







行为决策系统的规划


1 行为决策基础
1.1 基本概念与任务
行为类型:
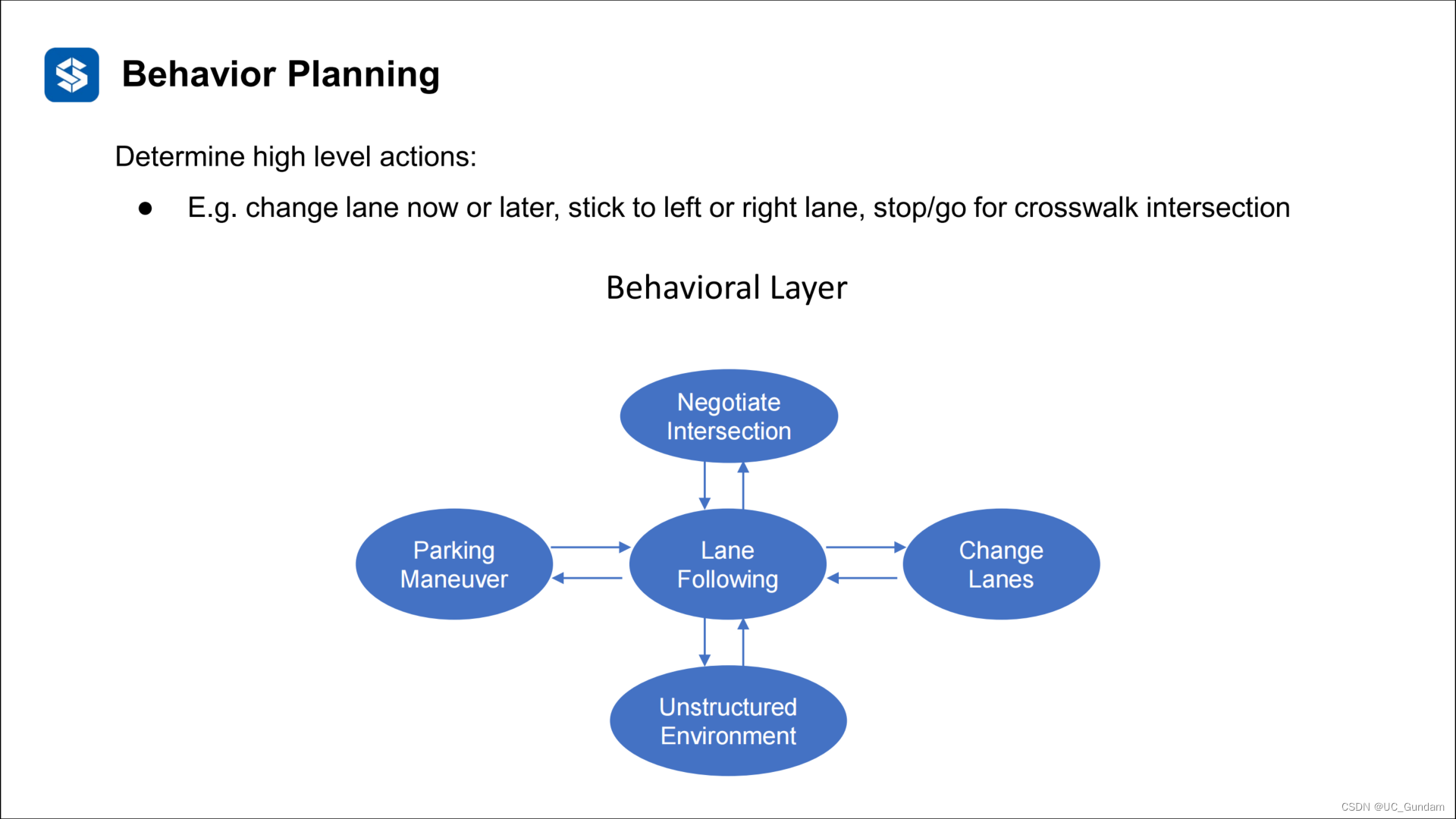
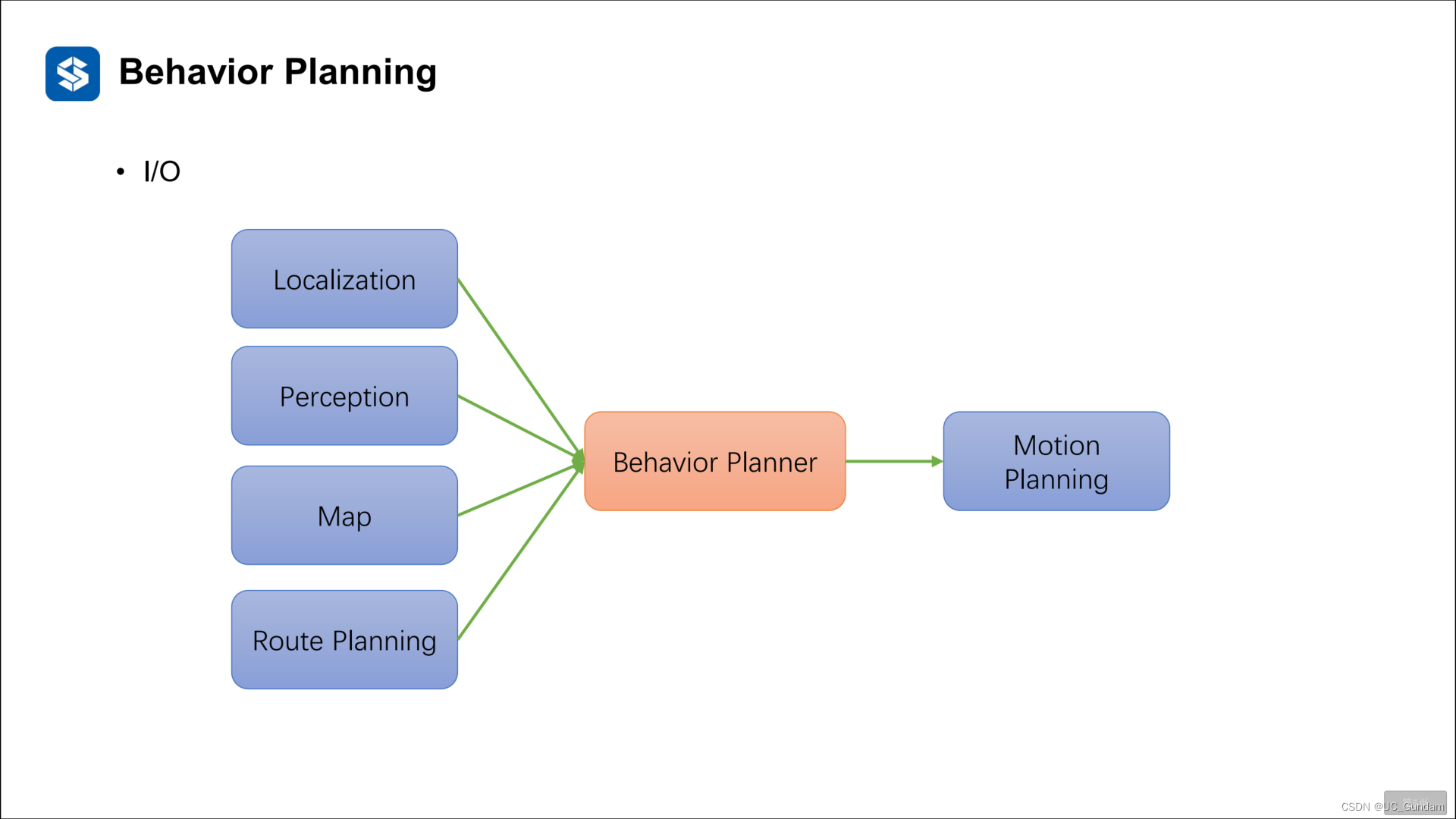
系统输入输出:
输入:定位、感知、地图等
输出:决策意图
小例子:

1.2决策系统的评价与挑战
评价指标

挑战
(1)决策密度
(2)决策时的不确定性

从功能模块看不确定性:
定位:误差、偏差
控制:跟踪误差
感知:感知到信息的不确定性
预测:未来状态的不确定性
可见性:环境中有不可见的信息

1.3 决策系统的基本分类

2 有限状态机
2.1 模型概述
车辆在某些状态下的动作,适用于有限的简单场景
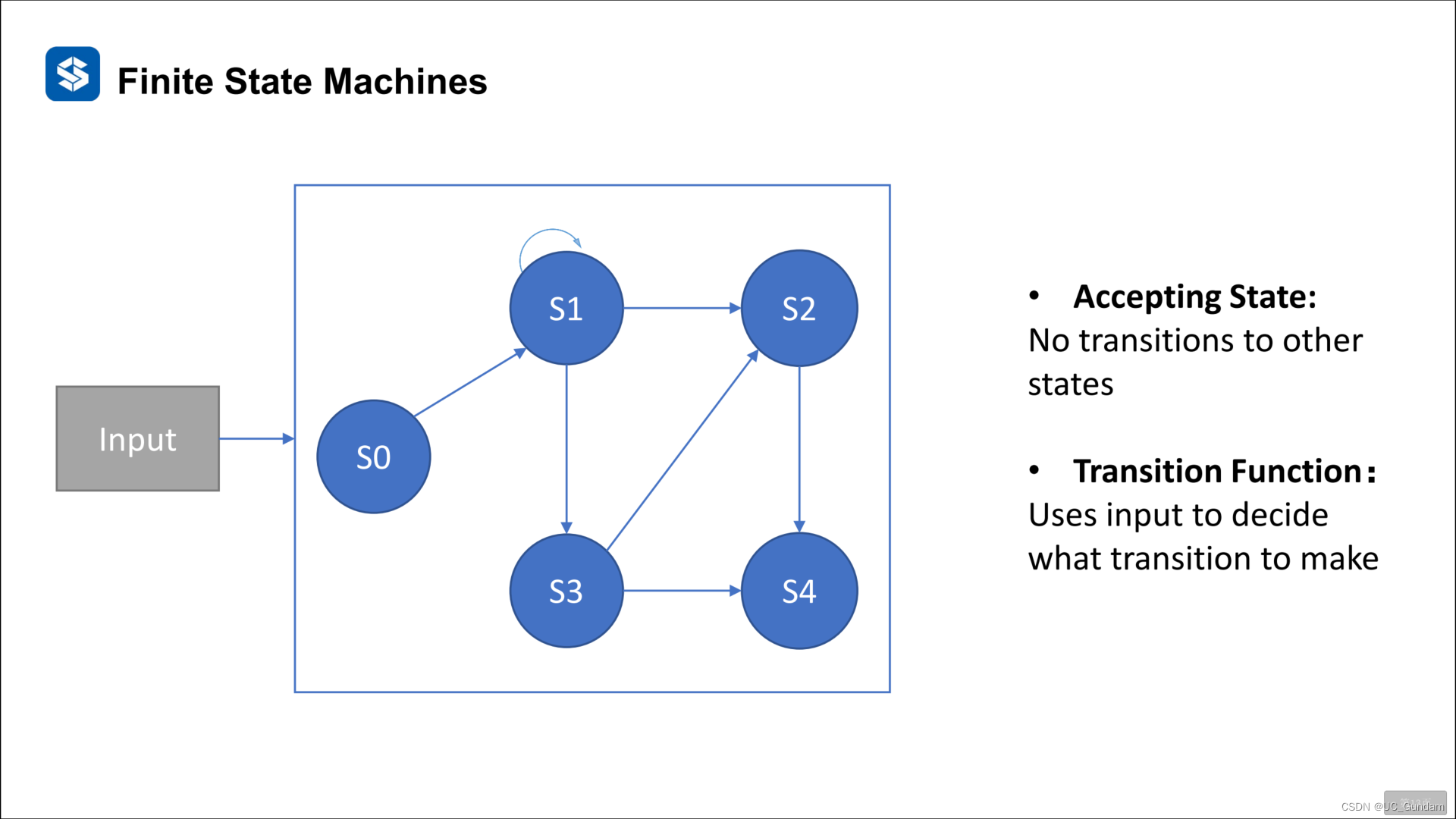
基本例子:
5个动作可选择,根据车辆的状态选择动作。
另一个停车的例子:

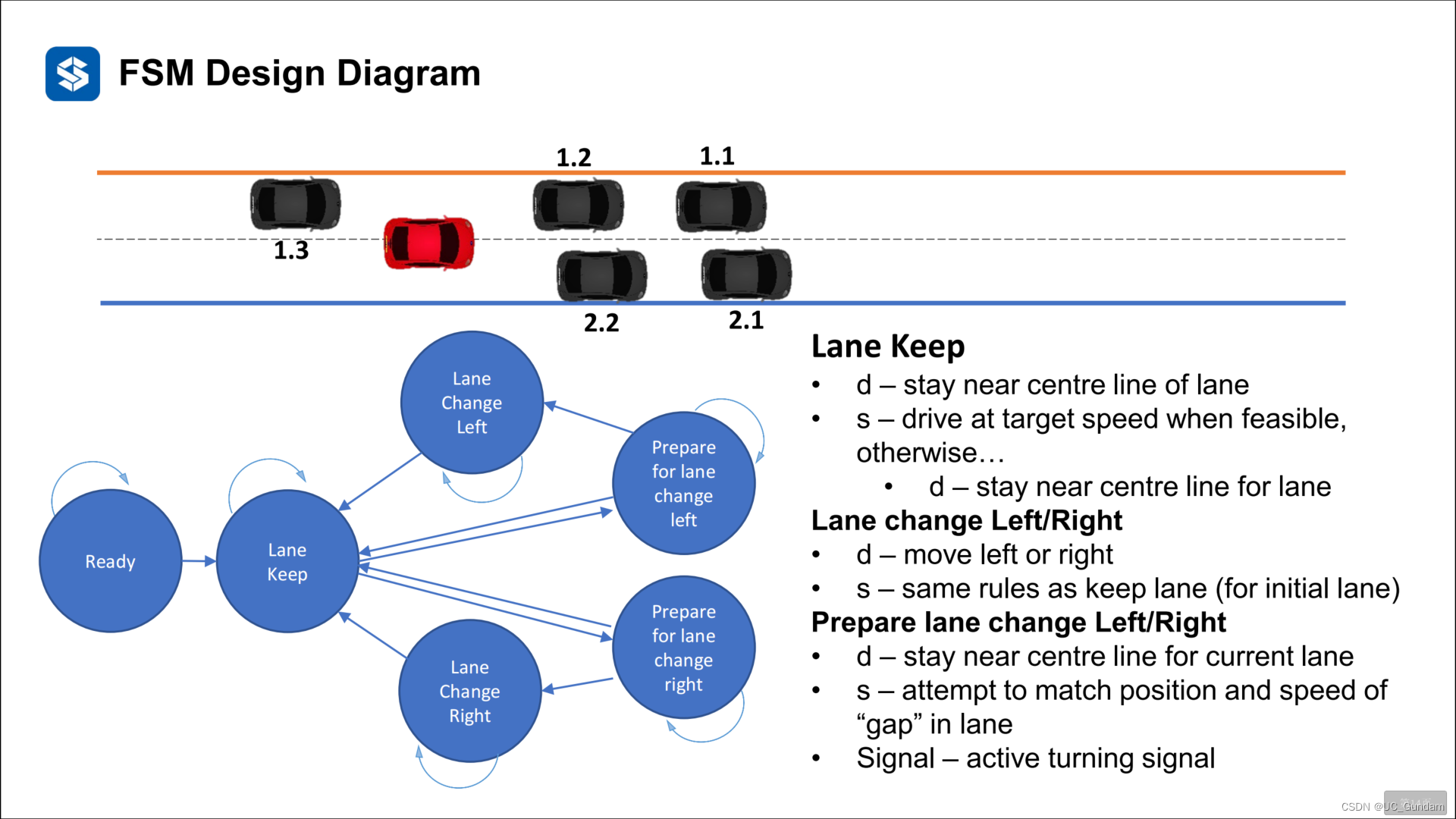
2.2 状态机的有向图表示
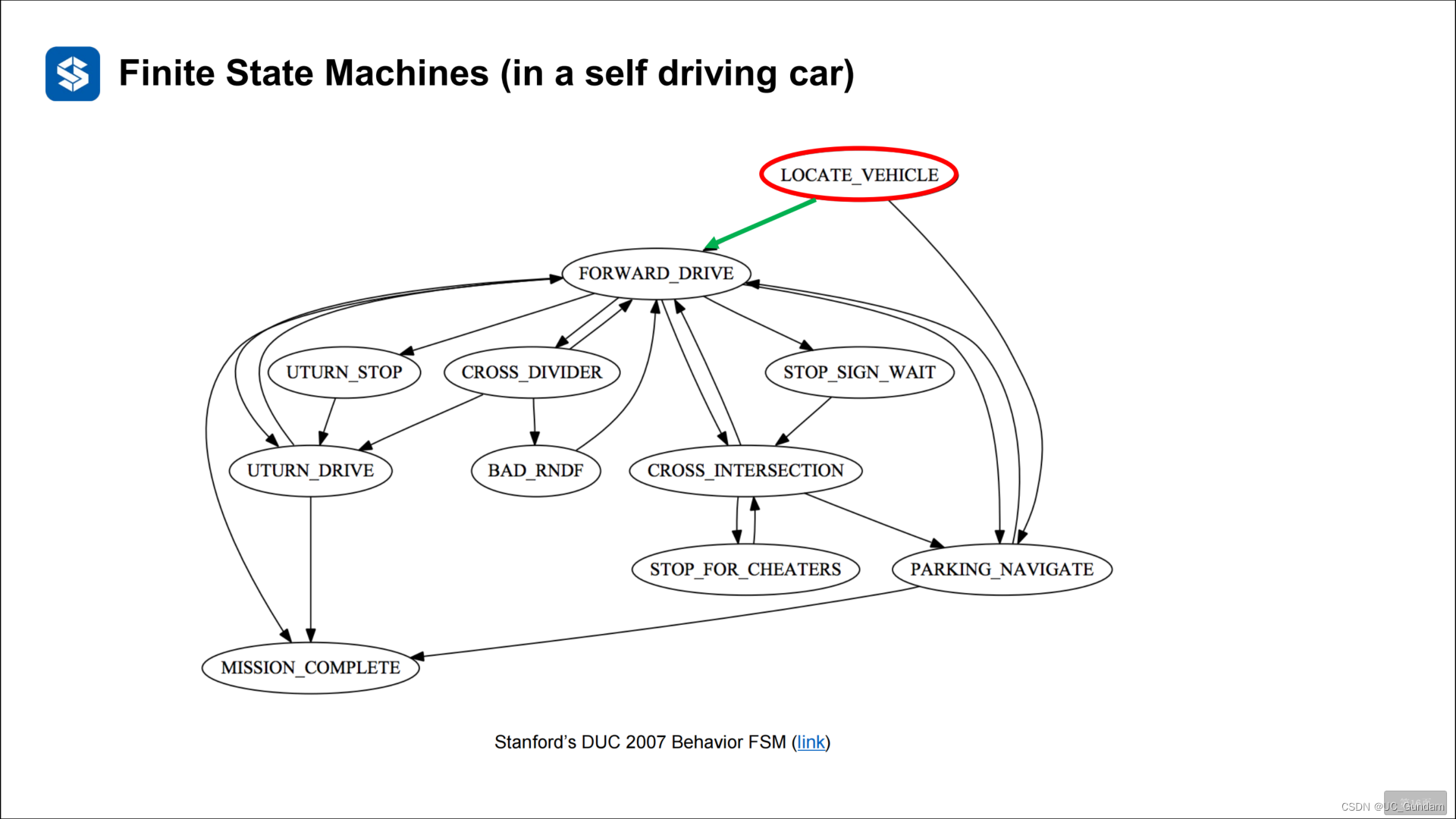

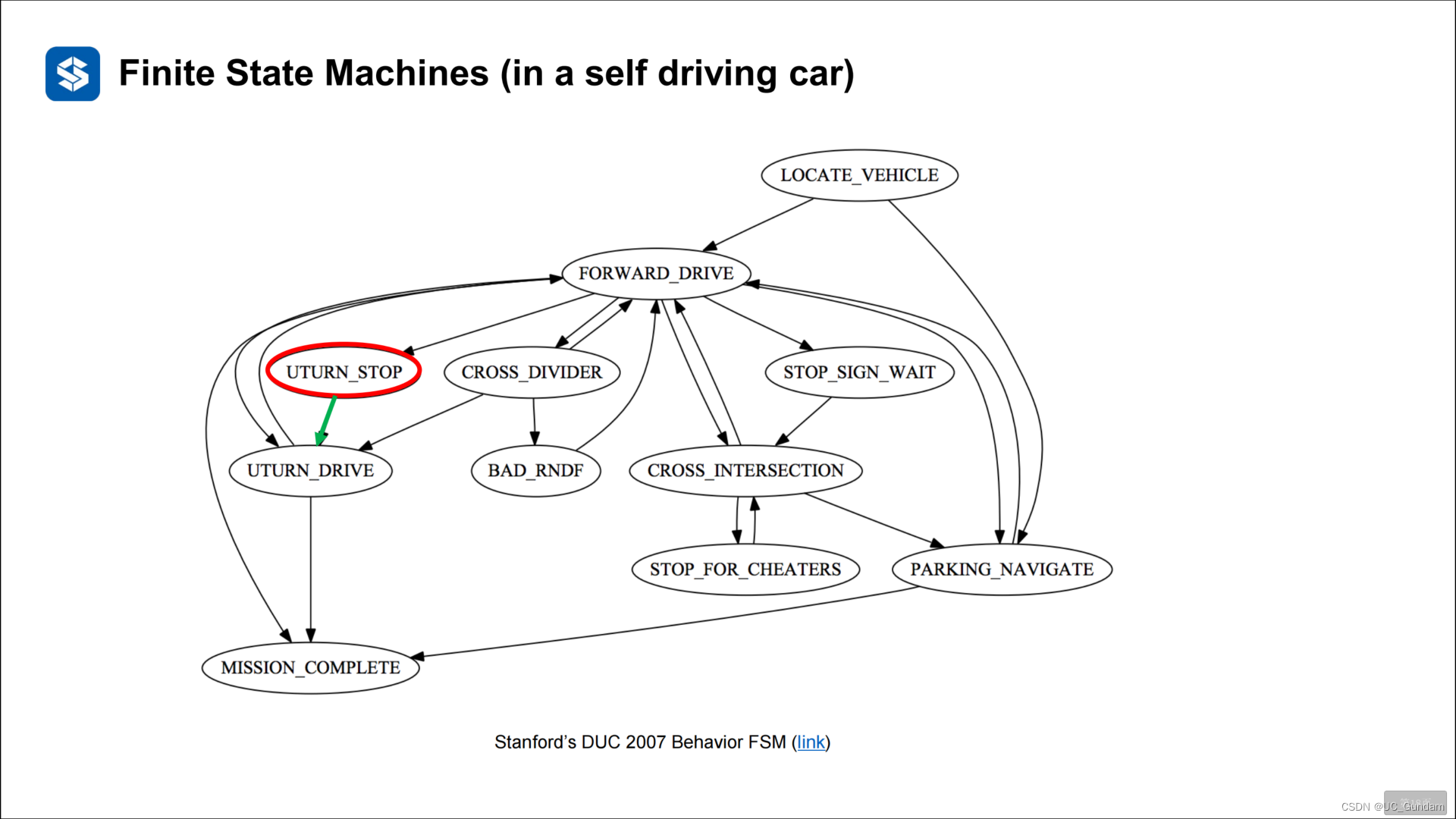


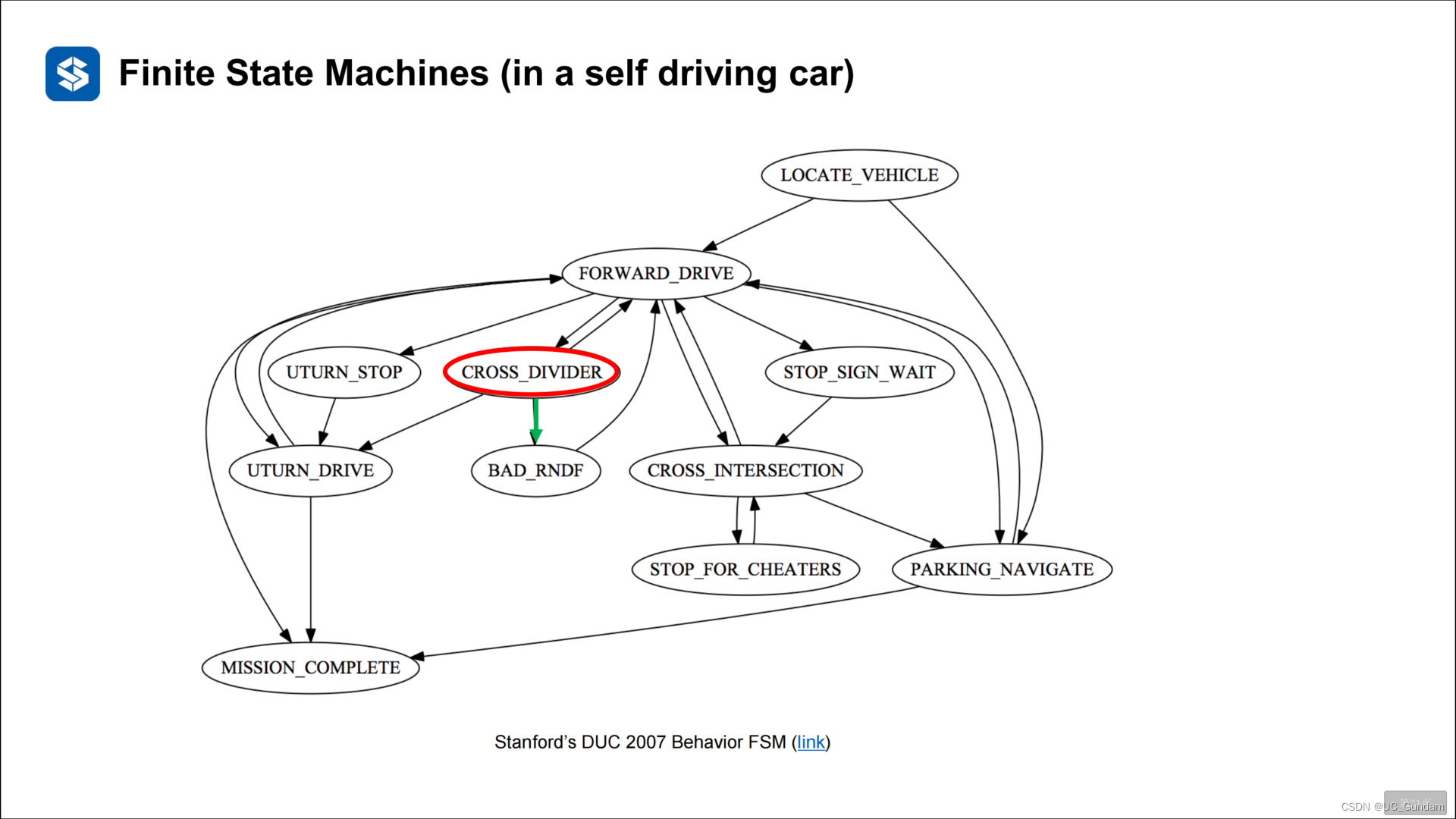
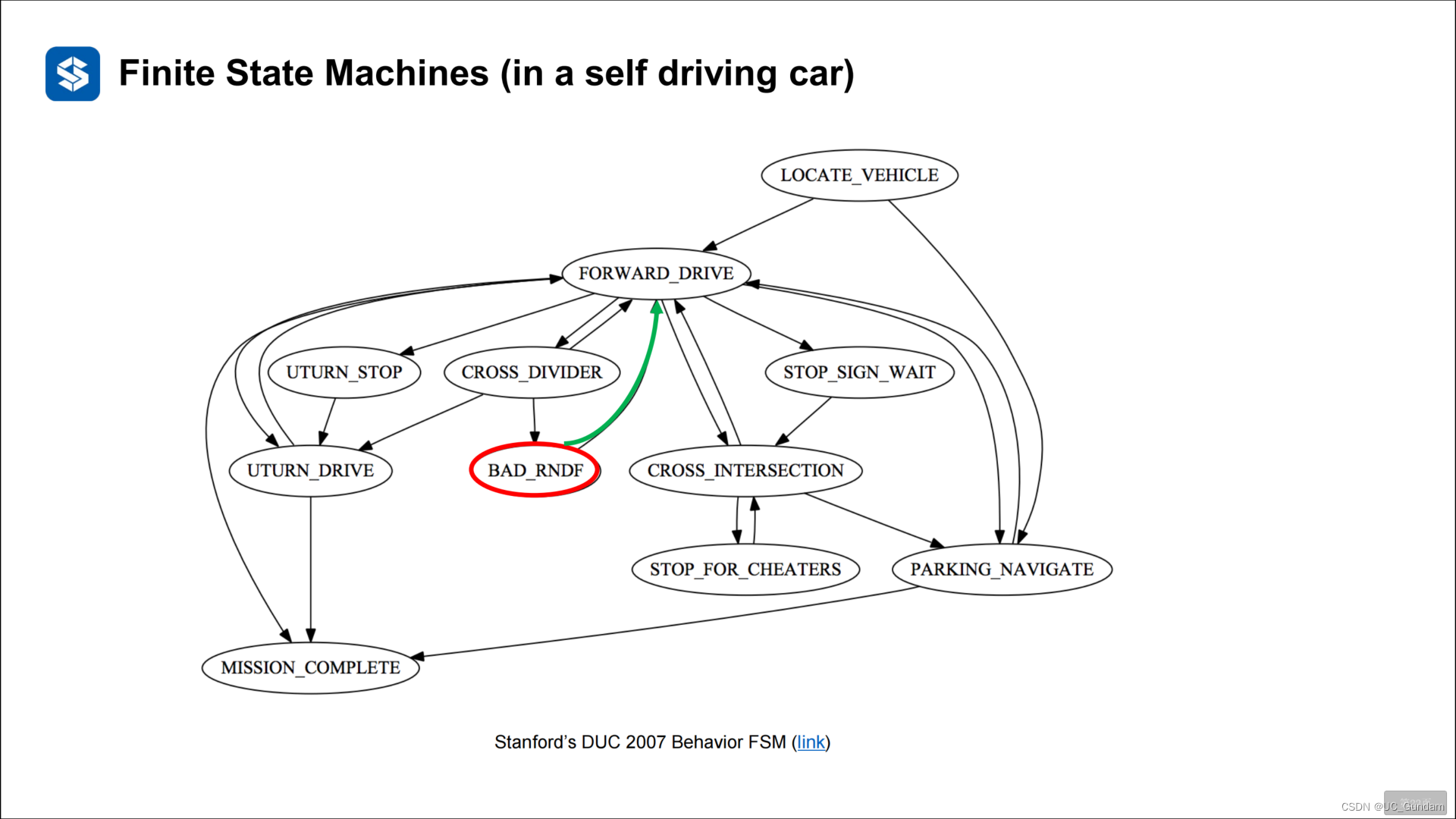
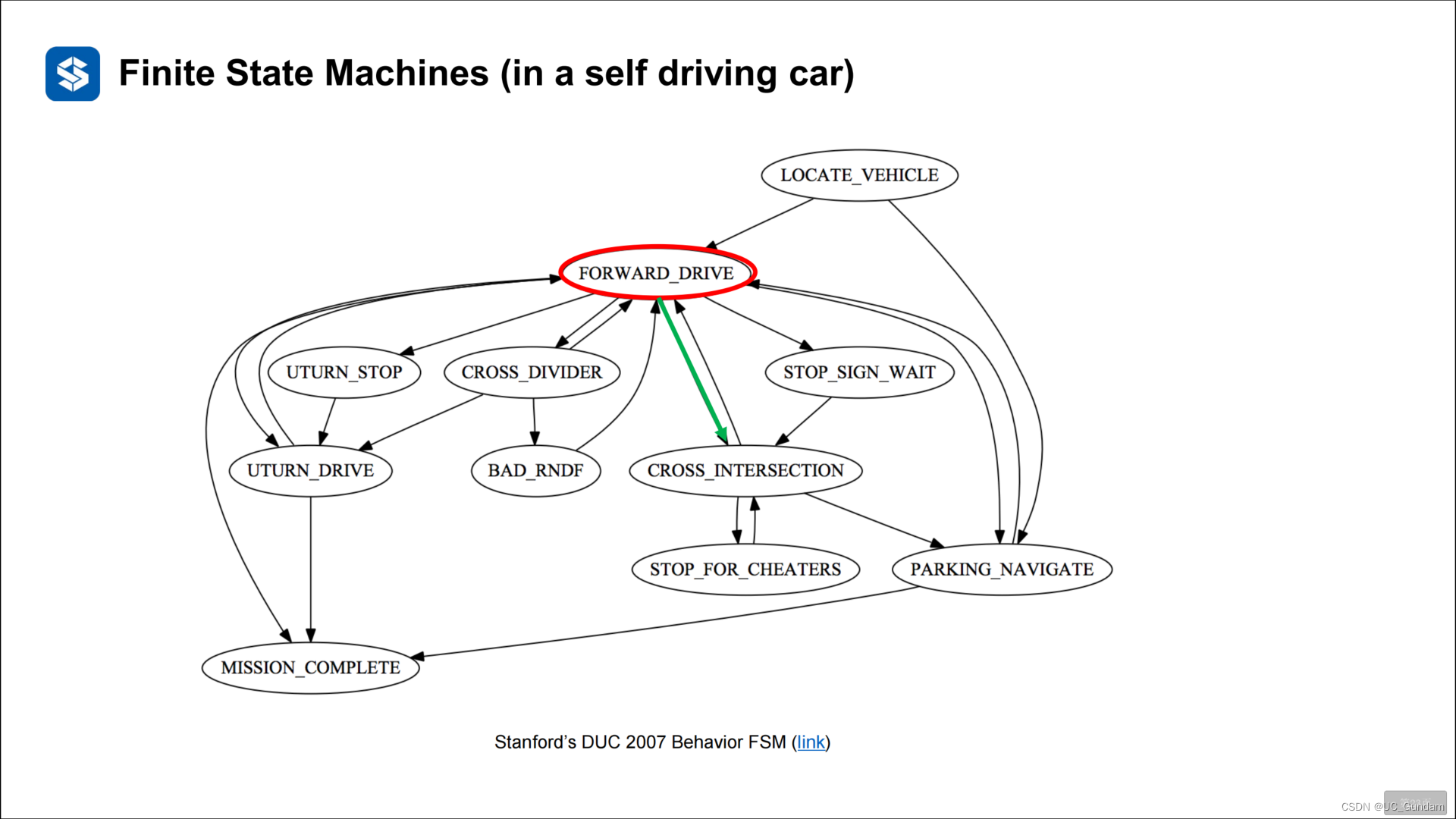

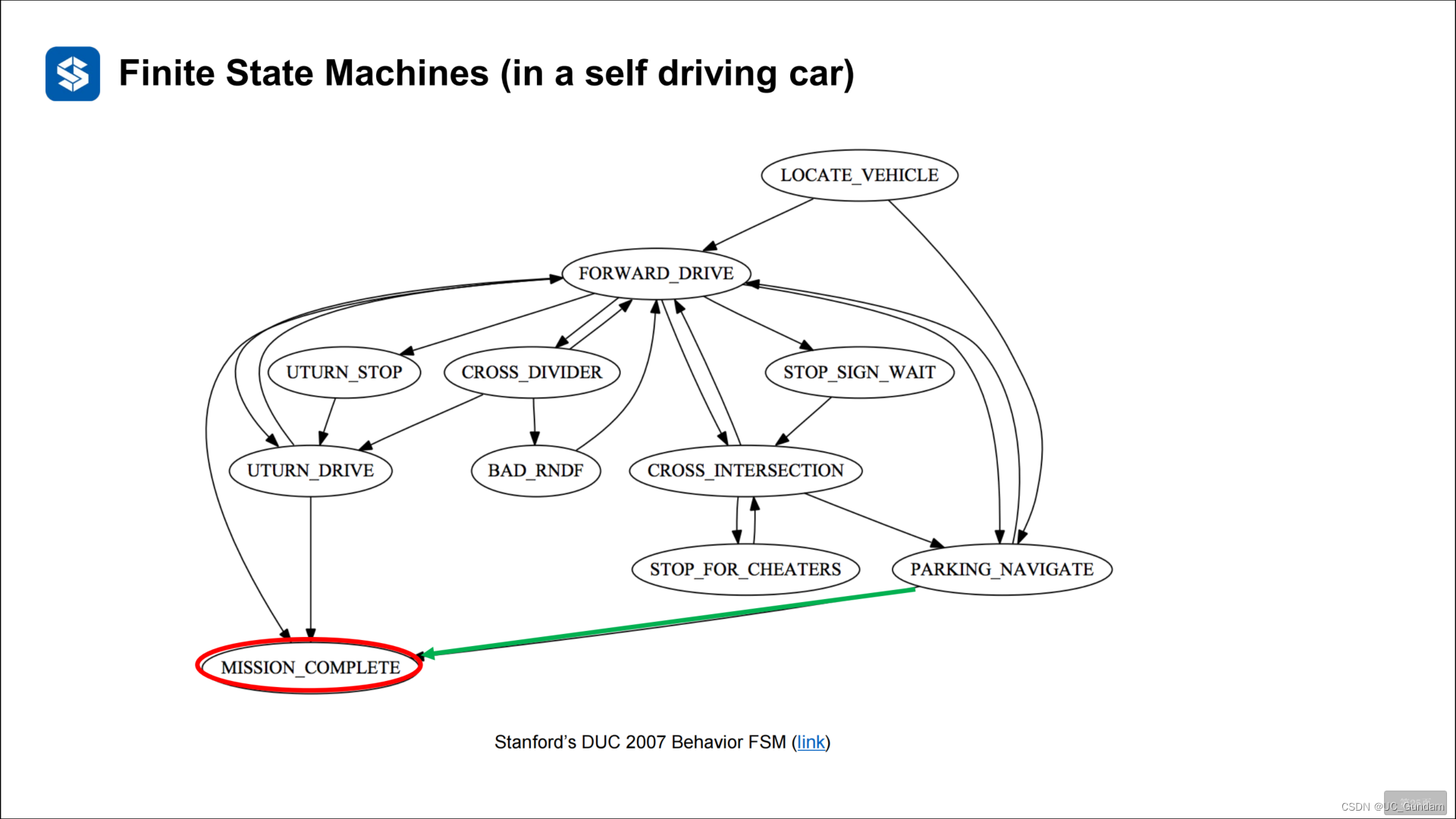
2.3 有限状态机的问题
(1)很复杂,系统模型庞大,有向图难以全面绘制,所以引入分层状态机
分层状态机:将相同的状态划分到子集
比如下图中的变道子集合
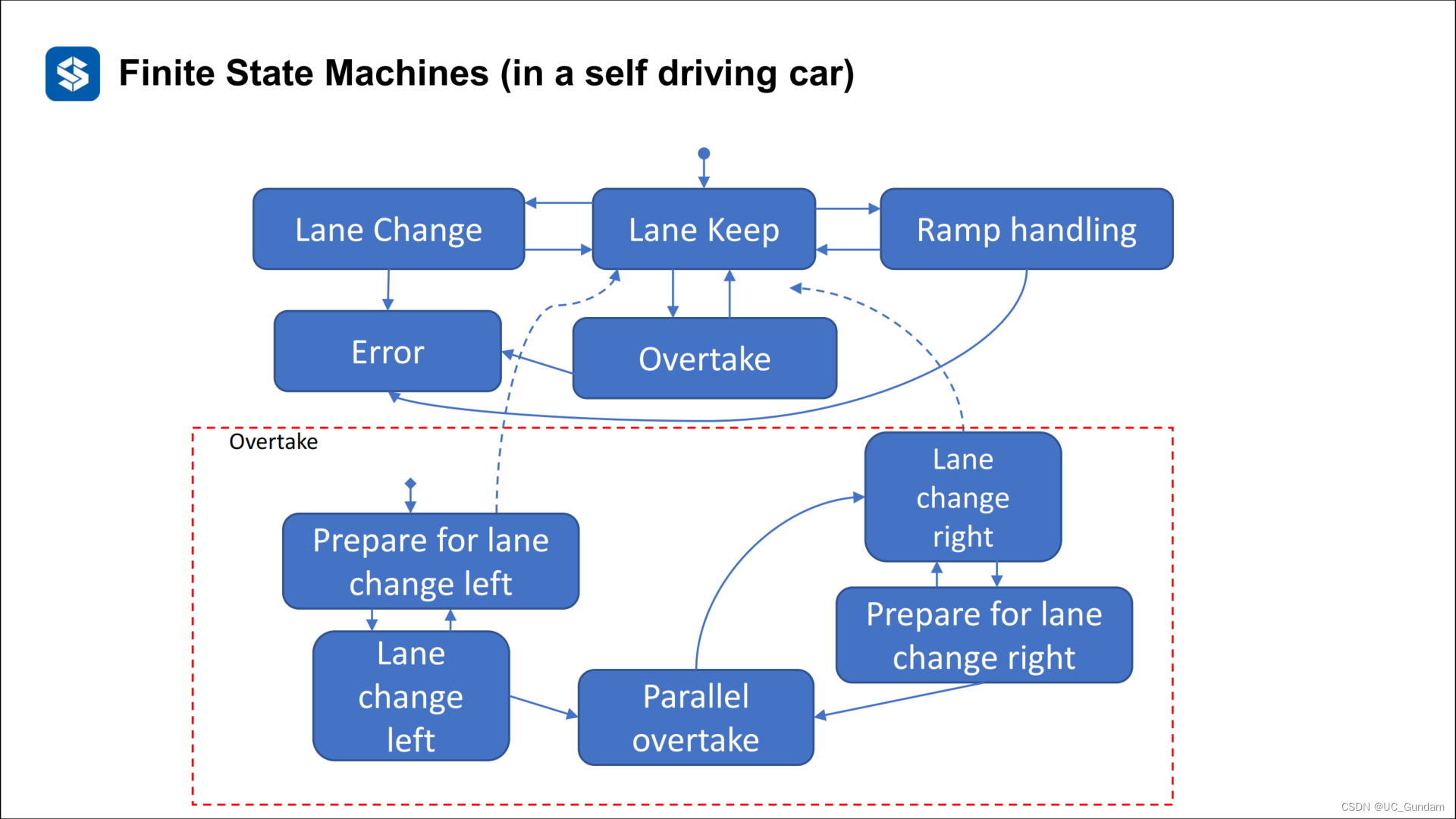
(2)其他的一些问题
庞大、可扩展性、可读性、可维护性、复用性很差

3 行为树决策法
3.1 基本结构

将场景的任务模块化。
和状态机的方法是类似的,都是将场景任务与决策联系起来。换了一种方式表述。
更容易被理解,不容易出错。
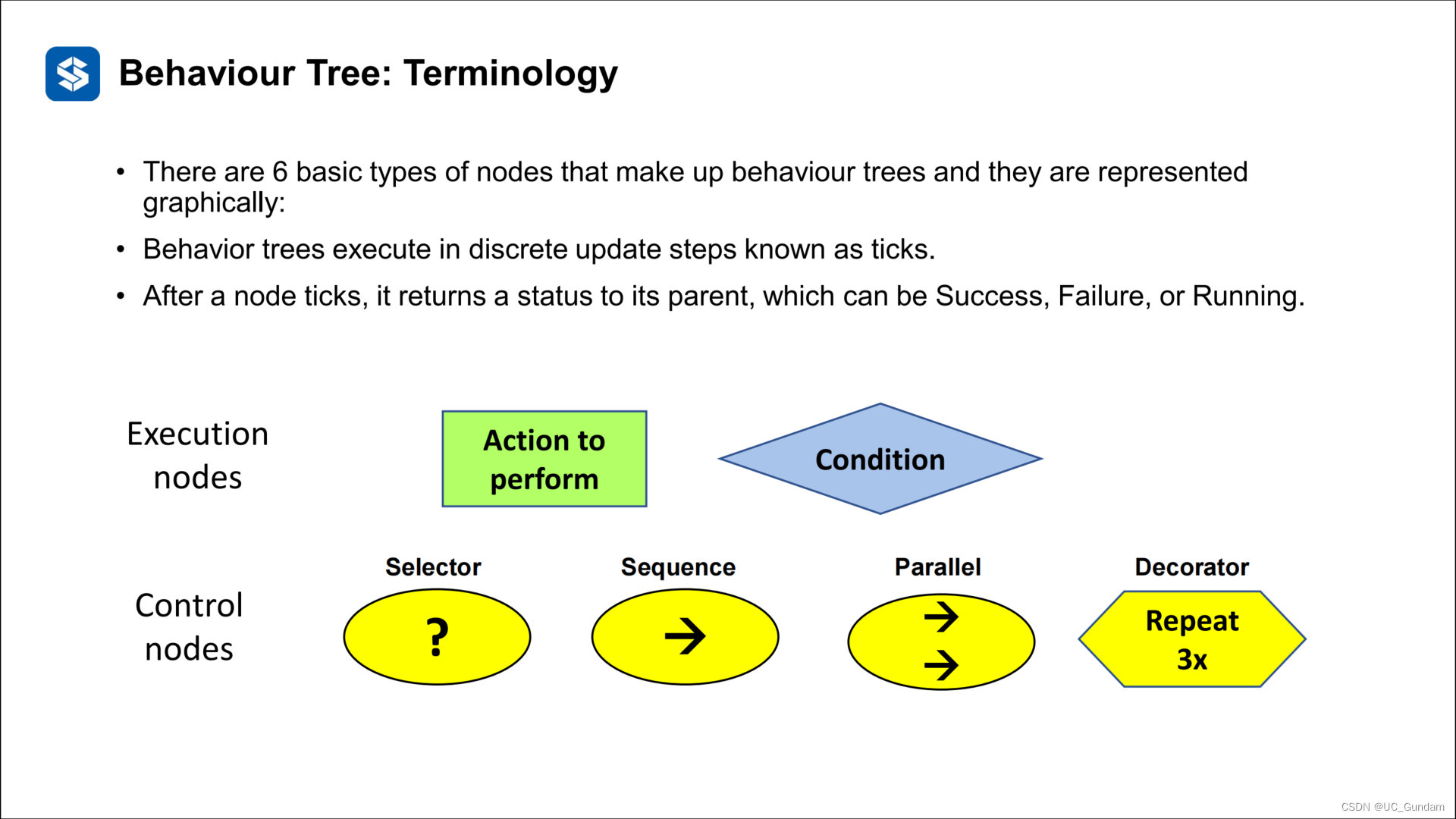
行为树被公式化为具有树结构的有向图,并具有以下特点:
行为树是树:它们从根节点开始,设计为按特定顺序遍历,直到达到终端状态(成功或失败)。
叶节点是可执行的行为:每个叶都会执行一些操作,无论是简单检查还是复杂操作,并输出状态(成功、失败或正在运行)。换句话说,叶节点是将BT连接到特定应用程序的较低级别代码的地方。
内部节点控制树遍历:树的内部(非叶)节点将接受其子节点的结果状态,并应用自己的规则来指定下一个应该扩展哪个节点。

模型结构
构成行为树的节点有6种基本类型,它们以图形方式表示:
行为树在离散的更新步骤中执行,称为滴答声。
节点发出滴答声后,它会向其父节点返回一个状态,可以是“成功”、“失败”或“正在运行”。
动作节点
动作节点是树的叶子
它执行任务,如果操作完成,则返回成功;如果任务无法完成,则为失败;如果任务正在执行,则返回运行。

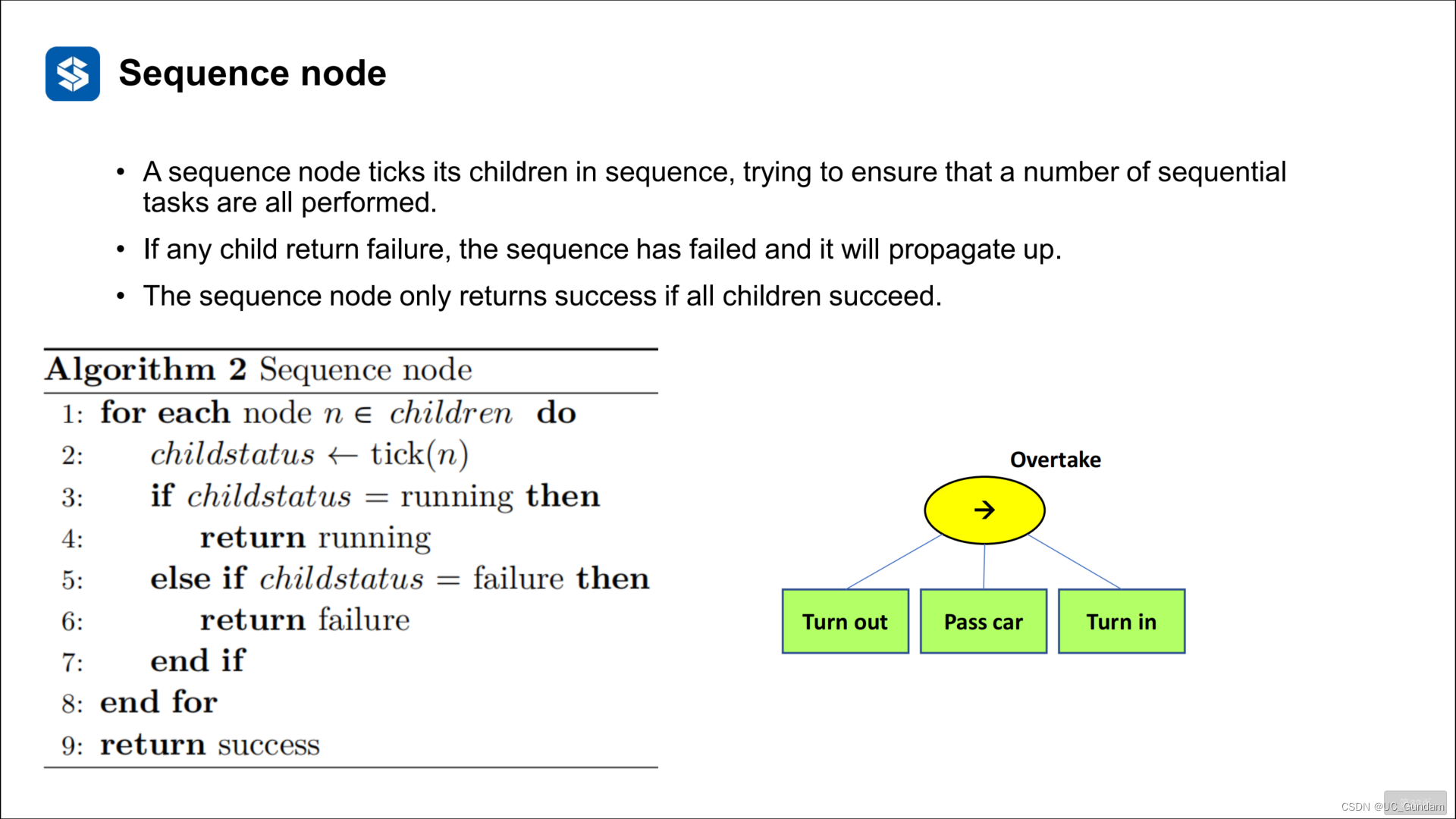
序列节点
一个序列节点按顺序标记其子节点,试图确保所有序列任务都被执行。
如果任何子级返回失败,则序列已失败,并将向上传播。序列节点仅在所有子级成功时返回成功。
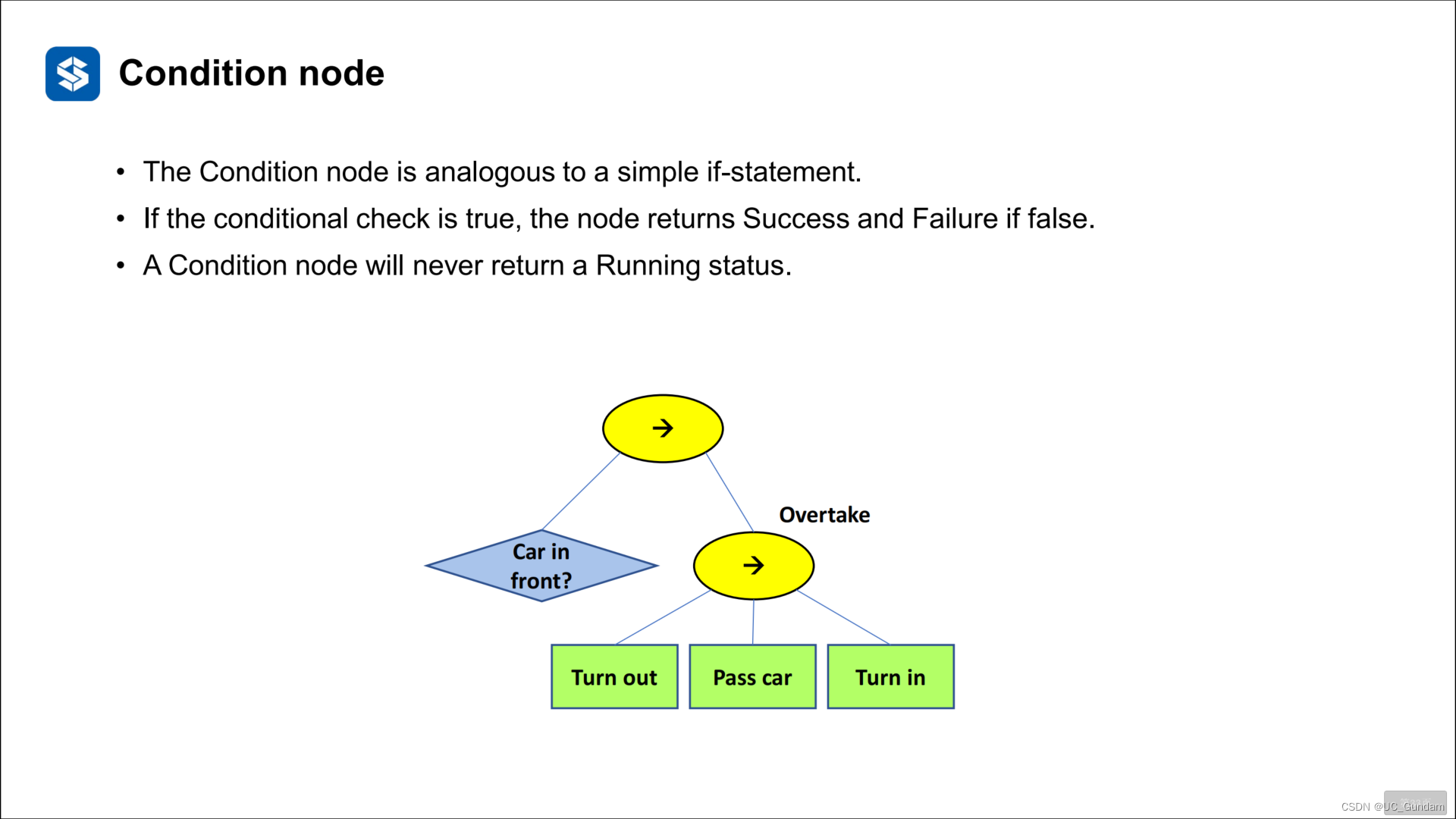
条件节点
条件节点类似于简单的if语句。
如果条件检查为true,则节点返回Success,如果为false,则返回Failure。条件节点永远不会返回Running状态。
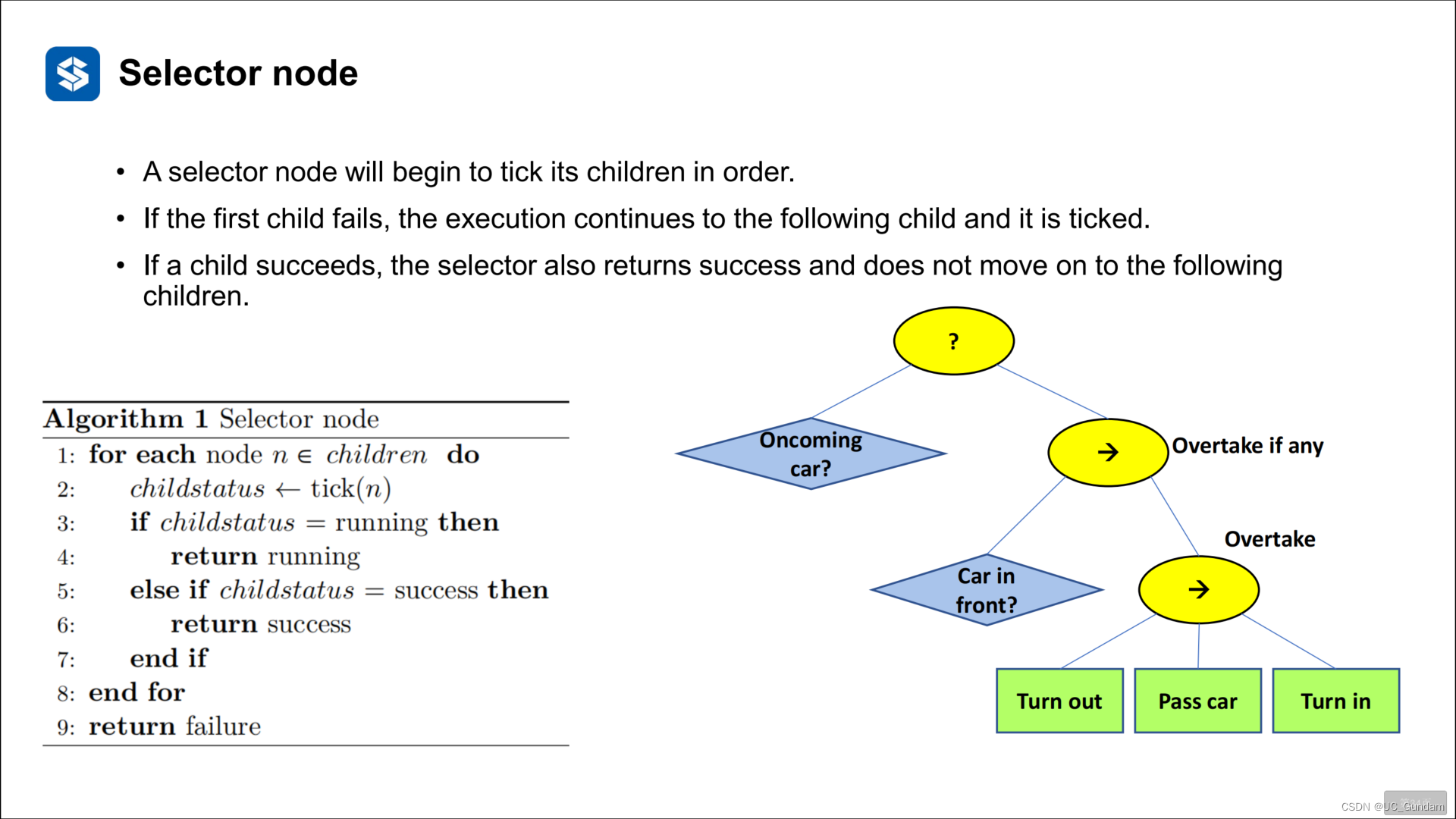
选择节点
选择器节点将开始按顺序勾选其子节点。
如果第一个子节点失败,执行将继续到下一个子节点,并勾选。
如果一个子节点成功了,选择器也会返回成功,并且不会继续下一个。
并行节点
并行节点同时标记其所有子节点,从而允许多个Action节点同时进入arunning状态。
并行节点自身报告访问/失败之前需要多少子节点才能成功的要求可以根据每个实例进行自定义。

装饰器节点
decorator节点包装底层子树或子树的功能。
例如,它可以影响基础节点的行为或修改返回状态。

超车场景的节点图

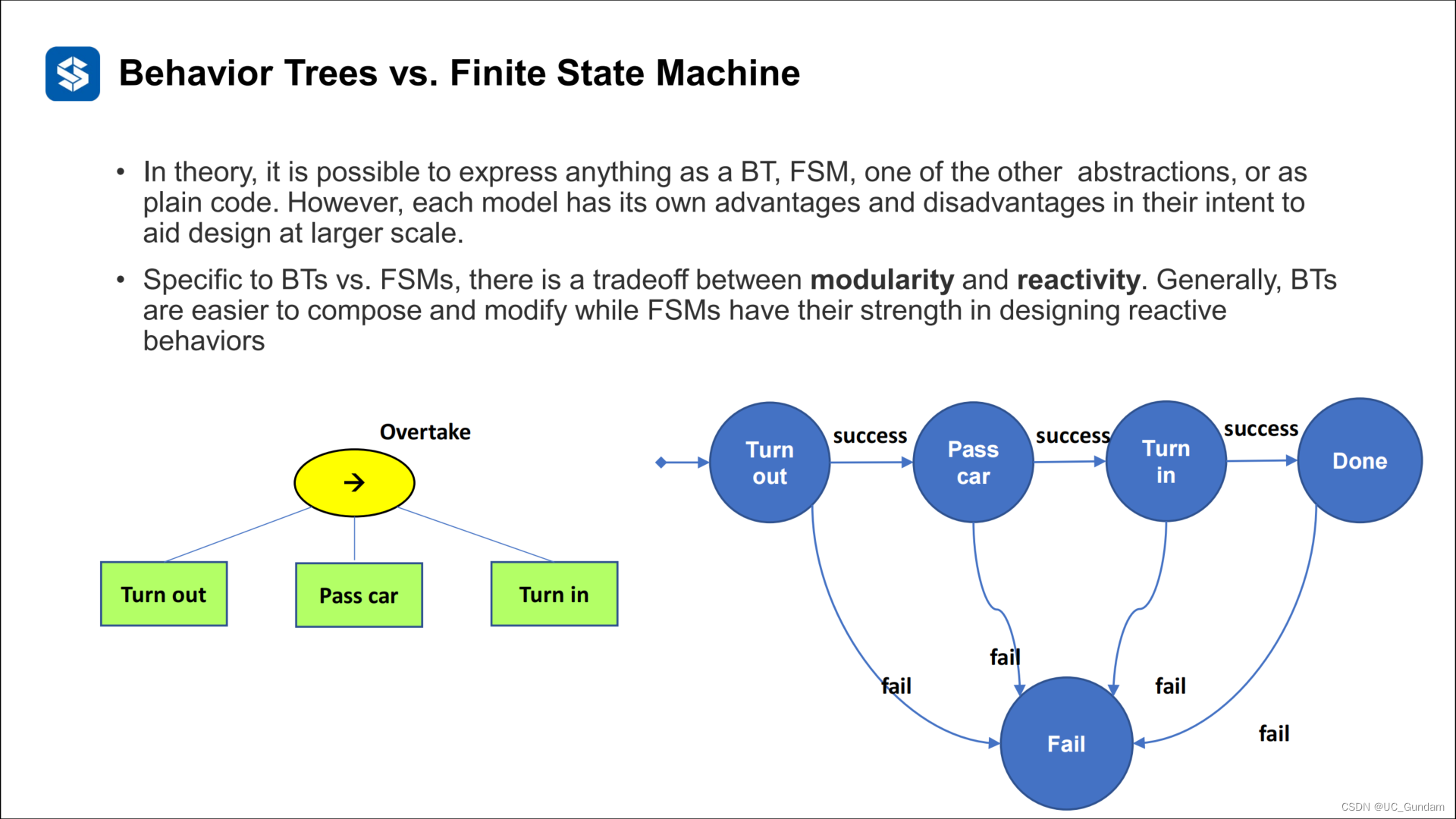
3.2 与状态机的比较
理论上,可以将任何东西表示为BT、FSM、其他抽象之一或asplain代码。然而,每种模型都有其自身的优点和缺点,它们的意图是在更大的规模上进行设计。
具体到BTs和FSM,在模块化和反应性之间存在权衡。通常,BTs更容易组成和修改,而FSM在设计反应性方面具有优势。


4 基于部分可观的马尔科夫决策过程

4.1 马尔科夫过程简述
下一状态仅仅由当前状态决定。

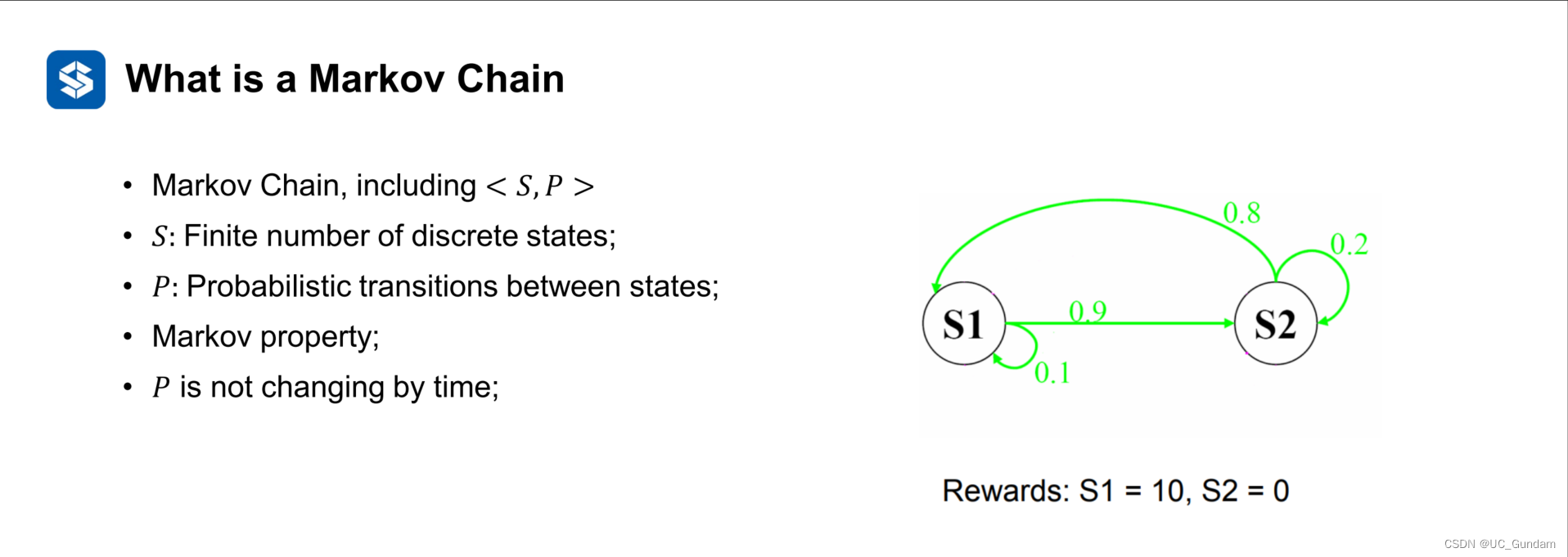
隐性马尔科夫链
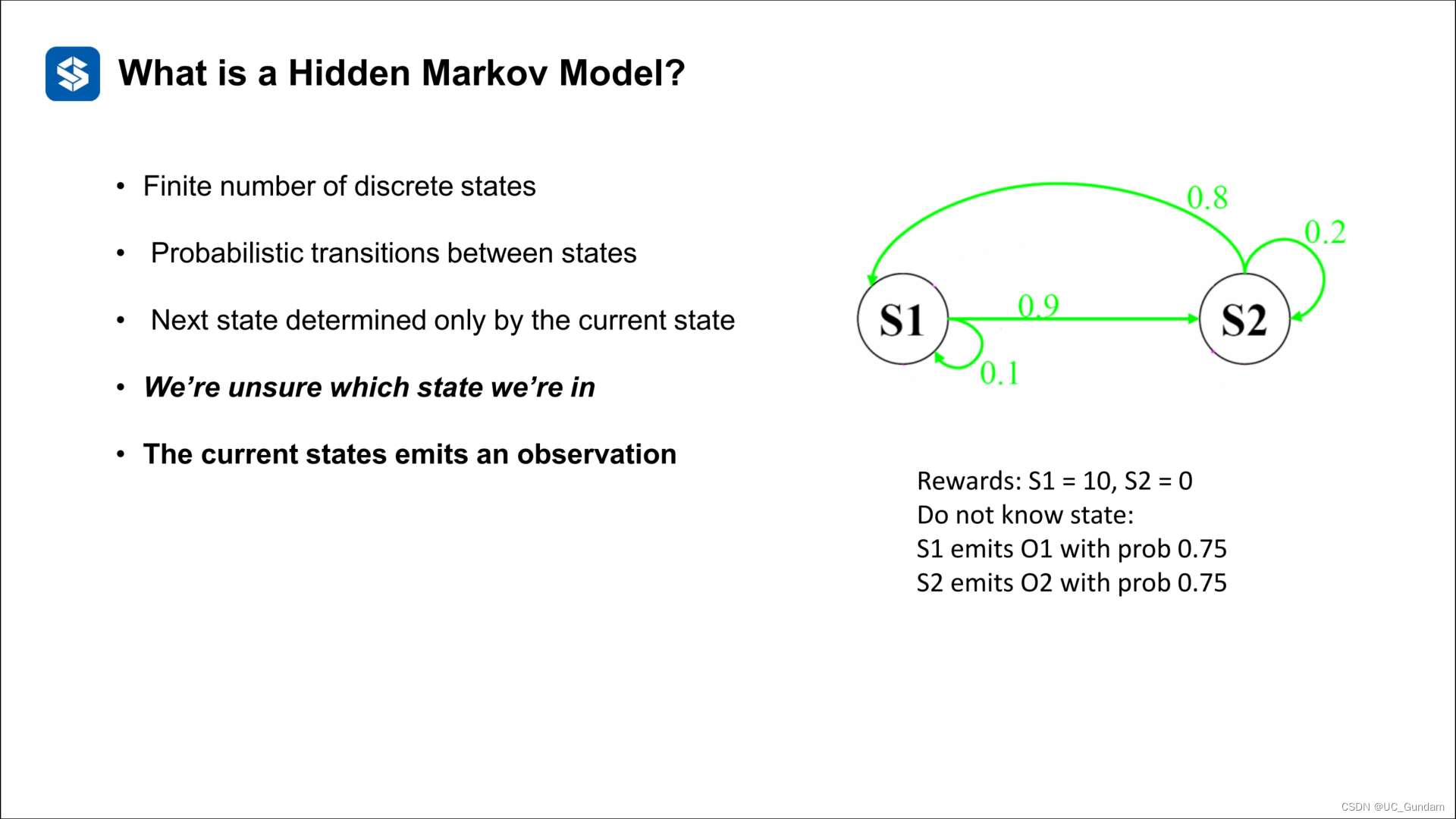
4.2 马尔科夫决策过程
为基本的马尔科夫链加入了Action

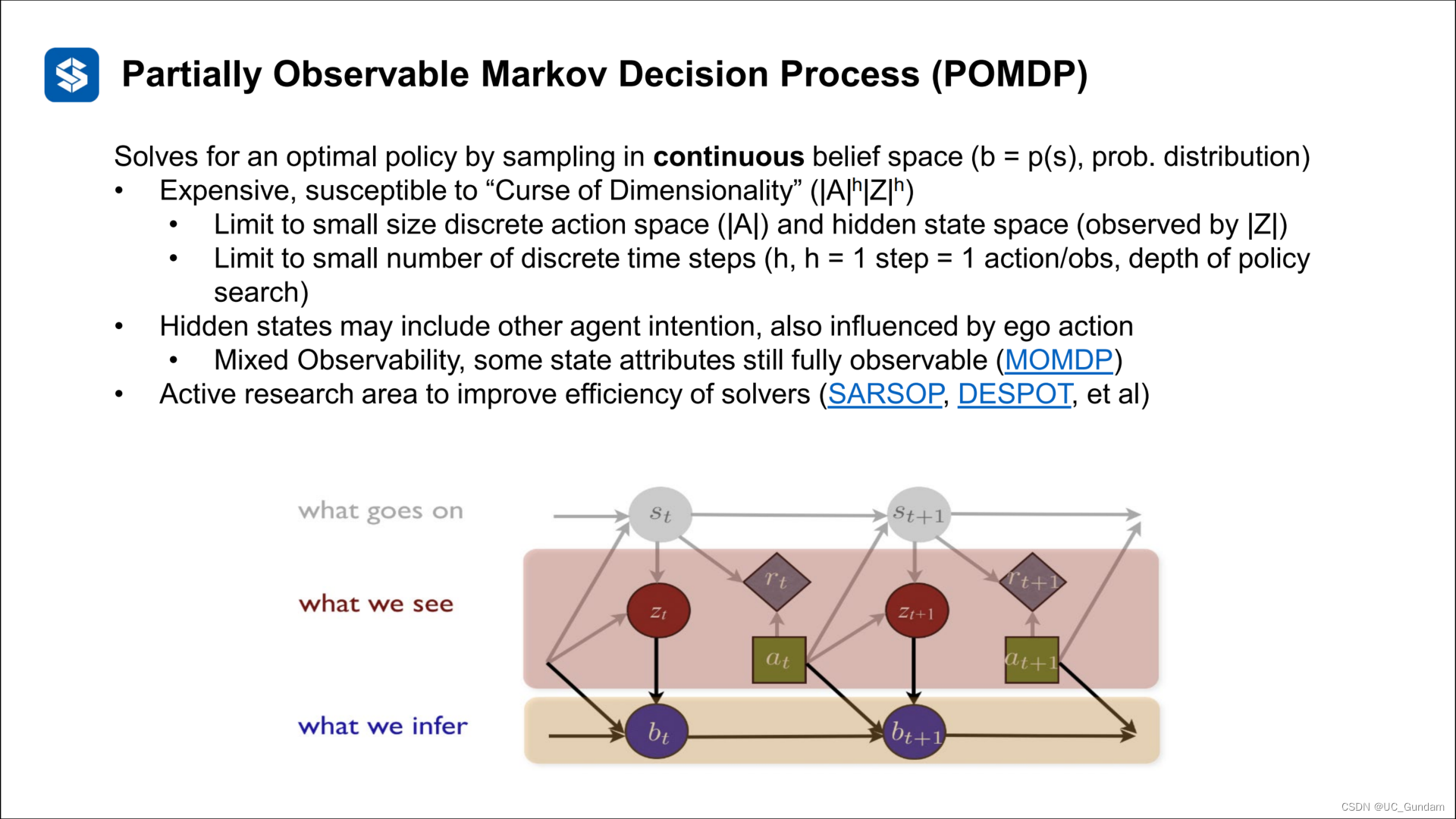
部分可观的马尔科夫决策过程

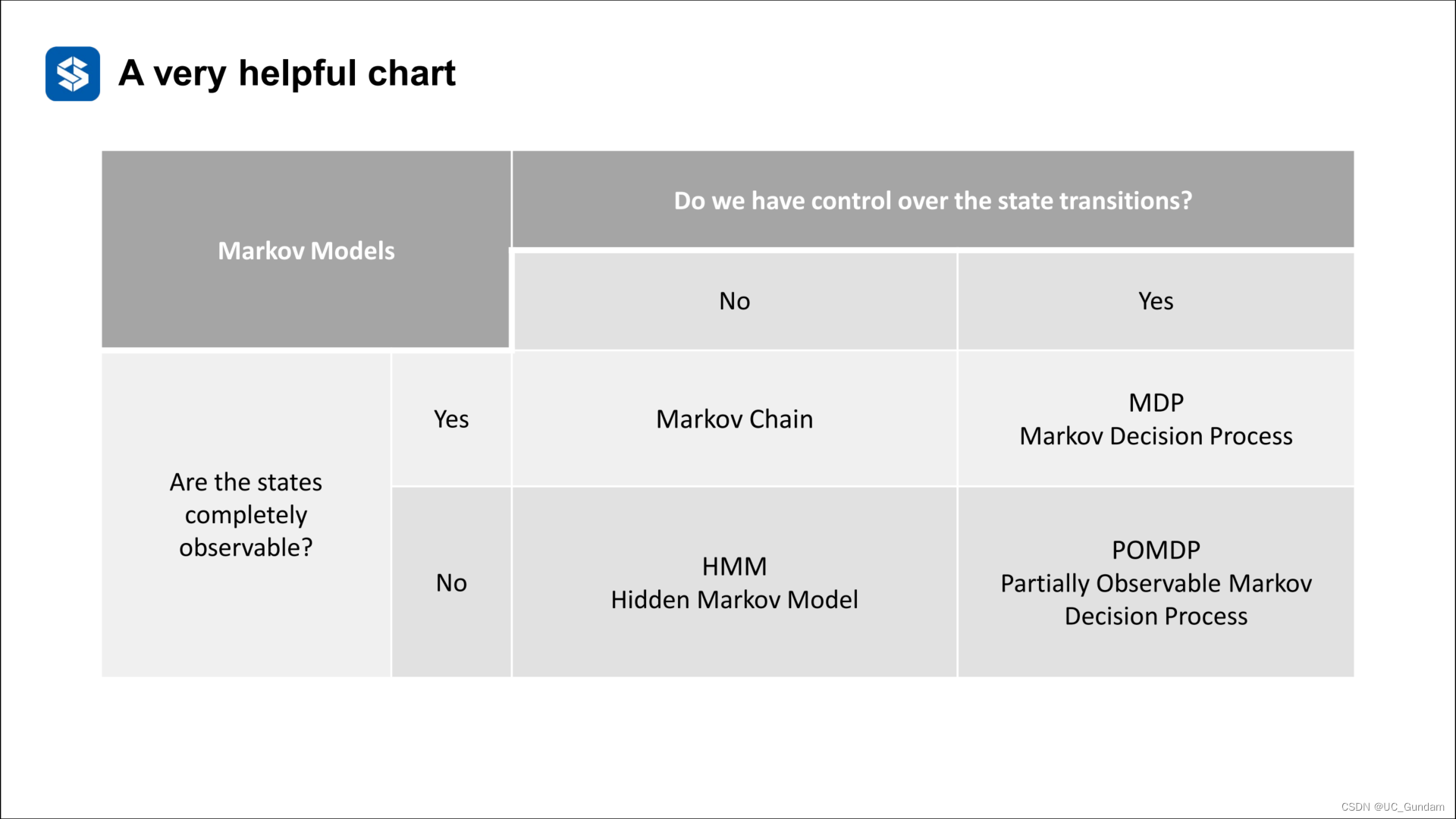
上述几个过程的比较表格
部分马尔科夫决策过程的解决方法:引入预测模型
4.3 马尔科夫决策过程在无人车中的应用
MDP的基本模块再次表述

无人车的基本问题:找到一个目标策略,使得奖励最大化

马尔科夫决策过程的挑战:
(1)奖励设计(2)安全性(3)舒适性

5 模仿学习
应用在多步决策方面效果较好。

状态——动作映射关系的学习
状态:感知信息
动作:驾驶员的操作数据
进行监督学习

存在复合误差
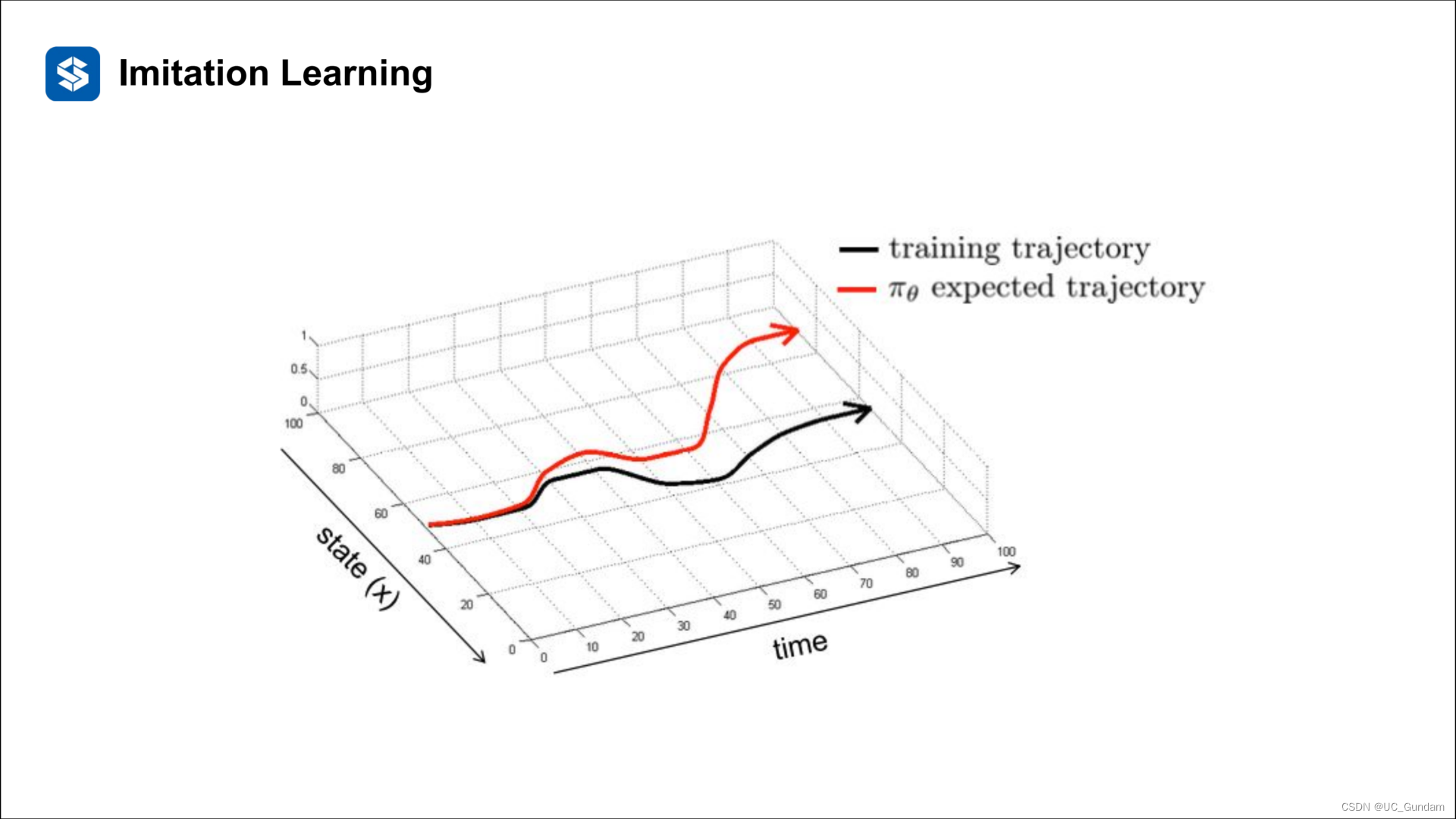
数据增强
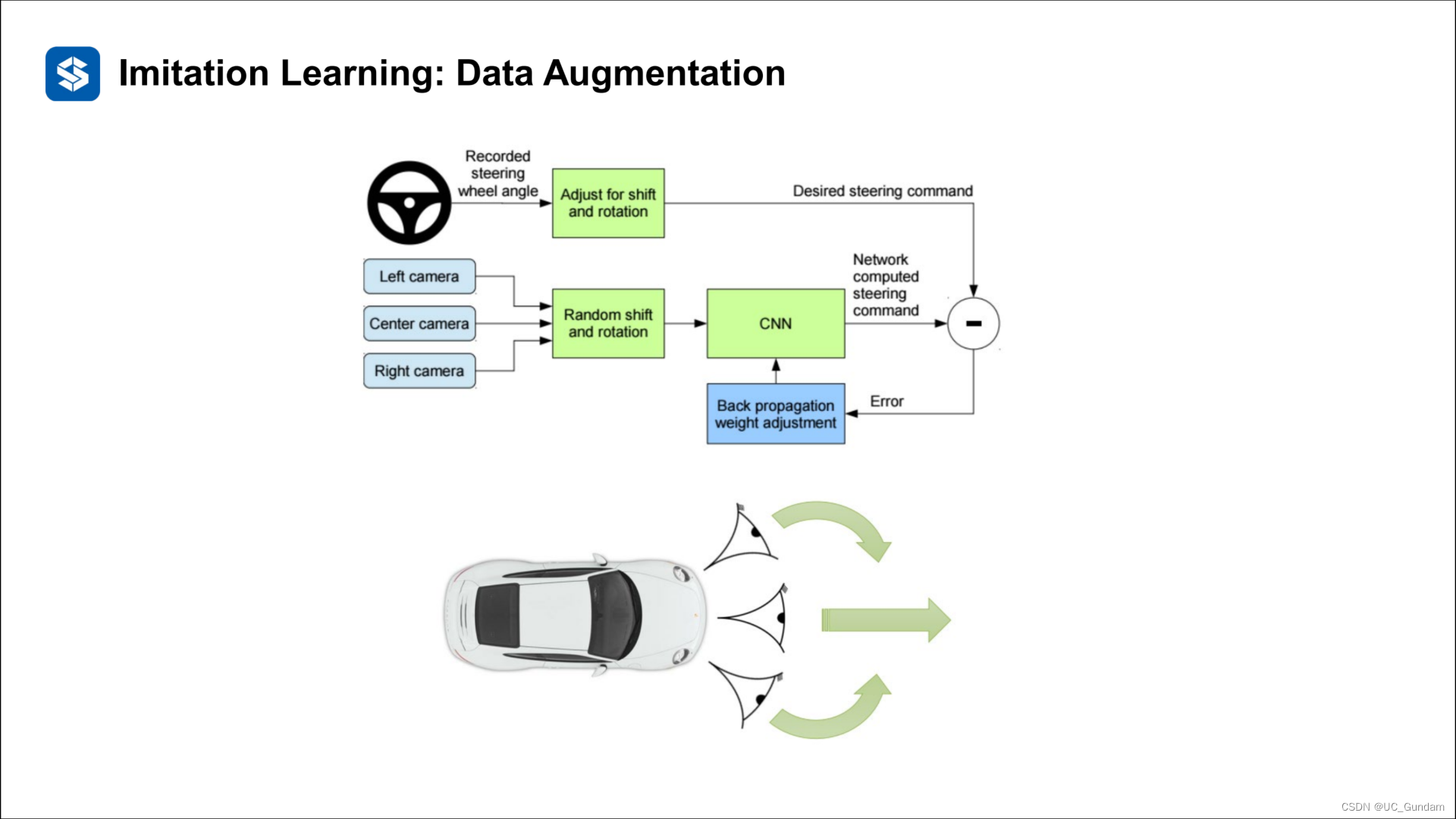
这个文章的作者将优化目标转移到了采集的数据上
人为打标签

模仿学习的基本问题:
其他挑战:
1.如果没有自己的反馈,专家很难为转弯提供正确的幅度
解决方案:向专家提供视觉反馈
2.专家对车辆行为的反应时间很长,这会导致不完美的命令
解决方案:离线慢动作回放并记录他们的行为
3.执行不完善的策略会导致事故、崩溃障碍
解决方案:安全措施再次使列车和测试之间的数据分布不匹配,但足够好。

两种广泛的方法:
直接:监督政策培训(将状态映射到行动),使用演示轨迹作为基本事实(又称行为克隆)
间接:了解教师的未知奖励功能/目标,并从中得出政策,即反向强化学习。

6 总结
基于规则的方法与基于学习的方法之间的比较:
(1)基于规则的方法
逻辑容易理解稳定
易于建模和调整
对处理器性能的要求更低
通过级联多层易于扩展
车辆行为的不连续性
如果没有精心设计,规则可能会变得无效。有限状态机可能无法覆盖所有场景
长尾效应

(2)基于学习的方法
更好的场景覆盖率优势,每个场景都可以用大数据进行训练
通过网络可以简化决策
一些学习算法能够提取环境特征和决策财产。
无需遍历所有场景,随着收集到更多数据,将对WnIcn进行培训/改进。
难以理解为什么要做出某些决定
难以修改模型
不同的场景可能会导致完全不同的模型
需要大量实验数据作为训练样本
性能高度依赖于数据的质量



















 2085
2085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











