






Attention Is All You Need
摘要
我们提出一种新的简单的网络架构Transformer,仅基于attention机制并完全避免循环和卷积。对两个机器翻译任务的实验表明,这些模型在质量上更加优越、并行性更好并且需要的训练时间显著减少。
引言
RNN、LSTM、gated rnn被用作最好的序列模型和转录模型,许多工作推动着它们的发展界限。通过在计算期间将位置与步骤对齐,它们根据前一步的隐藏状态ht-1和输入产生位置t的隐藏状态序列ht。这种固有的顺序特性阻碍样本训练的并行化,这在更长的序列长度上变得至关重要,因为有限的内存限制样本的批次大小。 最近的工作通过巧妙的因子分解[21]和条件计算[32]在计算效率方面取得重大进展,后者还同时提高了模型性能。 然而,顺序计算的基本约束依然存在。
Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences [2, 19]. In all but a few cases [27], however, such attention mechanisms are used in conjunction with a recurrent network.
(attention机制主要用于把编码器的东西有效的传给解码器)
在这项工作中我们提出Transformer,这种模型架构避免循环并完全依赖于attention机制来绘制输入和输出之间的全局依赖关系。 Transformer允许进行更多的并行化,并且可以在八个P100 GPU上接受少至十二小时的训练后达到翻译质量的新的最佳结果。
相关工作
第一段:
其他人如何用卷积来替换,提高并行性。距离远的话,computing hidden representations的操作变多。注意力机制一层可以看所有。
In the Transformer this is reduced to a constant number of operations, albeit at the cost of reduced effective resolution due
to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as
described in section 3.2.
(卷积的优势,多输出通道,用多头注意力机制)
第二段:
自注意力不是作者的创新
第三段:
transformer是第一个只用自注意力做encode和decode的模型
模型架构
第一段:
解释编码器与解码器。
auto-regressive:过去时刻的输出可以作为当前时刻的输入
第二段:
略
3.1Encoder and Decoder Stacks
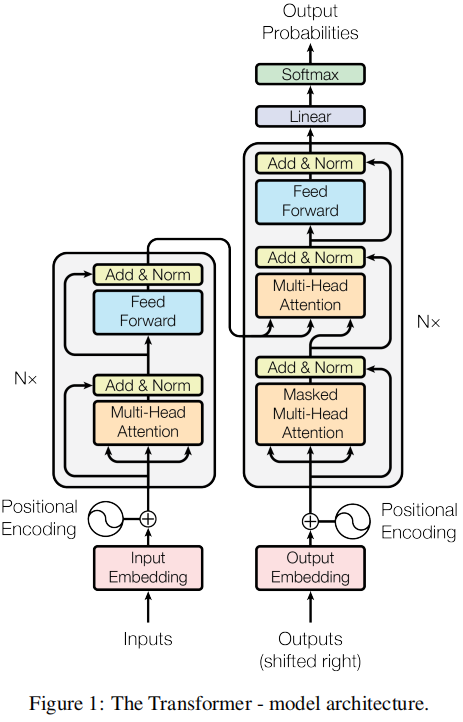
Encoder:
每层包含两个子层,每个子层LayerNorm(x + Sublayer(x))
LayerNorm:按样本进行normalization
BatchNorm:按特征进行normalization
Decoder:
每层包含三个子层,加了掩码层来实现自回归auto-regressive,遮盖后边的向量,指利用前面得到的向量
Multi-Head Attention的输入依次为k,v,query
3.2 Attention
An attention function can be described as mapping a query and a set of key-value pairs to an output,
where the query, keys, values, and output are all vectors. The output is computed as a weighted sum
of the values, where the weight assigned to each value is computed by a compatibility function of the
query with the corresponding key.
query,key,value
query和每个key比较,得到每个key对应的value的权重,每个value按权重相加,得到query的结果
3.3 Scaled Dot-Product Attention
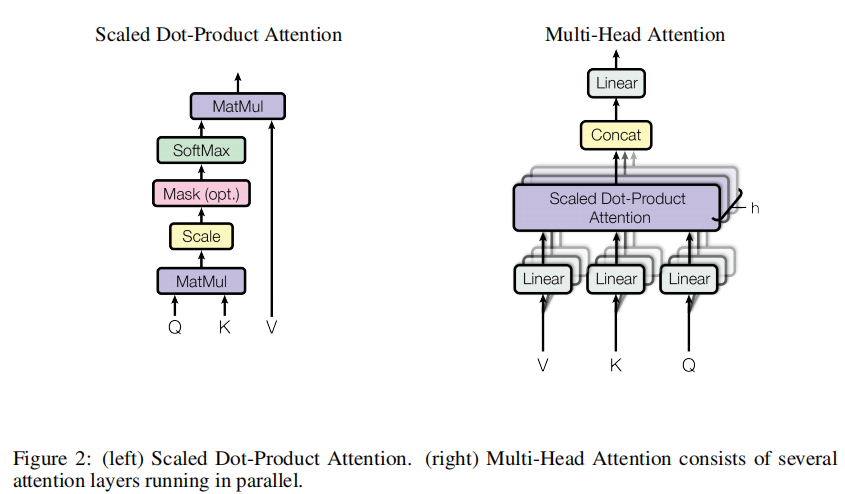
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
一个q和每个Key相乘,这个q和整个句子中的每个Key内积,得到每个q和句中每个词的相似度,除以
d
k
\sqrt{d_k}
dk在进行softmax得到每个Value上的权值,权值向量再和V内积(即Value按权值相加)。当然这里用的q是n个q组成n维的Q(即n行,dk维)。
Q(n,dk),K(m,dk),V(m,dv),QKT(n,m),QKTV(n,dv)
下边是为什么除以dk
While for small values of dk the two mechanisms perform similarly, additive attention outperforms
dot product attention without scaling for larger values of dk [3]. We suspect that for large values of
dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has
extremely small gradients 4
. To counteract this effect, we scale the dot products by
1 d k \frac{1}{\sqrt{d_k}} dk1
dk大时,QKT的softmax结果可能向两端走,梯度变小
图二:
左
MatMul指矩阵相乘
Mask:t时间刻只利用k1,k2,…,kt-1的编码,其余替换为非常大的负数
右
MultiHead(Q,K,V)=Concat(head_1,...,head_h)W^O
\\where\quad head_i=Attention(QW^Q_i,KW^K_i,VW^V_i)
把Q,K,V投影h次,投影成
d
k
=
d
v
=
d
m
o
d
e
l
h
d_k=d_v=\frac{d_{model}}{h}
dk=dv=hdmodel
多头类似CV中图像的多通道
3.3 Position-wise Feed-Forward Networks
FFN(x)=max(0,xW_1+b_1)W_2+b_2
3.4 Embeddings and Softmax
In the embedding layers, we multiply those weights by d \sqrt{d} dmodel.(词向量太长,每个数变小,相乘后和position相近 )
3.5 Positional Encoding
attention没有位置信息,如何加入具体略















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









