大期望,即Expectation Maximization。下面就先后介绍这两种算法。
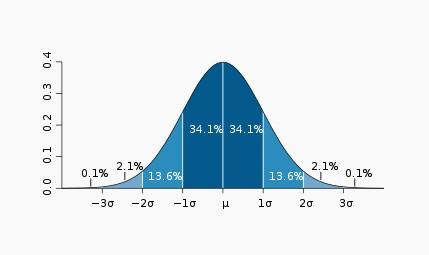
如下为标准正态分布:
多维高斯分布模型下概率密度函数如下:
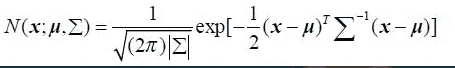
公式中,x是维度为d的列向量,u是模型期望,Σ是模型方差。在实际应用中u通常用样本均值来代替,Σ通常用样本方差来代替。很容易判断一个样x本是否属于类别C。因为每个类别都有自己的u和Σ,把x代入公式中,当概率大于一定阈值时我们就认为x属于C类。通过增加 Model 的个数,改变权重的计算方法等,我们可以逼近任意连续的概率密度分布

GMM是一种聚类算法,每个component就是一个聚类中心。GMM与k-means聚类相似,也使用迭代算法计算并最终收敛到局部最优,但高斯混合模型在各类尺寸不同、聚类间有相关关系的的时候可能比k-means聚类更合适;GMM 是基于概率密度函数进行学习,所以除了在聚类应用外,还经常应用于密度检测(density estimation),在图像识别领域以及语音提取领域都有部分应用。另外, k-means 的结果是每个观测点一定被分类到某个数据集类别中,而 GMM 则给出的是被分类到不同数据集类别中的概率(即软分类soft assignment)
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
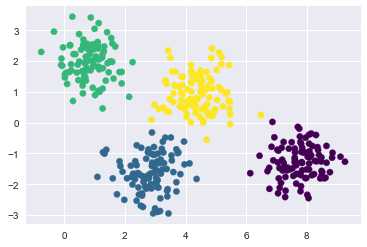
#构建示例数据集
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples=400, n_features=2,centers=4,cluster_std=0.60, random_state=0)#random_state每次产生的随机数固定
X = X[:, ::-1] #为了更好地绘制图像,从后往前逆序
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=4).fit(X)
labels = gmm.predict(X)
plt.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap='viridis')
最大期望算法EM(Expectation Maximization):
在开始最大期望算法原理的推导之前,我们先看一个例子。假设现在有100个人的身高数据,且这个100个数据是随机抽取的。通常,对于任意一维数据都可以使用高斯分布来拟合,基于这样的假设,男性和女性的身高满足不同参数下的高斯分布。给定初始参数值以后(均值和方差)我们就可以粗略的给这100个数据进行分类。然后利用这些已经分好男女类别的身高数据重新估计男女生身高的高斯分布参数值,接着归属于这两个分布的概率也发生变化,继续更新并多次迭代直到分布参数不再变化为止。



参考文献:点击打开链接















 89
89

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









