







摘要
大多数目标检测算法可以分为两类:两阶段检测器和单阶段检测器。对于两阶段探测器,区域建议阶段可以在第一阶段过滤大量的背景候选,并且使在第二阶段的分类任务更平衡。近年来,单阶段探测器因其结构简单、效率高而受到广泛关注。与两阶段探测器不同,单阶段探测器必须在一个阶段内从所有候选对象中识别出前景对象。这种体系结构是有效的,但在两个方面可能会遇到不均衡的问题:类的不均衡与背景分布的不均衡,只有少数候选框难以识别的。在这项工作中,我们建议通过发展分配the distributional ranking (DR) loss 来解决这一挑战。首先,我们将分类问题转化为一个ranking问题,以缓解类不均衡问题。然后,我们建议在约束最坏情况下,将前景候选框的分布排序在背景候选狂的分布之上。该策略不仅解决了背景候选的不均衡问题,而且提高了排序算法的效率。除了分类任务外,我们还按照内点法(interior-point methods)逐步逼近l1损失,从而改善回归损失。为了评估提出的损失理论,我们替换了具有最先进性能的RetinaNet的相应损失。该方法以resnet-101为主干,只需改变损失函数,就可以将coco数据集的映射从39:1%提高到41:1%,并验证了所提出损失的有效性。
1. Introduction
近年来,随着深度神经网络(deep neural networks)的发展,目标检测(object detection)的性能得到了显著提高。大多数检测算法分为两类:两阶段检测器[3、11、12、14] (two-stage detectors) 和单阶段检测器[6、15、17、20] (one-stage detectors)。对于两阶段模式,算法的过程可以分为两个部分。在第一阶段,区域建议方法将过滤大部分背景候选边界框,只保留一小部分候选。在第二阶段中,这些候选对象被分类为前景或背景,通过优化回归损失进一步优化边界框。两阶段探测器在实际数据集上表现出优越的性能,而效率在实践中可能是一个问题,特别是对于计算资源有限的设备,如智能手机、相机等。
因此,为了有效地进行检测,研制了单阶段探测器。与两阶段探测器不同,单阶段算法由一个单相组成,必须直接从所有候选对象中识别出前景对象。单阶段探测器的结构简单有效。然而,单阶段探测器可能会遇到以下两个方面的不平衡问题。首先,类别之间的候选数量不均衡。如果没有区域提出(region proposal)阶段,背景候选的数量很容易超过前景候选的数量。第二,背景候选的分布不平衡。它们中的大多数可以很容易地与前景对象分开,而只有少数很难区分。
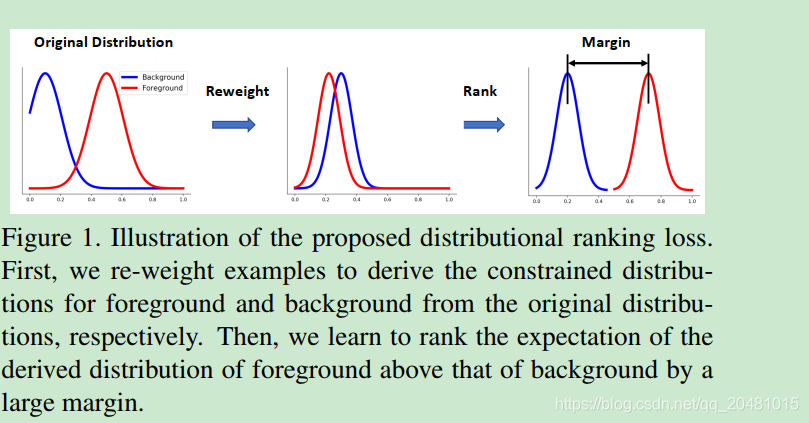
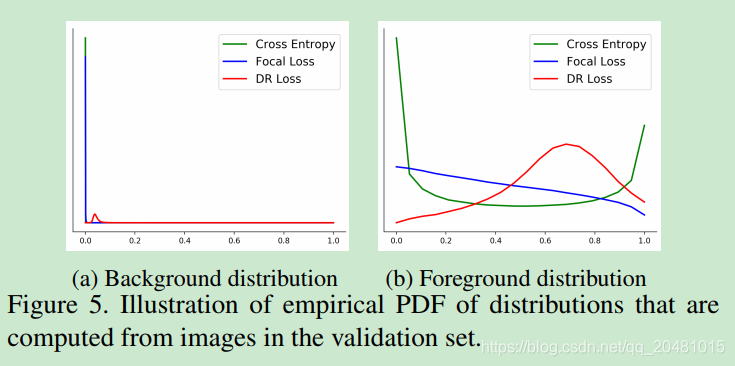
为了缓解不平衡问题,SSD[17]采用了hard negative mining,保留了一小部分损失最大的背景候选对象。通过消除简单的背景候选,该策略可以同时平衡班级之间的候选数量和背景分布。然而,一些重要的背景分类信息可能会丢失,从而降低检测性能。Retinanet[15]建议保留所有背景候选,但为损失函数分配不同的权重。加权交叉熵损失(The weighted cross entropy loss)称为focal loss。它使算法在保留所有候选信息的同时,将重点放在the hard candidates上。该策略显著提高了单级探测器的性能。尽管焦点损失取得了成功,但它以启发式的方式重新加权分类损失,不足以解决类不平衡问题。此外,focal loss的设计是数据独立的,缺乏对数据分布的探索,这对于平衡背景候选分布至关重要。
在这项工作中,我们提出了一个与数据相关的ranking loss来处理不平衡的挑战。首先,为了减轻类不平衡问题的影响,我们将分类问题转化为一个ranking问题,从而优化对的排序。因为每一对都由一个前景候选和一个背景候选组成,所以它是平衡的。此外,考虑到背景候选的不平衡,引入distributional ranking (DR)损失,将前景的约束分布排序在背景候选人的约束分布之上。通过对候选项进行重新加权,得到对应于最坏情况下损失的分布,损失可以集中在前景和背景分布之间的决策边界上。此外,我们将分布的期望值进行排序,以取代原来的例子,从而减少了排序中的对数,提高了效率。与Focal loss的re-weighting策略相比,DR loss策略具有数据依赖性,能够更好地平衡背景分布。图1说明了提出的Focal loss。除了分类任务外,回归对检测对象边界框的细化也很重要。在检测算法中,通常采用平滑的L1损失来近似L1损失。我们建议通过逐步逼近L1损失来改善回归损失,以便更好地近似,其中类似的技巧也应用于内点法[1]。
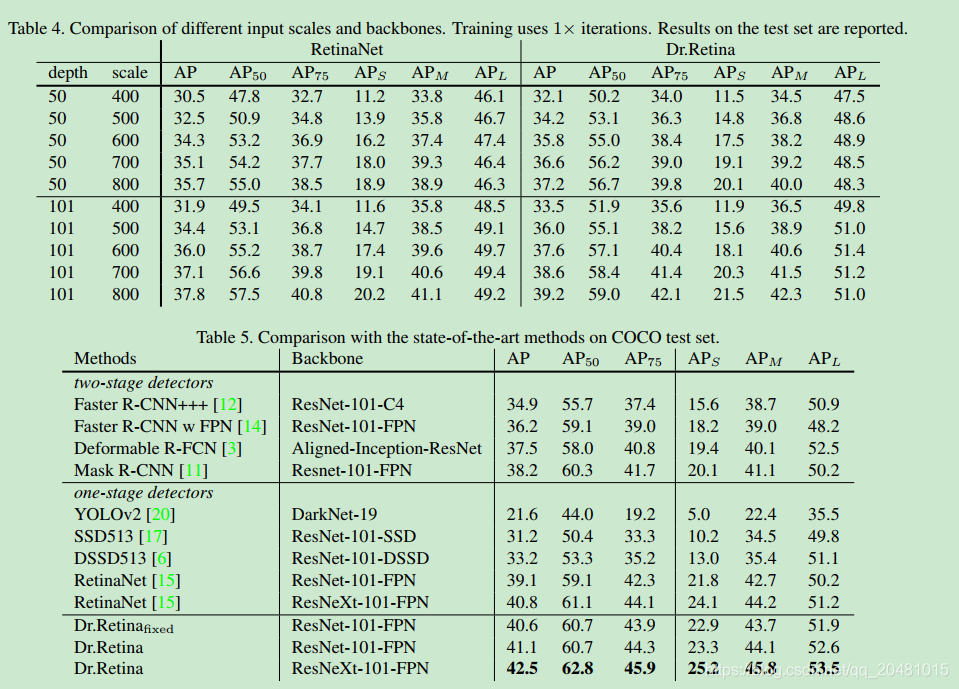
我们对COCO[16]数据集进行了实验,以证明所提出的loss。由于retinanet代表了单阶段探测器的最新性能,因此我们将retinanet中的相应损失替换为DR loss,而保留其他组件。为了公平比较,我们在retinanet的官方代码库Detectron 中实现了我们的算法。以resnet-101[12]为骨干,优化我们的损失函数可以将retinanet的mAP从39:1%提高到41:1%,这证实了所提出损失的有效性。
2. Related Work
检测是计算机视觉的基本任务。在传统的方法中,hand crafted的特征,如HOG[4]和SIFT[18]被用于检测,要么使用滑动窗口策略,该策略产生一组密集的候选框,如DPM[5],要么使用保留一组稀疏候选对象的区域提出方法,如选择性搜索[23]。最近,由于深层神经网络在分类任务中显示出主导性的性能[13],因此利用从神经网络中获得的特征被用于检测。
R-CNN[9]使用了区域提出,并作为两阶段算法工作。它首先通过选择性搜索得到一组稀疏的候选框。在下一阶段,应用深度卷积神经网络(CNN)提取每个候选框的特征。最后,使用常规分类器对区域进行分类,例如,SVM。R-CNN大大提高了检测性能,但对于实际应用来说,这个过程太慢了。因此,开发了许多变体来加速它[8,21]。为了进一步提高精度,Mask-RCNN[11]增加了一个用于对象掩码预测的分支,以利用来自多任务学习的附加信息提高性能。除了两阶段结构外,Cascade R-CNN[2]还开发了一种多阶段策略,以级联方式在区域建议阶段之后提高探测器的质量。
为了提高效率,还开发了单阶段探测器[17、19、22]。由于没有区域提出阶段对背景候选样本进行抽样,因此单阶段检测器在类间和背景分布中都存在不平衡问题。为了缓解挑战,SSD[17]采用了hard example mining,只保留了用于训练的the hard background candidates。最近,retinanet[15] 提出通过focal loss失来解决这个问题。与SSD不同的是,它保留了所有背景候选项,但对它们进行了重新加权,这样hard example将被赋予很大的权重。focal loss对检测性能有明显的改善,但对检测中的不平衡问题的研究还不够充分。在这项工作中,我们发展了对前景和背景分布进行排序的the distributional ranking loss。它可以通过一种数据依赖机制来缓解不平衡问题,更好地捕获数据分布。
3. DR Loss
给定一组来自图像的候选边界框,检测器必须使用分类模型从背景边界框识别前景对象。让表示一个分类器,它可以通过优化问题来学习。
(1)
其中是总图像数。在本文中,我们使用sigmoid函数来预测每个example的概率。
由
确定,表示第
图像中第
候选对象来自
类的估计概率。
是损失函数。在大多数检测器中,分类器是通过优化交叉熵损失来学习的。对于二进制分类问题,它可以写为
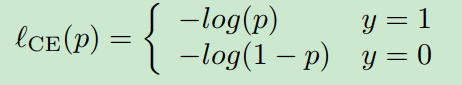
这儿,。
Eqn. 1常被用于目标检测,存在类不平衡问题。这可以通过将问题改写成等价的形式来证明
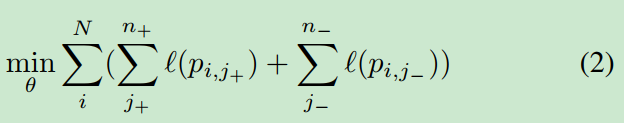
这儿,,
分别表示正例和负例,
,
分别表示正examples和负examples的数量。当
时,后一项的累计损失将占主导地位。这一问题的根源在于正例和负例的损失是分开的,正例的贡献会被负例所淹没。一种启发式的处理方法是加强正的例子,这样可以增加相应损失的权重。在这项工作中,我们的目标是从根本上解决这个问题。
3.1. Ranking
为了缓解类不平衡带来的挑战,我们优化了正例和负例之间的rank。给出一对正、负样本,理想的排序模型可以使正样本的排序远高于负样本。
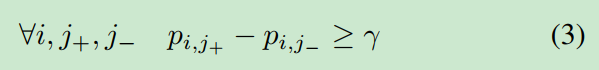
这儿,是一个非负值.与公式1、ranking模型优化了个体正负示例之间的关系,这是均衡的(注:因为假设数据成对存在)。
ranking的目标函数可以写成:
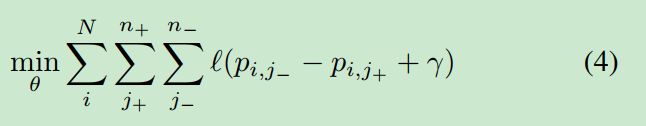
这儿,是铰链损失(the hinge loss)(注:一般用于最大间隔分类,例如在SVM中)
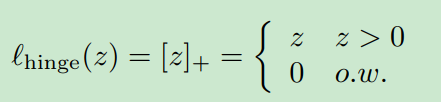
目标函数可以被解释为
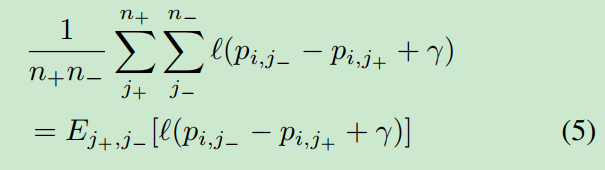
通过对一对正、负样本的均匀抽样,证明了该目标对预期ranking loss的度量。
ranking loss通过比较每一个正例和负例的排名来解决类失衡问题。然而,它忽略了对象检测中的一个现象,即负例的分布也不平衡。此外,ranking loss带来了一个新的挑战,即大量的配对。我们将在下面的小节中讨论它们。
3.2. Distributional Ranking
如公式5所示,公式4中的ranking loss惩罚了对均匀采样的错误排序。在检测中,绝大多数的负样本都可以很容易地进行排序,也就是说,一对随机抽样的样本不会产生高概率的排序损失。因此,我们建议优化排序边界以避免琐碎的解。
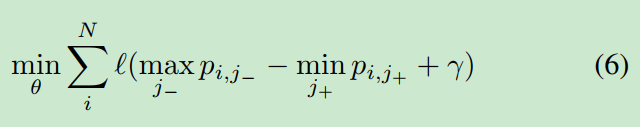
如果我们能把得分最低的正例排在得分最高的负例的上面,那么整个候选框的排序就完美了。与传统的ranking loss相比,最坏情况下的损失更有效,因为将配对数从减少到1。此外,它还清楚地消除了类不平衡问题,因为每个图像只需要一对正负示例。然而,该公式对异常值非常敏感,会导致检测模型的退化。
为了提高鲁棒性,我们首先引入正负例的分布,并得到期望值
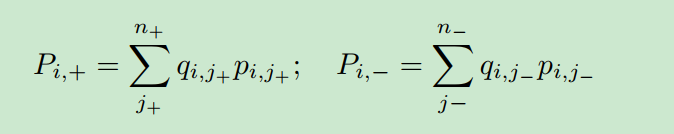
这儿,和
分别表示正例和负例上的分布,
,
分别表示相应分布下的期望排名分数,
。当
和
为均匀分布时,
和
表示原始分布的期望。
由原分布推导出最坏情况下损失对应的分布(注:求解下式的q):
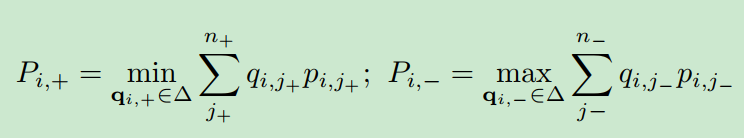
我们可以把公式6的问题改写成等价形式
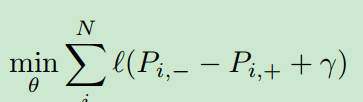
在最坏的情况下,它可以被认为是对正例和负例之间的分布进行排序。很明显,由于生成分布的域是无约束的,原始公式并不具有鲁棒性。因此,它将集中在单个示例上,而忽略原始分布(注:简单说pij+最小的那个,对应qij+为1,同理pij-最小的那个,对应qij-为1)。因此,我们通过将派生分布的自由度调整为
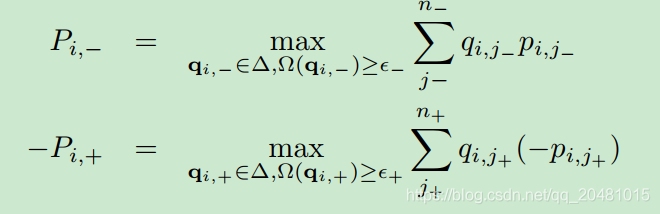
是分布多样性的一个正则化器,可以防止分布到平凡one-hot解决方案。它可以是不同形式的熵,如仁义熵、香农熵等。
和
是控制分布自由度的常量。(注:变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大)
为了得到约束分布,我们研究了下面的子问题:
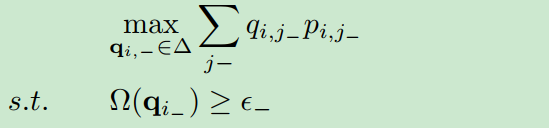
根据【1】,给定,我们可以找到参数
获得最优
,通过解决下面这个问题:
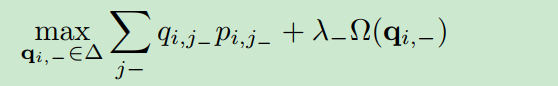
第一项是线性的,如果第二项是强凹(注意:国际通用的凹凸说法和国内是相反的),这个问题就可以通过【1】被有效的解决。
考虑到效率,本文采用香农熵作为正则化器,可以得到如下的闭式解。
命题1:对于问题
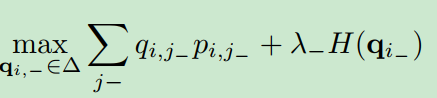
我们有闭式解
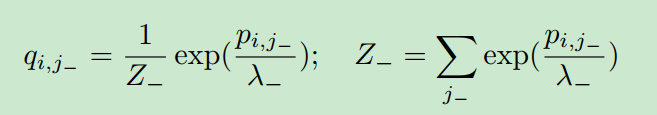
同样:对于正样本上的分布,我们得到了类似的结果
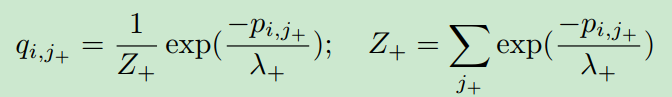
备注1:这些命题表明,样例越难,样例的权重越大。此外,权重依赖于数据,受数据分布的影响。
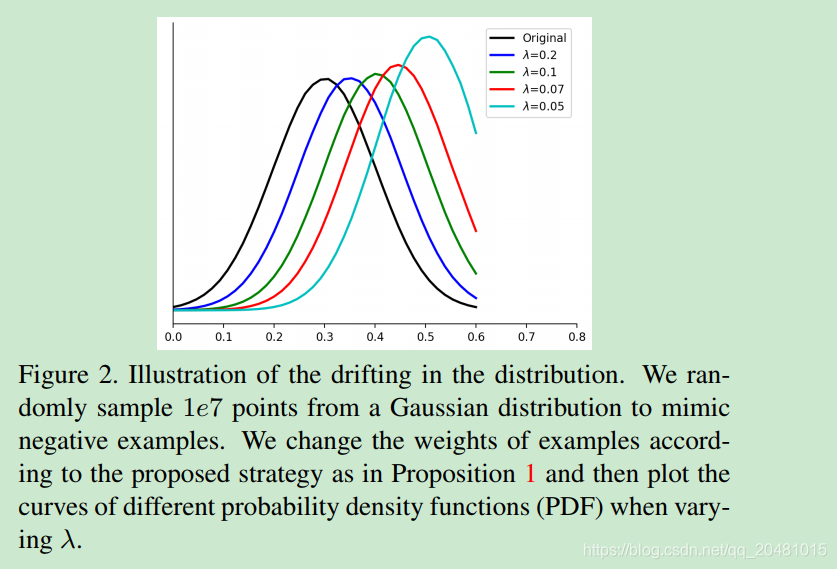
图2给出了该策略下的分布漂移情况。当减少,派生的分布接近对应于最糟糕的分布损失时。
对于分布的闭式解,分布的期望可以计算为:
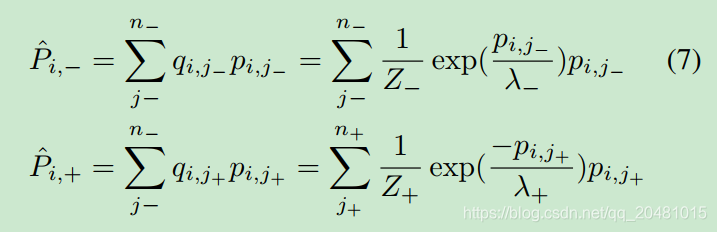
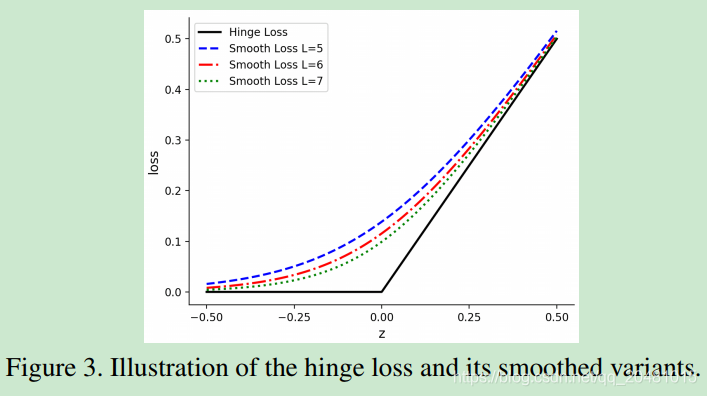
最后,光滑性对非凸优化[7]的收敛至关重要。因此,我们使用平滑近似(公式8)代替原来的铰链损耗作为损耗函数[25]
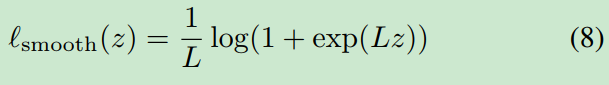
其中控制函数的平滑度。
越大,近似值越接近铰链损失。图3将铰链损失与公式8平滑后的版本进行比较。
综合所有这些因素,我们的distributional ranking loss可以定义为:
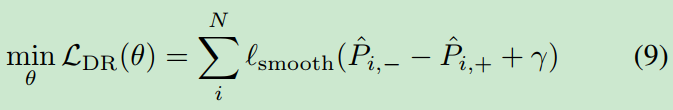
与传统的排序损失相比,我们对两个分布之间的期望进行了排序。它将“对”的数量减少到1,从而实现有效的优化。
Eqn. 9中的目标看起来很复杂,但是它的梯度很容易计算。梯度的详细计算见附录。
采用标准随机梯度下降法(SGD),以小批量为优化对象,优化DR loss。
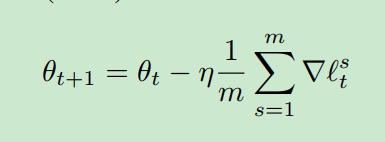
我们可以证明它可以像下面的定理那样收敛,详细的证明在附录中给出。
3.3. Recover Classification from Ranking
在检测中,我们必须从背景中识别前景。因此,Ranking的结果必须转换为分类。一个简单的方法是为ranking score设置一个阈值。然而,不同“对”的分数在分类上可能是不一致的。例如,给定两对分数:
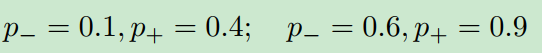
我们观察到,这两个例子都有完美的排名,但很难设置一个阈值来同时区分正样例和负样例。为了使ranking results对分类有意义,我们执行一个约束3:。因此,约束变成:
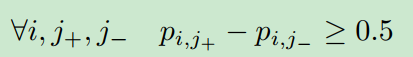
由于概率的非负性,它意味着
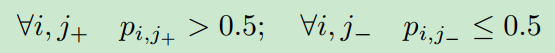
恢复了分类的标准准则。
3.4. Bounding Box Regression
除了分类外,回归对于检测和细化边界框也很重要。大多数检测器采用平滑损失来优化bounding box。
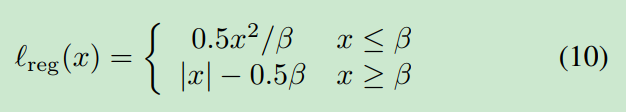
它通过在区间[−;
]上的
损失平滑
损失,保证整个损失函数光滑。这是合理的,因为光滑性对收敛很重要,如定理1所示。(具体介绍)。然而,它可能导致
损失在区间的优化变慢。受逐渐通过在不同阶段增加相应barrier function接近非光滑区域的权重内点法刺激[1],从一个递减函数中得到
,以减小
和
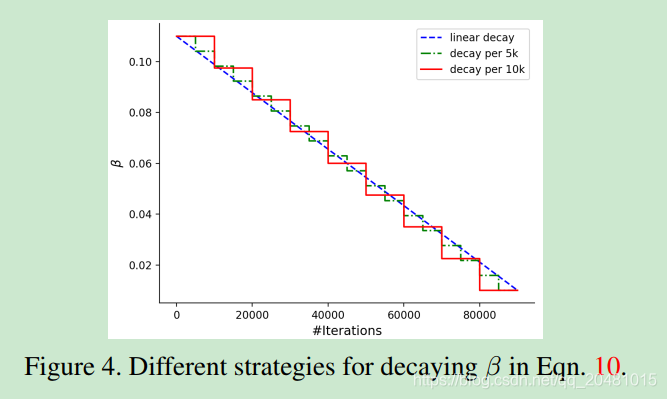
之间的损失。如内点法所建议的,在改变barrier function的权重之前,应将当前目标求解为最优。我们逐步衰减
的值。具体来说,我们在
次迭代计算
为:
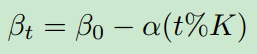
是一个常量,
是迭代次数。结合回归损失,训练检测器的目标函数为:
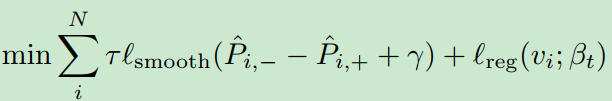
4. Experiments
4.1. Implementation Details
数据集:COCO2017
硬件:8 GPU
测试网络:RetinaNet
4.2 Effect of Parameters
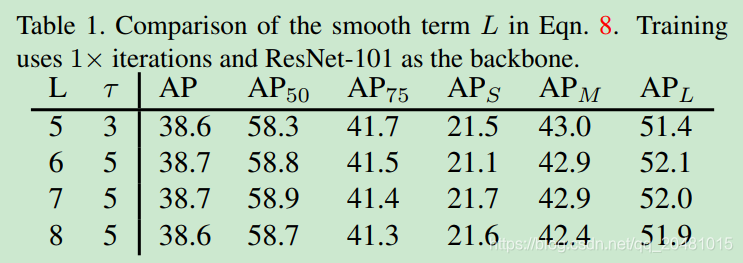
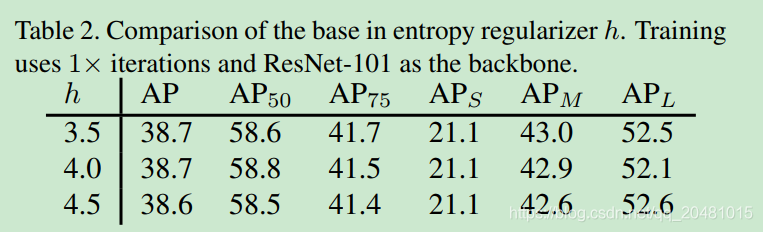
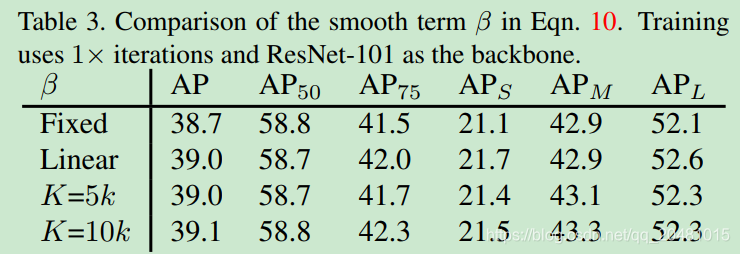

















 5811
5811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









