







AnomalyDiffusion: Few-Shot Anomaly Image Generation with Diffusion Model
1、Background
在现实世界的工业生产中,异常样本非常稀少,给异常检测带来了重大挑战。为了缓解异常数据少的问题,现有的异常检测大多依赖于仅使用正常样本的无监督学习方法,或者少样本监督学习方法。尽管这些方法在异常检测方面表现良好,但在异常定位方面的表现有限,无法处理异常分类。
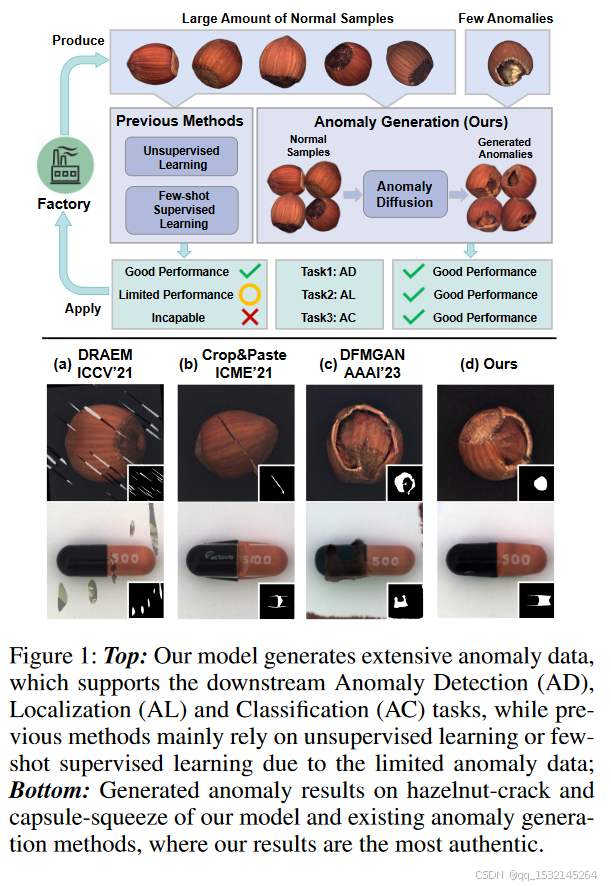
为了应对异常样本稀缺的问题,研究人员提出了异常生成方法来补充异常数据,这些方法可以分为两类:
1)无模型的方法。从现有异常或异常纹理数据集中随机裁剪和粘贴补丁到正常样本上。但这些方法在合成数据的真实性上表现较差(图1-底部-a/b)。
2)基于GAN的方法利用生成对抗网络(GANs)生成异常,但它们大多数需要大量的异常样本进行训练。唯一的少样本生成模型DFMGAN采用在正常样本上预训练的StyleGAN2,然后使用少量异常样本进行领域适应。但生成的异常与异常掩模的对齐不准确(图1-底部-c)。
总之,现有的异常生成方法要么无法生成真实的异常,要么通过学习少量异常数据无法准确生成异常图像-掩模对,这限制了它们在下游异常检测任务中的改进。
为了解决上述问题,我们提出了AnomalyDiffusion,一种新颖的基于扩散模型的异常生成方法,它将异常生成到输入的正常样本上,并使用异常掩模。
通过利用从大规模数据集中学到的预训练LDM的强大先验信息,我们可以使用少量的异常图像提取更好的异常表示,从而增强生成的真实性和多样性。
为了生成具有特定类型和位置的异常,我们提出了空间异常嵌入,它将异常信息分离成异常嵌入(用于异常外观)和空间嵌入(用于异常位置)。通过将异常位置与外观分离,我们可以在任何所需位置生成异常,从而为下游任务生成大量异常图像-掩模对。
此外,我们提出了一种自适应注意力重权重机制,它根据生成图像与输入正常样本之间的差异动态调整交叉注意力图,使模型更多地关注生成的异常不太明显的区域。这种自适应机制使得生成的异常图像与异常掩模精确对齐,极大地方便了下游异常定位任务。
2、Method
AnomalyDiffusion方法 旨在从少量异常样本中学习并生成大量与异常掩模对齐的异常数据 ,以支持下游的异常检测任务。
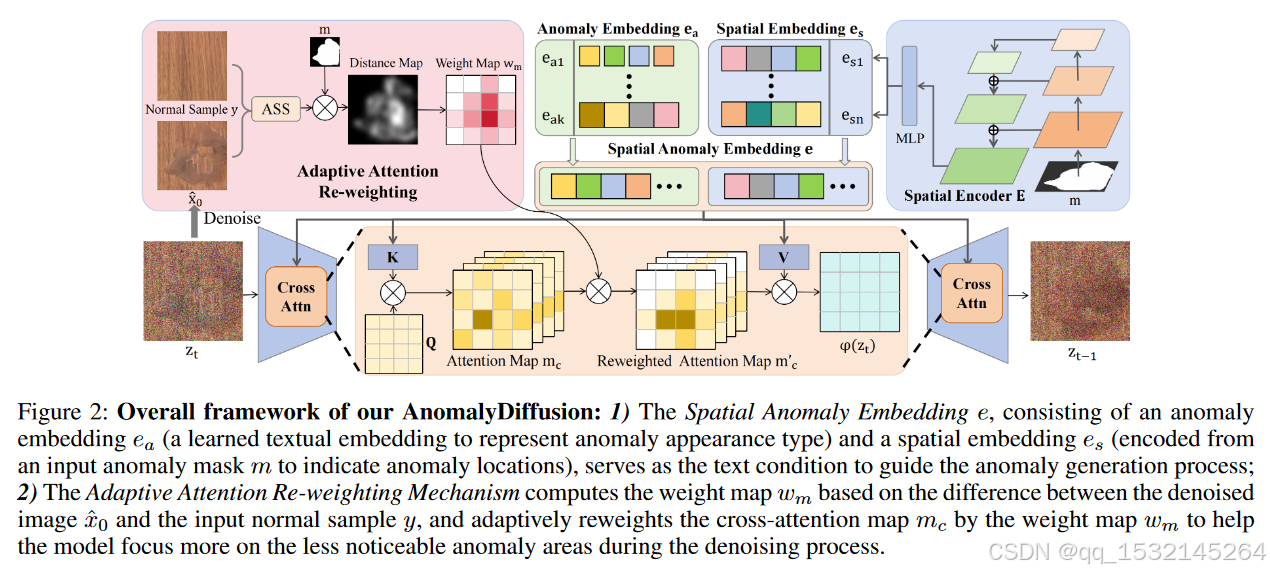
AnomalyDiffusion模型的整体框架两个关键组件:空间异常嵌入(Spatial Anomaly Embedding)和自适应注意力重权重机制(Adaptive Attention Re-weighting Mechanism)。
1) 空间异常嵌入(Spatial Anomaly Embedding)
- 异常嵌入(ea):这是一个学习到的文本嵌入,用于表示异常的外观类型。它捕获了异常的视觉特征,例如异常的形状、纹理或颜色等。
- 空间嵌入(es):这是从输入的异常掩模(mask)编码得到的空间嵌入,用于指示异常的位置。掩模通常是一个二值图像,其中异常区域被标记出来。
- 组合:将异常嵌入(ea)和空间嵌入(es)组合起来形成空间异常嵌入(e),这个组合嵌入作为文本条件输入到扩散模型中,指导异常生成过程。这种设计允许模型在指定的位置生成特定类型的异常。
2) 自适应注意力重权重机制(Adaptive Attention Re-weighting Mechanism)
- 权重图(wm)计算:在去噪过程的每一步,模型会计算去噪后的图像(记为 x ^ 0 \hat{x}_0 x^0 )和输入的正常样本(记为 y)之间的差异。基于这个差异,模型会计算出一个权重图(wm),用于指示哪些区域的异常生成不够明显。
- 交叉注意力图(mc)的自适应重权重:权重图(wm)被用来自适应地调整交叉注意力图(mc)。交叉注意力图控制着模型在生成过程中对不同区域的关注程度。通过将权重图(wm)与交叉注意力图(mc)相乘,模型可以更多地关注那些异常生成不够明显的区域。
- 去噪过程:在扩散模型的去噪过程中,这种自适应重权重机制帮助模型更准确地对齐生成的异常和输入的掩模,从而生成与掩模精确对齐的异常图像。
pseudo-code
# 导入必要的库
import torch
from diffusion_model import DenoisingDiffusionModel
from spatial_encoder import SpatialEncoder
from anomaly_embedding import AnomalyEmbedding
# 初始化模型组件
spatial_encoder = SpatialEncoder()
anomaly_embedding = AnomalyEmbedding()
diffusion_model = DenoisingDiffusionModel()
# 假设我们有以下输入:
normal_sample = ... # 正常样本图像
anomaly_mask = ... # 异常掩模
# 步骤1: 使用空间编码器从异常掩模中编码得到空间嵌入
spatial_embedding = spatial_encoder(anomaly_mask)
# 步骤2: 使用异常嵌入学习异常的外观类型
# 这里假设异常嵌入已经通过文本反演方法预训练好
anomaly_embedding = anomaly_embedding.get_learned_embedding(anomaly_type)
# 步骤3: 将异常嵌入和空间嵌入组合成空间异常嵌入
spatial_anomaly_embedding = combine_embeddings(anomaly_embedding, spatial_embedding)
# 步骤4: 使用扩散模型生成异常图像
# 这里假设扩散模型已经预训练好,并可以用于生成过程
generated_anomaly_image = diffusion_model.generate_image(
normal_sample, spatial_anomaly_embedding
)
# 步骤5: 自适应注意力重权重机制
# 计算去噪后的图像与输入正常样本之间的差异
difference_map = calculate_difference(generated_anomaly_image, normal_sample)
# 计算权重图,并自适应地调整交叉注意力图
weight_map = calculate_weight_map(difference_map)
adjusted_cross_attention_map = adjust_cross_attention(weight_map)
# 使用调整后的交叉注意力图再次生成异常图像
final_generated_anomaly_image = diffusion_model.refine_image(
generated_anomaly_image, adjusted_cross_attention_map
)
# 函数定义
def combine_embeddings(anomaly_embedding, spatial_embedding):
# 组合嵌入向量
return torch.cat((anomaly_embedding, spatial_embedding), dim=0)
def calculate_difference(generated_image, normal_sample):
# 计算生成图像与正常样本之间的差异
return torch.abs(generated_image - normal_sample)
def calculate_weight_map(difference_map):
# 根据差异计算权重图
# 这里使用简化的softmax操作作为示例
return torch.softmax(difference_map, dim=0)
def adjust_cross_attention(weight_map):
# 自适应地调整交叉注意力图
# 这里假设有一个交叉注意力图,我们根据权重图进行调整
# 实际实现会更复杂,涉及模型内部的注意力机制
return weight_map # 简化示例
3、Experiments
🐂🐎。。。
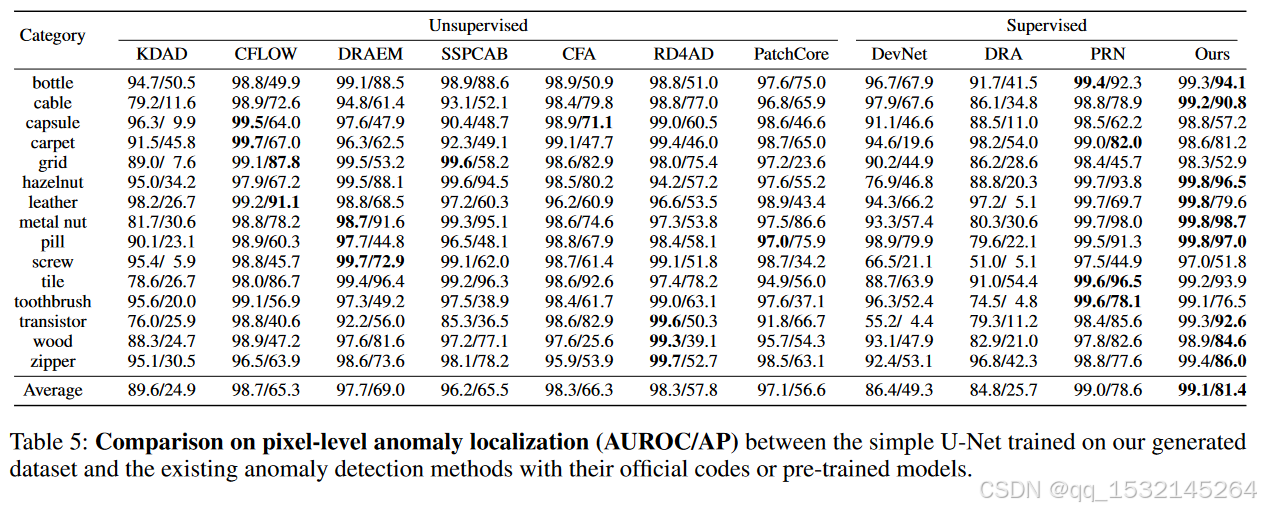
4、Conclusion
- 提出了AnomalyDiffusion,这是一种新颖的异常生成模型,用于生成异常图像-掩模对。
- 将异常信息解耦为异常外观和位置信息,分别由潜在扩散模型(LDM)文本空间中的异常嵌入和空间嵌入表示。
- 此外,还引入了一种自适应注意力重权重机制,它帮助模型更多地关注生成的异常不太明显的区域,从而提高生成的异常与掩模之间的对齐度。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









