









最近我们被客户要求撰写关于缺失值填充的研究报告,包括一些图形和统计输出。
在每个现实世界的数据集中,缺失数据值几乎是不可避免的,在典型的数据收集过程中几乎不可能避免。
这可能由于各种原因而发生,例如文件丢失/损坏、数据输入过程中的错误、数据收集过程中的技术问题以及许多其他原因。
【视频】为什么要处理缺失数据?如何R语言中进行缺失值填充?
为什么要处理缺失数据?如何R语言中进行缺失值填充?


在任何现实世界的数据集中,通常都会有一些数据科学家和机器学习工程师必须处理的缺失数据,否则,它可能会导致开发数据时出现一些问题。
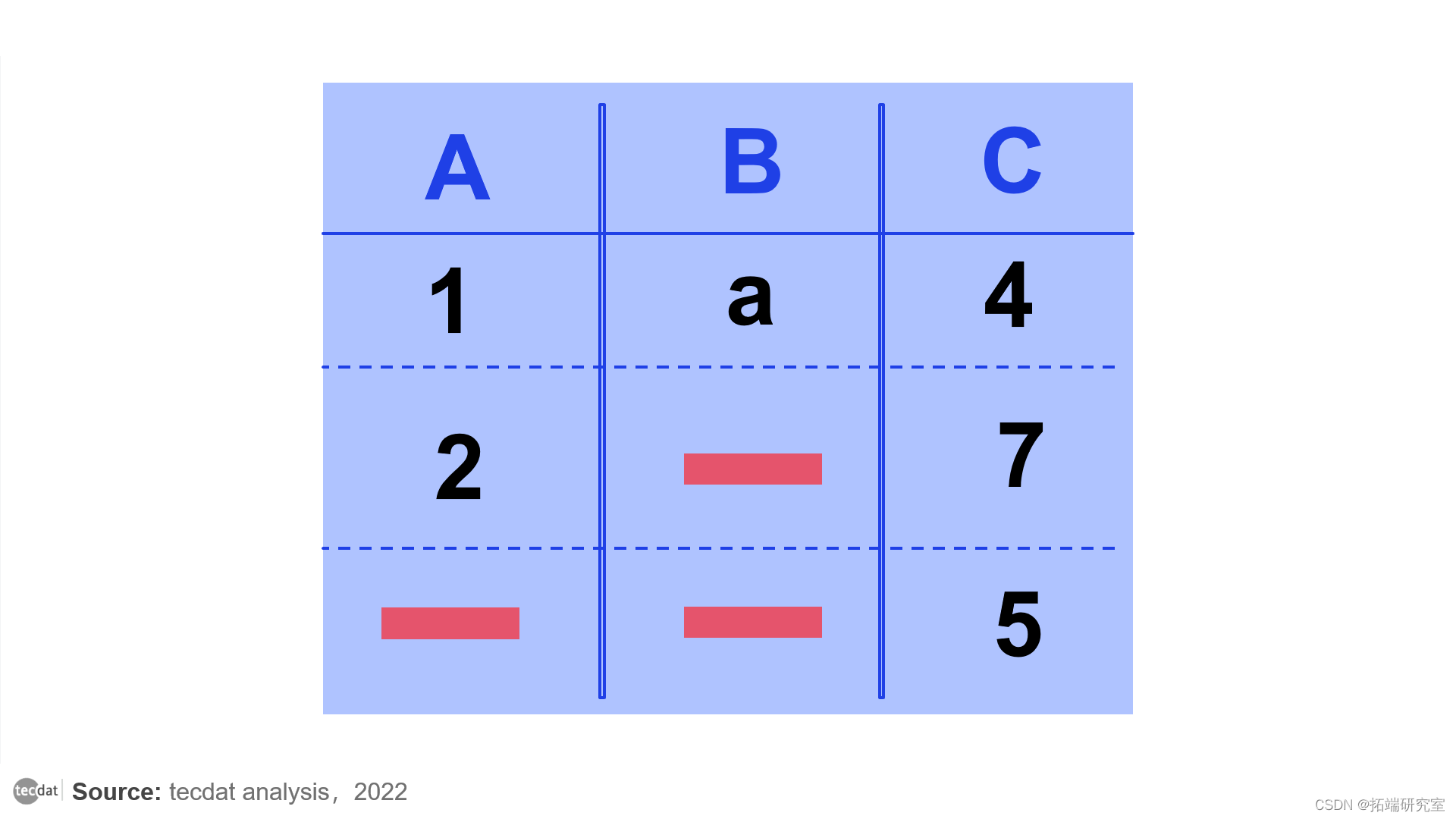
表中缺少数据
因此,在这篇文章中,我将展示一些可用于处理数据驱动项目中丢失数据的技术,并可能消除在构建数据管道时丢失数据可能导致的问题。
为什么你应该处理丢失的数据
在继续如何解决问题之前,必须首先了解为什么需要处理丢失的数据。
数据确实是所有数据科学和机器学习项目的主要驱动力。它是机器做出所有决定的所有项目的核心要素。
虽然缺失数据的存在确实令人沮丧,但从数据集中彻底消除它可能并不总是正确的方法。例如,考虑下图。
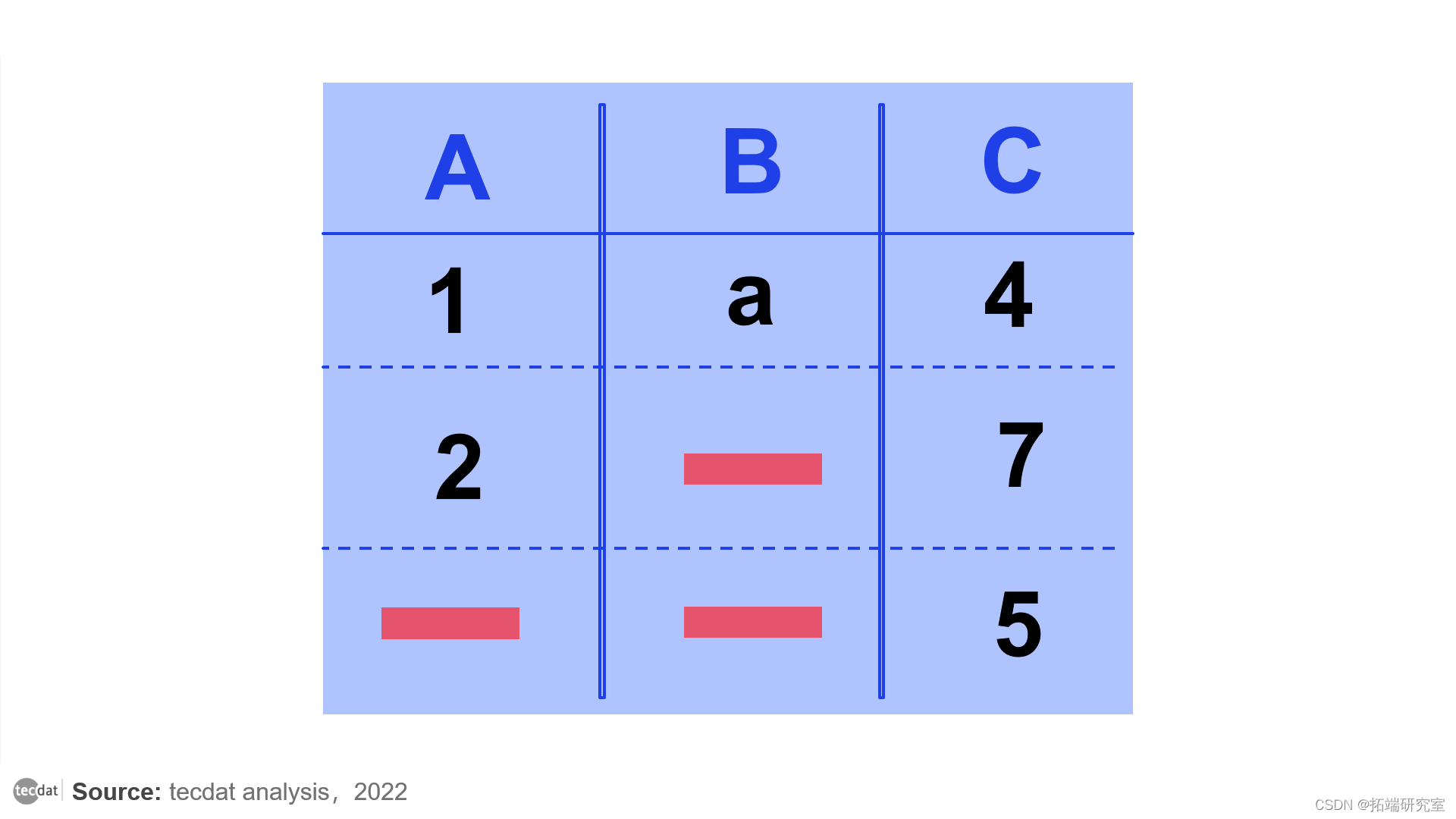
表中缺少数据
如果您考虑消除所有至少有一个缺失值的行,它:
#1 减少数据集中的数据点数量
下图所示,完全拒绝包含任何缺失值的行会显着减少数据集中的行数。
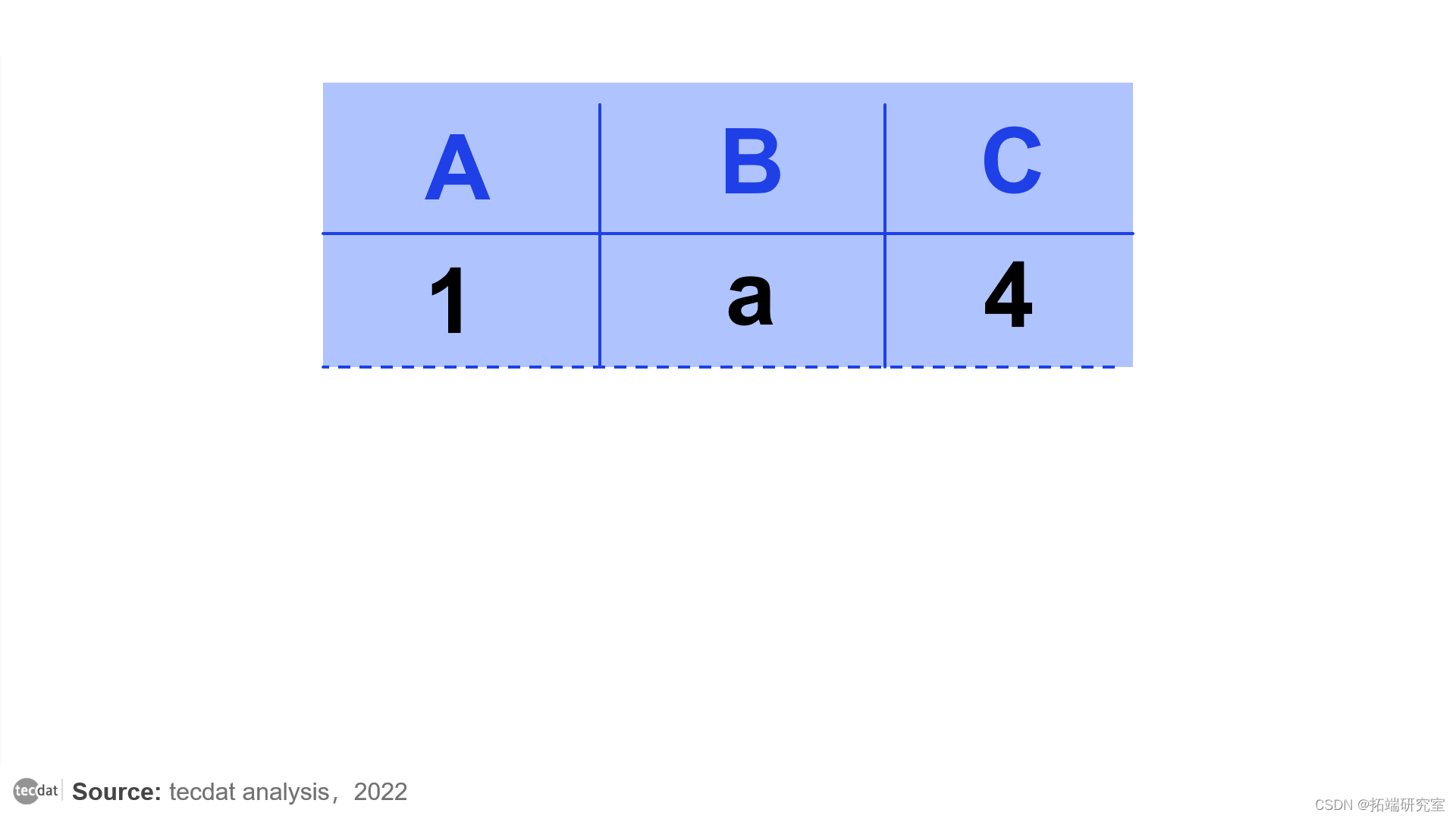
删除具有至少一个 NaN 值的行
#2 导致我们已经拥有的其他有价值(和正确)信息的丢失
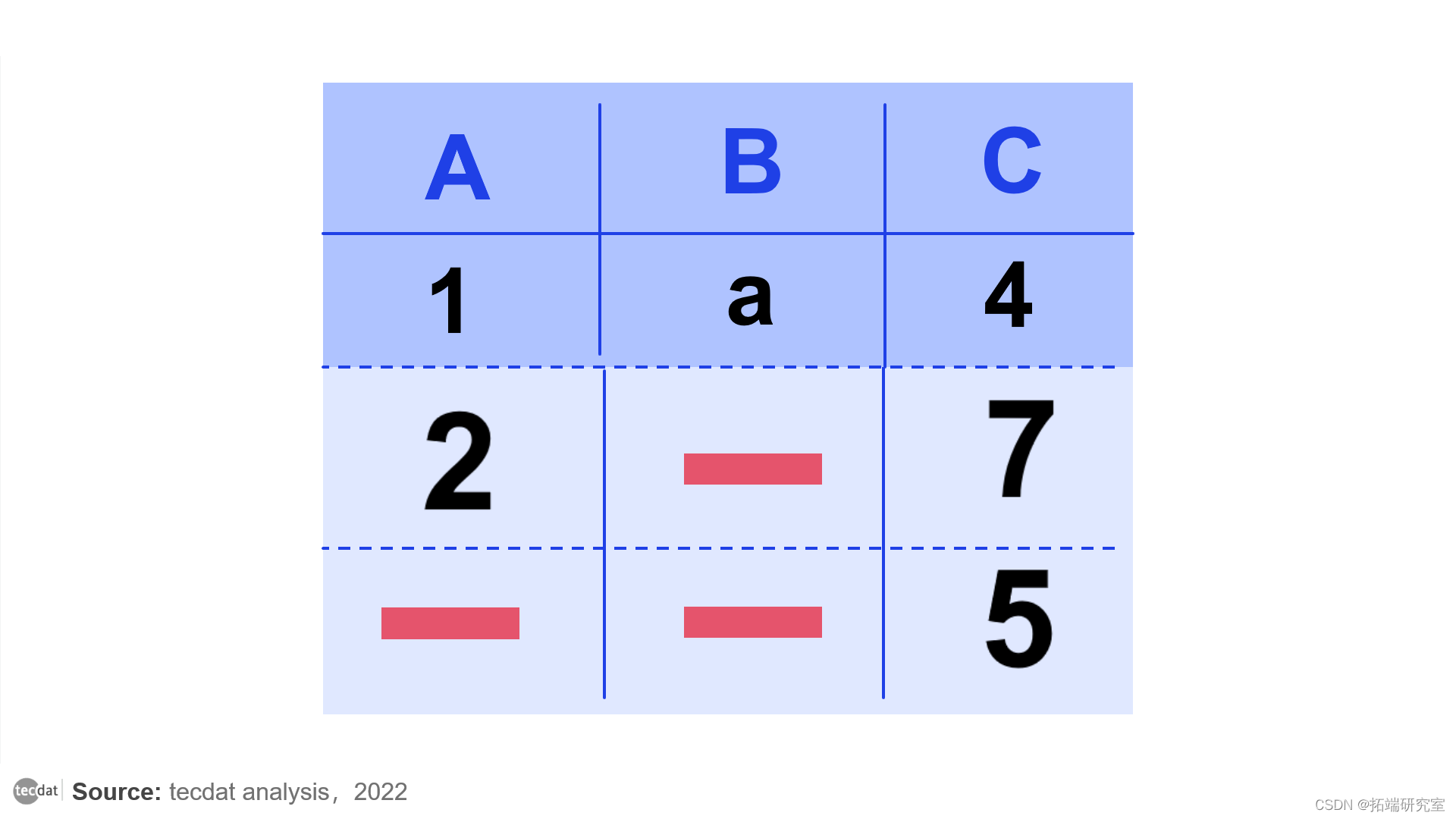
在具有至少一个 NaN 值的行中标记的非 NaN 值
即使没有B观察到的值,我们仍然可以精确地知道A,C对应值,这仍然非常有价值。
处理缺失数据
现在您已经了解了为什么要处理缺失数据,让我们了解处理缺失数据的技术方面。
每当您在表格数据中遇到缺失值时,您基本上只有三个选项可供选择,如下图所示:
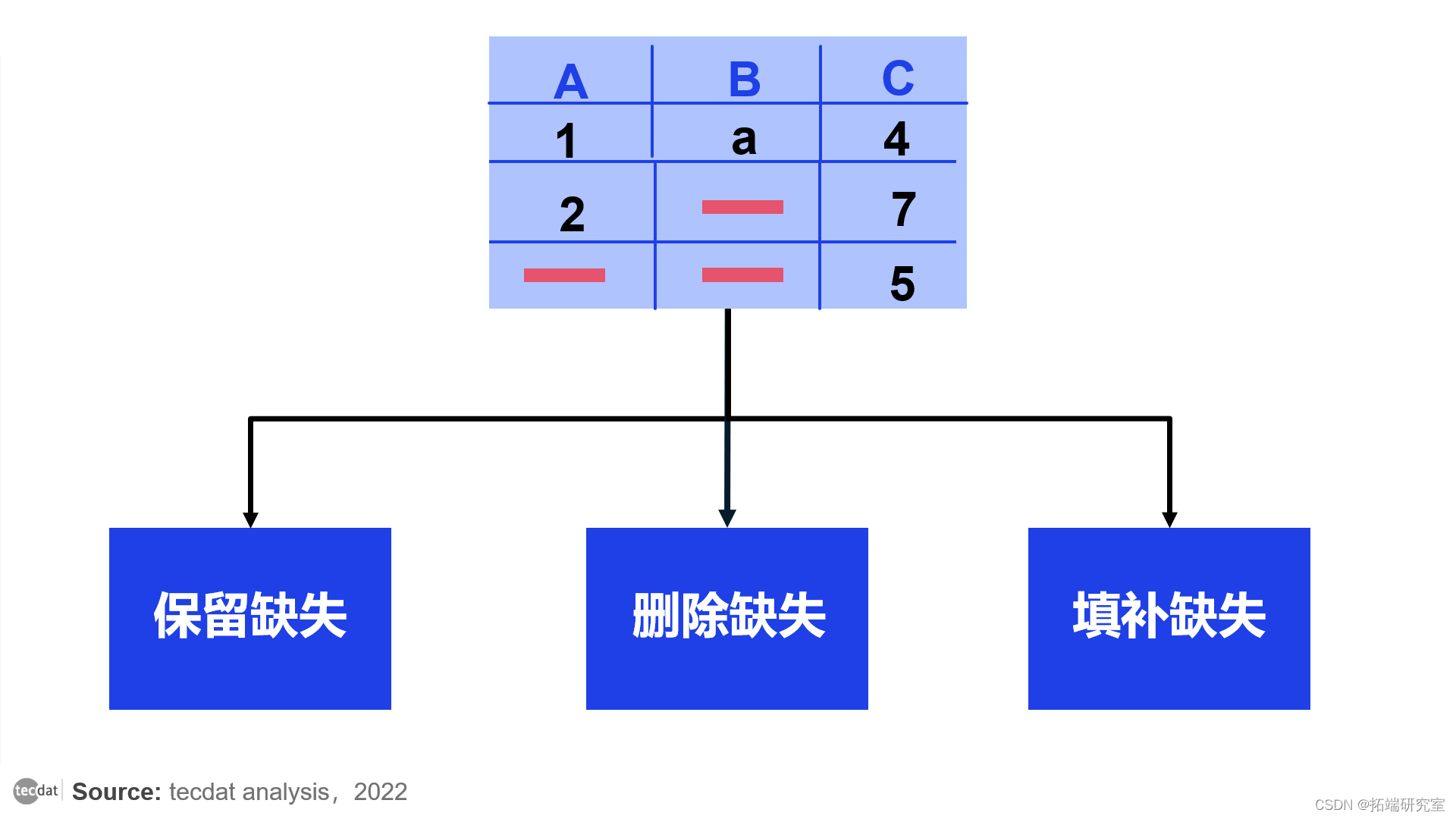
处理缺失数据的三种方法
下面让我们详细讨论这三种方法。
#1 保留缺失的数据
顾名思义,这种方法绝对忽略了数据集中任何缺失数据点的存在。
不对 DataFrame 应用任何转换
然而,在这里,本质上假设丢失的数据点不会在数据管道中造成任何问题,并且所利用的方法擅长处理丢失的数据。
因此,数据科学家或机器学习工程师的工作是决定如果丢失的数据保持原样,他们的算法是否可以工作。
#2 删除缺失的数据
接下来,想象一下,如上所述,保留丢失的数据对于您的特定用例是不可行的。
在这种情况下,完全删除丢失的数据可能是一个继续前进的方向。
这里的主要想法是从 DataFrame 中删除具有任何缺失值的整行(如果您的用例需要基于系列的分析,则删除一列)。
换句话说,在这种技术中,您只保留与每一列(或行)对应的非空值的数据行(或列),并将数据集视为删除的行从未存在过。
逐行丢弃
顾名思义,这里的目标是删除包含缺失值的 DataFrame 行。
下图描绘了逐行下降。
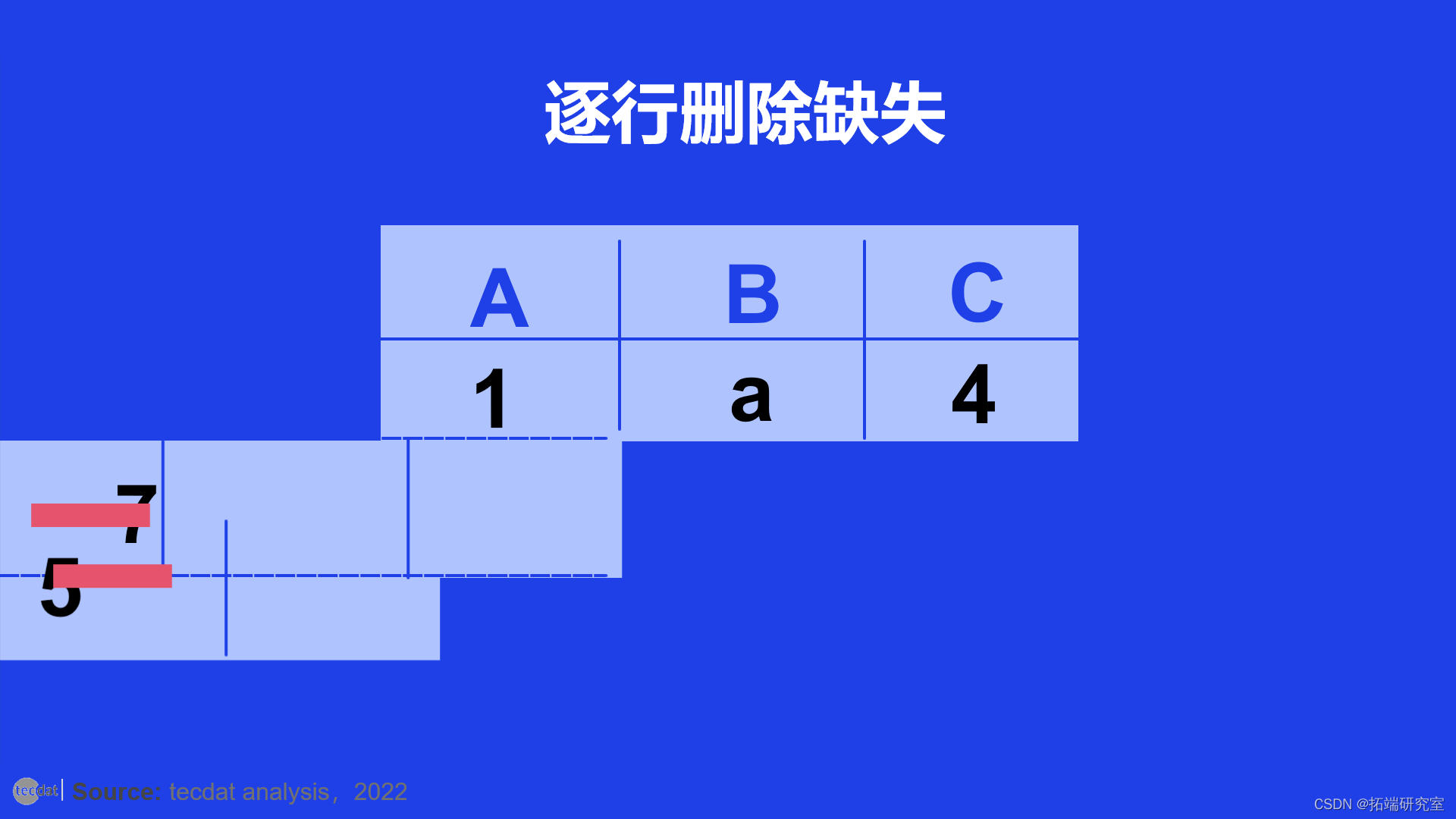
删除具有至少一个 NaN 值的行
在面向行的删除中,列数保持不变。
逐列删除
与逐行删除相比,逐列删除涉及删除包含缺失值的 DataFrame 的列(或系列)。
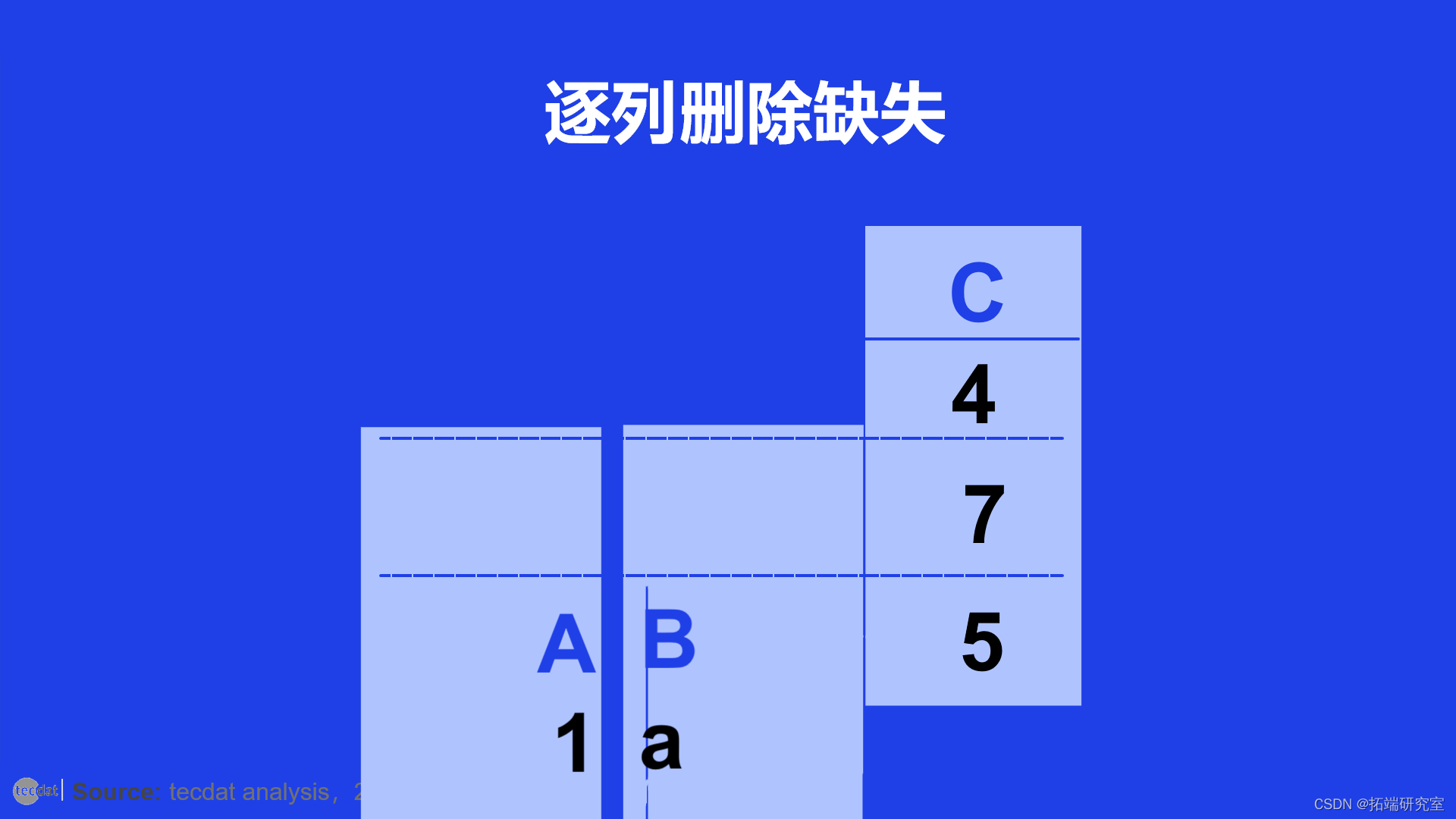
删除具有至少一个 NaN 值的列
在面向列的删除中,行数保持不变。
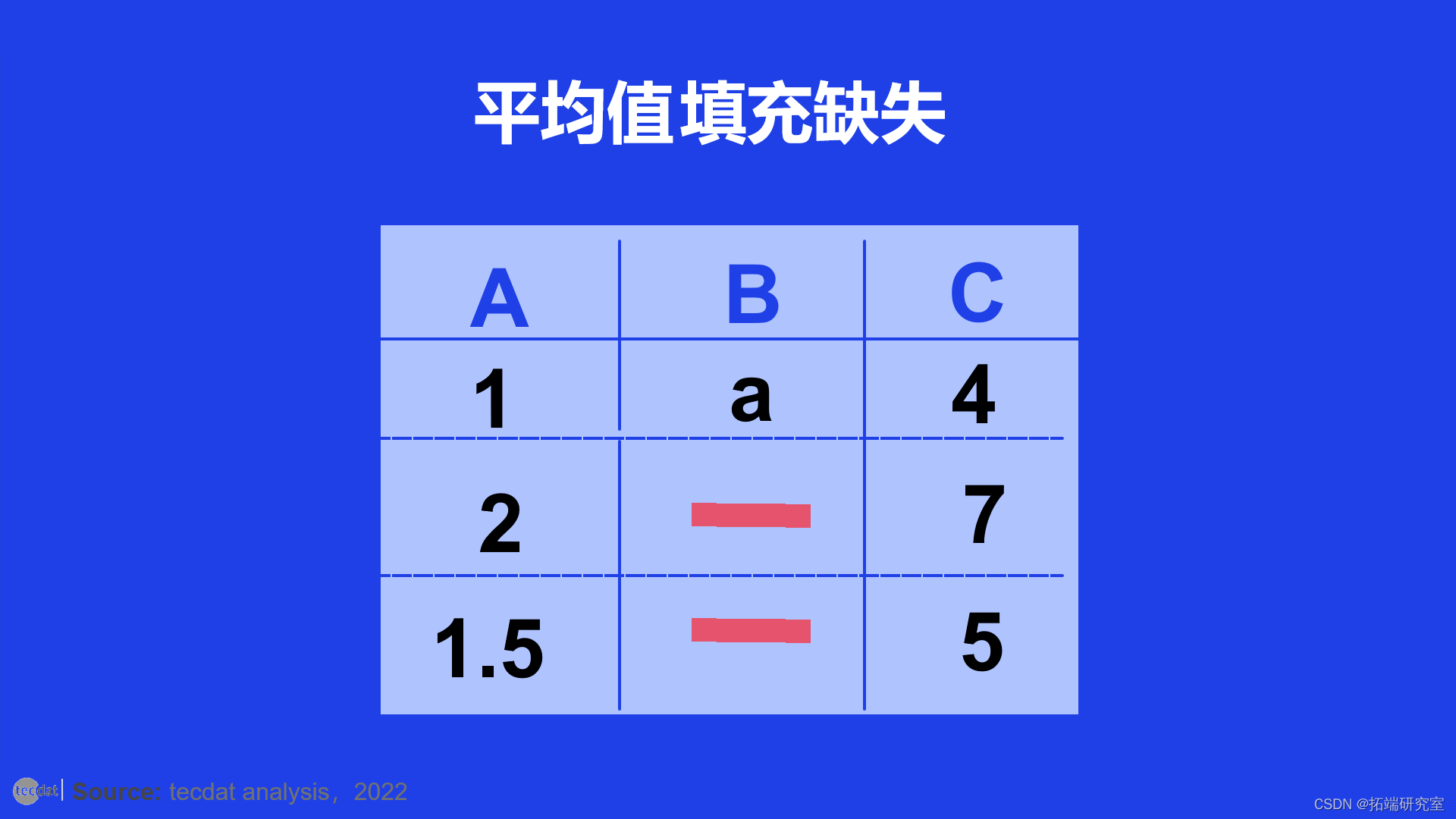
#3 填补缺失的数据
最后一种技术涉及用一些值填充缺失的数据,该值可能是给定未观察位置的最佳估计值。
用随机策略替换缺失值
该策略可能涉及用列的平均值、中值或列的最频繁值(众数)填充缺失数据——具体取决于列中值的类型。
这是因为平均值、中位数和众数只能针对数值进行估计。但是,在分类列的情况下,均值和中位数没有意义。
此外,填充标准完全取决于您的特定数据源、您正在解决的问题以及评估该特定缺失数据点的舒适程度。
执行
寻找缺失值的最佳估计值的最常用技术包括均值、中值和众数,如下所示:
- 用平均值填充:
均值策略用列的平均值替换缺失值。
如上所述,均值策略没有替换colB.
- 填充中位数:
接下来,中值策略将列中的缺失值替换为中值。这是在下面实现的:
再一次,最初缺少的值colB仍然充满了NaN值。
- 填充众数:
最后,用众数填充,将缺失值替换为列中出现频率最高的值,如下所示:
您还可以对不同的列应用不同的填充策略,如下所示:

colA在这里,我们用colA的平均值和colB的众数填充缺失值。
结论
具体来说,我们研究了为什么处理缺失数据对您的数据管道至关重要,然后是处理缺失数据的常用策略。
在处理缺失数据时,您应该记住,我们在本文中讨论的三种方法(保持、丢弃和填充)中没有正确的方法。这是因为每种情况都不同。
根据情况需要,始终由您决定选择哪种具体方法。
在R语言中进行缺失值填充:估算缺失值
介绍
缺失值被认为是预测建模的首要障碍。因此,掌握克服这些问题的方法很重要。
估算缺失值的方法的选择在很大程度上影响了模型的预测能力。在大多数统计分析方法中,删除是用于处理缺失值的默认方法。但是,它会导致信息丢失。
在本文中,我们列出了5个R语言方法。
链式方程进行的多元插补
通过链式方程进行的多元插补是R用户常用的。与单个插补(例如均值)相比,创建多个插补可解决缺失值的不确定性。
MICE假定缺失数据是随机(MAR)缺失,这意味着,一个值缺失概率上观测值仅取决于并且可以使用它们来预测。通过为每个变量指定插补模型,可以按变量插补数据。
例如:假设我们有X1,X2….Xk变量。如果X1缺少值,那么它将在其他变量X2到Xk上回归。然后,将X1中的缺失值替换为获得的预测值。同样,如果X2缺少值,则X1,X3至Xk变量将在预测模型中用作自变量。稍后,缺失值将被替换为预测值。
默认情况下,线性回归用于预测连续缺失值。Logistic回归用于分类缺失值。一旦完成此循环,就会生成多个数据集。这些数据集仅在估算的缺失值上有所不同。通常,将这些数据集分别构建模型并组合其结果被认为是一个好习惯。
确切地说,使用的方法是:
-
PMM(预测均值匹配)–用于数字变量
-
logreg(逻辑回归)–对于二进制变量(具有2个级别)
-
polyreg(贝叶斯多元回归)–用于因子变量(> = 2级)
-
比例模型(有序,\> = 2个级别)
现在让我们实际操作。
#读取数据
> data <- iris
#随机产生10%的缺失值
> summary(iris)
#随机产生10%的缺失值
> iris.mis <- prodNA(iris, noNA = 0.1)
#检查数据中引入的缺失值
> summary(iris.mis)我删除了分类变量。让我们在这里关注连续值。要处理分类变量,只需对类level进行编码并按照以下步骤进行即可。
#删除类别变量
> iris.mis <- subset(iris.mis, select = -c(Species))
md.pattern返回数据集中每个变量中存在的缺失值的表格形式。
> pattern(iris.mis)
让我们了解一下这张表。有98个观测值,没有缺失值。Sepal.Length中有10个观测值缺失的观测值。同样,Sepal.Width等还有13个缺失值。
我们还可以创建代表缺失值的视觉效果。
> plot(iris.mis, col,
numbers=TRUE, sortVars=TRUE"))
让我们快速了解这一点。数据集中有67%的值,没有缺失值。在Petal.Length中缺少10%的值,在Petal.Width中缺少8%的值,依此类推。您还可以查看直方图,该直方图清楚地描述了变量中缺失值的影响。
现在,让我们估算缺失的值。
Multiply imputed data set
Call:
Number of multiple imputations: 5
Missing cells per column:
Sepal.Length Sepal.Width Petal.Length Petal.Width
13 14 16 15
Imputation methods:
Sepal.Length Sepal.Width Petal.Length Petal.Width
"pmm" "pmm" "pmm" "pmm"
VisitSequence:
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 2 3 4
PredictorMatrix:
Sepal.Length Sepal.Width Petal.Length Petal.Width
Sepal.Length 0 1 1 1
Sepal.Width 1 0 1 1
Petal.Length 1 1 0 1
Petal.Width 1 1 1 0
Random generator seed value: 500这是使用的参数的说明:
-
m – 估算数据集
-
maxit – 插补缺失值的迭代次数
-
method –是指插补中使用的方法。我们使用了预测均值匹配。
由于有5个估算数据集,因此可以使用_complete()_函数选择任何数据集。
还可以合并来自这些模型的结果,并使用_pool()_命令获得合并的输出。
请注意,我仅出于演示目的使用了上面的命令。您可以在最后替换变量值并尝试。
多重插补
该程序包还执行多个插补(生成插补数据集)以处理缺失值。多重插补有助于减少偏差并提高效率。它可以通过基于bootstrap程序的EMB算法,从而可以更快速,更可靠地插入许多变量,包括横截面,时间序列数据等。此外,还可以使用多核CPU的并行插入。
相关视频
拓端
它做出以下假设:
-
数据集中的所有变量均具有多元正态分布(MVN)。它使用均值和协方差汇总数据。
-
缺失数据本质上是随机的(随机缺失)
因此,当数据具有多变量正态分布时,最有效。如果没有,将进行转换以使数据接近正态分布。
唯一需要注意的是对变量进行分类。
#访问估算的输出
> amelia_fit$imputations\[\[1\]\]
要检查数据集中的特定列,使用
> amelia_fit$imputations\[\[5\]\]$Sepal.Length
#将输出导出到csv文件
随机森林
顾名思义,missForest是一个实现随机森林算法。它适用于各种变量类型的非参数插补法。那么,什么是非参数方法?
相关视频
拓端
非参数方法不会有关于函数形式明确的假设_˚F _。取而代之的是,它尝试估计_f_,使其可以与数据点尽可能接近。
它是如何工作的 ?简而言之,它为每个变量建立一个随机森林模型。然后,它使用模型在观测值的帮助下预测变量中的缺失值。
它产生OOB(袋外)估算误差估计。而且,它对插补过程提供了高水平的控制。它有选择分别返回OOB(每个变量),而不是聚集在整个数据矩阵。这有助于准确估算模型值。
NRMSE是归一化的均方误差。它用于表示从估算连续值得出的误差。PFC(错误分类的比例)用于表示从估算类别值得出的误差。
#比较实际数据准确性
>iris.err
NRMSE PFC
0.1535103 0.0625000这表明类别变量的误差为6%,连续变量的误差为15%。这可以通过调整_mtry_和_ntree_参数的值来改善 。mtry是指在每个分支中随机采样的变量数。ntree是指在森林中生长的树木数量。
非参数回归方法
对多个插补中的每个插补使用不同的bootstrap程序重采样。然后,将 加性模型(非参数回归方法)拟合到从原始数据中进行替换得到的样本上,并使用非缺失值(独立变量)预测缺失值(充当独立变量)。
然后,它使用预测均值匹配(默认)来插补缺失值。预测均值匹配非常适合连续和分类(二进制和多级),而无需计算残差和最大似然拟合。
自动识别变量类型并对其进行相应处理。
> impute_arg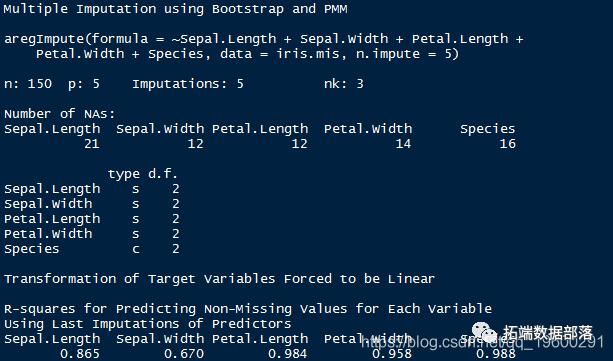
输出显示R²值作为预测的缺失值。该值越高,预测的值越好。使用以下命令检查估算值
#检查估算变量Sepal.Length
> impute_arg$imputed$Sepal.Length带有诊断的多重插补
带有诊断的多重插补 提供了一些用于处理缺失值的方法。它也构建了多个插补模型来近似缺失值。并且,使用预测均值匹配方法。
虽然,我已经在上面解释了预测均值匹配(pmm) :对于变量中缺失值的每个观察值,我们都会从可用值中找到最接近的观察值该变量的预测均值。然后将来自“匹配”的观察值用作推断值。
-
它可以对插补模型进行图形诊断,并可以实现插补过程的收敛。
-
它使用贝叶斯版本的回归模型来处理问题。
-
插补模型规范类似于R中的回归输出
-
它会自动检测数据中的不规则性,例如变量之间的高共线性。
-
而且,它在归算过程中增加了噪声,以解决加性约束的问题。
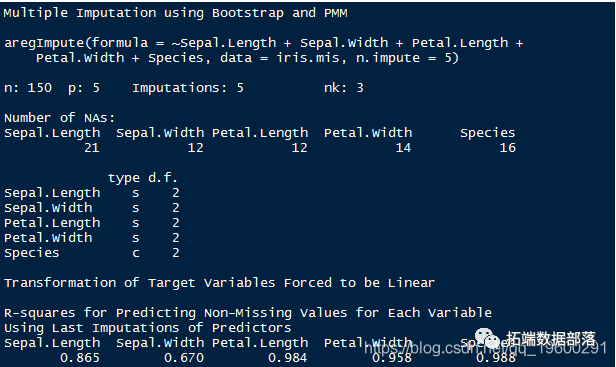
如图所示,它使用汇总统计信息来定义估算值。
尾注
在本文中,我说明使用5个方法进行缺失值估算。这种方法可以帮助您在建立预测模型时获得更高的准确性。
















 836
836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









