







文章目录
参考:
https://www.deepspeed.ai/getting-started/
https://www.deepspeed.ai/tutorials/cifar-10/
https://github.com/NVIDIA/Megatron-LM
https://docs.nvidia.com/megatron-core/developer-guide/latest/user-guide/index.html#quick-start
https://colossalai.org/
https://github.com/OpenBMB/BMTrain
《大模型导论》
1. DeepSpeed
它是一个易于使用的深度学习优化软件套件,为训练和推理提供了前所未有的规模和速度。
-
训练/推理具有数十亿或数万亿个参数的密集或稀疏模型
-
实现出色的系统吞吐量并高效扩展到数千个 GPU
-
在资源受限的 GPU 系统上进行训练/推理
-
实现前所未有的低延迟和高吞吐量,实现推理
-
实现极致压缩,以低成本实现无与伦比的推理延迟和模型大小缩减
1. 安装
pip install deepspeed
检查有哪些兼容操作
$ ds_report
[2024-12-02 19:40:06,326] [INFO] [real_accelerator.py:219:get_accelerator] Setting ds_accelerator to cuda (auto detect)
--------------------------------------------------
DeepSpeed C++/CUDA extension op report
--------------------------------------------------
NOTE: Ops not installed will be just-in-time (JIT) compiled at
runtime if needed. Op compatibility means that your system
meet the required dependencies to JIT install the op.
--------------------------------------------------
JIT compiled ops requires ninja
ninja .................. [OKAY]
--------------------------------------------------
op name ................ installed .. compatible
--------------------------------------------------
[WARNING] async_io requires the dev libaio .so object and headers but these were not found.
[WARNING] async_io: please install the libaio-devel package with yum
[WARNING] If libaio is already installed (perhaps from source), try setting the CFLAGS and LDFLAGS environment variables to where it can be found.
async_io ............... [NO] ....... [NO]
fused_adam ............. [NO] ....... [OKAY]
cpu_adam ............... [NO] ....... [OKAY]
cpu_adagrad ............ [NO] ....... [OKAY]
cpu_lion ............... [NO] ....... [OKAY]
[WARNING] Please specify the CUTLASS repo directory as environment variable $CUTLASS_PATH
evoformer_attn ......... [NO] ....... [NO]
[WARNING] NVIDIA Inference is only supported on Ampere and newer architectures
fp_quantizer ........... [NO] ....... [NO]
fused_lamb ............. [NO] ....... [OKAY]
fused_lion ............. [NO] ....... [OKAY]
/opt/bdp/data01/miniforge3/envs/py38/compiler_compat/ld: /usr/local/cuda/lib64/libcufile.so: undefined reference to `dlvsym'
/opt/bdp/data01/miniforge3/envs/py38/compiler_compat/ld: /usr/local/cuda/lib64/libcufile.so: undefined reference to `dlopen'
/opt/bdp/data01/miniforge3/envs/py38/compiler_compat/ld: /usr/local/cuda/lib64/libcufile.so: undefined reference to `dlclose'
/opt/bdp/data01/miniforge3/envs/py38/compiler_compat/ld: /usr/local/cuda/lib64/libcufile.so: undefined reference to `dlerror'
/opt/bdp/data01/miniforge3/envs/py38/compiler_compat/ld: /usr/local/cuda/lib64/libcufile.so: undefined reference to `dlsym'
collect2: error: ld returned 1 exit status
gds .................... [NO] ....... [NO]
transformer_inference .. [NO] ....... [OKAY]
inference_core_ops ..... [NO] ....... [OKAY]
cutlass_ops ............ [NO] ....... [OKAY]
quantizer .............. [NO] ....... [OKAY]
ragged_device_ops ...... [NO] ....... [OKAY]
ragged_ops ............. [NO] ....... [OKAY]
random_ltd ............. [NO] ....... [OKAY]
[WARNING] sparse_attn requires a torch version >= 1.5 and < 2.0 but detected 2.4
[WARNING] using untested triton version (3.0.0), only 1.0.0 is known to be compatible
sparse_attn ............ [NO] ....... [NO]
spatial_inference ...... [NO] ....... [OKAY]
transformer ............ [NO] ....... [OKAY]
stochastic_transformer . [NO] ....... [OKAY]
--------------------------------------------------
DeepSpeed general environment info:
torch install path ............... ['/opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/torch']
torch version .................... 2.4.0+cu121
deepspeed install path ........... ['/opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/deepspeed']
deepspeed info ................... 0.16.0, unknown, unknown
torch cuda version ............... 12.1
torch hip version ................ None
nvcc version ..................... 12.4
deepspeed wheel compiled w. ...... torch 2.4, cuda 12.1
shared memory (/dev/shm) size .... 78.57 GB
2. 单卡训练
git clone https://github.com/microsoft/DeepSpeedExamples.git
cd DeepSpeedExamples/training/cifar
pip install -r requirements.txt
python cifar10_tutorial.py # 首次执行会下载数据集
输出:
Using downloaded and verified file: ./data/cifar-10-python.tar.gz
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
cat car dog car
[1, 2000] loss: 2.251
[1, 4000] loss: 1.926
[1, 6000] loss: 1.715
[1, 8000] loss: 1.598
[1, 10000] loss: 1.566
[1, 12000] loss: 1.504
[2, 2000] loss: 1.432
[2, 4000] loss: 1.420
[2, 6000] loss: 1.355
[2, 8000] loss: 1.344
[2, 10000] loss: 1.319
[2, 12000] loss: 1.305
Finished Training
GroundTruth: cat ship ship plane
cifar10_tutorial.py:233: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
net.load_state_dict(torch.load(PATH))
Predicted: cat ship ship plane
Accuracy of the network on the 10000 test images: 54 %
Accuracy of plane : 66 %
Accuracy of car : 68 %
Accuracy of bird : 33 %
Accuracy of cat : 46 %
Accuracy of deer : 38 %
Accuracy of dog : 27 %
Accuracy of frog : 65 %
Accuracy of horse : 66 %
Accuracy of ship : 77 %
Accuracy of truck : 55 %
cuda:0
可以看到训练只用到了一个GPU
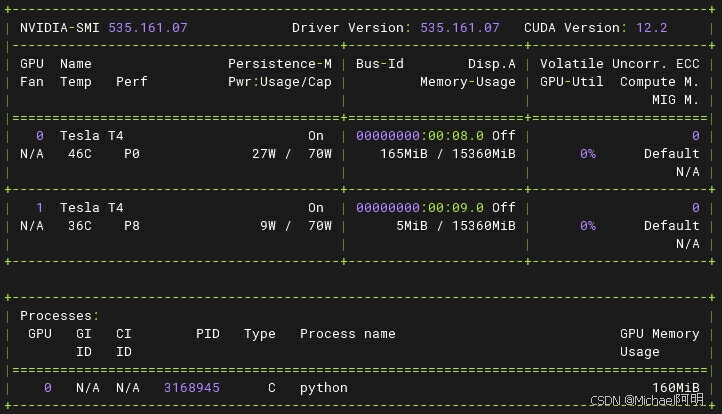
3. DS多卡训练
参数解析
应用 DeepSpeed 的第一步是将 DeepSpeed 参数添加到 CIFAR-10 模型中,使用 deepspeed.add_config_arguments()
import argparse
import deepspeed
def add_argument():
parser=argparse.ArgumentParser(description='CIFAR')
# Data.
# Cuda.
parser.add_argument('--with_cuda', default=False, action='store_true',
help='use CPU in case there\'s no GPU support')
parser.add_argument('--use_ema', default=False, action='store_true',
help='whether use exponential moving average')
# Train.
parser.add_argument('-b', '--batch_size', default=32, type=int,
help='mini-batch size (default: 32)')
parser.add_argument('-e', '--epochs', default=30, type=int,
help='number of total epochs (default: 30)')
parser.add_argument('--local_rank', type=int, default=-1,
help='local rank passed from distributed launcher')
# Include DeepSpeed configuration arguments.
parser = deepspeed.add_config_arguments(parser)
args=parser.parse_args()
return args
初始化
在 deepspeed.initialize 的帮助下创建 model_engine、optimizer 和 trainloader
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
batch_size = 4
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
def initialize(args,
model,
optimizer=None,
model_params=None,
training_data=None,
lr_scheduler=None,
mpu=None,
dist_init_required=True,
collate_fn=None):
# Initialize DeepSpeed to use the following features
# 1) Distributed model.
# 2) Distributed data loader.
# 3) DeepSpeed optimizer.
model_engine, optimizer, trainloader, _ = deepspeed.initialize(args=args, model=model, model_parameters=model_params,
training_data=training_data)
return model_engine, optimizer, trainloader
训练
criterion = nn.CrossEntropyLoss()
parameters = filter(lambda p: p.requires_grad, net.parameters())
args = add_argument()
model_engine, optimizer, trainloader = initialize(args, net, model_params=parameters, training_data=trainset)
for i, data in enumerate(trainloader):
# Get the inputs; data is a list of [inputs, labels].
inputs = data[0].to(model_engine.device)
labels = data[1].to(model_engine.device)
outputs = model_engine(inputs)
loss = criterion(outputs, labels)
model_engine.backward(loss)
model_engine.step()
在使用小批量更新权重后,DeepSpeed 会自动处理梯度归零
配置
创建配置文件 ds_config.json
{
"train_batch_size": 4,
"steps_per_print": 2000,
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.001,
"betas": [
0.8,
0.999
],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.001,
"warmup_num_steps": 1000
}
},
"wall_clock_breakdown": false
}
执行训练
deepspeed cifar10_deepspeed.py --deepspeed_config ds_config.json
机器的 gcc 版本不满足,要求在 9.0以上,没能执行成功,后续再研究
[2024-12-04 09:01:30,169] [INFO] [real_accelerator.py:219:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-12-04 09:01:32,689] [WARNING] [runner.py:215:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.
[2024-12-04 09:01:32,689] [INFO] [runner.py:607:main] cmd = /opt/bdp/data01/miniforge3/envs/py38/bin/python -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMCwgMV19 --master_addr=127.0.0.1 --master_port=29500 --enable_each_rank_log=None deepspeed1.py
[2024-12-04 09:01:34,339] [INFO] [real_accelerator.py:219:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-12-04 09:01:36,793] [INFO] [launch.py:146:main] WORLD INFO DICT: {'localhost': [0, 1]}
[2024-12-04 09:01:36,793] [INFO] [launch.py:152:main] nnodes=1, num_local_procs=2, node_rank=0
[2024-12-04 09:01:36,793] [INFO] [launch.py:163:main] global_rank_mapping=defaultdict(<class 'list'>, {'localhost': [0, 1]})
[2024-12-04 09:01:36,793] [INFO] [launch.py:164:main] dist_world_size=2
[2024-12-04 09:01:36,793] [INFO] [launch.py:168:main] Setting CUDA_VISIBLE_DEVICES=0,1
[2024-12-04 09:01:36,808] [INFO] [launch.py:256:main] process 2284035 spawned with command: ['/opt/bdp/data01/miniforge3/envs/py38/bin/python', '-u', 'deepspeed1.py', '--local_rank=0']
[2024-12-04 09:01:36,819] [INFO] [launch.py:256:main] process 2284036 spawned with command: ['/opt/bdp/data01/miniforge3/envs/py38/bin/python', '-u', 'deepspeed1.py', '--local_rank=1']
[2024-12-04 09:01:38,447] [INFO] [real_accelerator.py:219:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-12-04 09:01:38,493] [INFO] [real_accelerator.py:219:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-12-04 09:01:40,979] [INFO] [comm.py:652:init_distributed] cdb=None
[2024-12-04 09:01:40,979] [INFO] [comm.py:683:init_distributed] Initializing TorchBackend in DeepSpeed with backend nccl
[2024-12-04 09:01:41,038] [INFO] [comm.py:652:init_distributed] cdb=None
Files already downloaded and verified
Files already downloaded and verified
[2024-12-04 09:01:43,136] [INFO] [logging.py:128:log_dist] [Rank 0] DeepSpeed info: version=0.16.0, git-hash=unknown, git-branch=unknown
[2024-12-04 09:01:43,136] [INFO] [config.py:733:__init__] Config mesh_device None world_size = 2
[2024-12-04 09:01:43,136] [WARNING] [config_utils.py:70:_process_deprecated_field] Config parameter cpu_offload is deprecated use offload_optimizer instead
Files already downloaded and verified
Files already downloaded and verified
[2024-12-04 09:01:44,745] [INFO] [config.py:733:__init__] Config mesh_device None world_size = 2
[2024-12-04 09:01:44,745] [WARNING] [config_utils.py:70:_process_deprecated_field] Config parameter cpu_offload is deprecated use offload_optimizer instead
[2024-12-04 09:01:44,838] [INFO] [logging.py:128:log_dist] [Rank 0] DeepSpeed Flops Profiler Enabled: False
Using /home/web/.cache/torch_extensions/py38_cu121 as PyTorch extensions root...
Using /home/web/.cache/torch_extensions/py38_cu121 as PyTorch extensions root...
Detected CUDA files, patching ldflags
Emitting ninja build file /home/web/.cache/torch_extensions/py38_cu121/fused_adam/build.ninja...
/opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/torch/utils/cpp_extension.py:1965: UserWarning: TORCH_CUDA_ARCH_LIST is not set, all archs for visible cards are included for compilation.
If this is not desired, please set os.environ['TORCH_CUDA_ARCH_LIST'].
warnings.warn(
Building extension module fused_adam...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[1/3] /usr/local/cuda/bin/nvcc --generate-dependencies-with-compile --dependency-output multi_tensor_adam.cuda.o.d -DTORCH_EXTENSION_NAME=fused_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/deepspeed/ops/csrc/includes -I/opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/deepspeed/ops/csrc/adam -isystem /opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/torch/include -isystem /opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/torch/include/torch/csrc/api/include -isystem /opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/torch/include/TH -isystem /opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /opt/bdp/data01/miniforge3/envs/py38/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_75,code=compute_75 -gencode=arch=compute_75,code=sm_75 --compiler-options '-fPIC' -O3 -DVERSION_GE_1_1 -DVERSION_GE_1_3 -DVERSION_GE_1_5 -lineinfo --use_fast_math -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_75,code=compute_75 -std=c++17 -c /opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/deepspeed/ops/csrc/adam/multi_tensor_adam.cu -o multi_tensor_adam.cuda.o
FAILED: multi_tensor_adam.cuda.o
/usr/local/cuda/bin/nvcc --generate-dependencies-with-compile --dependency-output multi_tensor_adam.cuda.o.d -DTORCH_EXTENSION_NAME=fused_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/deepspeed/ops/csrc/includes -I/opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/deepspeed/ops/csrc/adam -isystem /opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/torch/include -isystem /opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/torch/include/torch/csrc/api/include -isystem /opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/torch/include/TH -isystem /opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /opt/bdp/data01/miniforge3/envs/py38/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_75,code=compute_75 -gencode=arch=compute_75,code=sm_75 --compiler-options '-fPIC' -O3 -DVERSION_GE_1_1 -DVERSION_GE_1_3 -DVERSION_GE_1_5 -lineinfo --use_fast_math -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_75,code=compute_75 -std=c++17 -c /opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/deepspeed/ops/csrc/adam/multi_tensor_adam.cu -o multi_tensor_adam.cuda.o
In file included from /opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/torch/include/c10/util/CallOnce.h:8,
from /opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/torch/include/ATen/Context.h:22,
from /opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/torch/include/ATen/ATen.h:7,
from /opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/deepspeed/ops/csrc/adam/multi_tensor_adam.cu:11:
/opt/bdp/data01/miniforge3/envs/py38/lib/python3.8/site-packages/torch/include/c10/util/C++17.h:13:2: error: #error "You're trying to build PyTorch with a too old version of GCC. We need GCC 9 or later."
#error \
^~~~~
2. Megatron-LM
Megatron-LM 是 英伟达开发的分布式训练大模型的工具框架,支持数据并行、模型并行(张量并行、流水线并行)
内置高效数据加载器,拆分数据带有索引编号的序列,提高处理效率
采用CUDA融合技术,减少与内存的交互次数
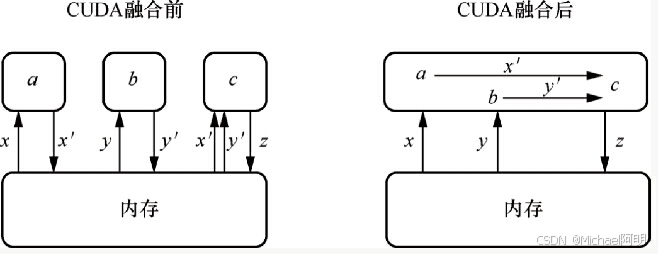
1. 安装
sudo docker run --ipc=host --shm-size=512m --gpus all -it nvcr.io/nvidia/pytorch:24.02-py3
pip install megatron_core
pip install tensorstore==0.1.45
pip install zarr
2. 主要步骤
- 初始化分布式训练和模型并行设置
import torch
from megatron.core import parallel_state
torch.distributed.init_process_group(world_size=world_size, rank=rank)
parallel_state.initialize_model_parallel(tensor_model_parallel_size, pipeline_model_parallel_size)
- GPT 模型配置
from megatron.core.transformer.transformer_config import TransformerConfig
from megatron.core.models.gpt.gpt_model import GPTModel
from megatron.core.models.gpt.gpt_layer_specs import get_gpt_layer_local_spec
def model_provider():
"""Build the model."""
transformer_config = TransformerConfig(
num_layers=2,
hidden_size=12,
num_attention_heads=4,
use_cpu_initialization=True,
pipeline_dtype=torch.float32)
gpt_model = GPTModel(
config=transformer_config,
transformer_layer_spec=get_gpt_layer_local_spec(),
vocab_size=100,
max_sequence_length=64)
return gpt_model
- 创建 数据迭代器
- 加载并保存
分布式检查点,可以灵活地在加载模型时将模型从一个模型并行设置转换为另一个模型并行设置(例如,使用张量并行大小 2 训练的模型,之后可以加载为张量模型并行大小 4 )
from megatron.core import dist_checkpointing
dist_checkpointing.save(sharded_state_dict=sharded_state_dict, checkpoint_dir=checkpoint_path)
checkpoint = dist_checkpointing.load(sharded_state_dict=sharded_state_dict, checkpoint_dir=checkpoint_path)
3. Colossal-AI
pip install colossalai
采用 零冗余优化器ZeRO ,对优化起状态、梯度、模型参数进行切分,仅在显卡中保存当前计算所需的数据。
推理时,还可以将模型卸载到CPU内存或磁盘,减少GPU占用
4. BMTrain
OpenBMB团队研发,BMTrain 是一个高效的大型模型训练工具包,可用于训练具有数百亿个参数的大型模型。
它可以以分布式方式训练模型,同时保持代码像单机训练一样简单
ZeRO 技术分成 3个等级,满足不同场景的需求
ZeRO-1
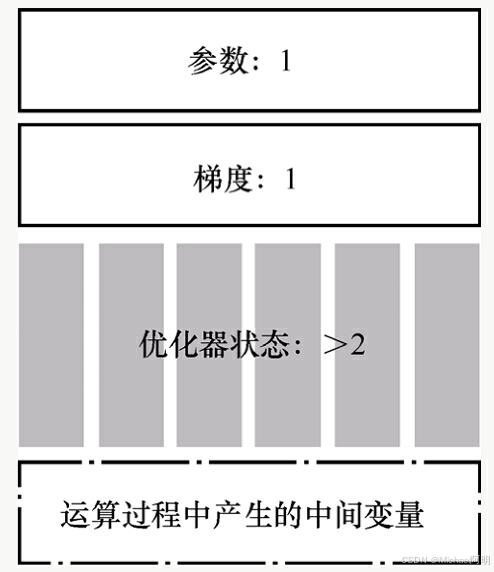
ZeRO-2
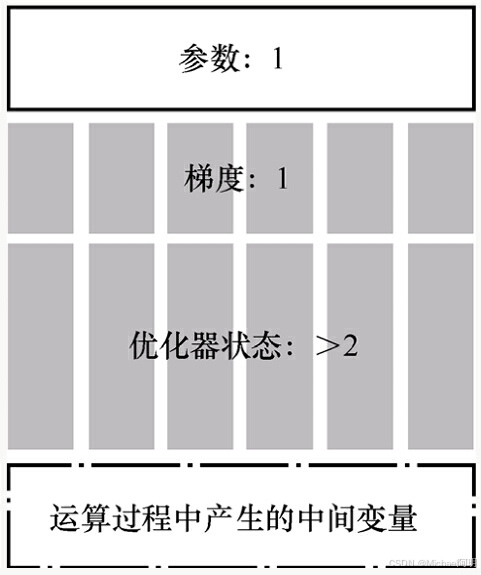
ZeRO-3
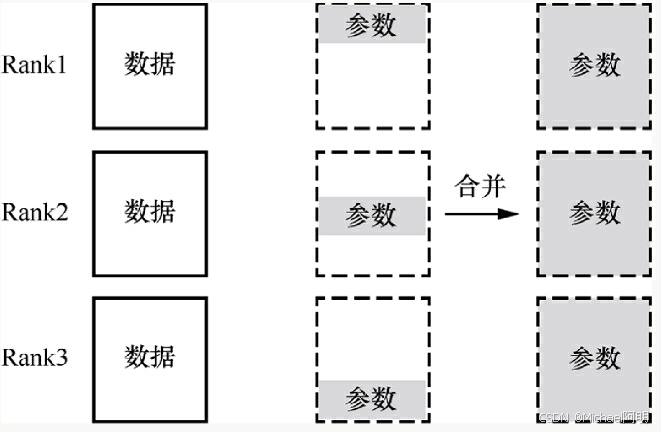
5. 总结
数据并行方法的核心设计思想
将训练数据划分成多个小批次(mini-batches),并将这些批次分配到不同的设备(如GPU)上同时进行并行训练。
- 每个设备都保存完整的模型参数的一个副本
- 不同设备使用不同的数据子集进行前向传播和反向传播
- 在每个训练步骤后,通过梯度同步(如AllReduce)来协调和平均各设备的梯度
- 最终所有设备的模型参数会同步一致的状态
模型并行方法的核心设计思想
将单个神经网络模型的不同层或组件分割并分布到不同的设备上。
- 将模型的不同部分(如层、张量)映射到不同的硬件设备
- 在前向传播和反向传播过程中,数据需要在设备间传输
- 减少单个设备的显存压力,使得可以训练超大规模模型
- 通过精细的划分策略来优化计算和通信效率
流水线并行方法对模型并行的改进
流水线并行在模型并行的基础上做了以下改进
- 将模型的不同层按顺序映射到不同设备上
- 引入了流水线调度机制,使得多个微批次可以同时在不同阶段并行处理
- 减少了设备之间的空闲时间,提高了硬件利用率
- 通过调度来缓解通信开销和同步延迟
- 相比静态的模型并行,流水线并行提供了更动态和高效的并行执行方式
融合CUDA内核
融合CUDA内核是指将多个连续的GPU计算操作合并成一个单一的CUDA内核
- 减少内核启动开销
- 减少显存访问和数据传输
- 提高计算密度和并行效率
- 避免中间临时结果的显存开销
- 通过更紧凑的计算路径提高性能
Optimizer Offload节省显存的方法
- 将优化器状态(如Adam优化器的动量和方差估计)从GPU显存卸载到CPU内存
- 仅在梯度更新时临时将优化器状态加载到GPU
- 避免同时在显存中保存大量优化器参数
- 减少显存峰值使用量
- 使得可以用更少的显存训练更大的模型


















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











