








这个文章获得了2018ECCV best paper 提名,感觉在表情GAN里面很666~
Abstract
摘要里大概提到了几点:
1.StarGAN生成的表情状态有限,本文通过结合Action Units(AU)的条件GAN解决问题
2.通过控制AU的激活程度来控制表情
3.无监督学习,类似CycleGAN的网络结构
4.使用Attention机制来缓解背景和光照的影响
Introduction
StarGAN在离散标签数据集RaFD上生成的结果,在表情表达状态上不够丰富,而通过AU组合来丰富表情种类,30个AU组合成7000多个不同组合,但是带AU的数据相对较少。
本文通过控制AU的激活状态实现连续表情变化的生成,不需要landmarks,(Tip. FG有一篇paper是通过单图和landmarks来生成连续帧的)
而AU的表示可以这么理解:

医学上会把人脸肌肉分为不同的区域,那么人脸做出表情的时候,某些区域会有不同程度的变化,比如说左边这个图,这个惊恐的表情,有这些部位会有不同程度的运动。这个数据集就是记录了人脸做各种表情的时候各个区域的变化程度。一般的表情数据集的label都是说这个人脸是什么表情,那这个数据集的label不是离散的各种表情的定义,而是用向量来表示各个区域不同程度的表情变化。通过调节表情向量就可以使这篇文章的模型输出不同程度的表情。这个向量就长下面这个样子,向量长度为N,表示脸部N个区域,每个值的范围从0到1.表示运动程度。
![]()
而Attention机制很好地应对 complex backgrounds and illumination conditions,这也使得在wild下的生成效果更好。
Related Work
Generative Adversarial Networks.
代替JS loss 的 continuous Earth Mover Distance metric
出处:
Arjovsky, M., Chintala, S., Bottou, L.: Wasserstein GAN. arXiv preprint
arXiv:1701.07875 (2017)
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., Courville, A.C.: Improved
training of wasserstein GANs. In: NIPS (2017)
Conditional GANs
incorporate conditions and constraints into the generation process
Unpaired Image-to-Image Translation
类似CycleGAN, DiscoGAN and StarGAN的结构来保留关键属性
Face Image Manipulation
mass-and-spring models:无法生成细微表情变化
2D and 3D morphings:无法应对光照变化
本文将皮肤和肌肉模型引入深度学习机制
Problem Formulation

学习原图Iyr到生成图Iyg 的映射M,通过将原图和AU状态结合实现目标表情的生成。
Our Approach
整个网络结构简化结构可以分为三部分:

第一个G是将原图和目标边表情结合生成目标图

这里有两个分支,一个分支通过Attention机制生成Attention mask,另一个分支生成Color mask,二者通过下列公式结合成目标图

最后还有一个判别器D,判别器的输入是第一个生成器的输出图像,判别器的输出有两个,一个是对图像提取表情,还有一个是对图像提取特征,这两个都是用于判断生成图像和生成的表情的质量,计算损失。
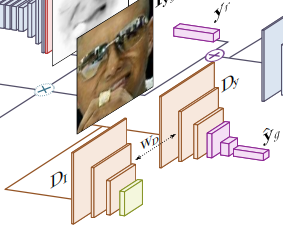
还有一个生成器G,他的输入是之前的生成器的输出图像以及一个目标表情,这次的目标表情是之前生成器的输入图像的表情,就是原始图像的表情向量,这个生成器的作用就是看生成器能否恢复出原始图像。因此,这个网络是无监督训练的。

Learning the Model
Image Adversarial Loss
这个损失是从WGAN改过来的,因为原始的GAN用JS散度很难训练,很容易梯度消失或者梯度爆炸。现在这个损失的意义就是最大化生成图像通过判别器得到的结果,最小化原始图像通过判别器得到的结果,另外再加入一个梯度惩罚项,让梯度控制在一定范围里。
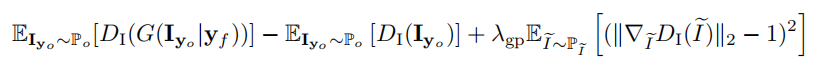
Attention Loss
因为数据集没有注意力掩膜的groundtruth,注意力掩膜就很容易过饱和,就是所有值趋向于1。注意力损失的第一项是全差分损失,全差分损失本来是用于图像的平滑,第二项是一个L2的惩罚项
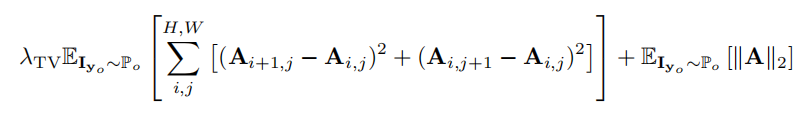
Conditional Expression Loss
表情的损失,就是分别把原始图像和生成图像输入判别器,分别得到的表情和表情向量的groundtruth计算损失。
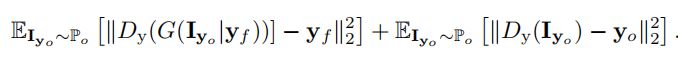
Identity Loss
身份损失,就是强迫第二个生成器的输出和原始图像更接近。保证生成的人脸和原始图像是同一个人
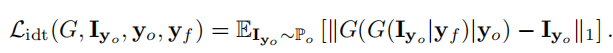
Experimental Evaluation
Single Action Units Edition:
第一组实验是只让目标表情向量中的某一项有四种强度的变化,其余项保持不变
Simultaneous Edition of Multiple AUs:
第二组实验是同时修改表情向量中的若干项,以及变化程度的参数,就可以得到一组线性插值的连续的表情变化。
Discrete Emotions Editing:
第三组实验是离散表情的生成,以及和其他方法的对比。本文和其他方法最大的不同是注意力掩膜,注意力掩膜可以避免生成器对人脸以外的区域投入太多的关注,更大程度上是对人脸区域的变化,保证了图像的完整和高分辨率。
High Expressions Variability:
第四组实验是说明根据表情向量可以对输入图像做各种极端表情的生成。
Images in the Wild:
最后一组实验说明了借助注意力掩膜,只关注人脸区域的表情变化,可以避免对人脸以外背景区域的修改,就可以很好地适应直接在图像中对表情修改,不需要其他的后处理。
本文参考:















 1568
1568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









