







目录
二、报错:ImportError: cannot import name 'openai_object' from 'openai'
三、报错:google.protobuf.message.DecodeError: Error parsing message
四、报错 torch.distributed.elastic.multiprocessing.errors.ChildFailedError(exitcode返回不是-9)
五、报错:torch.distributed.elastic.multiprocessing.api:failed (exitcode: -9) local_rank(exitcode返回是-9)
8.1、Huggingface 中 PreTrainedModel部分注释解析
8.3、LlamaModel(LlamaPreTrainedModel)
8.4、LlamaForCausalLM(LlamaPreTrainedModel)
8.5、其他的一些例子:Blip2 Huggingface 模型代码风格
8.6、其他的一些例子:Chatglm3 Huggingface 模型代码风格
一、基本环境
系统:Ubuntu
- torch:2.2.1
- cuda:12.1
- cudnn:8
- python:3.10
- GPU:A40 48G (使用 ZerO3,bf16)
- RAM:52G
- 模型:Llama-2-7b-chat-hf
 https://github.com/tatsu-lab/stanford_alpaca
https://github.com/tatsu-lab/stanford_alpaca二、报错:ImportError: cannot import name 'openai_object' from 'openai'
openai的版本不对,更换版本
pip install openai==0.28.0
三、报错:google.protobuf.message.DecodeError: Error parsing message
- 加载Tokenizer报 google.protobuf.message.DecodeError: Error parsing message 这个错误
错误代码(修改前):
tokenizer = transformers.AutoTokenizer.from_pretrained( model_args.model_name_or_path, cache_dir=training_args.cache_dir, model_max_length=training_args.model_max_length, padding_side="right", use_fast=False, )修改后:去掉 use_fast=False
tokenizer = transformers.AutoTokenizer.from_pretrained( model_args.model_name_or_path, cache_dir=training_args.cache_dir, model_max_length=training_args.model_max_length, padding_side="right" )
四、报错 torch.distributed.elastic.multiprocessing.errors.ChildFailedError(exitcode返回不是-9)
- 报这个错误原因有很多,错误点不在这里,应该看上面的错误提醒,上面的错误才是真正需要解决的,在分布式训练中,子进程只要报错,主进程总是可以看到torch.distributed.elastic.multiprocessing.errors.ChildFailedError这个错误,因此解决方法可以先把gpu其他节点关掉,使用一个节点去分析终端报的错误,然后去解决
例如:
Traceback (most recent call last):
File "/content/ChatDoctor/train.py", line 25, in
import utils
File "/content/ChatDoctor/utils.py", line 15, in
from openai import openai_object
ImportError: cannot import name 'openai_object' from 'openai' (/usr/local/lib/python3.10/dist-packages/openai/init.py)
Traceback (most recent call last):
File "/content/ChatDoctor/train.py", line 25, in
import utils
File "/content/ChatDoctor/utils.py", line 15, in
from openai import openai_object
ImportError: cannot import name 'openai_object' from 'openai' (/usr/local/lib/python3.10/dist-packages/openai/init.py)
Traceback (most recent call last):
File "/content/ChatDoctor/train.py", line 25, in
import utils
File "/content/ChatDoctor/utils.py", line 15, in
from openai import openai_object
ImportError: cannot import name 'openai_object' from 'openai' (/usr/local/lib/python3.10/dist-packages/openai/init.py)
Traceback (most recent call last):
File "/content/ChatDoctor/train.py", line 25, in
import utils
File "/content/ChatDoctor/utils.py", line 15, in
from openai import openai_object
ImportError: cannot import name 'openai_object' from 'openai' (/usr/local/lib/python3.10/dist-packages/openai/init.py)
[2024-02-09 11:04:21,257] torch.distributed.elastic.multiprocessing.api: [ERROR] failed (exitcode: 1) local_rank: 0 (pid: 14644) of binary: /usr/bin/python3
Traceback (most recent call last):
File "/usr/local/bin/torchrun", line 8, in
sys.exit(main())
File "/usr/local/lib/python3.10/dist-packages/torch/distributed/elastic/multiprocessing/errors/init.py", line 346, in wrapper
return f(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/distributed/run.py", line 806, in main
run(args)
File "/usr/local/lib/python3.10/dist-packages/torch/distributed/run.py", line 797, in run
elastic_launch(
File "/usr/local/lib/python3.10/dist-packages/torch/distributed/launcher/api.py", line 134, in call
return launch_agent(self._config, self._entrypoint, list(args))
File "/usr/local/lib/python3.10/dist-packages/torch/distributed/launcher/api.py", line 264, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:红框里才是报错的真正原因,有可能是openai包版本问题,需要更改openai包的版本

五、报错:torch.distributed.elastic.multiprocessing.api:failed (exitcode: -9) local_rank(exitcode返回是-9)
- 初步判定,cpu内存OOM造成的,gpu显存不够,ZeRO3卸载参数至cpu,cpu显存不够发生OOM。
个人解决方式(仅参考),详细放置github:
可能是由于GPU或RAM内存不足造成的
一开始也遇到了这个问题,我的配置是这样的
- torch:2.2.1
- cuda:12.1
- cudnn:8
- python:3.10
- GPU:A40 48G (开启 deepspeed ,使用 ZerO3,bf16)
- RAM:52G
- model:Llama-2-7b-chat-hf
后来更改了配置可以工作了,配置如下:
- CPU num:56
- RAM size: 256G
- GPU: V100 16G * 8
开启了deepspeed,因为V100不支持关闭了bf16 TF32,使用fp16
因此需要对官方的bash和deepspeed的json进行修改:{ // 新增 fp16 配置 "fp16": { // FP16训练设置,减少内存使用,加速训练,但需注意精度控制。 "enabled": "auto", // 是否启用FP16训练,auto表示自动决定。 "loss_scale": 0, // 损失缩放值,0表示自动调整,用于防止梯度下溢。 "loss_scale_window": 1000, // 自动调整损失缩放值的窗口大小。 "initial_scale_power": 16, // 初始损失缩放值的幂级。 "hysteresis": 2, // 延迟增加损失缩放值的迭代次数。 "min_loss_scale": 1 // 允许的最小损失缩放值。 }, "bf16": { // BF16训练设置,类似于FP16但在某些硬件上更优。 "enabled": "auto" // 是否启用BF16训练,'auto'表示自动决定。 }, "optimizer": { // 优化器设置。 "type": "AdamW", // 优化器类型,AdamW是一种常见的优化算法。 "params": { "lr": "auto", // 学习率,auto表示自动调整。 "betas": "auto", "eps": "auto", "weight_decay": "auto" } }, "scheduler": { // 学习率调度器设置。 "type": "WarmupDecayLR", // 调度器类型,用于管理学习率如何随时间变化。 "params": { "total_num_steps": "auto", // 总步数,auto表示自动计算。 "warmup_min_lr": "auto", // 预热期间的最小学习率,auto表示自动调整。 "warmup_max_lr": "auto", // 预热期间的最大学习率,auto表示自动调整。 "warmup_num_steps": "auto" } }, "zero_optimization": { // ZeRO优化策略设置,用于在大型模型训练中优化内存使用。 "stage": 3, // ZeRO优化的阶段,阶段3提供最大的内存优化。 "offload_optimizer": { "device": "cpu", // 优化器状态卸载到CPU。 "pin_memory": true // 是否固定内存,以加速CPU至GPU的数据传输。 }, "offload_param": { // 参数卸载到CPU。 "device": "cpu", "pin_memory": true // 是否固定内存,以加速CPU至GPU的数据传输。 }, "overlap_comm": true, // 是否在训练过程中重叠通信和计算。 "contiguous_gradients": true, // 是否使梯度在内存中连续,可以提高某些操作的性能。 "sub_group_size": 1e9, // 用于分组参数的子集大小,以优化通信。 "reduce_bucket_size": "auto", // 减少操作的桶大小,auto表示自动调整。 "stage3_prefetch_bucket_size": "auto", // 预取桶大小,在ZeRO-3中使用,auto表示自动调整。 "stage3_param_persistence_threshold": "auto", // 参数持久性门槛,auto表示自动调整。 "stage3_max_live_parameters": 1e9, // 最大活动参数数量。 "stage3_max_reuse_distance": 1e9, // 最大重用距离,影响参数缓存策略。 "stage3_gather_16bit_weights_on_model_save": true // 在模型保存时是否收集16位权重。 }, "gradient_accumulation_steps": "auto", // 梯度累积步骤,auto表示自动调整,用于模拟更大的批处理大小。 "gradient_clipping": "auto", // 梯度裁剪的阈值,auto表示自动调整,用于控制梯度爆炸。 "steps_per_print": 5, // 每打印一次日志的步数。 "train_batch_size": "auto", // 训练的总批处理大小,auto 表示自动调整。 "train_micro_batch_size_per_gpu": "auto", // 每个GPU的微批处理大小,auto表示自动调整。 "wall_clock_breakdown": false // 是否记录并打印时间分解,用于性能分析。 }对应的bash也进行修改
# 加入当前目录的绝对路径 PYTHONPATH=$PWD export PYTHONPATH echo "当前bash执行目录: $PWD, 已经将PYTHONPATH设置为: $PYTHONPATH" # TODO 修改官方, 暂时关闭 --bf16 True \ --tf32 True \ V100 不支持 torchrun --nproc_per_node=8 train.py \ --model_name_or_path /workspace/Llama-2-7b-chat-hf \ --data_path ./alpaca_data.json \ --output_dir ./alpaca_out \ --num_train_epochs 3 \ --per_device_train_batch_size 1 \ --per_device_eval_batch_size 1 \ --gradient_accumulation_steps 8 \ --evaluation_strategy "no" \ --save_strategy "steps" \ --save_steps 2000 \ --save_total_limit 1 \ --learning_rate 2e-5 \ --weight_decay 0. \ --warmup_ratio 0.03 \ --deepspeed "./configs/default_offload_opt_param.json"最后结果:
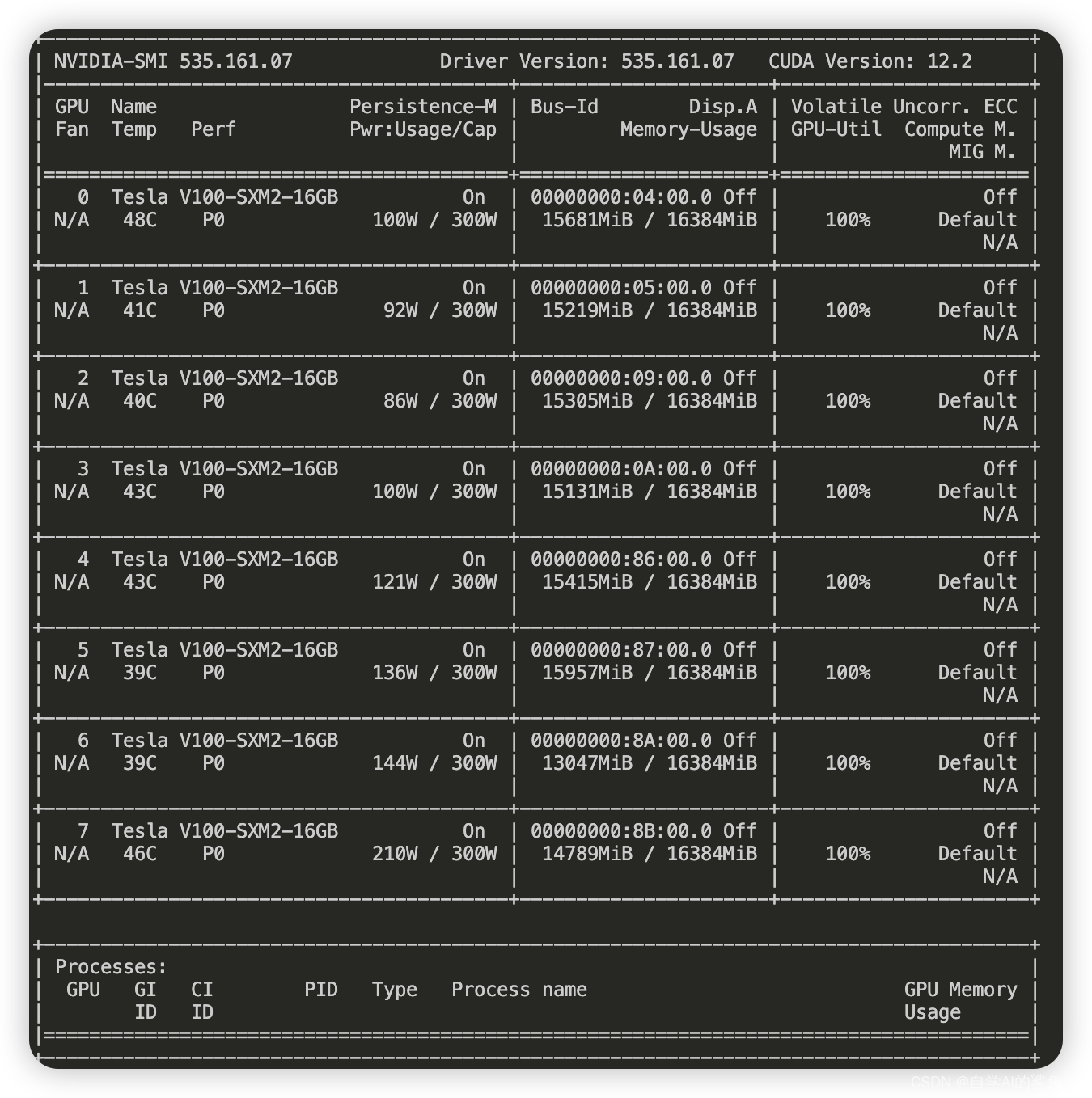
六、deepspeed安装后运行代码总是报错
deepspeed安装CUDA拓展安装注意事项
前置准备
- 安装 c++编译器
sudo apt-get update sudo apt-get install build-essential
- 安装ninja
sudo apt-get install ninja-build
- cuda 与 torch cuda 对齐,简单来说:需要外界cuda与conda虚拟环境中
pytorch的cuda版本一致,详见
七、优化的代码
7.1、更改model embedding 词汇表的函数
新增代码:将模型的 embedding 的词汇表大小调整至8的整数,用于提升性能
V,E = input_embeddings = model.get_input_embeddings().weight.shape
model.resize_token_embeddings(int(8 * math.ceil(V / 8.0)))
# smart_tokenizer_and_embedding_resize 函数用于调整 tokenizer 和模型 embedding 的大小
# 以适应新增的特殊 token,确保模型能够正确处理这些特殊 token
def smart_tokenizer_and_embedding_resize(
special_tokens_dict: Dict,
tokenizer: transformers.PreTrainedTokenizer,
model: transformers.PreTrainedModel,
):
"""Resize tokenizer and embedding.
Note: This is the unoptimized version that may make your embedding size not be divisible by 64.
"""
num_new_tokens = tokenizer.add_special_tokens(special_tokens_dict) # 将特殊 token 添加到 tokenizer 中,获取添加的新 token 数量
model.resize_token_embeddings(len(tokenizer)) # 调整模型 embedding 层的大小,使其与 tokenizer 的词汇表大小一致
if num_new_tokens > 0:
# 获取模型的输入 embedding 和输出 embedding
input_embeddings = model.get_input_embeddings().weight.data
output_embeddings = model.get_output_embeddings().weight.data
# 计算输入 embedding 和输出 embedding 的平均值,作为新 token 的初始化值
input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(dim=0, keepdim=True)
output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(dim=0, keepdim=True)
# 将新增 token 的 embedding 初始化为之前 token 的平均值
input_embeddings[-num_new_tokens:] = input_embeddings_avg
output_embeddings[-num_new_tokens:] = output_embeddings_avg
# TODO 新增代码, 将resize_token_embeddings设置为8的倍数, 为了提升性能
V,E = input_embeddings = model.get_input_embeddings().weight.shape
model.resize_token_embeddings(int(8 * math.ceil(V / 8.0)))7.2、更改后的train.py函数
# Copyright 2023 Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy,math
import logging
from dataclasses import dataclass, field
from typing import Optional, Dict, Sequence
import torch
import torch.distributed
import transformers
from torch.utils.data import Dataset
from transformers import Trainer
import utils
IGNORE_INDEX = -100
DEFAULT_PAD_TOKEN = "[PAD]"
DEFAULT_EOS_TOKEN = "</s>"
DEFAULT_BOS_TOKEN = "</s>"
DEFAULT_UNK_TOKEN = "</s>"
PROMPT_DICT = {
"prompt_input": (
"Below is an instruction that describes a task, paired with an input that provides further context. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:"
),
"prompt_no_input": (
"Below is an instruction that describes a task. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Response:"
),
}
# TODO 新增代码
import os
os.environ["WANDB_DISABLED"] = "true" # 关闭 wandb
# TODO 新增代码, logger
def set_logger_with_seed(training_args: transformers.Seq2SeqTrainingArguments):
import logging,sys
from transformers import set_seed
logger = logging.getLogger(__name__) # 7. 创建一个日志记录器,用于记录脚本运行时的日志信息。
# Setup logging
# 10. 设置日志记录的基本配置,包括日志格式、日期格式和输出处理器(在这里是将日志输出到标准输出流)。
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
if training_args.should_log:
# The default of training_args.log_level is passive, so we set log level at info here to have that default.
# 11. 如果训练参数指定应该记录日志,则将Transformers库的日志级别设置为info(信息级别)。默认情况下,训练参数的日志级别是被动的,所以这里将其设置为信息级别。
transformers.utils.logging.set_verbosity_info()
# 12. 获取训练参数指定的进程日志级别,并将该级别设置为当前日志记录器的级别。
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
# datasets.utils.logging.set_verbosity(log_level)
# 13. 设置Transformers库的日志级别为训练参数指定的进程日志级别,启用默认的日志处理器和显式的日志格式。
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# 设置一切相关的随机种子,保证训练结果的可重现性
set_seed(training_args.seed)
return logger
# TODO 新增代码, 打印模型的是否参与训练的参数名和数据类型
def print_model_allarguments_name_dtype(logger,model):
for n,v in model.named_parameters():
if v.requires_grad:
logger.info(f"trainable model arguments: {n} - {v.dtype} - {v.shape}")
else:
logger.info(f"not trainable model arguments: {n} - {v.dtype} - {v.shape}")
@dataclass
class ModelArguments:
model_name_or_path: Optional[str] = field(default="facebook/opt-125m")
@dataclass
class DataArguments:
data_path: str = field(default=None, metadata={"help": "Path to the training data."})
@dataclass
class TrainingArguments(transformers.TrainingArguments):
cache_dir: Optional[str] = field(default=None)
optim: str = field(default="adamw_torch")
model_max_length: int = field(
default=512,
metadata={"help": "Maximum sequence length. Sequences will be right padded (and possibly truncated)."},
)
def safe_save_model_for_hf_trainer(trainer: transformers.Trainer, output_dir: str):
"""Collects the state dict and dump to disk."""
state_dict = trainer.model.state_dict() # 从 Trainer 中获取当前模型的状态字典
if trainer.args.should_save: # 如果训练器的参数 should_save 为 True,表示需要保存模型
# 将状态字典中的所有参数张量转移到 CPU 设备上,以减少内存占用
cpu_state_dict = {key: value.cpu() for key, value in state_dict.items()}
del state_dict
trainer._save(output_dir, state_dict=cpu_state_dict) # noqa
# smart_tokenizer_and_embedding_resize 函数用于调整 tokenizer 和模型 embedding 的大小
# 以适应新增的特殊 token,确保模型能够正确处理这些特殊 token
def smart_tokenizer_and_embedding_resize(
special_tokens_dict: Dict,
tokenizer: transformers.PreTrainedTokenizer,
model: transformers.PreTrainedModel,
):
"""Resize tokenizer and embedding.
Note: This is the unoptimized version that may make your embedding size not be divisible by 64.
"""
num_new_tokens = tokenizer.add_special_tokens(special_tokens_dict) # 将特殊 token 添加到 tokenizer 中,获取添加的新 token 数量
model.resize_token_embeddings(len(tokenizer)) # 调整模型 embedding 层的大小,使其与 tokenizer 的词汇表大小一致
if num_new_tokens > 0:
# 获取模型的输入 embedding 和输出 embedding
input_embeddings = model.get_input_embeddings().weight.data
output_embeddings = model.get_output_embeddings().weight.data
# 计算输入 embedding 和输出 embedding 的平均值,作为新 token 的初始化值
input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(dim=0, keepdim=True)
output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(dim=0, keepdim=True)
# 将新增 token 的 embedding 初始化为之前 token 的平均值
input_embeddings[-num_new_tokens:] = input_embeddings_avg
output_embeddings[-num_new_tokens:] = output_embeddings_avg
# TODO 新增代码, 将resize_token_embeddings设置为8的倍数, 为了提升性能
T,E = input_embeddings = model.get_input_embeddings().weight.shape
model.resize_token_embeddings(int(8 * math.ceil(T / 8.0)))
# _tokenize_fn 函数用于对一个字符串列表进行分词
def _tokenize_fn(strings: Sequence[str], tokenizer: transformers.PreTrainedTokenizer) -> Dict:
"""Tokenize a list of strings."""
tokenized_list = [
tokenizer(
text,
return_tensors="pt",
padding="longest",
max_length=tokenizer.model_max_length,
truncation=True,
)
for text in strings # 一次一个样本
]
input_ids = labels = [tokenized.input_ids[0] for tokenized in tokenized_list]
input_ids_lens = labels_lens = [
tokenized.input_ids.ne(tokenizer.pad_token_id).sum().item() for tokenized in tokenized_list
]
return dict(
input_ids=input_ids,
labels=labels,
input_ids_lens=input_ids_lens,
labels_lens=labels_lens,
)
# preprocess 函数用于对输入和目标数据进行预处理和tokenization
# 它将输入和目标拼接成完整的序列,并使用 _tokenize_fn 进行分词
def preprocess(
sources: Sequence[str],
targets: Sequence[str],
tokenizer: transformers.PreTrainedTokenizer,
) -> Dict:
"""Preprocess the data by tokenizing."""
examples = [s + t for s, t in zip(sources, targets)] # 将输入和目标拼接成完整的序列
examples_tokenized, sources_tokenized = [_tokenize_fn(strings, tokenizer) for strings in (examples, sources)] # 使用 _tokenize_fn 对输入序列和源序列进行分词
input_ids = examples_tokenized["input_ids"] # 从分词结果中提取 input_ids
labels = copy.deepcopy(input_ids)
# 创建 labels 序列,将输入部分设置为 IGNORE_INDEX,只需预测输出部分
for label, source_len in zip(labels, sources_tokenized["input_ids_lens"]):
label[:source_len] = IGNORE_INDEX
return dict(input_ids=input_ids, labels=labels) # 返回包含输入 ID 和标签的字典
# SupervisedDataset 类继承自 PyTorch 的 Dataset 类,用于加载和管理监督式学习任务的数据
class SupervisedDataset(Dataset):
"""Dataset for supervised fine-tuning."""
def __init__(self, data_path: str, tokenizer: transformers.PreTrainedTokenizer):
super(SupervisedDataset, self).__init__()
# 加载指定路径下的数据
logging.warning("Loading data...")
list_data_dict = utils.jload(data_path)
# 格式化输入文本
logging.warning("Formatting inputs...")
prompt_input, prompt_no_input = PROMPT_DICT["prompt_input"], PROMPT_DICT["prompt_no_input"]
sources = [
prompt_input.format_map(example) if example.get("input", "") != "" else prompt_no_input.format_map(example)
for example in list_data_dict
]
targets = [f"{example['output']}{tokenizer.eos_token}" for example in list_data_dict]
# 对输入和目标进行tokenization
logging.warning("Tokenizing inputs... This may take some time...")
data_dict = preprocess(sources, targets, tokenizer)
# 将处理后的 input_ids 和 labels 保存为实例属性
self.input_ids = data_dict["input_ids"]
self.labels = data_dict["labels"]
def __len__(self):
return len(self.input_ids)
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
return dict(input_ids=self.input_ids[i], labels=self.labels[i])
# DataCollatorForSupervisedDataset 类用于对监督式学习任务的数据进行批处理
# 它将一个样本序列转换为一个批次的输入和标签张量
@dataclass
class DataCollatorForSupervisedDataset(object):
"""Collate examples for supervised fine-tuning."""
tokenizer: transformers.PreTrainedTokenizer
def __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:
# 从样本字典中提取 input_ids 和 labels
input_ids, labels = tuple([instance[key] for instance in instances] for key in ("input_ids", "labels"))
# 使用 PyTorch 的 rnn.pad_sequence 函数对 input_ids 和 labels 进行填充
input_ids = torch.nn.utils.rnn.pad_sequence(
input_ids, batch_first=True, padding_value=self.tokenizer.pad_token_id
)
labels = torch.nn.utils.rnn.pad_sequence(labels, batch_first=True, padding_value=IGNORE_INDEX)
return dict(
input_ids=input_ids,
labels=labels,
attention_mask=input_ids.ne(self.tokenizer.pad_token_id),
)
# make_supervised_data_module 函数用于创建监督式学习任务的数据模块
# 它返回一个字典,包含训练集、验证集和数据批处理器
def make_supervised_data_module(tokenizer: transformers.PreTrainedTokenizer, data_args) -> Dict:
"""Make dataset and collator for supervised fine-tuning."""
train_dataset = SupervisedDataset(tokenizer=tokenizer, data_path=data_args.data_path)
data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
return dict(train_dataset=train_dataset, eval_dataset=None, data_collator=data_collator)
def train():
# 使用 HuggingFace 的参数解析器,解析模型参数、数据参数和训练参数
parser = transformers.HfArgumentParser((ModelArguments, DataArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# TODO 新增代码
logger = set_logger_with_seed(training_args=training_args)
torch.distributed.barrier() # 进程阻塞,同步进程
# TODO 新增代码,训练阶段, 将 use_cache=False
config = transformers.AutoConfig.from_pretrained(model_args.model_name_or_path)
config.use_cache=False
# 从指定的预训练模型路径加载模型
model = transformers.AutoModelForCausalLM.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
# TODO 新增代码, 加载时使用 bf16, 节省内存
torch_dtype=torch.bfloat16,
# TODO 新增代码, 添加修改后的 config
config = config
)
# 从指定的预训练模型路径加载 tokenizer
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
model_max_length=training_args.model_max_length,
padding_side="right", # 右填充
# use_fast=False,
)
# 如果 tokenizer 没有 pad_token,则添加 pad_token 并调整模型 embedding 大小
if tokenizer.pad_token is None:
smart_tokenizer_and_embedding_resize(
special_tokens_dict=dict(pad_token=DEFAULT_PAD_TOKEN),
tokenizer=tokenizer,
model=model,
)
# 如果模型是 LLaMA 模型,则添加 eos_token、bos_token 和 unk_token
if "llama" in model_args.model_name_or_path:
tokenizer.add_special_tokens(
{
"eos_token": DEFAULT_EOS_TOKEN,
"bos_token": DEFAULT_BOS_TOKEN,
"unk_token": DEFAULT_UNK_TOKEN,
}
)
# TODO 新增代码, model 打印参数
if training_args.local_rank == 0:
logger.info(f"Model {model}")
logger.info(f"Training/evaluation parameters {training_args}")
logger.info(f"Model parameters {model.config}")
print_model_allarguments_name_dtype(logger=logger,model=model)
data_module = make_supervised_data_module(tokenizer=tokenizer, data_args=data_args)
# TODO 新增代码, 同步所有进程,等待所有进程到达这一点
torch.distributed.barrier()
trainer = Trainer(model=model, tokenizer=tokenizer, args=training_args, **data_module)
trainer.train()
trainer.save_state()
safe_save_model_for_hf_trainer(trainer=trainer, output_dir=training_args.output_dir)
if __name__ == "__main__":
train()
八、Llama2 Huggingface中模型风格简单解析
8.1、Huggingface 中 PreTrainedModel部分注释解析
 https://blog.csdn.net/qq_16555103/article/details/137919947?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22137919947%22%2C%22source%22%3A%22qq_16555103%22%7D
https://blog.csdn.net/qq_16555103/article/details/137919947?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22137919947%22%2C%22source%22%3A%22qq_16555103%22%7Dclass PreTrainedModel(nn.Module, ModuleUtilsMixin, GenerationMixin, PushToHubMixin, PeftAdapterMixin):
r"""
所有模型的基类。
[`PreTrainedModel`] 负责存储模型的配置,并处理加载、下载和保存模型的方法,以及一些所有模型共有的方法,例如:
- 调整输入嵌入的大小,
- 在自注意力头中裁剪头部。
类属性(由派生类覆盖):
- **config_class** ([`PretrainedConfig`]) -- 用作此模型架构配置类的 [`PretrainedConfig`] 的子类。
- **load_tf_weights** (`Callable`) -- 用于将 TensorFlow 检查点加载到 PyTorch 模型中的 Python *方法*,接受以下参数:
- **model** ([`PreTrainedModel`]) -- 要加载 TensorFlow 检查点的模型实例。
- **config** ([`PretrainedConfig`]) -- 与模型相关的配置实例。
- **path** (`str`) -- TensorFlow 检查点的路径。
- **base_model_prefix** (`str`) -- 一个字符串,指示在同一架构的派生类中与基础模型相关的属性,这些派生类在基础模型之上添加了模块。
- **is_parallelizable** (`bool`) -- 一个标志,指示此模型是否支持模型并行化。
- **main_input_name** (`str`) -- 模型主要输入的名称(通常是 NLP 模型的 `input_ids`、视觉模型的 `pixel_values` 和语音模型的 `input_values`)。
"""
# 指定配置类
# config_class 属性用于指定与当前模型架构相关的配置类,配置类通常继承自 PretrainedConfig 类
# 配置类中包含了模型的各种超参数和设置,在加载和初始化模型时会用到
config_class = None
# 基础模型前缀
# base_model_prefix 属性用于指定基础模型的前缀,通常在继承和扩展基础模型时使用
# 例如,如果一个模型在基础模型之上添加了额外的层或模块,可以使用该前缀来区分基础模型和扩展部分
base_model_prefix = ""
# 主输入名称
# main_input_name 属性用于指定模型的主要输入的名称,不同类型的模型可能有不同的主要输入
# 对于 NLP 模型,通常是 "input_ids";对于视觉模型,通常是 "pixel_values";对于语音模型,通常是 "input_values"
main_input_name = "input_ids"
# 模型标签
# model_tags 属性用于为模型添加一些标签或元信息,这些标签可以用于模型的分类、过滤和管理
model_tags = None
# 自动类
# _auto_class 属性用于指定模型的自动类,自动类通常用于根据配置自动创建和初始化模型
_auto_class = None
# 不进行模块拆分的模块列表
# _no_split_modules 属性用于指定在模型并行化时不进行拆分的模块列表
# 有些模块可能不适合拆分,或者拆分会导致性能下降,可以将其加入到该列表中
_no_split_modules = None
# 在设备放置时跳过的键列表
# _skip_keys_device_placement 属性用于指定在将模型放置到设备上时需要跳过的键(参数)列表
# 有些参数可能不需要放置到设备上,或者需要特殊处理,可以将其加入到该列表中
_skip_keys_device_placement = None
# 保持 FP32 精度的模块列表
# _keep_in_fp32_modules 属性用于指定需要保持 FP32 精度的模块列表
# 有些模块可能对数值精度比较敏感,需要保持较高的精度,可以将其加入到该列表中
_keep_in_fp32_modules = None
# 在加载时忽略的键模式列表,避免不必要的警告
# _keys_to_ignore_on_load_missing 属性用于指定在加载模型时可以忽略的键(参数)的模式列表
# 有些参数可能在模型加载时不存在,但并不影响模型的使用,可以将其模式加入到该列表中,避免不必要的警告
_keys_to_ignore_on_load_missing = None
# 在加载时忽略的意外键模式列表,避免不必要的警告
# _keys_to_ignore_on_load_unexpected 属性用于指定在加载模型时可以忽略的意外键(参数)的模式列表
# 有些参数可能在模型加载时出现,但并不影响模型的使用,可以将其模式加入到该列表中,避免不必要的警告
_keys_to_ignore_on_load_unexpected = None
# 在保存模型时忽略的键列表,用于不需要训练的键或确定性变量
# _keys_to_ignore_on_save 属性用于指定在保存模型时可以忽略的键(参数)列表
# 有些参数可能不需要保存,如确定性的变量或者不需要训练的参数,可以将其加入到该列表中
_keys_to_ignore_on_save = None
# 可能与状态字典中另一个键相关联的键列表
# _tied_weights_keys 属性用于指定可能与状态字典中另一个键(参数)相关联的键列表
# 有些参数可能与其他参数相关联,在更新其中一个参数时需要同步更新另一个参数,可以将这些参数加入到该列表中
_tied_weights_keys = None
# 是否支持并行化
# is_parallelizable 属性用于指示模型是否支持并行化,即是否可以将模型拆分到多个设备上并行训练或推理
is_parallelizable = False
# 是否支持梯度检查点
# supports_gradient_checkpointing 属性用于指示模型是否支持梯度检查点技术
# 梯度检查点可以降低模型训练时的内存消耗,但可能会增加计算开销
supports_gradient_checkpointing = False
# 是否支持 Flash Attention 2
# _supports_flash_attn_2 属性用于指示模型是否支持 Flash Attention 2 技术
# Flash Attention 2 是一种加速 Transformer 模型训练和推理的技术,可以显著降低内存消耗和计算时间
_supports_flash_attn_2 = False
# 是否支持 SDPA
# _supports_sdpa 属性用于指示模型是否支持 SDPA,SDPA是torch 2 推出的一种高效计算点积的接口
_supports_sdpa = False
# 是否支持将 `Cache` 实例作为 `past_key_values`
# _supports_cache_class 属性用于指示模型是否支持将 `Cache` 实例作为 `past_key_values` 参数传递
# 有些模型在生成任务中可以使用缓存机制来加速推理,这需要将 `Cache` 实例传递给模型
_supports_cache_class = False
# __init__ 方法是类的构造函数,用于初始化类的实例
def __init__(self, config: PretrainedConfig, *inputs, **kwargs):
# 调用父类的构造函数,完成一些基本的初始化工作
super().__init__()
# 检查配置对象是否是 PretrainedConfig 的实例
# 如果不是,则抛出 ValueError 异常,并提供相关的错误信息
if not isinstance(config, PretrainedConfig):
raise ValueError(
f"Parameter config in `{self.__class__.__name__}(config)` should be an instance of class "
"`PretrainedConfig`. To create a model from a pretrained model use "
f"`model = {self.__class__.__name__}.from_pretrained(PRETRAINED_MODEL_NAME)`"
)
# 保存预训练权重的配置和来源(如果在模型中给出)
# _autoset_attn_implementation 方法用于自动设置注意力实现方式
# torch_dtype 参数指定张量的数据类型
# check_device_map 参数用于检查设备映射
config = self._autoset_attn_implementation(
config, torch_dtype=torch.get_default_dtype(), check_device_map=False
)
self.config = config
# 保存模型配置的名称或路径
self.name_or_path = config.name_or_path
# 初始化一个空字典,用于存储已发出的警告
self.warnings_issued = {}
# 如果模型支持生成功能,则从模型配置创建一个生成配置对象
self.generation_config = GenerationConfig.from_model_config(config) if self.can_generate() else None
# 复制类属性 _keep_in_fp32_modules 到实例属性
# 这样做是为了允许模型动态更新该属性,而无需修改类属性
# 例如,当使用不同的组件(如 language_model)时,可以动态更新该属性
self._keep_in_fp32_modules = copy.copy(self.__class__._keep_in_fp32_modules)
8.2、LlamaPreTrainedModel
# LlamaPreTrainedModel 是一个继承自 PreTrainedModel 基类的自定义模型类
# PreTrainedModel 是 Transformers 库中用于加载和初始化预训练模型的基类
class LlamaPreTrainedModel(PreTrainedModel):
# config_class 指定该模型使用的配置类为 LlamaConfig
# LlamaConfig 是一个用于存储模型配置参数的数据类,如嵌入维度、层数、注意力头数等
config_class = LlamaConfig
# base_model_prefix 指定该模型的基础模型前缀为 "model"
# 这个前缀用于在加载预训练权重时识别模型的主干部分
base_model_prefix = "model"
# 指定该模型支持梯度检查点功能
# 梯度检查点是一种内存优化技术,可以减少训练过程中的内存占用
supports_gradient_checkpointing = True
# _no_split_modules 列出了在模型并行化时不应该被分割的模块
# 这里指定 LlamaDecoderLayer 模块不应该被分割
_no_split_modules = ["LlamaDecoderLayer"]
# _skip_keys_device_placement 列出了在放置模型到设备时应该跳过的键
# 这里指定 "past_key_values" 键应该被跳过,因为它是注意力缓存,不需要放置到设备上
_skip_keys_device_placement = ["past_key_values"]
# 指定该模型支持 flash_attn_2 优化
# flash_attn_2 是一种注意力计算的优化方法,可以加速注意力计算
_supports_flash_attn_2 = True
# 指定该模型支持 SDPA ,SDPA是torch 2 推出的高效点积计算atten的接口
_supports_sdpa = True
# 指定该模型支持使用缓存类
# 缓存类用于存储和管理注意力缓存,以加速后续的推理过程
_supports_cache_class = True
# _init_weights 方法用于初始化模型权重
def _init_weights(self, module):
# 从配置对象中获取初始化范围 std
std = self.config.initializer_range
# 如果模块是一个线性层 (nn.Linear)
if isinstance(module, nn.Linear):
# 使用正态分布初始化权重
module.weight.data.normal_(mean=0.0, std=std)
# 如果该线性层有偏置,将偏置初始化为 0
if module.bias is not None:
module.bias.data.zero_()
# 如果模块是一个嵌入层 (nn.Embedding)
elif isinstance(module, nn.Embedding):
# 使用正态分布初始化嵌入权重
module.weight.data.normal_(mean=0.0, std=std)
# 如果该嵌入层有填充索引,将相应的嵌入向量初始化为 0
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
# _setup_cache 方法用于设置注意力缓存
def _setup_cache(self, cache_cls, max_batch_size, max_cache_len: Optional[int] = None):
# 如果使用 flash_attention_2 注意力实现且缓存类型为 StaticCache,则抛出异常
# 因为 StaticCache 与 flash_attention_2 不兼容
if self.config._attn_implementation == "flash_attention_2" and cache_cls == StaticCache:
raise ValueError(
"`static` cache implementation is not compatible with `attn_implementation==flash_attention_2` "
"make sure to use `sdpa` in the mean time, and open an issue at https://github.com/huggingface/transformers"
)
# 遍历模型的每一层
for layer in self.model.layers:
device = layer.input_layernorm.weight.device # 获取当前层的设备
# 确定缓存的数据类型
if hasattr(self.config, "_pre_quantization_dtype"):
dtype = self.config._pre_quantization_dtype
else:
dtype = layer.self_attn.o_proj.weight.dtype
# 为当前层的自注意力模块创建缓存对象
# 传递配置、最大批量大小、最大缓存长度、设备和数据类型等参数
layer.self_attn.past_key_value = cache_cls(
self.config, max_batch_size, max_cache_len, device=device, dtype=dtype
)
# _reset_cache 方法用于重置注意力缓存
def _reset_cache(self):
# 遍历模型的每一层
for layer in self.model.layers:
# 将当前层的自注意力模块的缓存设置为 None
layer.self_attn.past_key_value = None几个小问题
1)base_model_prefix 这个参数什么作用?
base_model_prefix这个参数在 Transformers 库中用于指定模型的主体部分的前缀。它在加载预训练权重时起到了关键作用。解释一下它的作用:
- 在训练 Transformer 模型时,我们通常会从一个预训练的检查点开始,而不是从头开始训练。这个检查点包含了模型的所有参数和权重,通常是一个
.bin文件。当我们加载这个检查点时,Transformers 库需要知道哪些权重对应于模型的主体部分,哪些对应于其他部分,如嵌入层、分类头等。这就是base_model_prefix的作用所在。它指定了模型主体部分的前缀,Transformers 库会将以这个前缀开头的权重加载到模型的主体部分中。其他部分的权重则需要使用不同的前缀来区分。例如,在这段代码中,我们将base_model_prefix设置为"model"。这意味着,在加载预训练权重时,Transformers 库会将所有以"model"为前缀的权重加载到模型的主体部分中,如"model.encoder.layer.0.attention.self.query.weight"。而其他部分的权重则需要使用不同的前缀,如"embeddings.word_embeddings.weight"对应于词嵌入层的权重。设置正确的base_model_prefix非常重要,因为它确保了预训练权重能够正确地加载到模型的各个部分。如果设置错误,模型可能无法正常工作或者产生意外的结果。- 另外,
base_model_prefix还用于区分模型的不同版本或变体。例如,如果我们有一个 BERT-Base 模型和一个 BERT-Large 模型,它们的主体部分可能会使用不同的前缀,如"bert"和"bert-large"。这样可以确保在加载权重时不会发生混淆。总之,
base_model_prefix这个参数在 Transformers 库中扮演着非常重要的角色,它确保了预训练权重能够正确地加载到模型的各个部分,同时也有助于区分不同的模型版本或变体。正确设置这个参数对于模型的初始化和微调训练都至关重要。
2)_skip_keys_device_placement 这个参数什么作用?
- 在深度学习模型的训练和推理过程中,我们通常需要将模型及其参数放置到特定的设备上(如 GPU 或 CPU)以获得更好的计算性能。PyTorch 提供了
model.to(device)方法来实现这一功能,它会将模型的所有参数都移动到指定的设备上。然而,在 Transformer 模型中,有一些特殊的参数是不需要放置到设备上的,例如用于缓存注意力计算结果的past_key_values。这些参数通常是在推理过程中动态生成的,并且在每个时间步都会被重新计算,因此没有必要将它们移动到设备上。_skip_keys_device_placement参数就是用来指定在将模型放置到设备时需要跳过的参数键。在这段代码中,它被设置为["past_key_values"]。这意味着当调用model.to(device)时,Transformers 库会自动跳过将past_key_values相关的参数移动到设备上。- 跳过这些参数的移动有以下几个好处:
- 减少内存占用:由于这些参数通常比较大,将它们移动到 GPU 上会占用大量的显存。跳过它们可以节省宝贵的显存资源。
- 提高性能:将大量数据移动到设备上是一个相对耗时的操作。跳过不必要的数据移动可以提高模型的整体性能。
- 避免错误:如果不小心将这些参数移动到了不合适的设备上(如 CPU),可能会导致模型无法正常工作或者出现其他错误。
需要注意的是,
_skip_keys_device_placement参数只在将模型移动到新设备时生效。如果模型已经在指定的设备上,那么这些参数也会存在于该设备上。此外,不同的模型可能会有不同的需要跳过的参数键,因此这个参数的值需要根据具体情况进行设置。
8.3、LlamaModel(LlamaPreTrainedModel)
# LlamaModel 类继承自 LlamaPreTrainedModel,是 Llama2 模型中的一个关键组成部分,主要用于构建 Transformer 解码器。
class LlamaModel(LlamaPreTrainedModel):
# 构造函数初始化模型
def __init__(self, config: LlamaConfig):
# 调用父类的构造函数,传入配置信息
super().__init__(config)
self.padding_idx = config.pad_token_id # 填充索引,用于标识哪些位置是填充的,这对于处理不同长度的序列很重要。
self.vocab_size = config.vocab_size # 词汇表大小,即模型能够识别的不同词汇的总数。
# 词嵌入层,将输入的词汇索引转换为固定大小的向量。这是模型第一层的操作。
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
# 构造一个 ModuleList,里面包含了指定数量的 LlamaDecoderLayer 实例。
# 这里使用列表推导式创建了 config.num_hidden_layers 个解码器层。
self.layers = nn.ModuleList(
[LlamaDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
)
# 归一化层,使用 RMSNorm 对最后的输出进行归一化处理,有助于模型的训练稳定性。
self.norm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
# 设置梯度检查点的标志,默认为 False。这是一种内存优化技术,可以减少模型训练时的内存消耗,但会略微增加计算时间。
self.gradient_checkpointing = False
# 调用 post_init 方法进行权重的初始化和最终的处理。
self.post_init()8.4、LlamaForCausalLM(LlamaPreTrainedModel)
# LlamaForCausalLM 类是一个用于因果语言模型的 Llama 模型封装,它继承了 LlamaPreTrainedModel,提供了更高级的接口和工具函数
class LlamaForCausalLM(LlamaPreTrainedModel):
# 静态变量 _tied_weights_keys,指定了哪些权重被绑定(权重共享),这里 "lm_head.weight" 表示语言模型头部的权重将与其他部分共享,有助于减少模型参数
_tied_weights_keys = ["lm_head.weight"]
# 构造函数,初始化 LlamaForCausalLM 类的实例
def __init__(self, config):
# 调用基类的构造函数,传入配置对象 config,这是面向对象编程中的常见做法,用于初始化继承自父类的属性或方法
super().__init__(config)
# 创建 LlamaModel 实例,传入配置对象 config,LlamaModel 是模型的主体部分,负责大部分的计算工作
self.model = LlamaModel(config)
# 将配置对象中的 vocab_size 属性赋值给 self.vocab_size
# vocab_size 是模型词汇表的大小,对于生成任务非常关键
self.vocab_size = config.vocab_size
# 创建一个线性层 lm_head,用于将隐藏状态转换为词汇表大小的输出
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
# 调用 post_init 方法,完成模型权重的初始化和最终处理,这个方法通常包括权重初始化策略,有助于模型训练的稳定性和效率
self.post_init()8.5、其他的一些例子:Blip2 Huggingface 模型代码风格
# Blip2 模型相关的代码
class Blip2PreTrainedModel(PreTrainedModel):
# 指定配置类
config_class = Blip2Config
# 基础模型前缀
base_model_prefix = "blip"
# 支持梯度检查点
supports_gradient_checkpointing = True
# 不进行模块拆分的模块列表
_no_split_modules = ["Blip2Attention", "T5Block", "OPTDecoderLayer"]
# 在设备放置时跳过的键
_skip_keys_device_placement = "past_key_values"
# 保持 FP32 精度的模块列表
_keep_in_fp32_modules = ["wo"]
def _init_weights(self, module):
"""初始化权重"""
factor = self.config.initializer_range
# 对 Conv2d、Embedding 或 Linear 层进行权重初始化
if isinstance(module, nn.Conv2d) or isinstance(module, nn.Embedding) or isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=factor)
if hasattr(module, "bias") and module.bias is not None:
module.bias.data.zero_()
# 对 Blip2VisionEmbeddings 进行初始化
if isinstance(module, Blip2VisionEmbeddings):
if hasattr(self.config, "vision_config"):
factor = self.config.vision_config.initializer_range
nn.init.trunc_normal_(module.position_embedding, mean=0.0, std=factor)
nn.init.trunc_normal_(module.class_embedding, mean=0.0, std=factor)
# 对 LayerNorm 进行初始化
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
# 对带有 bias 的 Linear 层进行初始化
elif isinstance(module, nn.Linear) and module.bias is not None:
module.bias.data.zero_()
# Blip2 用于条件生成的模型
class Blip2ForConditionalGeneration(Blip2PreTrainedModel):
# 指定配置类
config_class = Blip2Config
# 指定主要输入名称
main_input_name = "pixel_values"
def __init__(self, config: Blip2Config):
super().__init__(config)
# 初始化视觉模型
self.vision_model = Blip2VisionModel(config.vision_config)
# 初始化查询 tokens
self.query_tokens = nn.Parameter(torch.zeros(1, config.num_query_tokens, config.qformer_config.hidden_size))
# 初始化 QFormer 模型
self.qformer = Blip2QFormerModel(config.qformer_config)
# 语言投影层
self.language_projection = nn.Linear(config.qformer_config.hidden_size, config.text_config.hidden_size)
# 根据配置初始化语言模型
if config.use_decoder_only_language_model:
language_model = AutoModelForCausalLM.from_config(config.text_config)
else:
language_model = AutoModelForSeq2SeqLM.from_config(config.text_config)
# 更新 `_tied_weights_keys` 使用基础模型中的权重
if language_model._tied_weights_keys is not None:
self._tied_weights_keys = [f"language_model.{k}" for k in language_model._tied_weights_keys]
self.language_model = language_model
# 初始化权重并应用最终处理
self.post_init()8.6、其他的一些例子:Chatglm3 Huggingface 模型代码风格
class ChatGLMPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and
a simple interface for downloading and loading pretrained models.
"""
is_parallelizable = False # 分布式
supports_gradient_checkpointing = True # 梯度检查点
config_class = ChatGLMConfig # 参数类,ChatGLMConfig继承 PreTrainedConfig
base_model_prefix = "transformer" # 主体模型的前缀
_no_split_modules = ["GLMBlock"] # 不拆分,提升效率
def _init_weights(self, module: nn.Module):
"""Initialize the weights."""
return
def get_masks(self, input_ids, past_key_values, padding_mask=None):
batch_size, seq_length = input_ids.shape
full_attention_mask = torch.ones(batch_size, seq_length, seq_length, device=input_ids.device)
full_attention_mask.tril_()
past_length = 0
if past_key_values:
past_length = past_key_values[0][0].shape[0]
if past_length:
full_attention_mask = torch.cat((torch.ones(batch_size, seq_length, past_length,
device=input_ids.device), full_attention_mask), dim=-1)
if padding_mask is not None:
full_attention_mask = full_attention_mask * padding_mask.unsqueeze(1)
if not past_length and padding_mask is not None:
full_attention_mask -= padding_mask.unsqueeze(-1) - 1
full_attention_mask = (full_attention_mask < 0.5).bool()
full_attention_mask.unsqueeze_(1)
return full_attention_mask
def get_position_ids(self, input_ids, device):
batch_size, seq_length = input_ids.shape
position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
return position_ids
# TODO 重写了方法, model内部自定义了梯度检查点的层
def gradient_checkpointing_enable(self, gradient_checkpointing_kwargs=None):
if not self.supports_gradient_checkpointing:
raise ValueError(f"{self.__class__.__name__} does not support gradient checkpointing.")
(......)
class ChatGLMModel(ChatGLMPreTrainedModel):
def __init__(self, config: ChatGLMConfig, device=None, empty_init=True):
super().__init__(config)
if empty_init:
init_method = skip_init # skip_init 表示model实例时不初始化参数, 因为后面还会进行 from_pretrained 的初始化, 可以节省时间
else:
init_method = default_init
init_kwargs = {}
if device is not None:
init_kwargs["device"] = device
self.embedding = init_method(Embedding, config, **init_kwargs)
# transformer 层数
self.num_layers = config.num_layers
# MQA多查询的分组数
self.multi_query_group_num = config.multi_query_group_num
# qkv dim
self.kv_channels = config.kv_channels
# Rotary positional embeddings, RoPE 最大的序列长度, 默认为 32k, 即 3W 多
self.seq_length = config.seq_length
# q k rope 的维度
rotary_dim = (
config.hidden_size // config.num_attention_heads if config.kv_channels is None else config.kv_channels
)
# rope 的维度是 q k 维度的一半, 即 d/2, original_rope 表示使用经典的 RoPE旋转位置编码
self.rotary_pos_emb = RotaryEmbedding(rotary_dim // 2, original_impl=config.original_rope, device=device,
dtype=config.torch_dtype)
self.encoder = init_method(GLMTransformer, config, **init_kwargs)
# 用于映射至 vocab 的输出层
self.output_layer = init_method(nn.Linear, config.hidden_size, config.padded_vocab_size, bias=False,
dtype=config.torch_dtype, **init_kwargs)
# P-tuning 的长度
self.pre_seq_len = config.pre_seq_len
# P-tuning 是否进行线性映射
self.prefix_projection = config.prefix_projection
if self.pre_seq_len is not None:
for param in self.parameters():
# P-tuning 冻结掉原来的模型参数
param.requires_grad = False
self.prefix_tokens = torch.arange(self.pre_seq_len).long()
self.prefix_encoder = PrefixEncoder(config)
self.dropout = torch.nn.Dropout(0.1)
(......)
class ChatGLMForConditionalGeneration(ChatGLMPreTrainedModel):
def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
super().__init__(config)
self.max_sequence_length = config.max_length
self.transformer = ChatGLMModel(config, empty_init=empty_init, device=device)
self.config = config
self.quantized = False
if self.config.quantization_bit:
self.quantize(self.config.quantization_bit, empty_init=True)
(......)(待更)

















 1600
1600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









