







c++YOLOV3部署系列代码解读,无需tensorrt,实现模型部署,目录如下:
C++ YOLOv3推理 第二讲: 权重及参数加载-CSDN博客
简介
通常基于C++实现模型推理,依赖于在nvidia平台上,通过onnx + tensorrt的工具链实现转化。
这一流程看起来高效,但是实际上也存在一个问题,那就是过分依赖nvidia提供的tensortt转换工具,并且因为该工具还没有开源,这也就意味着,当你用的不是nvidia的显卡时,模型推理的部署就会变得相对棘手,这对于高阶(比如高度硬件定制化)的模型部署来说,这样的黑匣子是无法接受的,因此,就更有必要熟悉一套白匣子的模型部署方式。
YOLOv3是YOLO最经典的作品之一,在工业界有广泛的应用,YOLOV3的源代码以C的代码提供了推理代码,参考【1】,此外,在ggml项目中,作者提供了基于GGUF格式模型的C推理代码【2】。代码风格简洁,值得学习。
使用的流程可以参考github中的介绍。
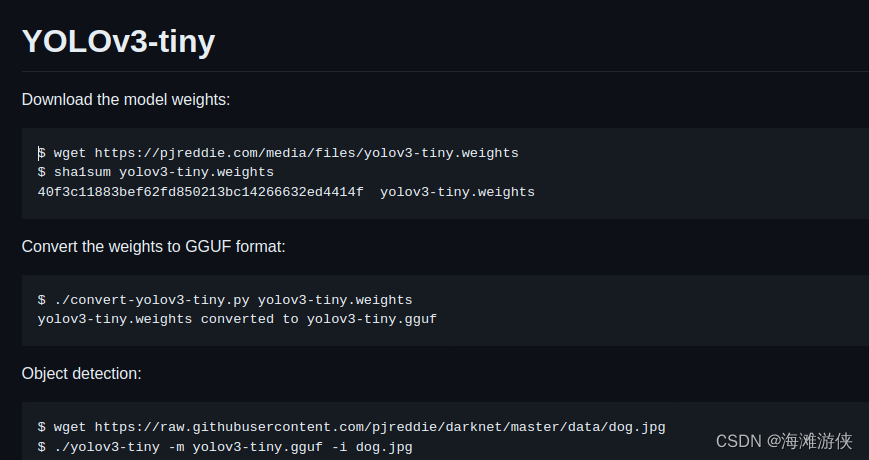
按照README的介绍编译并运行代码后,效果如下

具体的执行代码可以参考作者的github,而我总结一下,主要流程包括:
1. 推理模型框架编译
2. 推理模型权重格式转换
这里使用了gguf的数据格式,该格式详细的介绍请参考【3】
3. 基于权重和框架进行推理
项目组成
接下来我们来看一下模型推理的流程。
在yolo对应的文件夹中,可以看到yolo可执行文件的生成方式。
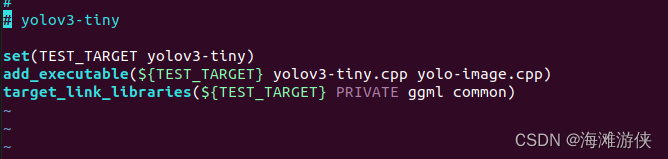
而经过仔细查看,yolo-image.cpp中,主要包含的是工具类的函数,而yolov3-tiny.cpp中,包含有main函数。
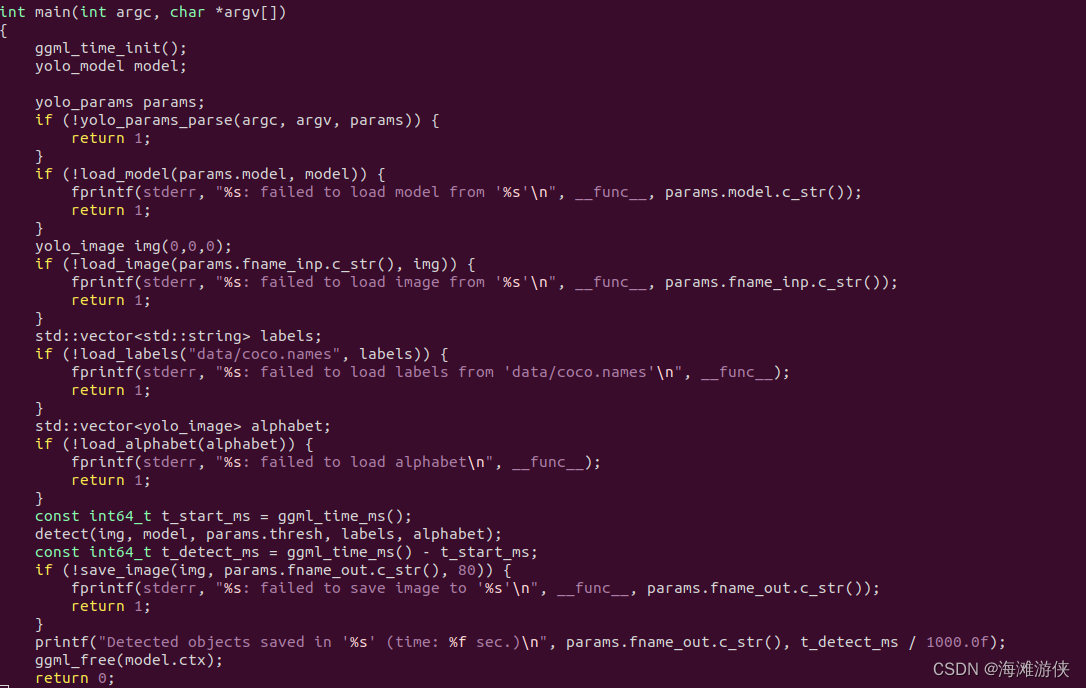
简单浏览一下main函数,可以看到主要包括如下几个部分
1. 模型加载
2. 图像预处理,及label加载
3. 检测
4. 输出图片
总结
第一讲我们梳理了一下yolo模型推理的流程,关键的步骤,展示了一下推理的结果。但是,更多的是引出了很多问题:
1. 模型加载过程中引入了哪些数据结构,哪些是比较常见的?数据结构设计时,考虑的点有哪些?
2. 模型推理的过程中,如何加速?有哪些加速方式?
3. gguf的数据格式还是让我比较困惑。是否有更多的开源代码呢?
【1】 YOLO: Real-Time Object Detection
【2】 https://github.com/ggerganov/ggml/tree/master/examples/yolo
【3】 https://github.com/ggerganov/ggml/blob/master/docs/gguf.md















 2051
2051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









