







训练大型语言模型,内存总是个大问题。
权重啊、优化器状态啊,都得吃内存,而且吃得还不少。
为了省内存,有人就想出了一些招儿,比如低秩适应(LoRA),就是给预训练权重添点儿可训练的低秩矩阵,这样就能少训练点参数,优化器状态也省了。
冻结预训练模型的参数还能加速训练呢,因为只有新模型的参数在更新,其他的都保持不变。
不过啊,这些方法虽然能省内存,但效果可能没全秩权重训练那么好。
因为它们限制了参数搜索的空间,改变了训练的方式,有时候可能还需要全秩热身来启动一下。
最近有人提出了一种新的训练策略,叫梯度低秩投影(GaLore)。
这招儿能让全参数学习更省内存,效果还挺好。
在优化器状态方面,它能减少高达65.5%的内存使用量,而且性能还不打折。在LLaMA 1B和7B架构上都试过了,确实有效果。
现在你可以试试在24GB内存的GPU上预训练那个7B参数的模型了,说不定真的能跑起来哦!
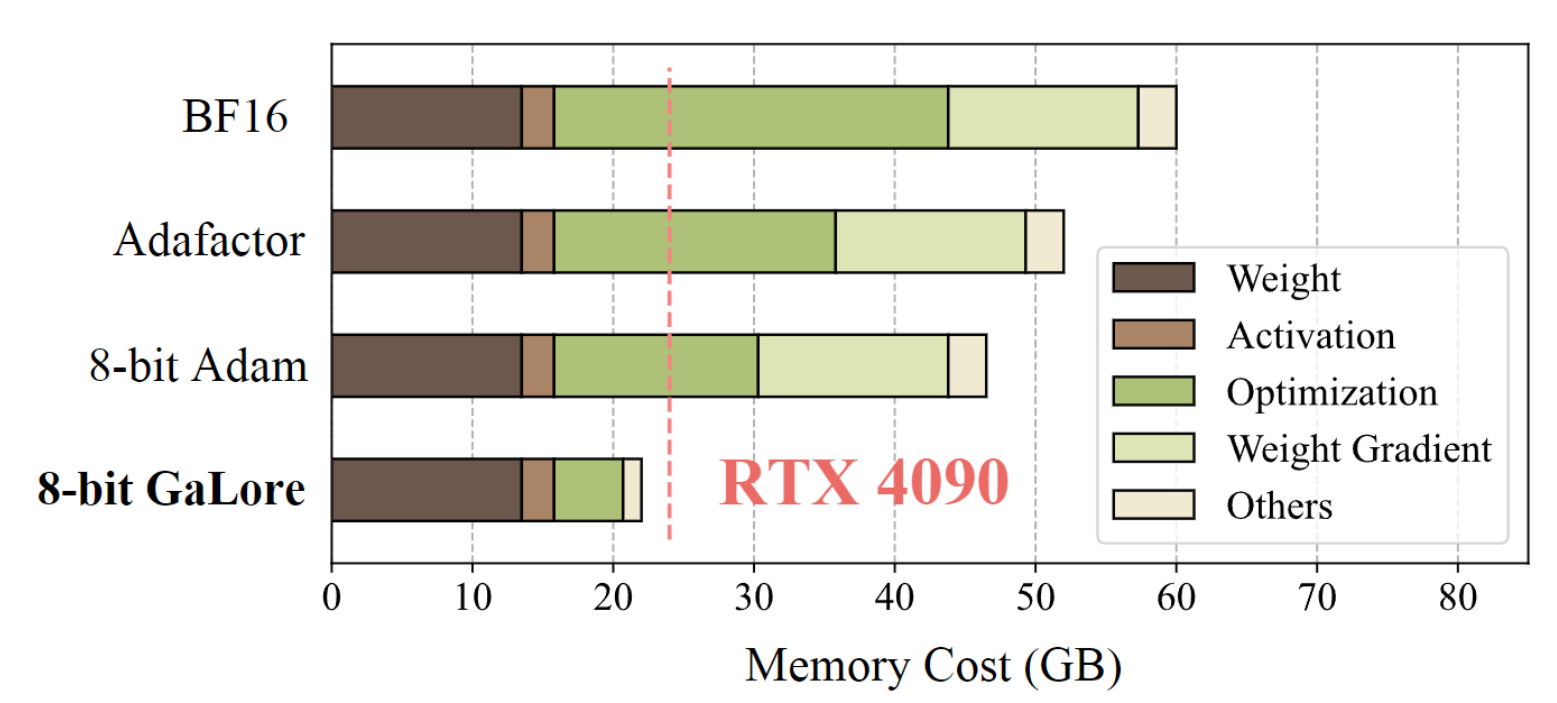
而且还不需要什么模型并行、检查点或卸载策略这些复杂的操作。
这不就是我们梦寐以求的“神器”吗?
不过啊,到底哪种预训练策略最好用呢?咱们一起来聊聊这些策略的使用过程吧。
内容迁移微信公众号:李孟聊AI




















 5122
5122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











