







❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 微信公众号|搜一搜:蚝油菜花 🥦
🎭 「校勘古籍被逗号逼疯?华南理工用AI复活文言文:24亿字训练的通古大模型,让《资治通鉴》开口说人话!」
大家好,我是蚝油菜花。你是否经历过——
- 📜 面对无标点古籍,断句错一次论文重写三天
- 🖋️ 想引用《楚辞》却怕翻译失真被导师划红线
- 🧐 查个典故翻遍二十五史,眼镜度数飙升200度…
今天要揭秘的 通古大模型 ,可能是文科生最需要的AI外挂!这个由华南理工大学实验室打造的文言文GPT,基于 24.1亿字古籍语料 训练,不仅实现:
- ✅ 精准智能断句(误差率<2%)
- ✅ 文白互译保真(支持双向转换)
- ✅ 诗词格律生成(平仄押韵全自动)
更用 检索增强技术 解决"AI瞎编典故"的行业痛点。汉语言系学生用它写论文,古籍馆用它数字化《四库全书》——原来穿越千年的对话,真的可以一键实现!
🚀 快速阅读
通古大模型是专注于古籍文言文处理的人工智能语言模型。
- 主要功能:支持古文句读、文白翻译、诗词创作、古籍赏析和古籍检索与问答。
- 技术原理:基于百川2-7B-Base进行增量预训练,结合24.1亿古籍语料和400万古籍对话数据,采用冗余度感知微调(RAT)技术和检索增强生成(RAG)技术。
通古大模型是什么
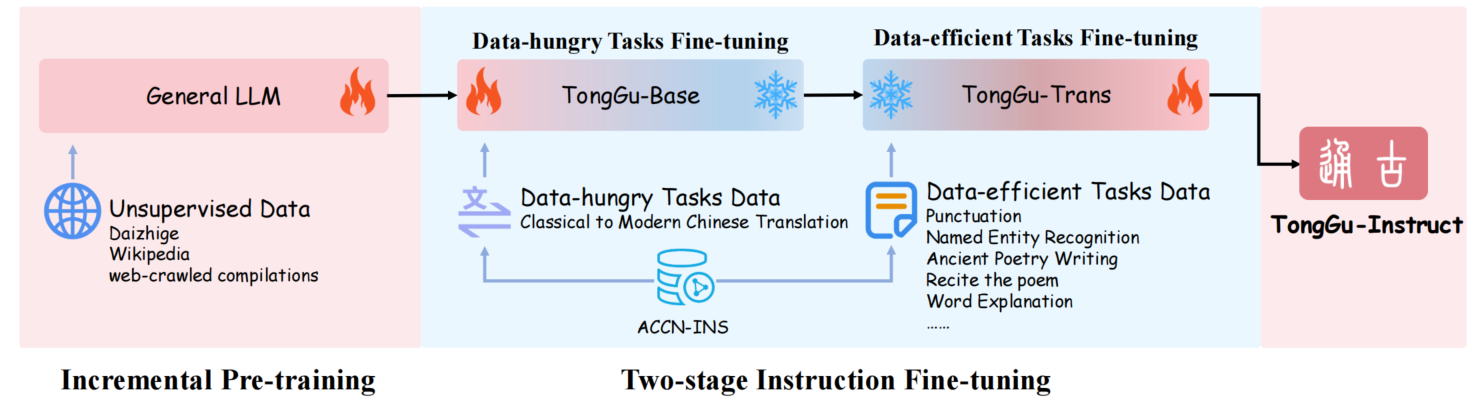
通古大模型是由华南理工大学深度学习与视觉计算实验室(SCUT-DLVCLab)开发的专注于古籍文言文处理的语言模型。该模型基于百川2-7B-Base进行增量预训练,使用24.1亿古籍语料进行无监督训练,并结合400万古籍对话数据进行指令微调。通过这些技术手段,通古大模型能够有效提升古籍任务的性能,帮助用户更便捷地理解和翻译古籍文献。
通古大模型不仅在古文句读、文白翻译等方面表现出色,还能够生成符合古诗词格律的作品,辅助用户进行古籍整理和数字化工作。通过检索增强生成(CCU-RAG)技术,模型减少了知识密集型任务中的幻觉问题,提高了生成内容的准确性和可靠性。
通古大模型的主要功能
- 古文句读:自动为古文添加标点符号,解决古籍中常见的断句问题,帮助用户更好地理解古文内容。
- 文白翻译:支持文言文与白话文之间的双向翻译,将晦涩的古文翻译为现代文,同时也可将现代文转换为文言文,方便用户进行古籍阅读和研究。
- 诗词创作:生成符合古诗词格律和风格的诗歌,用户可以根据需求提供主题或关键词,模型生成相应的诗词作品。
- 古籍赏析:对古籍中的经典篇章进行赏析,解读其文学价值、历史背景和文化内涵,辅助用户深入学习古籍。
- 古籍检索与问答:结合检索增强技术,快速检索古籍内容,根据用户的问题提供准确的答案,帮助用户高效获取古籍信息。
- 辅助古籍整理:识别古籍中的文字错误、缺漏等问题,提供修复建议,辅助古籍整理和数字化工作。
通古大模型的技术原理
- 基础模型架构:通古大模型基于百川2-7B-Base进行增量预训练。百川2-7B-Base是一个强大的预训练语言模型,为通古大模型提供了基础的语言理解和生成能力。
- 无监督增量预训练:模型在24.1亿古籍语料上进行无监督增量预训练,使模型学习古籍的语言风格和结构,为后续的古籍处理任务奠定基础。
- 多阶段指令微调:通古大模型采用了多阶段指令微调技术,提出了冗余度感知微调(RAT)方法。在提升下游任务性能的同时,保留了基座模型的能力。通过指令微调,模型能更好地适应古籍处理的具体任务,如古文翻译、句读等。
- 检索增强生成(RAG)技术:通古大模型结合了检索增强生成(RAG)技术,减少知识密集型任务中的幻觉问题。核心是将信息检索与文本生成相结合,通过从外部知识库中检索相关信息,作为上下文输入给语言模型,生成更准确、更符合上下文的答案。
如何运行通古大模型
1. 安装依赖
首先,确保你已经安装了必要的依赖库:
pip install torch transformers
2. 加载模型
接下来,加载通古大模型并设置系统消息和用户查询:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "SCUT-DLVCLab/TongGu-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_path, device_map='auto', torch_dtype=torch.bfloat16, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
system_message = "你是通古,由华南理工大学DLVCLab训练而来的古文大模型。你具备丰富的古文知识,为用户提供有用、准确的回答。"
user_query = "翻译成白话文:大学之道,在明明德,在亲民,在止于至善。"
prompt = f"{system_message}\n<用户> {user_query}\n<通古> "
3. 生成回复
最后,生成模型的回复并输出结果:
inputs = tokenizer(prompt, return_tensors='pt')
generate_ids = model.generate(
inputs.input_ids.cuda(),
max_new_tokens=128
)
generate_text = tokenizer.batch_decode(
generate_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)[0][len(prompt):]
print(generate_text)
资源
- GitHub 仓库:https://github.com/SCUT-DLVCLab/TongGu-LLM
- HuggingFace 仓库:https://huggingface.co/SCUT-DLVCLab/TongGu-7B-Instruct
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 微信公众号|搜一搜:蚝油菜花 🥦

















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









