







http://blog.csdn.net/wdzxl198/article/details/9102759/
https://wenku.baidu.com/view/307075fef18583d048645933.html
http://www.cnblogs.com/520zijuan/archive/2013/02/18/2913074.html
http://blog.csdn.net/huangkangying/article/details/50775278
1.什么是引用,声明和使用引用要注意哪些问题?
2.将引用作为函数返回值类型的格式,好处和需要遵守的规则?
3.什么时候需要用引用
4.下面关于“联合”的题目的输出?
题目1:

1 union 2 { 3 int i; 4 char x[2]; 5 }a; 6 7 a.x[0] =10; 8 a.x[1] =1; 9 printf("%d",a.i);
答案:266 (低位低地址,高位高地址,内存占用情况是Ox010A)
解答:union是共享内存的数据类型,其内存大小以union中size最大的为准,这里是4个字节(在32位机子中,int占4个字节,而char占1个字节,x就占2个字节)。内存占用情况是:0x010A,因为低位低地址,高位高地址,组合起来就是了(为什么a.x[0]是0A?因为char占1个字节,用16进制表示就是2位)。当使用
printf打印a.i的值时,尽管这里没有对a.i赋值,但是由于是union类型,它们都占用相同的内存,所以a.i是有值的,取法就是:从低位开始,根据a.i占用的字节大小截断取值。这里a.i占用4个字节,而a.x却是2个字节,所以就全部取走,即a.i的值为0x010A。如果我们将char x[2]改为char x[5],如下:
1 union 2 { 3 int i; 4 char x[5]; 5 }a; 6 7 a.x[0] = 0x00; 8 a.x[1] = 0x01; 9 a.x[2] = 0x02; 10 a.x[3] = 0x03; 11 a.x[4] = 0x04; 12 13 cout << a.i << endl; 14 cout << 0x03020100 << endl; // a.i的值 15 cout << 0x0403020100 << endl; //当前a的内存占用情况
此时a.i就只会截取前面4个字节的值,即0x03020100,而不是全部的内存中的值0x0403020100。
关于union一些高级的用法可以看看这篇文章:c++中union的使用,看高手们如何解释的
题目2:
1 union 2 { 3 int i; 4 struct 5 { 6 char first; 7 char second; 8 }half; 9 }number; 10 11 number.i=0x4241; /*联合成员赋值*/ 12 printf("%c%c\n", number.half.first, number.half.second); 13 number.half.first='a'; /*联合中结构成员赋值*/ 14 number.half.second='b'; 15 printf("%x\n",number.i);
答案: AB (0x41对应'A',是低位;Ox42对应'B',是高位)
6261 (number.i和number.half共用一块地址空间,'a'对应的ASSII码为61)
实现部分库函数
4.1 已知strcpy的函数原型:char *strcpy(char *strDest, const char *strSrc),其中strDest 是目的字符串,strSrc 是源字符串。不调用C++/C 的字符串库函数,请编写函数 strcpy、strlen、strcat。
#include"stdafx.h"
#include<cassert>
char* strcpy(char* strDest, const char* strSrc)
{
if ((strDest == NULL || strSrc == NULL))
throw"Invaild argument(s)";
char * strDestCopy = strDest;
while ((*strDest++ = *strSrc++) != '\0');
return strDestCopy;
}
int strlen(const char* str)
{
//assert()函数:如果参数为0,则终止程序
assert(str);
int len = 0;
while (*str++)
{
len++;
}
return len;
}
char* strcat(char* strDest, const char* strSrc)
{
assert(strDest && strSrc);
char * pd = strDest;
//若使用while(*Dest++),则会出错,指向'\0'之后,会出现dest++,则指向了个'\0'的下一个位置,
while (*pd!='\0')
pd++;
while ((*pd++ = *strSrc++)!='\0');
return strDest;
}
void main()
{
char str1[25] = "adwadad";
char str2[13] = "XX is best!!";
//strcpy(str1, str2);
strcat(str1, str2);
printf("%s", str1);
} 错误的做法:
[1]
(A)不检查指针的有效性,说明答题者不注重代码的健壮性。
(B)检查指针的有效性时使用((!strDest)||(!strSrc))或(!(strDest&&strSrc)),说明答题者对C语言中类型的隐式转换没有深刻认识。在本例中char *转换为bool即是类型隐式转换,这种功能虽然灵活,但更多的是导致出错概率增大和维护成本升高。所以C++专门增加了bool、true、false三个关键字以提供更安全的条件表达式。
(C)检查指针的有效性时使用((strDest==0)||(strSrc==0)),说明答题者不知道使用常量的好处。直接使用字面常量(如本例中的0)会减少程序的可维护性。0虽然简单,但程序中可能出现很多处对指针的检查,万一出现笔误,编译器不能发现,生成的程序内含逻辑错误,很难排除。而使用NULL代替0,如果出现拼写错误,编译器就会检查出来。
[2]
(A)return new string("Invalid argument(s)";,说明答题者根本不知道返回值的用途,并且他对内存泄漏也没有警惕心。从函数中返回函数体内分配的内存是十分危险的做法,他把释放内存的义务抛给不知情的调用者,绝大多数情况下,调用者不会释放内存,这导致内存泄漏。
(B)return 0;,说明答题者没有掌握异常机制。调用者有可能忘记检查返回值,调用者还可能无法检查返回值(见后面的链式表达式)。妄想让返回值肩负返回正确值和异常值的双重功能,其结果往往是两种功能都失效。应该以抛出异常来代替返回值,这样可以减轻调用者的负担、使错误不会被忽略、增强程序的可维护性。
[3]
(A)忘记保存原始的strDest值,说明答题者逻辑思维不严密。
[4]
(A)循环写成while (*strDest++=*strSrc++);,同[1](B)。
(B)循环写成while (*strSrc!='\0') *strDest++=*strSrc++;,说明答题者对边界条件的检查不力。循环体结束后,strDest字符串的末尾没有正确地加上'\0'。
2.返回strDest的原始值使函数能够支持链式表达式,增加了函数的“附加值”。同样功能的函数,如果能合理地提高的可用性,自然就更加理想。
链式表达式的形式如:
int iLength=strlen(strcpy(strA,strB));
又如:
char * strA=strcpy(new char[10],strB);
返回strSrc的原始值是错误的。其一,源字符串肯定是已知的,返回它没有意义。其二,不能支持形如第二例的表达式。其三,为了保护源字符串,形参用const限定strSrc所指的内容,把const char *作为char *返回,类型不符,编译报错。
5.定义String对象,并实现成员函数:
#include "stdafx.h"
#include <cstring>
class String
{
public:
String(const char *str = nullptr);// 通用构造函数
String(const String &another); // 拷贝构造函数
~String(); // 析构函数
String& operator= (const String &rhs); // 赋值函数
private:
char* m_data; // 用于保存字符串
};
String::String(const char* str)
{
if (str)
{
m_data = strcpy(new char[strlen(str) + 1], str);
}
else
{
m_data = new char;
m_data = '\0';
}
}
String::String(const String &another)
{
m_data = strcpy(new char[strlen(another.m_data) + 1], another.m_data);
}
String::~String()
{
delete[] this->m_data;
}
String& String::operator=(const String & ob)
{
if (this != &ob)
{
delete[] this->m_data;
m_data = strcpy(new char[strlen(ob.m_data)+1], ob.m_data);
}
return *this;
}6.如何判断一段程序是由C 编译程序还是由C++编译程序编译的?
1 #ifdef __cplusplus 2 cout << "cplusplus" << endl; 3 #else 4 cout << "c" << endl; 5 #endif
6.智能指针:
类中有指针成员时,有两种方法管理指针成员:1.值型的方式管理
7.智能指针:使用引用计数,将计数器与类指向的对象相关联,(赋值)引用则加一,(析构)反之减一,为0则删除。
8.继承:实现继承、接口继承、可视继承
9.为什么基类的析构函数是虚函数?
因为派生类的指针可以安全地转化为基类的指针,所以删除一个指针时调用的是基类的析构函数而不是派生 类的,
所以要重写基类的析构函数来释放资源
10.还不知道对象的准确类型,所以不能调用虚函数,所以构造函数不能是虚函数
11.虚函数不能滥用:因为虚函数对象需要维护虚函数表,形成系统开销,故不宜滥用
12.受保护的继承:基类成员只能被直接派生类访问,派生类 的子类不可以访问
13.私有继承:基类中的成员不可以被派生类访问
14.公有继承时,受保护的成员可由派生类访问,但不可以修改。
15.const成员和引用成员只可以用构造函数初始化列表,但是不可以赋值初始化。
16.虚指针是虚函数的实现细节,带有虚函数的每一个对象都有指向该函数的虚函数表
17.c++如何阻止一个类被实例化?
将类定义为抽象类或者将构造函数声明为私有的
18.什么时候将构造函数声明为私有的?
不允许在类的外部创建类的对象,只允许在类内部创建类的对象时
19.如何编写Sockt套接字
服务端:先调用socket创建一个套接字...
客户端:先调用socket创建一个套接字...
调用函数时进行参数压栈,一般从右边往左边进行压栈
20.经常要操作的内存分为哪几个类别:(5)
21.堆和栈的区别(3)
1.申请方式
2地址扩展、内存大小
3.速度快慢、产生碎片
22.类使用static成员的优点?(3)
1.static成员的名字是在类的作用域中,因此可以避免与其他类或全局对象名字冲突
2.可以实施封装,static成员可以是私有的,而全局对象不可以,
3.static成员与特定类关联,可清晰地显示程序员的意图
23.**static数据成员与static成员函数?
42题
24.static关键字的作用?
静态存储、内部连接(两种情况)
各种排序算法:
TCP和UDP的区别以及应用有什么不同?
答:TCP与UDP的区别
TCP---传输控制协议,提供的是面向连接、可靠的字节流服务。当客户和服务器彼此交换数据前,必须先在双方之间建立一个TCP连接,之后才能传输数据。TCP提供超时重发,丢弃重复数据,检验数据,流量控制等功能,保证数据能从一端传到另一端。
UDP---用户数据报协议,是一个简单的面向数据报的运输层协议。UDP不提供可靠性,它只是把应用程序传给IP层的数据报发送出去,但是并不能保证它们能到达目的地。由于UDP在传输数据报前不用在客户和服务器之间建立一个连接,且没有超时重发等机制,故而传输速度很快。
应用: HTTP协议在运输层采用的就是TCP协议,在浏览器中输入IP地址后,与服务器建立连接,采用的就是TCP协议,是一种面向连接、可靠的字节流服务。
当强调传输性能而不是传输的完整性时,如:音频、多媒体应用和视频会议时,UDP是最好的选择。另外,腾讯QQ采用也是UDP协议。
OpenGl面试题:
1.什么是model,view,project矩阵?
世界矩阵(World Matrix)、视图矩阵(View Matrix)以及投影矩阵(Projection Matirx);
世界矩阵确定一个统一的世界坐标,用于组织独立的物体形成一个完整的场景;
视图矩阵就是我们能看到的那部分场景,由虚拟摄像机负责拍摄;
投影矩阵就是3维物体的平面影射.把三维场景在一个二维的平面上显示.
2.说一下新OpenGL和老版本OpenGL的区别。
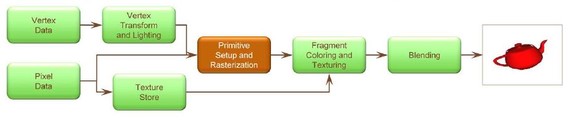
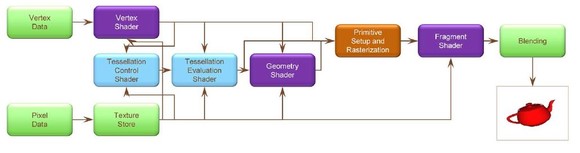
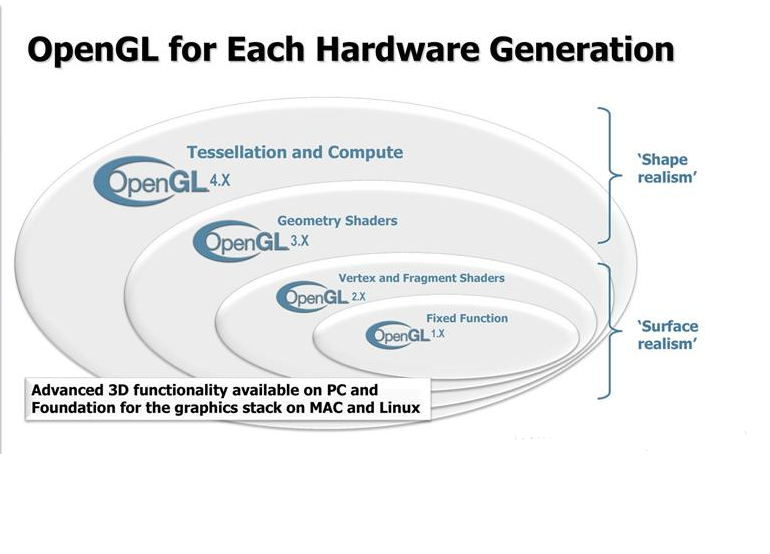
可编程流水线带来了极大的灵活性,通过Shader语言,可以在GPU上进行计算,释放CPU。而Shader的层次越越来越高,从Suerface级别的Vertexshader和Freagment Shader 到Shape级别的 Geometry shader和Tesselation shader。
3.OpenGL中要用到哪几种Buffer?
帧缓冲(Frame Buffer)
颜色缓冲(Color Buffer)
模板缓冲(Stencil Buffer)
顶点缓冲(Vertice Buffer)
深度缓冲(Depth Buffer)
具体说明参见:Real time rendering - 图形硬件
4.请介绍你所有知道的纹理Alpha混合方式,原理(公式).
假设一种不透明东西的颜色是A,另一种透明的东西的颜色是B,那么透过B去看A,看上去的颜色C就是B和A的混合颜色,可以用这个式子来近似,设B物体的透明度为alpha(取值为0-1,0为完全透明,1为完全不透明)
R(C)=alpha*R(B)+(1-alpha)*R(A)
G(C)=alpha*G(B)+(1-alpha)*G(A)
B(C)=alpha*B(B)+(1-alpha)*B(A)
R(x)、G(x)、B(x)分别指颜色x的RGB分量。看起来这个东西这么简单,可是用它实现的效果绝对不简单,应用alpha混合技术,可以实现出最眩目的火光、烟雾、阴影、动态光源等等一切你可以想象的出来的半透明效果。
5.GLSL的shader如何使用?
首先当然是glewint().
讲Shader文件读取进来。
初始化shader...
6.GLSL的如何传递数据?
uniform变量
uniform变量是外部application程序传递给(vertex和fragment)shader的变量。因此它是application通过函数glUniform**()函数赋值的。在(vertex和fragment)shader程序内部,uniform变量就像是C语言里面的常量(const ),它不能被shader程序修改。
attribute变量
attribute变量是只能在vertex shader中使用的变量。(它不能在fragment shader中声明attribute变量,也不能被fragment shader中使用)
一般用attribute变量来表示一些顶点的数据,如:顶点坐标,法线,纹理坐标,顶点颜色等。
在application中,一般用函数glBindAttribLocation()来绑定每个attribute变量的位置,然后用函数glVertexAttribPointer()为每个attribute变量赋值。
varying变量
varying变量是vertex和fragment shader之间做数据传递用的。一般vertex shader修改varying变量的值,然后fragment shader使用该varying变量的值。因此varying变量在vertex和fragment shader二者之间的声明必须是一致的。application不能使用此变量。
7.两圆相交,只有2交点A、B,过A点做线段CAD,CA、AD为两圆的弦,问什么情况下CAD最长,并证明。提示圆心角和圆周角的两倍关系。
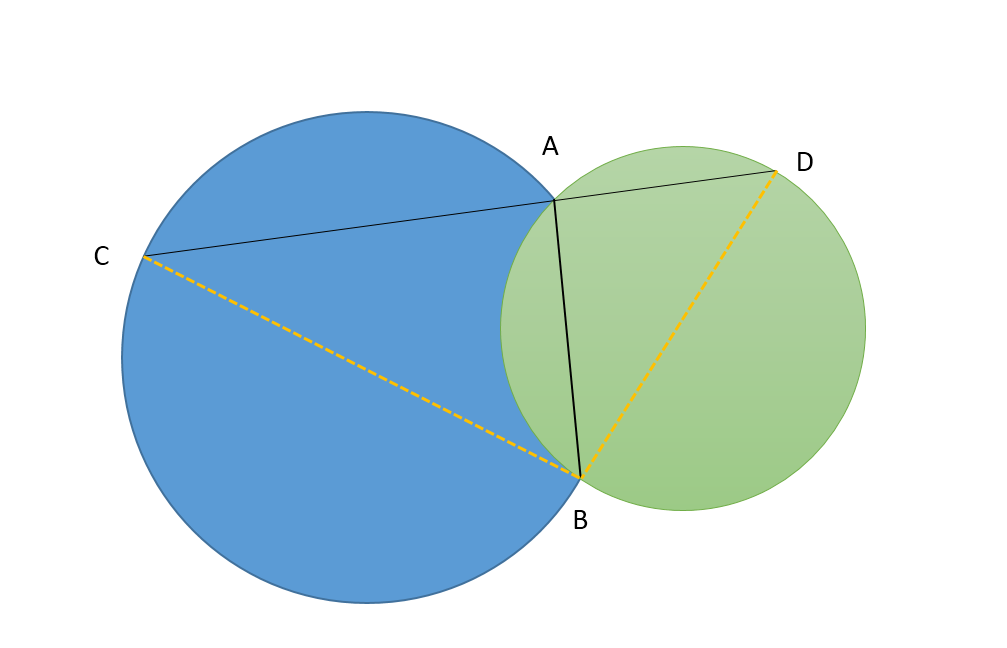
如图分别连接BC,BD。当CAD不断的变化的时候,可以得到个无数个三角形CBD,这些三角形的夹BCA和角BDA都是相同的,分别是BA对应的圆心角的一半。
则这些三角形都是相似的。
那么当BD最大的时候,也就是三角形最大的时候,也就是CAD最长的时候。
BD最大的时候就是BD为圆的直径,则BAD为直角,同理,BAC也是直角=>BA 垂直CAD。
8.平面上N个点,每两个点都确定一条直线, 求出斜率最大的那条直线所通过的两个点(斜率不存在的情况不考虑)时间效率越高越好。
程序的基本步骤就是:
1.把N个点按x坐标排序。
2.遍历,求相邻的两个点的斜率,找最大值。
时间复杂度Nlog(N)
9.顶点法线和面法线的作用。
面法线,垂直于平面,位于中央,经常用于flat着色。
点的法线是在使用Phone或Gouraud模型时计算光照使用。如果一个面上的所有法线都一样,他们的光照也就一样,就会产生 flatness 效果;而如果把每个顶点的法向设置不同,则更平滑。
********************************
问题1:大概说下着色器是怎么工作的

以unity为例:
最上面【Geometry】是几何模型,几何模型进入【Unity】,可以理解为把几何模型Mesh、网格等数据交给Unity,Unity导入后就通过Unity引擎去调用【Grphics APU】图形API,调用图形API的过程就是在驱动GPU进行处理运算。
进入GPU运算首先进行的是【Vertex Processor】顶点处理器,这个部分就需要我们使用【Vertex Shader】顶点着色器,顶点着色器运算的结果会交给【Pixel Processor】像素处理器,也就是片段处理器,在这个部分我需要为像素处理编写【Pixel Shader】像素着色器程序,这部分计算完后就输出了最终我们可以用于在屏幕上的颜色信息,我们把它叫做【Frame Buffer】帧缓冲。帧缓冲存储的是计算机依次显示所要的数据,但也不仅仅是这些数据,它还有其他的附加信息,比如深度值等。
问题2:cpu和gpu之间的调度
第一步:CPU从文件系统里读出原始数据,分离出图形数据,然后放在系统内存中,这个时候GPU在发呆。
第二步:CPU准备把图形数据交给GPU,这时系统总线上开始忙了,数据将从系统内存拷贝到GPU的显存里 。
第三步:CPU要求GPU开始数据处理,现在换CPU发呆了,而GPU开始忙碌工作。当然CPU还是会定期询问一下GPU忙得怎么样了。
第四步:GPU开始用自己的工作间(GPU核心电路)处理数据,处理后的数据还是放在显存里面,CPU还在继续发呆。
第五步:图形数据处理完成后,GPU告诉CPU,我忙完了,准备输出或者已经输出。于是CPU开始接手,读出下一段数据,并告诉GPU可以歇会了,然后返回第一步。
问题3:opengl的一些概念,如矩阵变换,矩阵变换的原理。怎么对顶点进行的变换,有多少个矩阵,分别是什么作用
矩阵变换就是将物体的位置、方向、坐标轴通过与矩阵相乘的形式而进行改变的过程,
对顶点进行变换:MVPMatrix=ProjectionMatrix∗ViewMatrix∗ModelMatrix∗vertex
三个矩阵分别是:
model矩阵:世界矩阵(统一的世界坐标)
view矩阵:视图矩阵(虚拟摄像机拍摄)
projection矩阵:投影矩阵(把三维场景在二维平面上显示)
问题4:opengl缓冲区的概念及工作原理
帧缓冲(Frame Buffer) :可能是放在内存中,也可能是放在显存中。color buffer是frame buffer
的一部分,然后和frame buffer 和 video conntroller相连接,video controller负责将frame Buffer 输出到各种显示器上
颜色缓冲(Color Buffer) :存放颜色和像素的值,并通过加载buffer把图形显示在屏幕上
模板缓冲(Stencil Buffer) :模板缓冲区可以为屏幕上的每个像素点保存一个无符号整数值,这个值的具体意义视程序的具体应用而定。原理:在渲染的过程中,可以用这个值与一个预先设定的参考值相比较,根据比较的结果来决定是否更新相应的像素点的颜色值。这个比较的过程被称为模板测试。模板测试发生在透明度测试(alpha test)之后,深度测试(depth test)之前。如果模板测试通过,则相应的像素点更新,否则不更新。
顶点缓冲(Vertice Buffer):
深度缓冲(Depth Buffer):是在三维图形中处理图像深度坐标的过程,这个过程通常在硬件中完成,它也可以在软件中完成,它是可见性问题的一个解决方法。可见性问题是确定渲染场景中哪部分可见、哪部分不可见的问题。原理:如果场景中的两个物体在同一个像素生成渲染结果,那么图形处理卡就会比较二者的深度,并且保留距离观察者较近的物体。然后这个所保留的物体点深度保存到深度缓冲区中。最后,图形卡就可以根据深度缓冲区正确地生成通常的深度感知效果:较近的物体遮挡较远的物体。这个过程叫作 z 消隐。
问题5:mipmap是怎么回事
Mipmap是一个功能强大的纹理技术,它可以提高渲染的性能以及提升场景的视觉质量,它可以用来解决一般纹理贴图出现的两个常见问题:
1.闪烁,当屏幕上被渲染物体的表面与它所应用的纹理图像相比显得非常小时,就会出现闪烁,尤其当相机和物体在移动的时候,这种负面效果更容易出现。2.性能问题,加载了大量纹理数据之后,还要对其缩小,在屏幕上显示的只是一小部分,纹理越大,所造成的影响越大。
Mipmap就可以解决上面那两个问题,当加载纹理的时候,不单单加载一个纹理,而是加载一系列从大到小的纹理mipmapped纹理状态,然后OpenGL会根据给定的几何图像的大小选择最合适的纹理,Mipmap是把纹理按照2的倍数进行缩放,知道图像1X1的大小,然后把这些图都存储起来,当要使用就选择一个合适的图像。但是这会增加一些额外的内存,在正方形的纹理贴图中使用Mipmap技术,大概要比原来多出三分之一的内存空间。
mipmap有多少个层级是有glTexImage的第二个参数level决定的。层级从0开始,0,1,2,3这样递增,如果没有使用mipmap技术,只有第0层的纹理会被加载。在默认情况下, 为了使用mipmap,所有层级都会被加载,但是我们可以用纹理参数来控制要加载的层级范围,使用glTexParameteri,第二个参数为GL_TEXTURE_BASE_LEVEL来指定最低层级的level,第三个参数GL_TEXTURE_MAX_LEVEL来指定最高层级的level,例如我只需要加载0到4层级的纹理。
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_BASE_LEVEL, 0);
glTexParameteri(GL_TEXTURE_2D,GL_TEXTURE_MAX_LEVEL,4);
除此之外,我们还可通过GL_TEXTURE_MIN_LOD和GL_Texture_max_lOD来限制纹理的使用范围(最底层和最高层)
UE4相关概念:
1、蓝图Blueprint:蓝图是一个类,其工作模式类似于unity中的prefabs模式,包含了很多东西如函数、网格物体、灯光等,使用蓝图方便了三维交互的编程。















 45万+
45万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









