







目录
一、Batch Normalization(BN)
1.1为什么提出BN?
在深层网络的训练中,由于反向传播算法,模型的参数在发生指数型变化(因为是链式传播),从而导致每一层的输入分布会发生剧烈变化,这就会引起两个问题:
1.网络需要不断调整来适应输入数据分布的变化,导致网络学习速度的降低
2.网络的训练过程容易陷入梯度饱和区(详解见文章底部注释),减缓网络收敛速度
怎么解决这两个问题?
我们可以通过固定网络每一层输入值的分布来减缓这两个问题
所以有学者提出了用白化来解决这个问题(白化是机器学习里面常用的规范化数据分布的方法,一般是PCA白化和ZCA白化使得输入的特征具有相同的均值和方差,PCA均值为0,方差为1,而ZCA均值为0,方差相同)但是白化又存在两个问题:
1.计算成本太高,每一轮每一层都要计算
2.改变了网络中原始数据本身的表达能力,都是一样的均值方差
为了解决上面这两个问题,所以就提出了BN算法
1.2BN的基本原理和公式
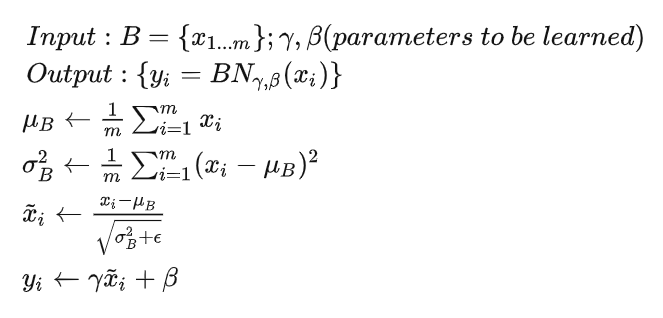

和
是两个可训练参数,主要是在一定程度上恢复数据本身的表达能力,对规范化后的数据进行线性处理。
1.3BN在神经网络中的实现
神经网络里面一般传递的都是张量数据,如[N, H, W, C],其中N是batch_size,H、W是特征图宽高,C是通道数。那么上面公式中的B就是下图的蓝色部分。
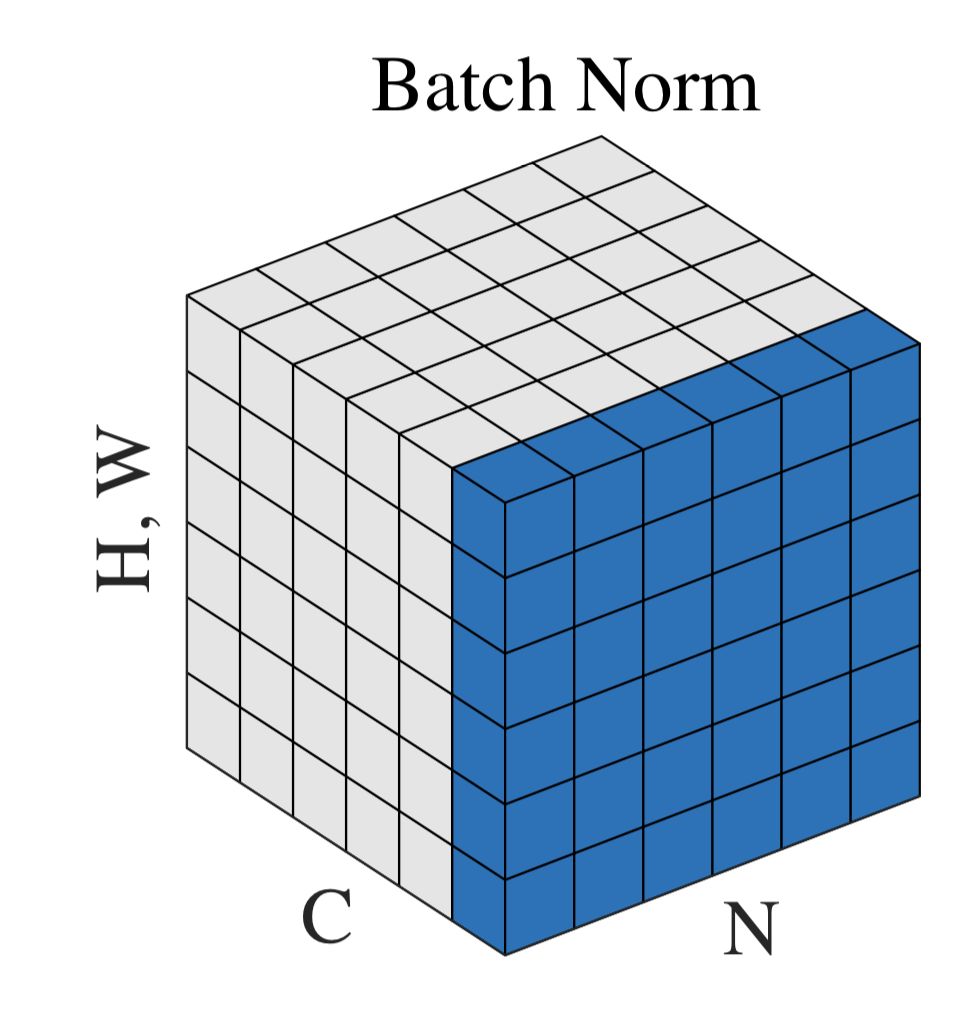
也就是说BN是对不同样本里面的同一个特征通道进行归一化处理,逐特征维度归一化,可训练参数的维度为C。
BN训练时的均值和方差:该批次内数据相应维度的均值与方差;
BN测试时的均值和方差:基于所有批次的期望(无偏估计)计算所得
1.4BN的优点和缺点
优点:
1.使得网络中每层输入数据的分布相对稳定,加速模型的训练速度。
2.允许网络使用饱和性激活函数(sigmoid,tanh),缓解了梯度消失的问题。
3.因为不同的mini_batch均值和方差都有所不同,这就为网络的学习过程增加了随机噪音,与dropout随机关闭神经元给网络带来的噪音类似,一定程度上起到了正则化的作用。
缺点:
1.BN特别依赖于大的batch_size,而由于显卡等硬件限制,我们大多数batch_size都设置的较小。
2.对于序列化数据的网络不太适用,尤其是序列样本长度不同时。如RNN,LSTM
二、LN,IN,GN的原理和适用范围
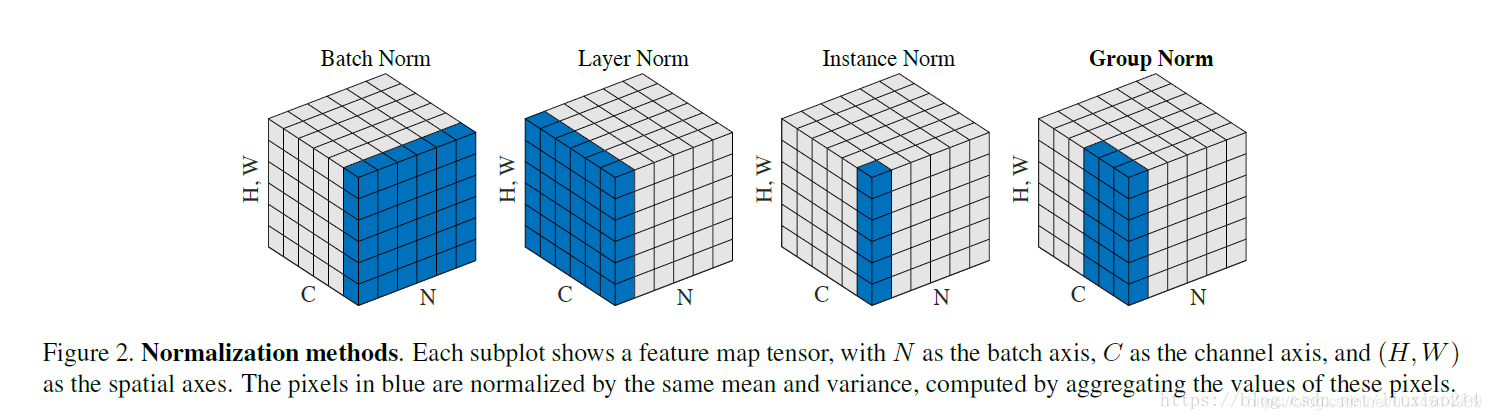
LN:取同一个样本的不同通道做归一化,逐样本归一化。是由Hinton及其学生提出,可以很好的用在序列型网络如RNN中,同时LN在训练和预测时均值方差都由当前样本确定,这与BN不同。可以不进行批训练。
IN:仅仅对每一个样本的每一个通道做归一化。主要用于生成模型中, feature map 的各个 channel 的均值和方差会影响到最终生成图像的风格,如图片风格迁移,图片生成结果主要依赖于某个图像实例,所以BN不行
GN:介于LN和IN之间的一种方法,对每个样本的多个通道进行归一化。用由何凯明团队提出,优化了BN在batch_size较小时的劣势,适用于占用显存较大的任务,如图像分割,一般为16个通道为一组(经验)
三、Reference和注释
https://zhuanlan.zhihu.com/p/93643523
https://zhuanlan.zhihu.com/p/34879333
什么是梯度饱和区?
当我们在神经网络中采用饱和激活函数(saturated activation function)时,例如sigmoid,tanh激活函数,很容易使得模型训练陷入梯度饱和区,此时梯度会变得很小接近于0,从而导致网络收敛很慢。有两种解决方法:
1.线性整流函数ReLU可以在一定程度上解决训练进入梯度饱和区的问题
2.我们可以让激活函数的输入分布保持在一个稳定的状态来尽可能避免他们陷入梯度饱和区,这就是BN的想法。















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











