







神经网络中,常用的归一化策略有BN(Batch Normalization), GN(Group Normalization),, LN(Layer Normalization), IN(Instance Normalization),WN(Weight Normalization).
BN是针对单个神经元进行归一化操作,多用于batch size大的CNN网络。使用batch_size数量的 样本的均值和方差,近似整体样本的均值和方差,独立地规范每一个输入维度x。也有人说, BN输出的是标准正态分布。BN使用的这样均值、方差近似,给神经网络引入了噪声,提高了泛化性。BN对batch_size和样本的随机要求相对严苛。
GN是对通道进行分组,每个组做归一化操作。GN可以看作是LN与IN之间的一种折中方案。把当前层的所有通道都作为一个组的时候,GN结果就是LN。如果把所有通道N分为N个组里,GN结果就是IN。
LN是对当前神经网络层单个训练样本的所有神经元的输入进行计算,利用统一的均值和方差,对数据进行归一化。但是,对不同类别的特征使用同样的限定,会降低网络性能。
IN是对单个图像进行的归一化操作。常用于风格迁移等。
WN是对神经网络的权重进行归一化,不直接依赖于输入样本。虽然是对权重w进行限定,但限定的结果还是反应到y=w*x+b的y中。

四种归一化的理解:
BatchNorm:batch方向做归一化,计算N*H*W的均值
LayerNorm:channel方向做归一化,计算C*H*W的均值
InstanceNorm:一个channel内做归一化,计算H*W的均值
GroupNorm:先将channel方向分group,然后每个group内做归一化,计算(C//G)*H*W的均值
LN, IN, GN都与batch无关。
BN,LN和IN的所有方法都学习了一个每通道的线性变换,来补偿表示能力的丢失:
y i = γ x i + β y_i=\gamma x_i + \beta yi=γxi+β, γ \gamma γ, β \beta β是可训练的比例和位移。
这几个方法主要的区别就是在:
- BN是在batch上,对N、H、W做归一化,而保留通道 C 的维度。BN对较小的batch size效果不好,
因为计算过程中所得到的均值和方差不能代表全局。BN适用于固定深度的前向神经网络,如CNN,不适用于RNN;- LN在通道方向上,对C、H、W归一化,主要对RNN效果明显;
- IN在图像像素上,对H、W做归一化,用在风格化迁移;
- GN将channel分组,然后再做归一化。
另外,还需要注意它们的映射参数γ和β的区别:
- 对于 BN,IN,GN, 其γ和β都是维度等于通道数 C 的向量。针对每个channel我们都有一组γ,β,所以可学习的参数为2*C。
- 而对于 LN,其γ和β都是维度等于 normalized_shape 的矩阵。
最后,BN 和 IN 可以设置参数:momentum和track_running_stats来获得在整体数据上更准确的均值和标准差。LN 和 GN 只能计算当前 batch 内数据的真实均值和标准差。
GN与LN和IN有关,LN和IN在RNN、LSTM、GAN中有效,但是在视觉方面的效果并不如GN好。
关于BN的详细讲解请参考另一篇博客深度学习之批归一化–BN详解
1、GN(Group Normalization)
论文链接:https://arxiv.org/pdf/1803.08494.pdf
1.1 为什么提出GN?
BN是在一个batch中计算均值和方差,BN可以简化并优化使得非常深的网络能够收敛。但是BN却很受batch大小的影响,通过实验证明:BN需要一个足够大的批量,小的批量大小会导致对批统计数据的不准确率提高,显著增加模型的错误率。比如在检测、分割、视频识别等任务中,比如在faster R-cnn或mask R-cnn框架中使用一个batchsize为1或2的图像,因为分辨率更高,其中BN被“冻结”转换为线性层;
GN是为了解决BN对较小的mini-batch size效果差的问题。GN适用于占用显存比较大的任务,例如图像分割。对这类任务,可能 batch size 只能是个位数,再大显存就不够用了。而当 batch size 是个位数时,BN 的表现很差,因为没办法通过几个样本的数据量,来近似总体的均值和标准差。GN 也是独立于 batch 的,它是 LN 和 IN 的折中。
1.2 GN的原理
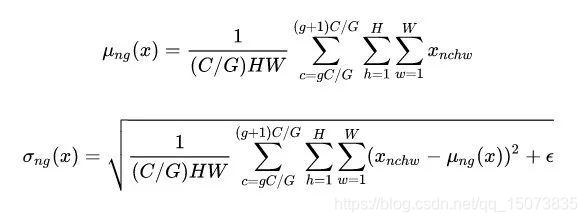
GN的主要思想:在 channel 方向 group,然后每个 group 内做 Norm,计算 ( C / G ) × H × W (C/G)\times H \times W (C/G)×H×W的均值和方差,这样就与batch size无关,不受其约束。
具体方法:GN 计算均值和标准差时,把每一个样本 feature map 的 channel 分成 G 组,每组将有 C/G 个 channel,然后将这些 channel 中的元素求均值和标准差。各组 channel 用其对应的归一化参数独立地归一化。

1.3 GN与BN的比较
下图可以看出,
(1)训练误差,GN比BN低,说明GN更利于优化;
(2)验证误差,GN比BN高,因为GN没有BN的正则化能力,思考:可以通过其他正则化方法做弥补(待研究)。

GN对batch_size 不敏感,从下图中可以看出,batch_size 32~2表现几乎一致。

问题:GN是否丝毫不受batch_size影响呢?
1.4 groups
实验表明,
(1)groups固定时,G=32效果最好;
(2)channels per group固定时,没组channel=16效果最好。

1.5 PyTorch实现
CLASS torch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True)

- 输入参数
num_groups,分成几组,即G,默认32.
num_channels,输入的channel数,每组的channel=num_channels/num_groups
eps,数值稳定性。
affine,是否需要仿射变换,即 γ \gamma γ和 β \beta β,默认True。
- shape
输入: N × C × H × W N \times C\times H\times W N×C×H×W
输出: N × C × H × W N \times C\times H\times W N×C×H×W
- example
>>> input = torch.randn(20, 6, 10, 10)
>>> # Separate 6 channels into 3 groups
>>> m = nn.GroupNorm(3, 6)
>>> # Separate 6 channels into 6 groups (equivalent with InstanceNorm)
>>> m = nn.GroupNorm(6, 6)
>>> # Put all 6 channels into a single group (equivalent with LayerNorm)
>>> m = nn.GroupNorm(1, 6)
>>> # Activating the module
>>> output = m(input)
- PyTorch源码
class GroupNorm(Module):
__constants__ = ['num_groups', 'num_channels', 'eps', 'affine']
num_groups: int
num_channels: int
eps: float
affine: bool
def __init__(self, num_groups: int, num_channels: int, eps: float = 1e-5, affine: bool = True) -> None:
super(GroupNorm, self).__init__()
self.num_groups = num_groups
self.num_channels = num_channels
self.eps = eps
self.affine = affine
if self.affine:
self.weight = Parameter(torch.Tensor(num_channels))
self.bias = Parameter(torch.Tensor(num_channels))
else:
self.register_parameter('weight', None)
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self) -> None:
if self.affine:
init.ones_(self.weight)
init.zeros_(self.bias)
def forward(self, input: Tensor) -> Tensor:
return F.group_norm(
input, self.num_groups, self.weight, self.bias, self.eps)
def extra_repr(self) -> str:
return '{num_groups}, {num_channels}, eps={eps}, ' \
'affine={affine}'.format(**self.__dict__)
F.group_norm()
def group_norm(input, num_groups, weight=None, bias=None, eps=1e-5):
# type: (Tensor, int, Optional[Tensor], Optional[Tensor], float) -> Tensor
r"""Applies Group Normalization for last certain number of dimensions.
See :class:`~torch.nn.GroupNorm` for details.
"""
if not torch.jit.is_scripting():
if type(input) is not Tensor and has_torch_function((input,)):
return handle_torch_function(
group_norm, (input,), input, num_groups, weight=weight, bias=bias, eps=eps)
_verify_batch_size([
input.size(0) * input.size(1) // num_groups, num_groups]
+ list(input.size()[2:]))
return torch.group_norm(input, num_groups, weight, bias, eps,
torch.backends.cudnn.enabled)
2、LN(Layer Normalization)层归一化
论文链接:https://arxiv.org/pdf/1607.06450v1.pdf
如果一个神经元的净输入分布在神经网络中是动态变化的,比如循环神经网络,那么无法应用批归一化操作。
针对BN不适用于深度不固定的网络(sequence长度不一致,如RNN),LN对深度网络的某一层的所有神经元的输入按以下公式进行normalization操作。
层归一化和批归一化不同的是,层归一化是对一个中间层的所有神经元进行归一化。
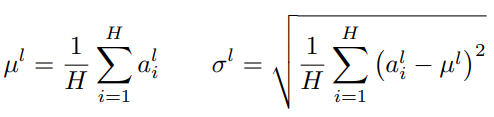
LN中同层神经元的输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差。
Layer Normalization (LN) 的一个优势是不需要批训练,在单条数据内部就能归一化。LN不依赖于batch size和输入sequence的长度,因此可以用于batch size为1和RNN中。LN用于RNN效果比较明显,但是在CNN上,效果不如BN。
3、IN(Instance Normalization)
论文链接:https://arxiv.org/pdf/1607.08022.pdf
IN针对图像像素做normalization,最初用于图像的风格化迁移。在图像风格化中,生成结果主要依赖于某个图像实例,feature map 的各个 channel 的均值和方差会影响到最终生成图像的风格。所以对整个batch归一化不适合图像风格化中,因而对H、W做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
对于,IN 对每个样本的 H、W 维度的数据求均值和标准差,保留 N 、C 维度,也就是说,它只在 channel 内部求均值和标准差,其公式如下:
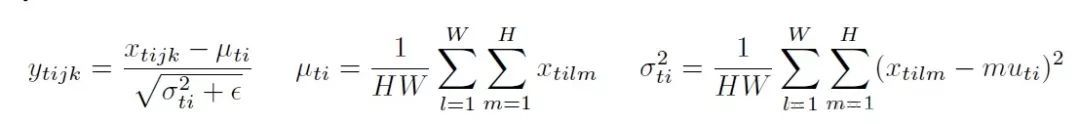
4、总结

上图为四种归一化方法,其中N为批量,C为通道,(H,W)表示feature map,蓝色像素代表相同的均值和方差归一化。
Batch Normalization:
1.BN的计算就是把每个通道的NHW单独拿出来归一化处理
2.针对每个channel我们都有一组γ,β,所以可学习的参数为2*C
3.当batch size越小,BN的表现效果也越不好,因为计算过程中所得到的均值和方差不能代表全局
Layer Normalizaiton:
1.LN的计算就是把每个CHW单独拿出来归一化处理,不受batch_size 的影响
2.常用在RNN网络,但如果输入的特征区别很大,那么就不建议使用它做归一化处理
Instance Normalization
1.IN的计算就是把每个HW单独拿出来归一化处理,不受通道和batchsize 的影响
2.常用于风格迁移,但如果特征图可以用到通道之间的相关性,那么就不建议使用它做归一化处理
Group Normalizatio
1.GN的计算就是把先把通道C分成G组,然后把每个gHW单独拿出来归一化处理,最后把G组归一化之后的数据合并成CHW
2.GN介于LN和IN之间,当然可以说LN和IN就是GN的特例,比如G的大小为1或者为C
Switchable Normalization
1.将 BN、LN、IN 结合,赋予权重,让网络自己去学习归一化层应该使用什么方法,自动为神经网络的每个归一化层确定一个合适的归一化操作。
2.集万千宠爱于一身,但训练复杂。
BN,LN和IN的所有方法都学习了一个每通道的线性变换,来补偿表示能力的丢失:
y i = γ x i + β y_i=\gamma x_i + \beta yi=γxi+β, γ \gamma γ, β \beta β是可训练的比例和位移。
如果我们将组号设置为G = 1,则GN变为LN 。LN假设层中的所有通道都做出“类似的贡献”。GN比LN受限制更少,因为假设每组通道(而不是所有通道)都受共享均值和方差的影响; 该模型仍然具有为每个群体学习不同分布的灵活性。这导致GN相对于LN的代表能力提高。
如果我们将组号设置为G = C(即每组一个通道),则GN变为IN。 但是IN只能依靠空间维度来计算均值和方差,并且错过了利用信道依赖的机会。
这几个方法主要的区别就是在:
- BN是在batch上,对N、H、W做归一化,而保留通道 C 的维度。BN对较小的batch size效果不好,
- 因为计算过程中所得到的均值和方差不能代表全局。BN适用于固定深度的前向神经网络,如CNN,不适用于RNN;
- LN在通道方向上,对C、H、W归一化,主要对RNN效果明显;
- IN在图像像素上,对H、W做归一化,用在风格化迁移;
- GN将channel分组,然后再做归一化。
另外,还需要注意它们的映射参数γ和β的区别:
对于 BN,IN,GN, 其γ和β都是维度等于通道数 C 的向量。针对每个channel我们都有一组γ,β,所以可学习的参数为2*C。
而对于 LN,其γ和β都是维度等于 normalized_shape 的矩阵。
最后,BN 和 IN 可以设置参数:momentum和track_running_stats来获得在整体数据上更准确的均值和标准差。LN 和 GN 只能计算当前 batch 内数据的真实均值和标准差。
5、WN(Weighted Normalization)
BN和LN将规范化应用于输入数据x,WN则对权重进行规范化。WN是在训练过程中,对网络参数进行标准化。这也是一个很神奇的操作。不过效果表现上,是被BN、LN虐了。还不足以成为主流的标准化方法,所以在这里只是稍微提一下。(效果不是很好,仅提一下。)
WN将权重向量分解为权重大小和方向两部分:

WN不依赖于输入数据的分布,故可应用于mini-batch较小的情景且可用于动态网络结构。此外,WN还避免了LN中对每一层使用同一个规范化公式的不足。
总的来看,LN、BN属于将特征规范化,WN是将参数规范化。三种规范化方式尽管对输入数据的尺度化(scale)参数来源不同,但其本质上都实现了数据的规范化操作。
参考博客
https://blog.csdn.net/hao1994121/article/details/85171610














 583
583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









