







也可以看看这篇文章:http://blog.csdn.net/historyasamirror/article/details/6746217
常见URL过滤方法
1 直接查询比较
即假设要存储url A,在入库前首先查询url库中是否存在 A,如果存在,则url A 不入库,否则存入url库。这种方法准确性高,但是一旦数据量变大,占用的存储空间也变大,同时,由于要查库,数据一多,查询时间变长,存储效率下降。
2 基于hash的存储
对于给定的url,通过建立的hash函数,来获得对应的hash值,并将该值存入库中。当在检查url是否存在库中时,只要将要检查的url,通过hash函数获取其hash值,然后查看库中是否存在该hash值,存在则丢弃,否则入库。这种方法在数据量变大时,占用的存储空间也会增大,查询时间也会加长。但是它可以将url进行压缩。对于很长的url,hash值可以相对很短。
以上方法中,为加快查询速度,一般可以选择 Redis作为查询库。
布隆过滤器 Bloom Filter
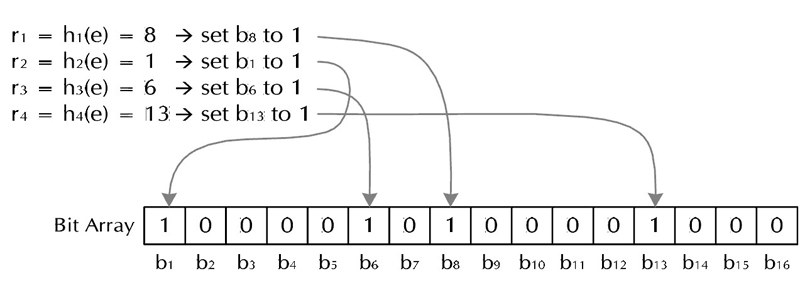
基本思路(网上一大堆):
1, 设数据集合
A={a1,a2,....,an}
,含
n
个元素,作为待操作的集合。
2, Bloom Filter用一个长度为 m 的位向量 V 表示的集合中的元素,位向量初始值全为0。
3, k 个具有均匀分布特性的散列函数 h1,h2,....,hk .
4, 对于要加入的元素,首经过k个散列函数产生k个随机数 h1,h2,......hk ,使向量 V 的相应位置 h1,h2,......hk 均置为1。集合中其他元素也通过类似的操作,将向量 V 的若干位置为1。
5, 对于新要加入的元素的检查,首先将该元素经过上步中类似操作,获得k个随机数 h1,h2,......hk ,然后查看向量 V 的相应位置 h1,h2,......hk 上的值,若全为1,则该元素已经在之前的集合中;若至少有一个0存在,表明,此元素不在之前的集合中,为新元素。
算法特点:
对于已经在集合中的元素,通过5中的查找方法,一定可以判定该元素在集合中。
对于不在集合中的元素,可能会被误判在集合中。
其整个流程可以参照以下伪代码:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
参数计算:
在Bloom Filter表示方法中,对于一元素,某一位被置1的概率为
1m
,为0的概率为
1−1m
,散列函数执行k次,对于集合中所有元素,执行次数kn次,所以在运算结束时,某位仍为0 的概率为:
由于
有
因此误判概率为:
由以上式可知,m增大,P减小;对于给定的n和m,求最小的P值。
将上式取对数有:
对k求导:
令 ∂P∂k=0
有:
可以发现,在上式中等号的任意一边,后一个数取对数刚好是前一个数,所以等号左右两边结构相似。则有:
求得:
求得:
时,误判率最小
python3中pybloom
自己使用的是python3.5, 而官网pypi上下载的pybloom是时候python2版本的。所以直接安装pip install pybloom 或者Python setup.py install会出错。自己将文件中部分内容修改后就可以正常安装(python setup.py install)与运行。
源文件见个人CSDN下载页。
http://download.csdn.net/detail/a1368783069/9597338
如何使用,参考:http://axiak.github.io/pybloomfiltermmap/
Welcome to Python BloomFilter’s documentation!
If you are here, you probably don’t need to be reminded about the nature of a Bloom filter. If you need to learn more, just visit the wikipedia page to learn more. This module implements a Bloom filter in python that’s fast and uses mmap files for better scalability. Did I mention that it’s fast?
Here’s a quick example:
from pybloomfilter import BloomFilter
bf = BloomFilter(10000000, 0.01, 'filter.bloom')
with open("/usr/share/dict/words") as f:
for word in f:
bf.add(word.rstrip())
print 'apple' in bf
#outputs True

















 1853
1853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









