








前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。https://www.captainbed.cn/north

文章目录
1. 引言:Transformer的革命性意义
2017年,Google Brain团队在论文《Attention Is All You Need》中首次提出了Transformer架构,彻底改变了自然语言处理(NLP)领域的格局。与之前的RNN和LSTM相比,Transformer具有以下革命性优势:
- 并行计算能力:不再受限于序列的时序处理
- 长距离依赖捕捉:通过自注意力机制有效捕捉任意距离的依赖关系
- 卓越的扩展性:模型规模可以轻松扩展到数十亿参数
ChatGPT作为基于Transformer的杰出代表,其强大能力正是源自这一基础架构。本文将深入解析Transformer的各个组件,并通过代码实现和流程图展示其工作原理。
2. Transformer整体架构
Transformer采用经典的编码器-解码器结构,但完全基于注意力机制构建,摒弃了传统的循环神经网络结构。
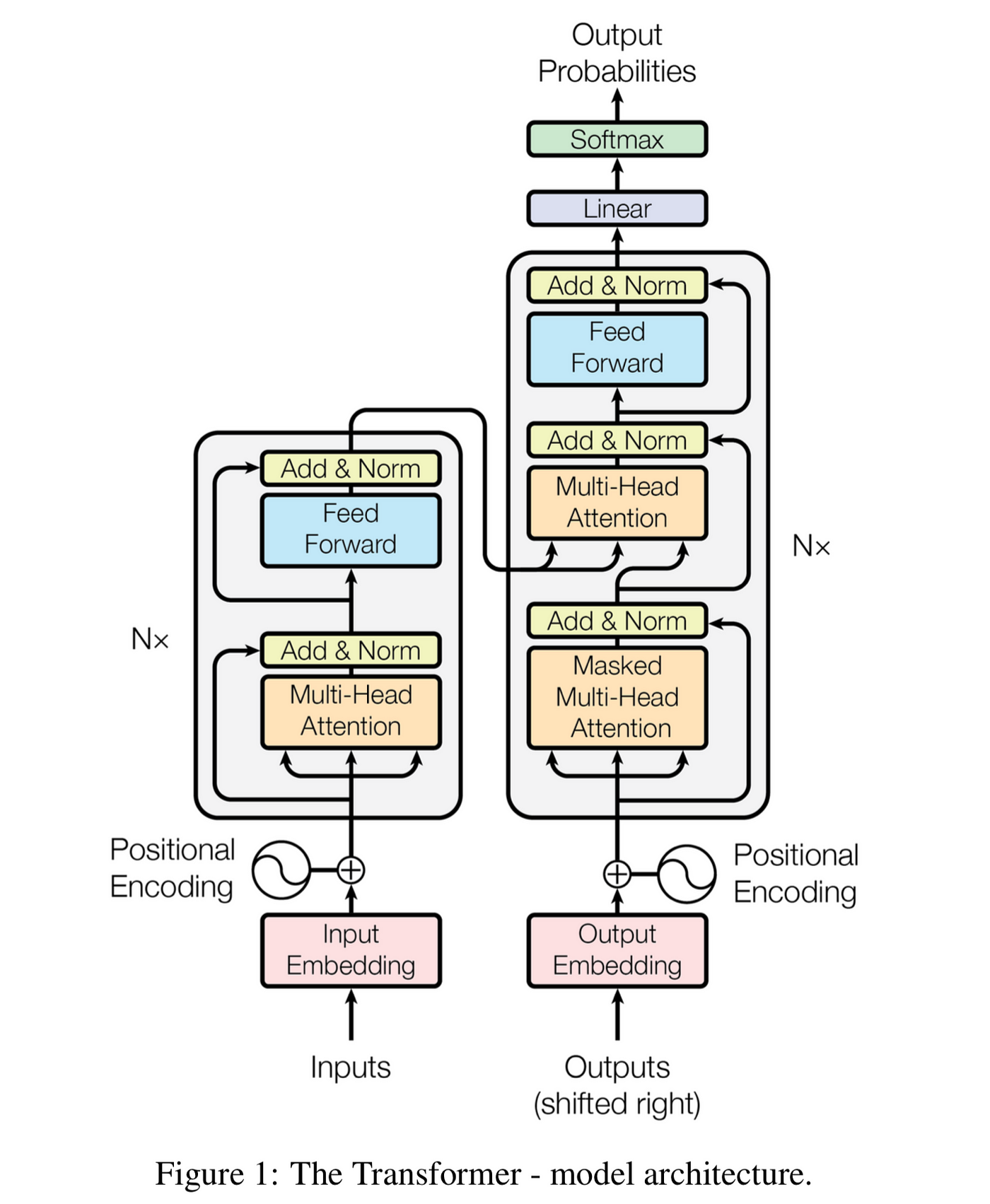
图1:Transformer整体架构示意图
2.1 编码器结构
编码器由N个相同的层堆叠而成(原论文中N=6),每层包含两个主要子层:
- 多头自注意力机制(Multi-Head Self-Attention)
- 前馈神经网络(Feed Forward Network)
每个子层都采用残差连接(Residual Connection)和层归一化(Layer Normalization)。
2.2 解码器结构
解码器同样由N个相同层堆叠而成,每层包含三个子层:
- 掩码多头自注意力机制(Masked Multi-Head Self-Attention)
- 编码器-解码器注意力机制(Encoder-Decoder Attention)
- 前馈神经网络(Feed Forward Network)
同样采用残差连接和层归一化。
3. 核心组件详解
3.1 自注意力机制(Self-Attention)
自注意力机制是Transformer的核心创新,它允许模型在处理每个词时关注输入序列中的所有词,并动态计算它们的重要性。
计算过程:
- 将输入向量转换为查询(Q)、键(K)、值(V)三个矩阵
- 计算注意力分数: A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
import torch
import torch.nn.functional as F
def self_attention(query, key, value, mask=None, dropout=None):
"计算缩放点积注意力"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
代码1:自注意力机制实现
3.2 多头注意力(Multi-Head Attention)
多头注意力将自注意力机制并行执行多次,然后将结果拼接起来,使模型能够同时关注不同表示子空间的信息。
图2:多头注意力机制示意图
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) 线性投影得到Q,K,V
query, key, value = [
l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))
]
# 2) 计算注意力
x, self.attn = self_attention(query, key, value, mask=mask, dropout=self.dropout)
# 3) 拼接多头结果并通过最终线性层
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
代码2:多头注意力实现
3.3 位置编码(Positional Encoding)
由于Transformer没有循环结构,需要显式地注入位置信息。位置编码使用不同频率的正弦和余弦函数:
P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i)} = sin(pos/10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i+1)} = cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
class PositionalEncoding(nn.Module):
"实现位置编码"
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return self.dropout(x)
代码3:位置编码实现
4. Transformer完整实现
4.1 编码器层实现
class EncoderLayer(nn.Module):
"编码器由自注意力和前馈网络组成"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"自注意力和前馈网络,均有残差连接"
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
4.2 解码器层实现
class DecoderLayer(nn.Module):
"解码器由自注意力、源注意力(编码器-解码器注意力)和前馈网络组成"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"依次执行掩码自注意力、编码器-解码器注意力和前馈网络"
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
4.3 完整Transformer模型
class Transformer(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(Transformer, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
def forward(self, src, tgt, src_mask, tgt_mask):
"处理屏蔽的源序列和目标序列"
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
5. 训练与优化
5.1 训练流程
Transformer训练包含以下关键步骤:
- 数据准备:构建词汇表,处理输入输出序列
- 批次生成:创建带有填充和掩码的批次
- 损失计算:使用标签平滑的交叉熵损失
- 优化策略:使用Adam优化器配合学习率预热
def run_epoch(data_iter, model, loss_compute):
"标准训练和日志函数"
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
for i, batch in enumerate(data_iter):
out = model.forward(batch.src, batch.trg,
batch.src_mask, batch.trg_mask)
loss = loss_compute(out, batch.trg_y, batch.ntokens)
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 50 == 1:
elapsed = time.time() - start
print(f"Epoch Step: {i} Loss: {loss/batch.ntokens:.6f} "
f"Tokens per Sec: {tokens/elapsed:.1f}")
start = time.time()
tokens = 0
return total_loss / total_tokens
5.2 学习率调度
Transformer使用动态学习率调度策略,在训练初期线性增加学习率,之后按步数平方根的倒数衰减:
l r a t e = d m o d e l − 0.5 ⋅ min ( s t e p _ n u m − 0.5 , s t e p _ n u m ⋅ w a r m u p _ s t e p s − 1.5 ) lrate = d_{model}^{-0.5} \cdot \min(step\_num^{-0.5}, step\_num \cdot warmup\_steps^{-1.5}) lrate=dmodel−0.5⋅min(step_num−0.5,step_num⋅warmup_steps−1.5)
class NoamOpt:
"优化器包装器,实现学习率动态调整"
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
def step(self):
"更新参数和学习率"
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step=None):
"实现学习率计算"
if step is None:
step = self._step
return self.factor * \
(self.model_size ** (-0.5) *
min(step ** (-0.5), step * self.warmup ** (-1.5)))
6. 实战:构建小型Transformer模型
6.1 数据准备
from torchtext.datasets import Multi30k
from torchtext.data import Field, BucketIterator
SRC = Field(tokenize="spacy", tokenizer_language="de",
init_token='<sos>', eos_token='<eos>', lower=True)
TRG = Field(tokenize="spacy", tokenizer_language="en",
init_token='<sos>', eos_token='<eos>', lower=True)
train_data, valid_data, test_data = Multi30k.splits(exts=('.de', '.en'),
fields=(SRC, TRG))
SRC.build_vocab(train_data, min_freq=2)
TRG.build_vocab(train_data, min_freq=2)
BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device)
6.2 模型初始化
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
HID_DIM = 256
ENC_LAYERS = 3
DEC_LAYERS = 3
ENC_HEADS = 8
DEC_HEADS = 8
ENC_PF_DIM = 512
DEC_PF_DIM = 512
ENC_DROPOUT = 0.1
DEC_DROPOUT = 0.1
enc = Encoder(INPUT_DIM, HID_DIM, ENC_LAYERS, ENC_HEADS,
ENC_PF_DIM, ENC_DROPOUT, device)
dec = Decoder(OUTPUT_DIM, HID_DIM, DEC_LAYERS, DEC_HEADS,
DEC_PF_DIM, DEC_DROPOUT, device)
SRC_PAD_IDX = SRC.vocab.stoi[SRC.pad_token]
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
model = Transformer(enc, dec, SRC_PAD_IDX, TRG_PAD_IDX, device).to(device)
6.3 训练循环
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg[:,:-1])
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
trg = trg[:,1:].contiguous().view(-1)
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
7. Transformer的演进与ChatGPT
7.1 GPT系列模型演进
- GPT-1:首次展示Transformer在生成任务上的潜力
- GPT-2:更大规模,展示零样本学习能力
- GPT-3:1750亿参数,强大的少样本学习能力
- ChatGPT:基于GPT-3.5/GPT-4,通过RLHF优化对话能力
7.2 ChatGPT的关键改进
-
RLHF(人类反馈强化学习):
- 监督微调(Supervised Fine-Tuning)
- 奖励模型训练(Reward Modeling)
- 强化学习优化(PPO算法)
-
对话优化:
- 多轮对话记忆
- 安全性和对齐性增强
- 更自然的回复风格
8. 总结与展望
Transformer架构以其卓越的性能和可扩展性,已经成为现代NLP的基石。从原始Transformer到ChatGPT,我们可以看到:
- 架构创新:从基础注意力机制到各种变体和改进
- 规模扩展:模型参数从几亿到数千亿的增长
- 训练方法:从监督学习到自监督学习再到RLHF
未来发展方向可能包括:
- 更高效的注意力机制
- 多模态Transformer
- 更强大的推理和规划能力
- 持续改进的安全性和对齐性
Transformer架构仍在快速发展中,ChatGPT只是这一革命性架构的一个成功应用案例。理解Transformer的原理对于深入掌握现代NLP技术至关重要。
附录:关键流程图
自注意力计算流程图
Transformer训练流程图
希望这篇详尽的Transformer解析能够帮助你深入理解ChatGPT背后的核心技术!



















 499
499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











