







最近DeepSeek V3 升级。
本文将带您了解该模型的核心特性、基准表现,以及如何通过Hugging Face推理终端和OpenRouter平台亲身体验。我们还将通过创意生成与逻辑分析两大测试案例,直观展示其卓越性能。
DeepSeek-V3-0324
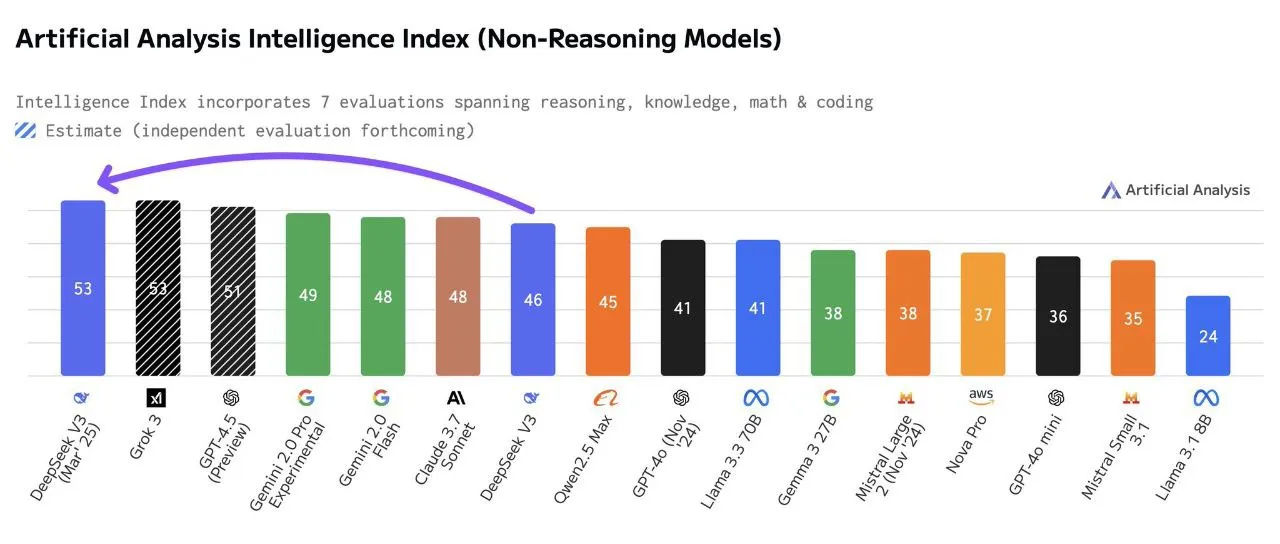
2025年3月24日,深度求索(DeepSeek)AI正式发布了V3系列的重磅升级——DeepSeek-V3-0324。
这一版本实现了质的飞跃:约700GB的庞大体量采用MIT开源协议,向全球开发者敞开怀抱;6850亿参数的混合专家(MoE)架构设计,使其性能不仅超越前代产品,更可与Claude 3.7等顶尖模型比肩。
突破性的性能表现
DeepSeek-V3-0324的卓越之处不仅在于规模,更在于实际性能。根据官方测试数据,其在编程能力方面尤为突出,甚至超越claude-sonnet-3.7和GPT4.5,这一重大突破为AI能力树立了新标杆。

核心升级亮点
DeepSeek-V3-0324在多个维度实现跨越式发展,以下是其最引人注目的进步领域:
1. 推理能力进化
该模型在复杂推理任务中展现显著提升:
• MMLU-Pro:75.9→81.2(+5.3)通用知识推理能力增强
• GPQA:59.1→68.4(+9.3)问答任务表现优化
• AIME:39.6→59.4(+19.8)数学推理实现跨越式突破
• LiveCodeBench:39.2→49.2(+10.0)编程挑战处理能力提升
这些基准测试证实,DeepSeek-V3-0324不仅具备顶尖竞争力,更在准确性与逻辑推理方面定义了新标准。
2. 前端开发赋能
模型生成的网页代码质量显著提升:
• 可执行性增强:产出代码更稳定可靠,实现无缝部署
• 美学升级:网页与游戏界面设计更符合现代审美标准
这种功能性与美观性的双重突破,使其成为前端开发者的得力助手。
3. 中文写作精进
针对中文使用者特别优化:
• 文风把控:精准契合R1风格的清晰雅致表达
• 长文本优化:大幅提升报告、文章等长篇幅内容质量
这些改进确保模型能产出符合专业要求的精品文本。
4. 功能体验升级
• 多轮交互改写:支持持续对话下的内容优化调整
如何体验DeepSeek-V3?
通过Hugging Face测试
作为最受欢迎的AI模型平台之一,Hugging Face提
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 118
118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











