







Eshraghian J K, Ward M, Neftci E O, et al. Training spiking neural networks using lessons from deep learning[J]. Proceedings of the IEEE, 2023.
Training Spiking Neural Networks-反向传播方式
4.训练脉冲神经网络(Training Spiking Neural Networks)
脉冲神经网络 (SNN) 的丰富时间动态使得神经元的发放模式可以有多种解释方式。因此,训练 SNN 也有多种方法。通常可以分为以下几种方法:
- 影子训练 (Shadow Training):先训练一个非脉冲人工神经网络 (ANN),然后通过将激活值解释为发放率或发放时间,将其转换为 SNN。
- 使用脉冲进行反向传播 (Backpropagation using Spikes):SNN 原生地使用误差反向传播进行训练,通常通过时间反向传播,就像对序列模型进行训练一样。
- 局部学习规则 (Local Learning Rules):权重更新是权重空间和时间局部信号的函数,而不是像误差反向传播那样的全局信号。
每种方法都有其适用的时间和场景。在此,我们将重点讨论直接将反向传播应用于 SNN 的方法,但通过探索影子训练和各种局部学习规则,也可以获得有用的见解。
反向传播算法的目标是最小化损失。为了实现这一目标,通过从最后一层到每个权重应用 链式法则 ,计算损失相对于每个可学习参数的梯度。然后使用这个梯度来更新权重,以理想状态下总是减少误差。如果这个梯度为“0”,则不会更新权重。这也是由于脉冲的不可微性,导致使用误差反向传播训练 SNN 的主要障碍之一,这也被称为令人畏惧的 “死神经元”问题 。“梯度消失”和“死神经元”之间存在微妙但重要的区别,这将在第4.3节中解释。
为了更深入地理解脉冲不可微性背后的原因,回顾漏积分发放(Leaky Integrate-and-Fire,LIF)神经元的膜电位离散化解(见方程(4)): U [ t ] = β U [ t − 1 ] + W X [ t ] U[t] = \beta U[t − 1] + WX[t] U[t]=βU[t−1]+WX[t]。其中,第一项代表膜电位 U U U 的衰减,第二项是加权输入 W X WX WX 。为了简化,省略了重置项和下标。
现在,假设对权重 W W W 进行权重更新 Δ W \Delta W ΔW(见方程(4))。这个更新使膜电位发生变化 Δ U \Delta U ΔU ,但这种电位变化未能导致神经元发放行为的进一步变化(见方程(5) S o u t [ t ] = { 1 , if U [ t ] > θ 0 , otherwise ( 5 ) S_{out}[t] = \begin{cases} 1, & \text{if } U[t] > \theta \\ 0, & \text{otherwise} \end{cases} (5) Sout[t]={ 1,0,if U[t]>θotherwise(5)
也就是说,除了在阈值 θ \theta θ 处, d S / d U = 0 dS/dU = 0 dS/dU=0 对所有 U U U 而言, d S / d U → ∞ dS/dU \rightarrow \infty dS/dU→∞。这使得我们真正感兴趣的项,即损失在权重空间中的梯度 d L / d W dL/dW dL/dW ,要么为“0”要么为“∞”。无论哪种情况,通过脉冲神经元进行反向传播时都没有足够的学习信号(见图9(a))。
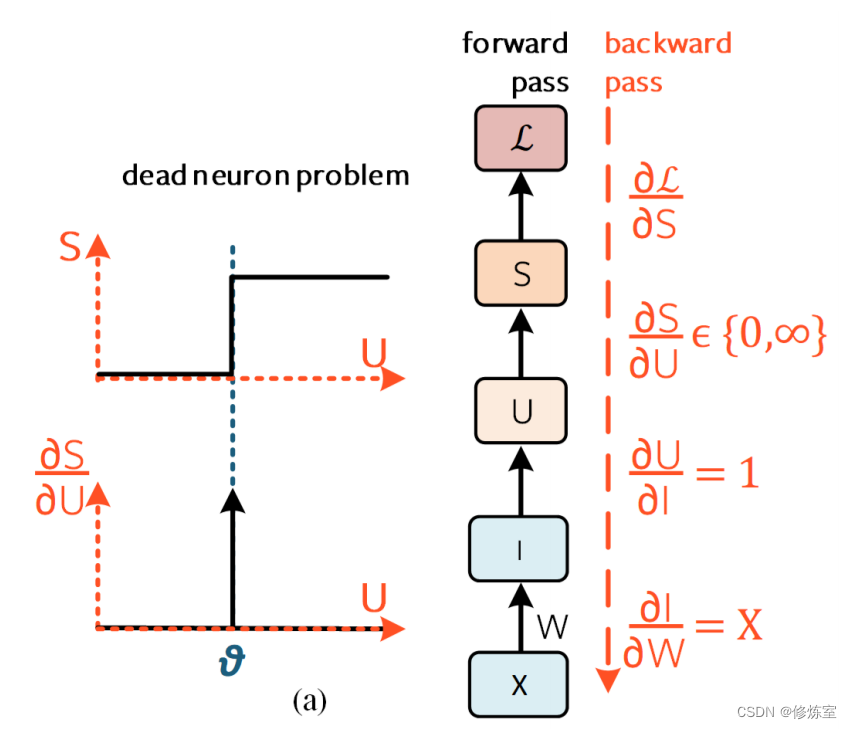
- 膜电位(Membrane Potential,U):神经元膜两侧的电位差。
- 权重更新(Weight Update,( \Delta W )):神经网络训练过程中对连接权重的调整。
- 阈值(Threshold,( \theta )):神经元发放脉冲的电位阈值。
- 梯度(Gradient,( dL/dW )):损失相对于权重的变化率,用于指导权重更新以减少损失。
4.1 影子训练(Shadow Training)
通过影子人工神经网络(Artificial Neural Network,ANN)进行训练并将其转换为脉冲神经网络(Spiking Neural Network,SNN),可以完全规避死神经元问题(见图9(b))。
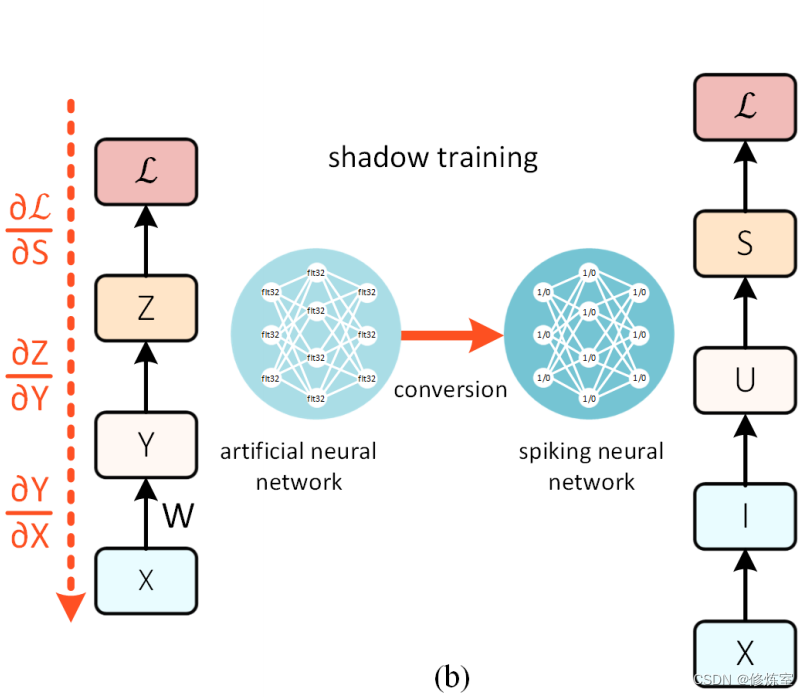
每个神经元的高精度激活函数可以转换为脉冲频率或潜伏期编码(latency code)。使用影子训练的最有力理由之一是,传统深度学习的进步可以直接应用于SNN。因此,对于复杂数据集(如CIFAR-10和ImageNet)的静态图像分类任务,ANN到SNN的转换目前处于领先地位。如果 推理效率 比训练效率更重要,并且输入数据 不是时间变化 的,那么影子训练可能是最优选择。
- 影子人工神经网络(Shadow ANN):在训练过程中使用的传统ANN,其激活函数最终转换为SNN的脉冲编码。
- 脉冲神经网络(SNN):一种神经网络模型,利用离散的脉冲信号(spikes)进行信息传递和处理。
- 死神经元问题(Dead Neuron Problem):在反向传播过程中,某些神经元因为无法发放脉冲而导致梯度为零,从而阻碍学习。
- 脉冲频率(Spike Rate):神经元在一段时间内发放脉冲的频率,用于编码信息。
- 潜伏期编码(Latency Code):根据神经元首次发放脉冲的时间来编码信息。
除了训练过程效率低下外,影子训练方法还有其他几个缺点。
首先,最常用于基准测试的任务类型并未利用SNN的时间动态特性,而将序列神经网络转换为SNN的领域研究还很少。
其次,将高精度激活转换为脉冲通常需要较长的仿真时间步骤,这可能抵消了最初从SNN中寻求的功率和延迟优势。
但真正促使人们放弃ANNs的是转换过程本质上是一种近似。因此,经过影子训练的SNN很难达到原始网络的性能。
- 影子训练方法(Shadow Training Method):通过训练传统人工神经网络(ANN),然后将其转换为脉冲神经网络(SNN)。
- 时间动态特性(Temporal Dynamics):指神经网络在时间维度上的变化和响应能力,SNN能够利用时间动态来处理信息。
- 仿真时间步骤(Simulation Time Steps):在SNN中进行仿真所需的离散时间步骤数量。
- 近似(Approximation):将高精度ANN激活转换为SNN脉冲编码时产生的误差。
对于长时间序列问题,可以通过使用混合方法部分解决:首先使用影子训练的SNN,然后对转换后的SNN进行反向传播。虽然这种方法在CIFAR-10和ImageNet上报告的结果显示精度有所下降,但它能够将所需的步骤数减少一个数量级。有关影子训练技术和挑战的更详细讨论,可以参考[164]。
[164] Michael Pfeiffer and Thomas Pfeil. Deep learning with spiking neurons: Opportunities and challenges. Frontiersin Neuroscience, 12:774, 2018.
- 混合方法(Hybrid Approach):结合影子训练和反向传播的方法,先训练ANN再转换为SNN,并进行进一步的优化训练。
- 反向传播(Backpropagation):通过计算损失函数相对于每个可学习参数的梯度来更新权重的算法。
- 精度(Accuracy):指模型在给定数据集上的预测准确性。
- 步骤数(Number of Steps):训练或仿真过程中所需的离散时间步骤数量。
4.2 反向传播中的脉冲时间(Backpropagation Using Spike Times)
另一种绕过“死神经元问题”的方法是 对脉冲时间求导 。实际上,这是第一个通过反向传播训练多层SNN的方法。SpikeProp的原始方法指出, 虽然脉冲是离散的,但时间是连续的 。因此,求脉冲时间相对于权重的导数可以达到功能性的结果。详细描述见附录C.1。
[124] Sander M Bohte, Joost N Kok, and Han La Poutre. Error-backpropagation in temporally encoded networks of spiking neurons. Neurocomputing, 48(1-4):17–37, 2002.
- 脉冲时间(Spike Times):指神经元发出脉冲的时间点。
- SpikeProp:一种通过脉冲时间导数进行反向传播的方法。
- 连续时间(Continuous Time):尽管脉冲是离散事件,但时间是连续变化的。
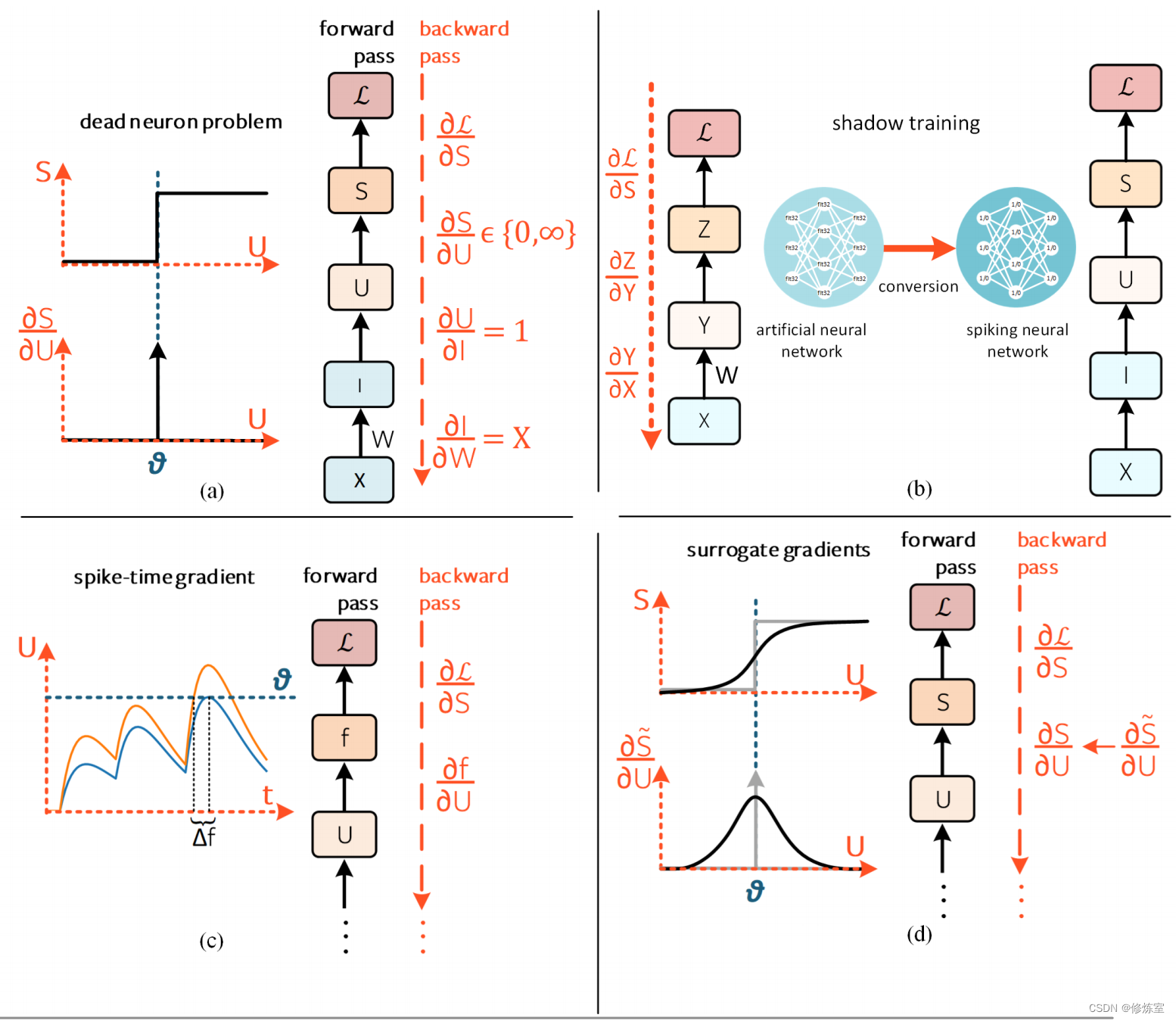
图9:解决死神经元问题
仅显示一个时间步,为简单起见,省略了图6中的时间连接和下标。
(a) 死神经元问题: ∂ S / ∂ U ∈ { 0 , ∞ } \partial S/\partial U \in \{0, ∞\} ∂S/∂U∈{ 0,∞} 的解析解导致梯度无法进行学习。
(b) 阴影训练:首先训练一个非脉冲神经网络,然后转换为SNN。
(c) 脉冲时间梯度:取脉冲时间 f f f 的梯度,而不是脉冲生成机制的梯度,只要脉冲必然发生,这就是一个连续函数。
(d) 代理梯度(Surrogate gradients):在反向传播过程中将脉冲生成函数近似为连续函数[123]。左箭头(←)表示函数替代。这是解决死神经元问题的最广泛采用的解决方案。
直觉上,SpikeProp 计算了误差相对于脉冲时间的梯度。对权重的变化 ∆ W ∆W ∆W 导致了膜电位的变化 ∆ U ∆U ∆U ,最终导致了脉冲时刻的变化 ∆ f ∆f ∆f,其中 f f f 是神经元的发放时刻。实质上,不可微分的项 ∂ S / ∂ U ∂S/∂U ∂S/∂U 已经被 ∂ f / ∂ U ∂f /∂U ∂f/∂U 替代。这也意味着 每个神经元必须发出一个脉冲才能计算出梯度 。这种方法在图 9© 中有所说明。SpikeProp 的扩展使其与多个脉冲兼容,在一些数据驱动任务上表现出色,其中一些任务已经超越了人类在 MNIST 和 N-MNIST 上的表现水平。
存在几个缺点。一旦神经元变得不活跃,它们的权重就会被冻结。在大多数情况下,如果没有发生脉冲,就不存在求解 梯度的闭式解 [169]。SpikeProp 通过修改参数初始化(即 增加权重直到触发脉冲 )来解决这个问题。但自从 SpikeProp 于 2002 年问世以来,深度学习社区对权重初始化的理解逐渐成熟。我们现在知道, 初始化的目标是在层之间设置恒定的激活方差 ,缺乏这一点会导致梯度在空间和时间上消失和爆炸。修改权重以促进发生脉冲可能会削弱(detract)这一点。相反,克服缺乏发放的更有效方法是降低神经元的发放阈值。人们可以考虑应用活动正则化来鼓励隐藏层中的发放,尽管这在脉冲时进行导数运算时会降低分类准确性。这个结果并不令人意外,因为正则化只能在脉冲时应用,而不能在神经元静默时应用。
另一个挑战是,它对网络施加了严格的先验条件(例如,每个神经元只能发放一次),这与动态变化的输入数据不兼容。可以通过使用周期性的时间编码来解决这个问题,在给定的间隔内刷新,类似于视觉扫视可能设置参考时间的方式。但这是唯一一种在多层脉冲神经网络中能够计算出无偏梯度的方法,而不需要任何近似。这种精度是否必要,需要在更广泛范围的任务上进一步探讨。
实用提示:脉冲时间的梯度(Gradients at Spike Times)
尽管这种方法仍在广泛研究中,但由于在优化损失函数方面表现不佳,已被反向传播通过时间使用替代梯度下降的方法所取代。为什么会这样呢?我们最好的猜测是性能较差是因为通过的边(edges)较少,使得学分(credit)分配更具挑战性。有关替代梯度下降的更多细节请参见下一节。
4.3 使用脉冲进行反向传播( Backpropagation Using Spikes)
过去几年中,最常采用的方法不是计算相对于脉冲时间的梯度,而是将广义反向传播算法应用于展开的计算图(图 6(b)),即通过时间的反向传播(BPTT)。
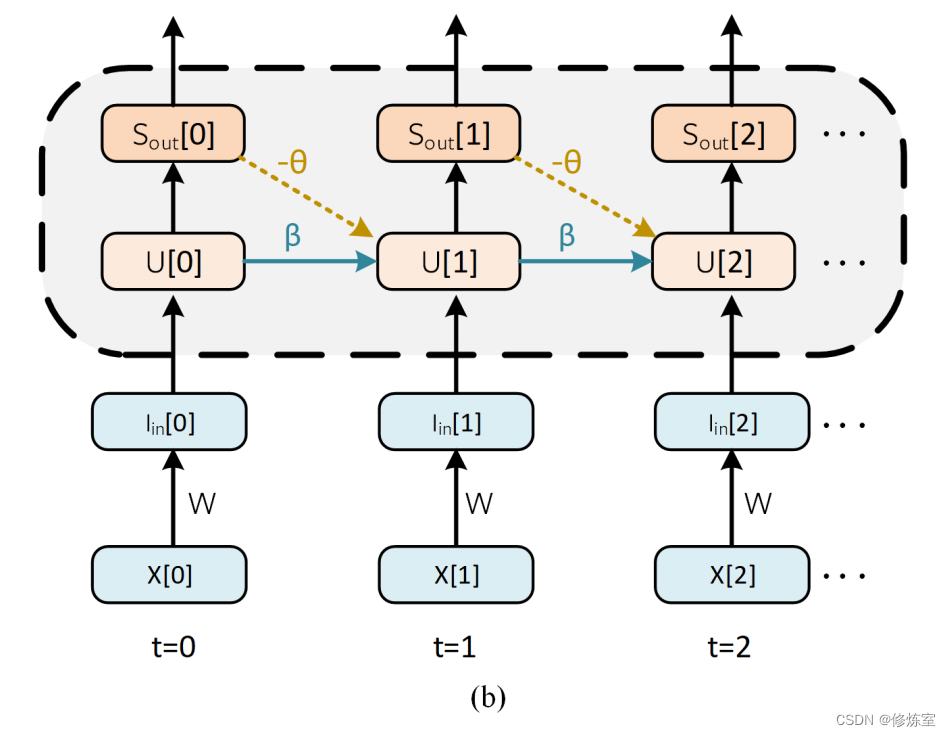
从网络的最终输出开始向后工作,梯度从损失传播到所有后代。通过这种方式,通过 SNN 计算梯度基本上与通过链式法则的迭代应用来计算 RNN 的梯度相同。图 10(a) 描述了梯度 ∂ L / ∂ W ∂L/∂W ∂L/∂W 从父节点 (L) 到其叶节点 (W) 的各个路径。
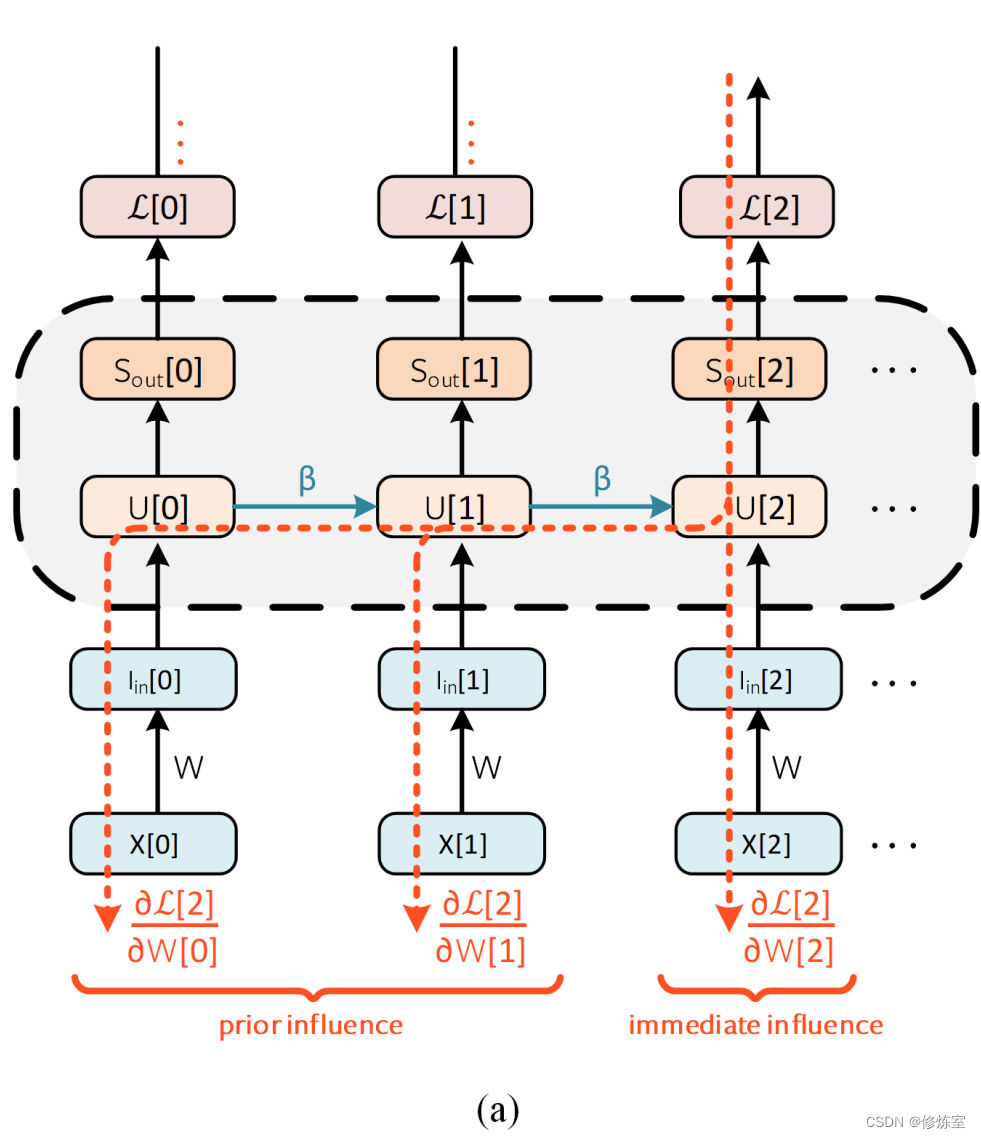
图10通过时间的反向传播。
(a) W W W 的当前时间应用称为即时影响, W W W 的历史应用称为先前影响。出于简洁起见,重置动态和显式循环已被省略。通过 L [ 0 ] L[0] L[0] 和 L [ 1 ] L[1] L[1] 的错误路径也被隐藏起来,但遵循与 L[2] 相同的思路。
相比之下,仅使用脉冲时间进行反向传播时,只有当神经元发放时才会遵循梯度路径,而这种方法则无论神经元是否发放都会遵循每条路径。最终损失是瞬时损失 ∑ t L [ t ] \sum_{t} \mathcal{L}[t] ∑tL[t] 的总和,尽管损失计算可以采用第 3.3 节中描述的各种其他形式。
找到总损失相对于参数的导数允许使用梯度下降来训练网络,因此目标是找到 ∂ L / ∂ W ∂L/∂W ∂L/∂W。参数 W W W 在每个时间步都被应用,特定步骤上的权重应用被表示为 W [ s ] W[s] W[s] 。假设可以在每个时间步计算瞬时损失 L [ t ] L[t] L[t](要注意的是,某些目标函数,如均方脉冲率损失(第 3.3.1 节),必须等到序列结束才能累积所有脉冲并生成损失)。由于前向传播需要通过有向无环图移动数据,每次权重的应用只会影响当前和未来的损失。
在图 10(a) 中, W [ s ] W[s] W[s] 对 L [ t ] L[t] L[t] 在 s = t s = t s=t 的影响被标记为即时影响。对于 s < t s < t s<t,我们将 W [ s ] W[s] W[s] 对 L [ t ] L[t] L[t] 的影响称为先前影响。所有参数应用对当前和未来损失的影响被总结在一起定义全局梯度:
∂ L ∂ W = ∑ t ∂ L [ t ] ∂ W = ∑ t ∑ s ≤ t ∂ L [ t ] ∂ W [ s ] ∂ W [ s ] ∂ W ( 6 ) \frac{\partial \mathcal{L}}{\partial W}=\sum_{t} \frac{\partial \mathcal{L}[t]}{\partial W}=\sum_{t} \sum_{s \leq t} \frac{\partial \mathcal{L}[t]}{\partial W[s]} \frac{\partial W[s]}{\partial W} (6) ∂W∂L=t∑∂W∂L[t]=t∑s≤t∑∂W[s]∂L[t]∂W∂W[s](6)
一个循环系统将会限制权重在所有步骤上是共享的: W [ 0 ] = W [ 1 ] = ⋅ ⋅ ⋅ = W W[0] = W[1] = · · · = W W[0]=W[1]=⋅⋅⋅=W。因此, W [ s ] W[s] W[s] 的变化将对所有其他 W W W 的值产生等效影响,这表明 ∂ W [ s ] / ∂ W = 1 ∂W[s]/∂W = 1 ∂W[s]/∂W=1,方程 (6) 简化为:
∂ L ∂ W = ∑ t ∑ s ≤ t ∂ L [ t ] ∂ W [ s ] ( 7 ) \frac{\partial \mathcal{L}}{\partial W}=\sum_{t} \sum_{s \leq t} \frac{\partial \mathcal{L}[t]}{\partial W[s]} (7) ∂W∂L=t∑s≤t∑∂W[s]∂L[t](7)
实用提示:我需要记住所有这些才能使用 SNN 吗?
幸运的是,梯度很少需要手动计算,因为大多数深度学习包都带有自动微分引擎。使用 SNN 并不需要对其内部结构有深入了解。但要推进 SNN 研究,当然需要这些知识!
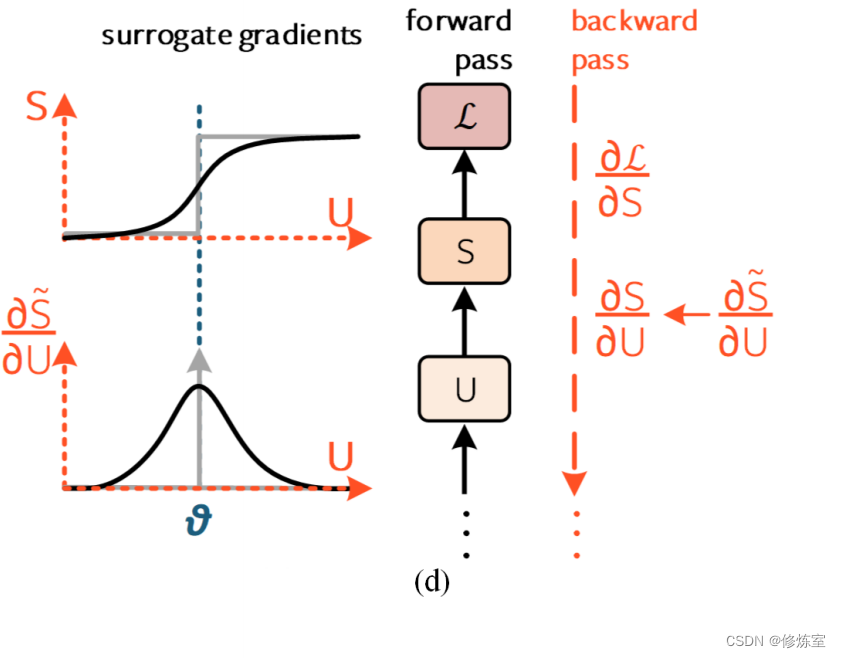
在图 9(d) 中隔离单个时间步的即时影响时,我们会发现 脉冲不可微性 问题出现在 ∂ S / ∂ U ∈ { 0 , ∞ } ∂S/∂U ∈ \{0, ∞ \} ∂S/∂U∈{ 0,∞} 项中。对膜电位进行阈值操作在功能上等同于应用一个移位的 Heaviside 算子,而这是不可微的。
解决方案其实很简单。在前向传播过程中,像往常一样对 U [ t ] U[t] U[t] 应用 Heaviside 算子以确定神经元是否发放脉冲。但在反向传播过程中,用连续函数 S ˜ S˜ S˜(例如 sigmoid)替换 Heaviside 算子。使用连续函数的导数作为替代 ∂ S / ∂ U ← ∂ S / ∂ U ˜ ∂S/∂U ← ∂S/∂U˜ ∂S/∂U←∂S/∂U˜,这被称为代理梯度方法(图 9(d))。
4.3.1 代理梯度
代理梯度的一个主要优点是它们有助于克服死神经元问题。为了更具体地说明死神经元问题,可以考虑一个具有阈值 θ 的神经元,并且以下情况之一发生:
- 膜电位低于阈值:U < θ
- 膜电位高于阈值:U > θ
- 膜电位正好达到阈值:U = θ
在案例 1 中,没有脉冲被引发,导数为 ∂ S / ∂ U U < θ = 0 \partial S / \partial U_{U < \theta} = 0 ∂S/∂UU<θ=0 。在案例 2 中,一个脉冲会发放,但导数仍为 ∂ S / ∂ U U > θ = 0 \partial S / \partial U_{U > \theta} = 0 ∂S/∂UU>θ=0 。将这两者中的任何一个应用到图 9(a) 中的方程链中都会使 ∂ L / ∂ W = 0 \partial L / \partial W = 0 ∂L/∂
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1584
1584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









