







参考:
《这就是神经网络 5:轻量化神经网络--MobileNet V1、MobileNet V2、ShuffleNet V1、ShuffleNet V2》






附录一
Depthwise(DW)卷积与Pointwise(PW)卷积,合起来被称作Depthwise Separable Convolution(参见Google的Xception),该结构和常规卷积操作类似,可用来提取特征,但相比于常规卷积操作,其参数量和运算成本较低。所以在一些轻量级网络中会碰到这种结构如MobileNet。
常规卷积操作
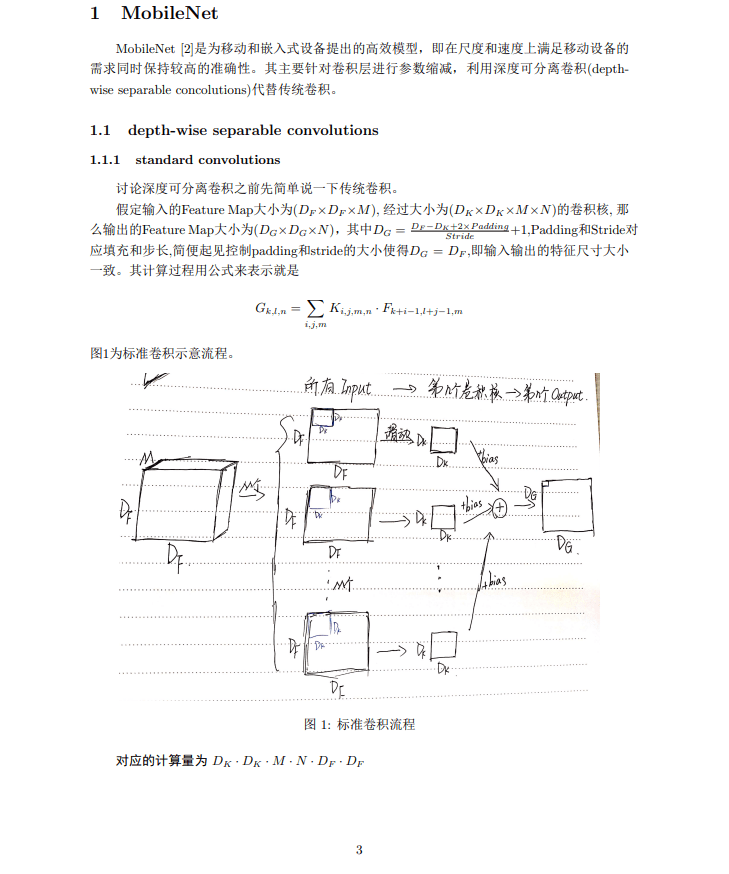
对于一张5×5像素、三通道彩色输入图片(shape为5×5×3)。经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4),最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),如果没有则为尺寸变为3×3。
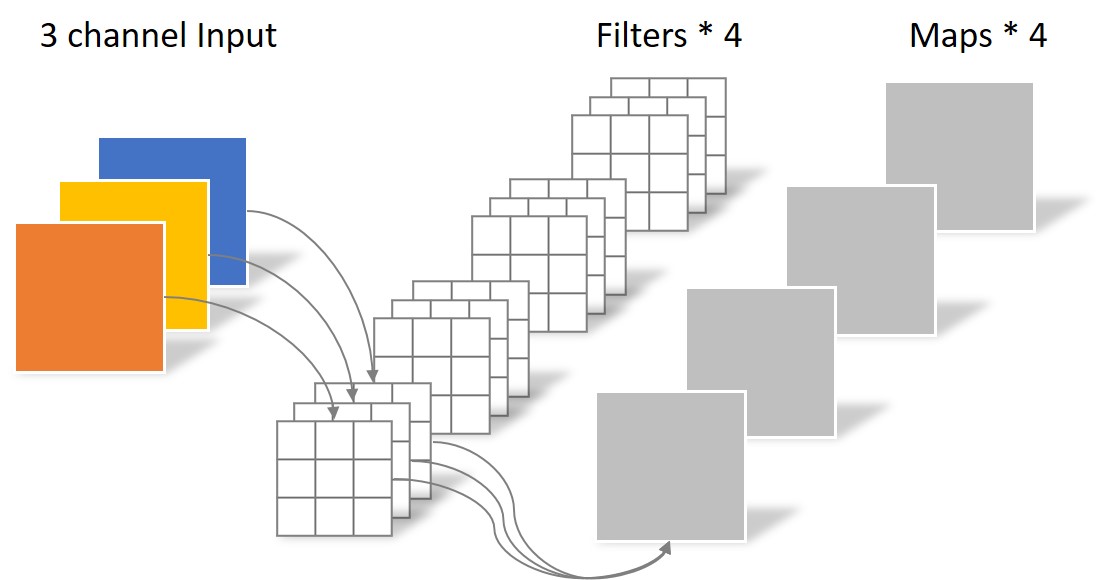
此时,卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:
N_std = 4 × 3 × 3 × 3 = 108
Depthwise Separable Convolution
Separable Convolution在Google的Xception以及MobileNet论文中均有描述。它的核心思想是将一个完整的卷积运算分解为两步进行,分别为Depthwise Convolution与Pointwise Convolution。
(1) Depthwise Convolution
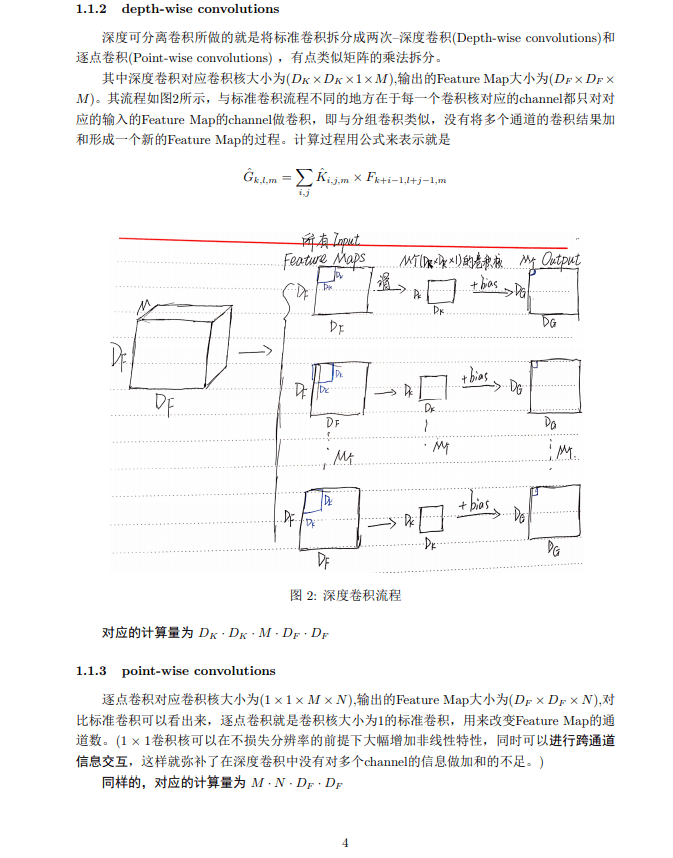
不同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。上面所提到的常规卷积每个卷积核是同时操作输入图片的每个通道。
同样是对于一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,不同于上面的常规卷积,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
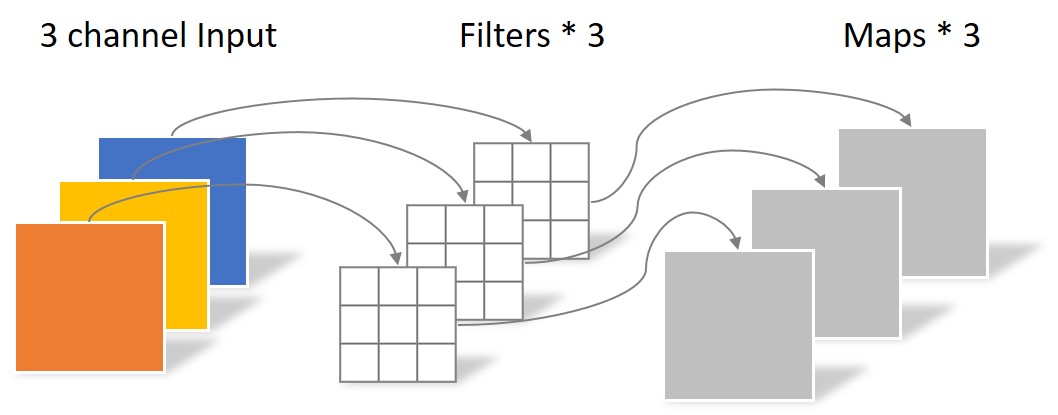
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:
N_depthwise = 3 × 3 × 3 = 27(2) Pointwise Convolution
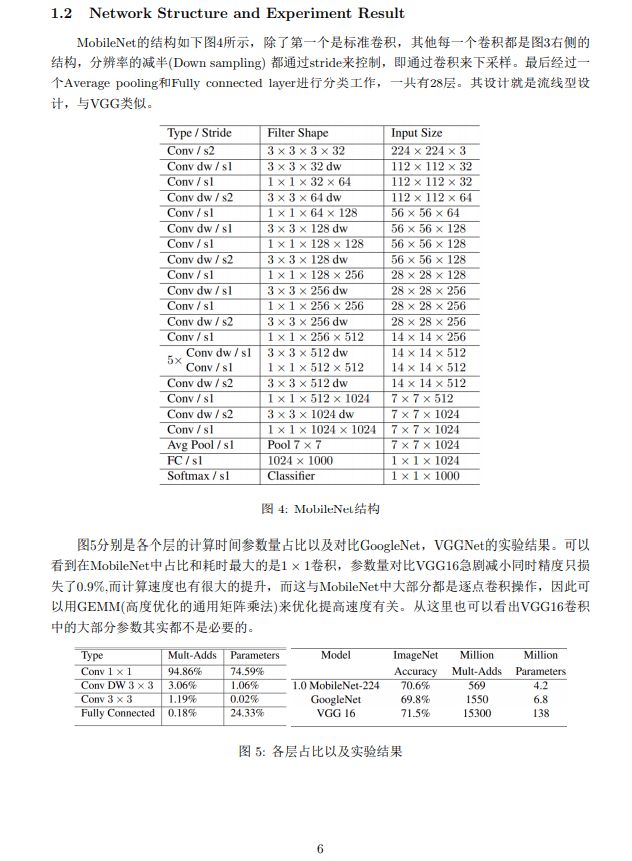
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。如下图所示。
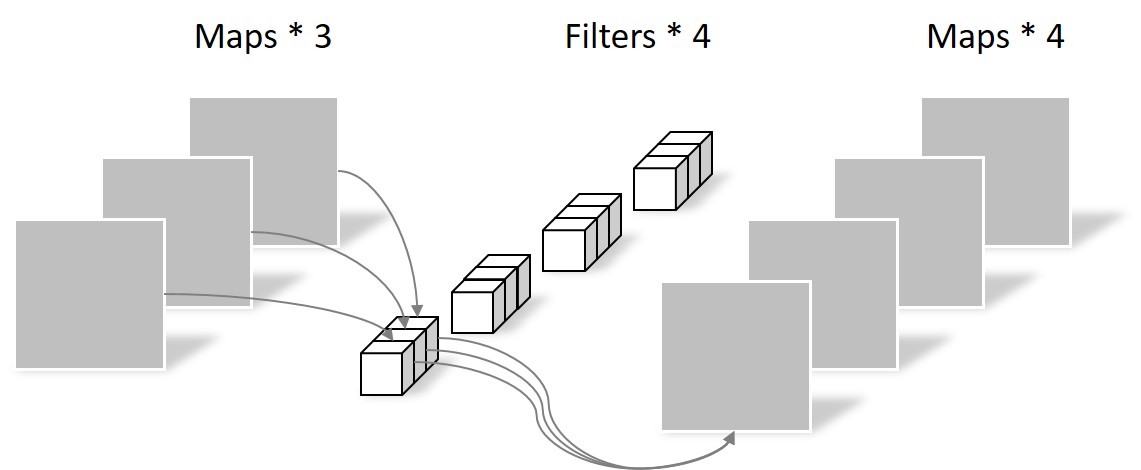
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
N_pointwise = 1 × 1 × 3 × 4 = 12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同。
附录二
常见问题
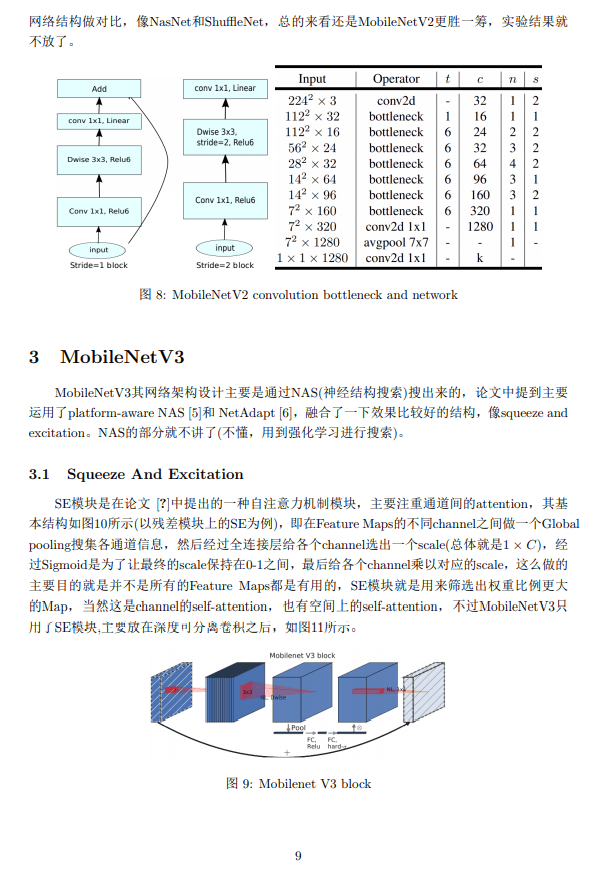
一、MobileV2与V1的区别
下图是MobileNetV2与MobileNetV1的区别(原图链接):

主要区别有两点:
(1)Depth-wise convolution之前多了一个1*1的“扩张”层,目的是为了提升通道数,获得更多特征;
(2)最后不采用Relu,而是Linear,目的是防止Relu破坏特征。
二、MobileNet V3相对于V2进行了何种改进
MobileNet v3 是谷歌大脑提出的一篇模型结构搜索的文章,它的前身是MNASNet,然后通过在MNASNet基础上的进一步优化实现的。MobileNet v3的设计初衷和MNASNet相同:通过AutoML技术搜索出一个即快又准的网络架构。MobileNet v3的主要贡献有3点:
- 使用Platform-Aware NAS得到网络的初始结构;
- 使用NetAdapt [3]对网络的部分层进行局部优化;
- 对网络中的耗时的结构进行重新设计;
- 设计了一组更快的激活函数。
另外,作者基于MobileNet v3和R-ASPP设计了一个又快又准的场景分割网络LR-ASPP。
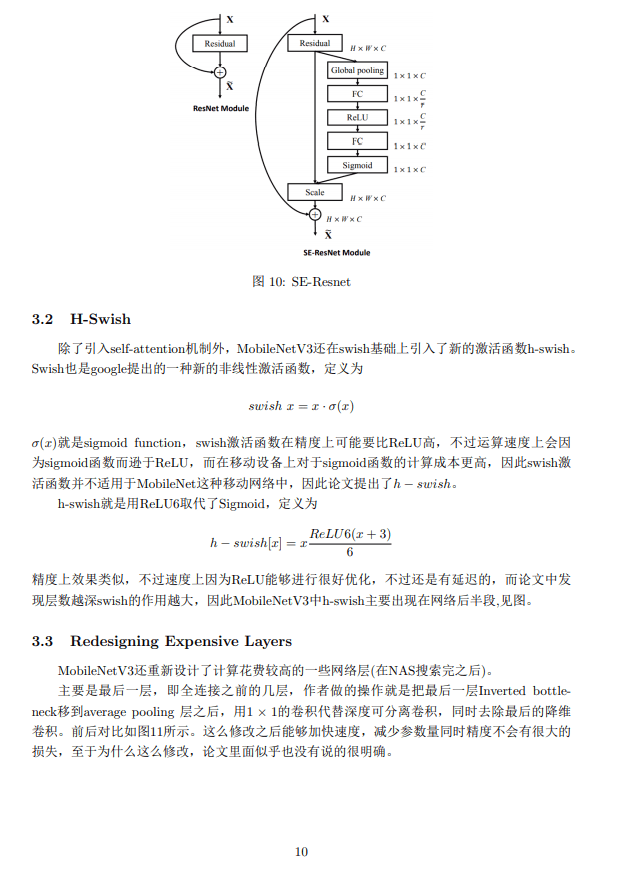
MobileNet v3参考的网络结构有三个,它们分别是MobileNet v1,MobileNet v2和MNASNet。MobileNet v1的提出的模块是深度可分离卷积网络(depthwise separable convolutions),深度可分离卷积网络由按通道的3x3卷积(深度卷积)和跨通道的1x1卷积(点卷积)组成。MobileNet v2提出的模块是线性瓶颈的逆残差结构(inverted residual with linear bottleneck),如图1所示。MNASNet则是在MobileNet v2的基础上加入了SENet中提出的Squeeze-and-Excitation模块。在残差结构使用了不同的结合方式,其中SENet将Squeeze-and-Excitation模块放在了残差模块之后,而MNASNet则是将这个模块放在了残差模块中间,如图2所示。

图1:MobileNet v2的线性瓶颈的逆残差结构

图2:MobileNet v3的结构,它将SE模块放在了残差内部















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











