







视频链接: https://www.youtube.com/watch?v=wrsid5tvuSM
项目链接: https://github.com/mit-han-lab/once-for-all
论文链接: https://arxiv.org/pdf/1908.09791.pdf
该项目吸引到我的是,它在效率和精度上实现的非常好的效果, 配合efficientML的Lecture也是很香.
此外, 提供的视频链接介绍了ofa的使用方式.
__________________________________________________________
初读
在介绍部分,作者提到,它是通过解耦合训练和搜索的方式来支持广泛的架构搜索。此外,为了有效的训练,通过一种广义的剪枝的方法,去从多维度减小模型大小。然后,OFA效果要明显好于目前的NAS方法。
在总结阶段中,作者提到,通过,OFA不需要基于不同平台采用不同架构,而是可以在一次训练后,适配所有架构,包括深度,宽度,kernel大小和分辨率。此外,还提出了一种progressive shrinking的算法。
读完之后,问题还是很多的,progressive shrinking就是一个让人很好奇的概念。
直接做实验吧,实验记录在这
EfficientAI Lab3: Neural Architecture Seach-CSDN博客
——————————————————————————————————
细读
Progressive shrinking 是用于提供OFA模型的训练效率。首先训练一个最大的网络,然后再慢慢缩小网络的深度,宽度和kernel size。
OFA在imagenet上的效果很惊艳。
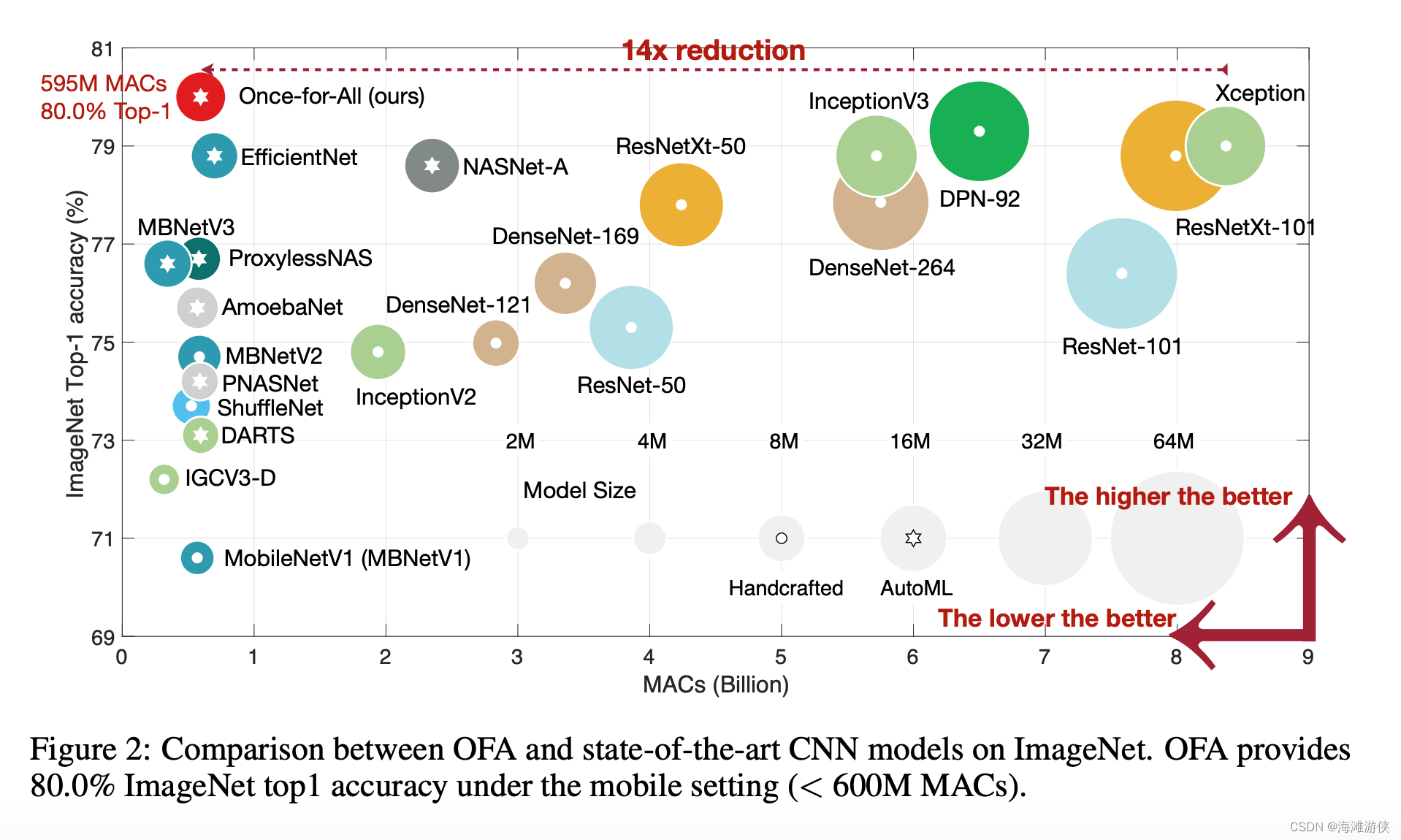
传统模型部署都是基于特定模型,然后优化结构。而OFA则使用了一个巨大的搜索空间,带来超强的灵活性,但是也给训练带来更大的挑战,因此我们使用Progressive shrinking的方法来试图解决。
Architecture space
搜索空间中对于图像大小,kernel大小等因素都可以调整,并且所有subnets共享相同的参数。
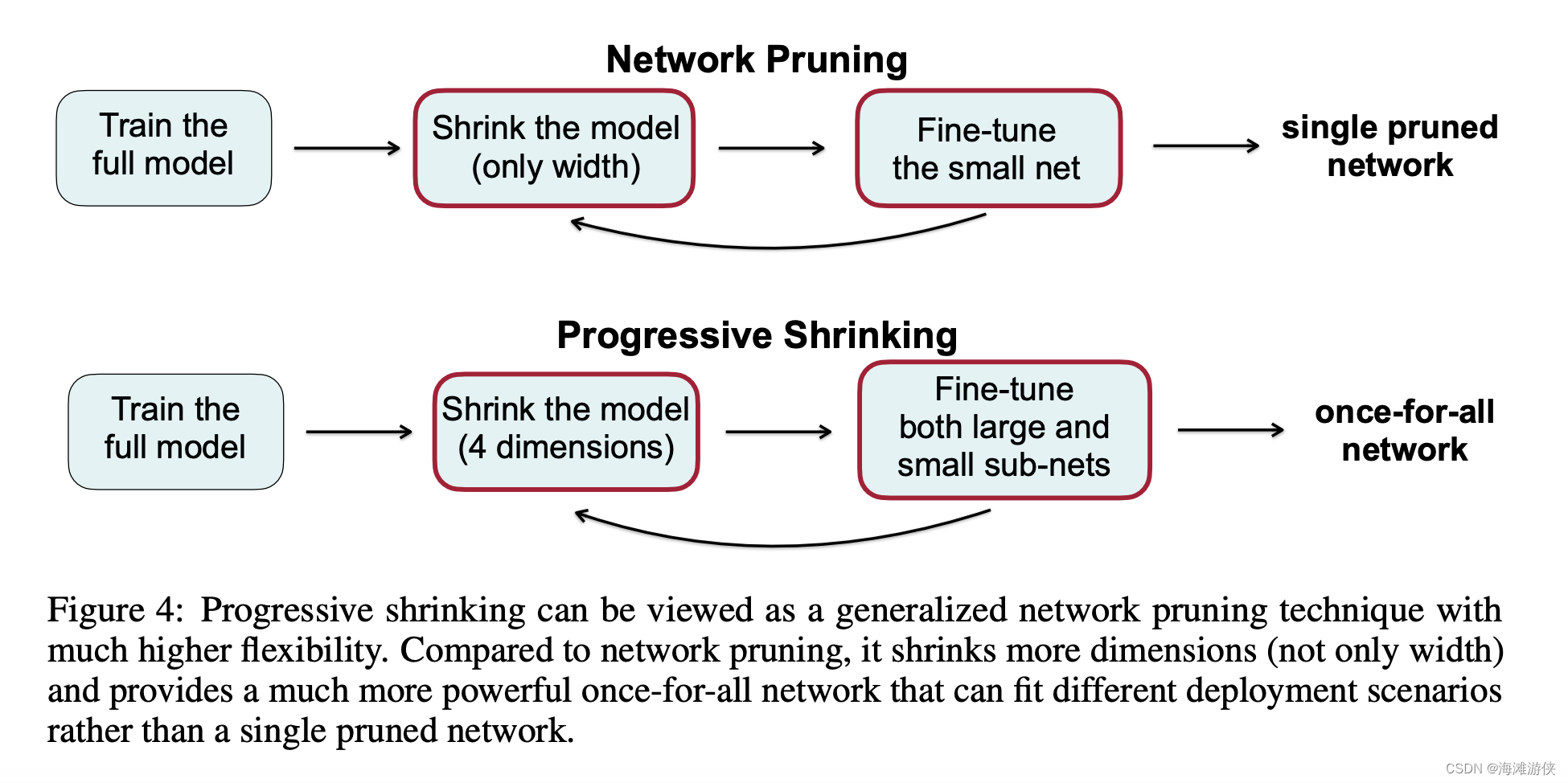 这张图例里很清楚的说明了,PS相比于Pruning,只是维度更多。在实际训练时,基于大模型训练小模型,然后采用知识蒸馏的方法进行进一步调优。
这张图例里很清楚的说明了,PS相比于Pruning,只是维度更多。在实际训练时,基于大模型训练小模型,然后采用知识蒸馏的方法进行进一步调优。
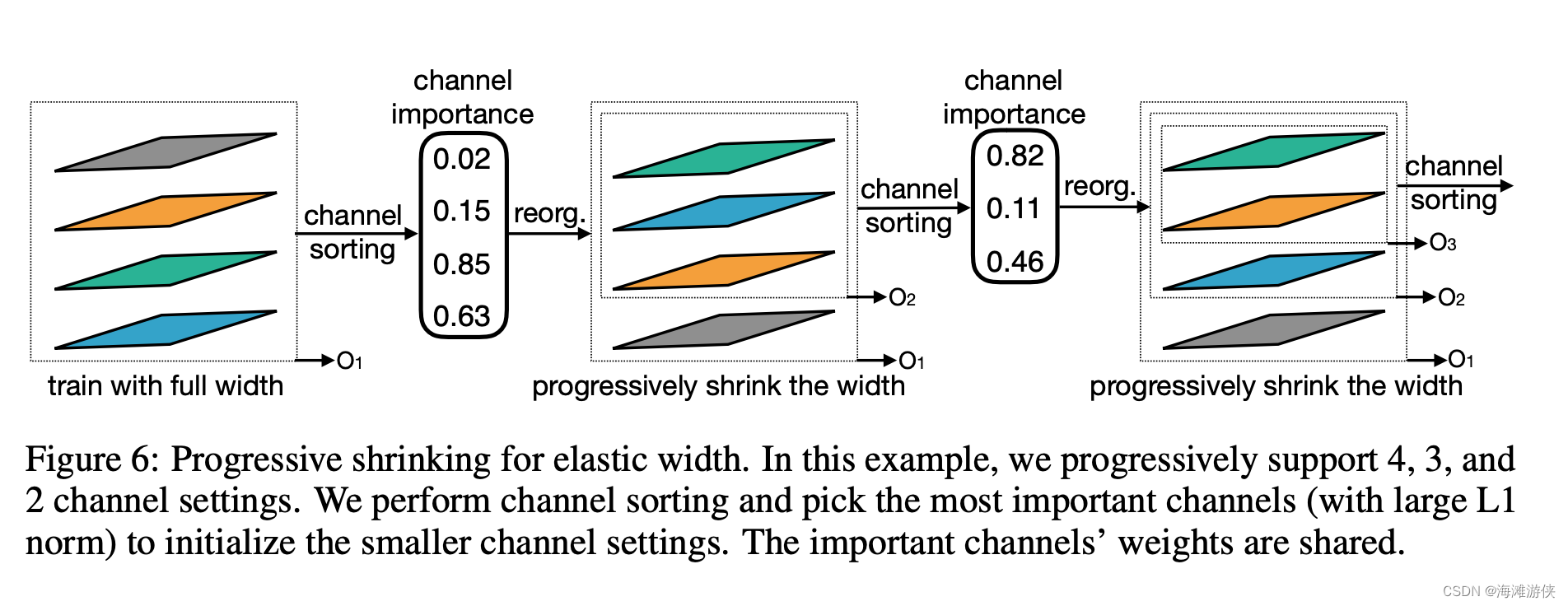
作者列举了缩小kernel size, channel size的策略,还是有细节在里面的。比如小kernel要考虑到它既是大kernel的一部分,但同时也承担了一定的责任。

Specifically, we randomly sample 16K sub-networks with different architectures and input image sizes, then measure their accuracy on 10K validation images sampled from the original training set. These [architecture, accuracy] pairs are used to train an accuracy predictor to predict the accuracy of a model given its architecture and input image size
上面这部分是我完成lab时候,印象最深的一部分,那就是,我构建了一个简单的FCN,用来评估不同架构的模型精度。
实验
在实验中,作者提到基于MobileNetV3 作为architecture space进行搜索。(其实这里,我的问题是为什么不使用MCUNet?)
作者这里的性能对比,包含intel CPU提供的MKL-DNN, 手机和TF-Lite,IoT设备使用Pytorch 1.0+cuDNN。实验结果是基于imagenet完爆mobilenet。。。
感受
这篇论文,因为它的实验结果很好,当然是值得细读。梳理一下它所提出的策略,感觉像一套组合拳,这套组合拳里,哪些是关键点,哪些优点累赘呢?这还需要进一步的分析判断。而在实际使用中,这个框架究竟有怎样的效果,还是需要进一步的分析和实验。















 1077
1077











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









