







“博客之星”2024年度总评选活动进行中...
点击以下链接进行投票:
https://www.csdn.net/blogstar2024/detail/102
一. 背景
春节期间,DeepSeek 在一夜之间迅速大火,成为全球瞩目的焦点,用一句话形容就是:高开疯走!
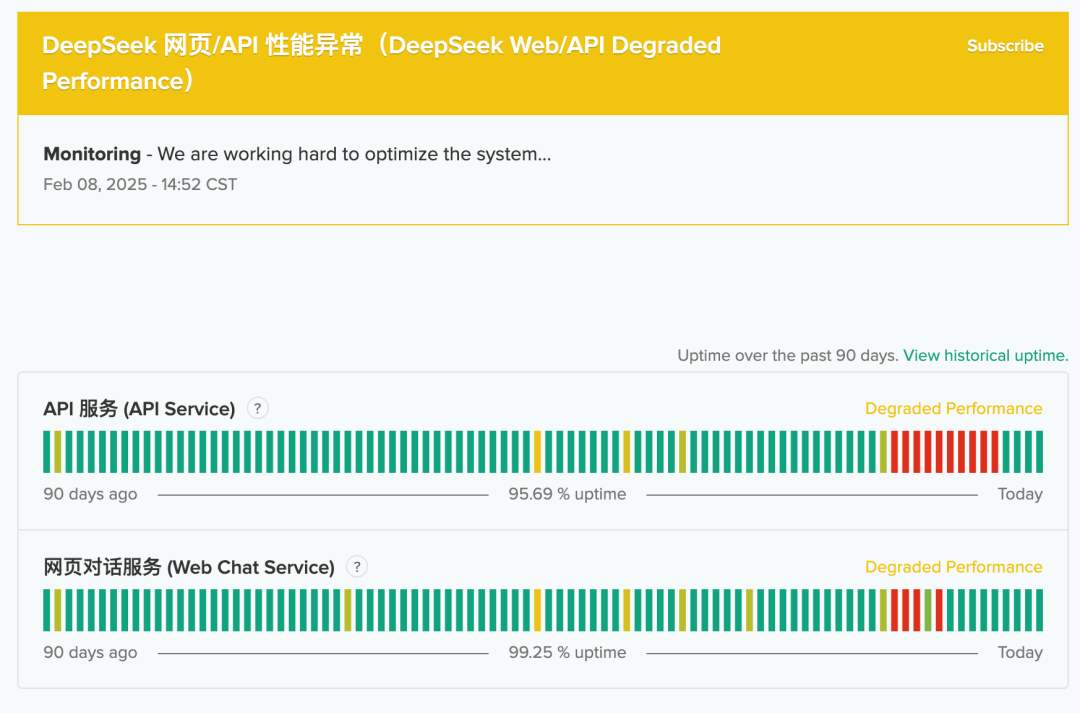
全球的爆火,让 DeepSeek 用户量激增,导致服务不稳定。同时还伴有国外大规模 DDOS 恶意攻击,因此,Deepseek 网页服务和 API 服务变得经常不可用。
直到现在,我们打开 DeepSeek 的官网,在使用过程中会经常会出现以下问题。
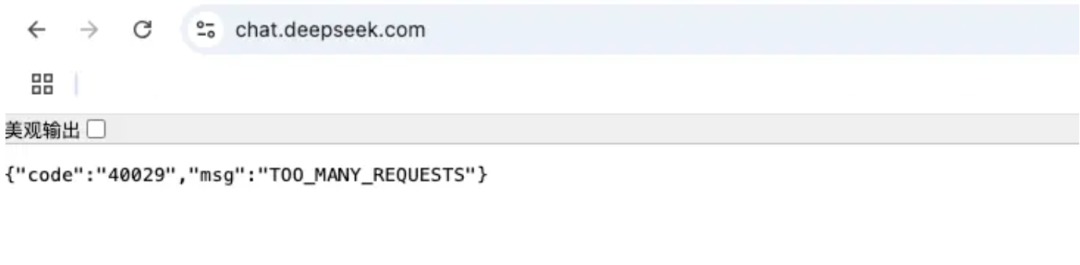
1.1 Too Many Requests
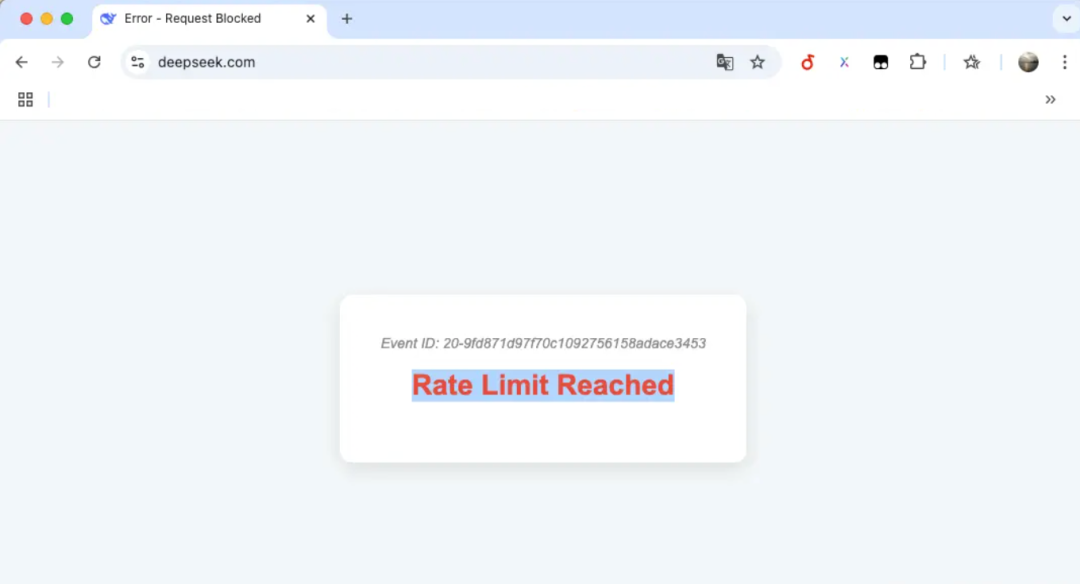
1.2 Rate Limit Reached
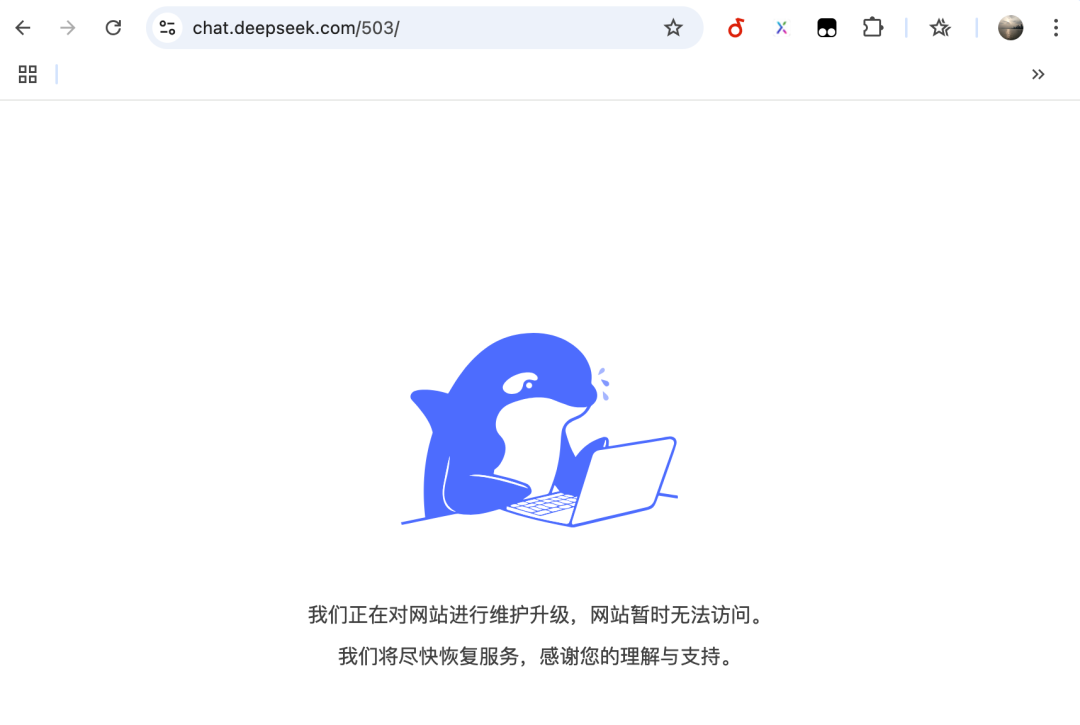
1.3 503
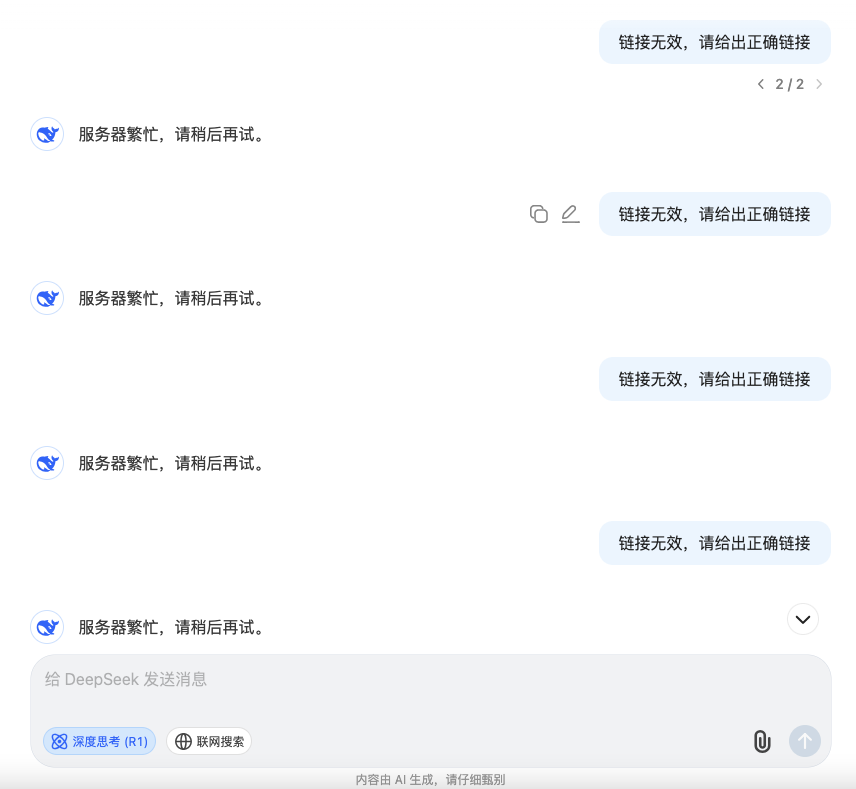
1.4 服务器繁忙,请稍后再试
使用过程中,最常见的就是服务器繁忙了,要哭了!
同时,我们也可以通过 https://status.deepseek.com/ 来查看 DeepSeek 的使用状态!
既然目前 DeepSeek 线上服务不稳定,那么本篇文章,我将教大家如何免费将 DeepSeek 模型部署到本地,无需联网,您也可以顺畅地使用 DeepSeek R1 模型。
我将介绍两种本地搭建方式,这可能是全网最全面的 DeepSeek 本地部署方法,记得点赞关注,下面我们直接进入部署教程!
二. 安装教程
为什么要本地部署?
现在有越来越多的开源模型,可以让你在自己的电脑或服务器上运行。使用本地模型有许多优势:
-
完全离线运行,保护隐私数据安全
-
无需支付在线 API 费用
-
完全离线,服务稳定,无网络延迟
-
可以自由调整和定制模型参数
本地部署开源大模型,可以简单总结为以下三步:
-
安装 Ollama
-
安装大模型(以 DeepSeek-R1 为例)
-
配置集成工具(Chatbox、Docker 等)
接下来我们详细的来走一遍流程。
2.1 安装 Ollama
首先,要在本地运行 DeepSeek,您需要一个名为 Ollama(欧拉玛) 的工具。
Ollama 是什么?Ollama 是一个开源的本地模型运行工具,可以方便地下载和运行各种开源模型,比如 Llama、Qwen、DeepSeek 等。这个工具支持 Windows、MacOS、Linux 等操作系统。
访问 Ollama 的官网,点击下载按钮,选择适合您操作系统的版本进行下载安装。
Ollama 下载地址:(https://ollama.com/)
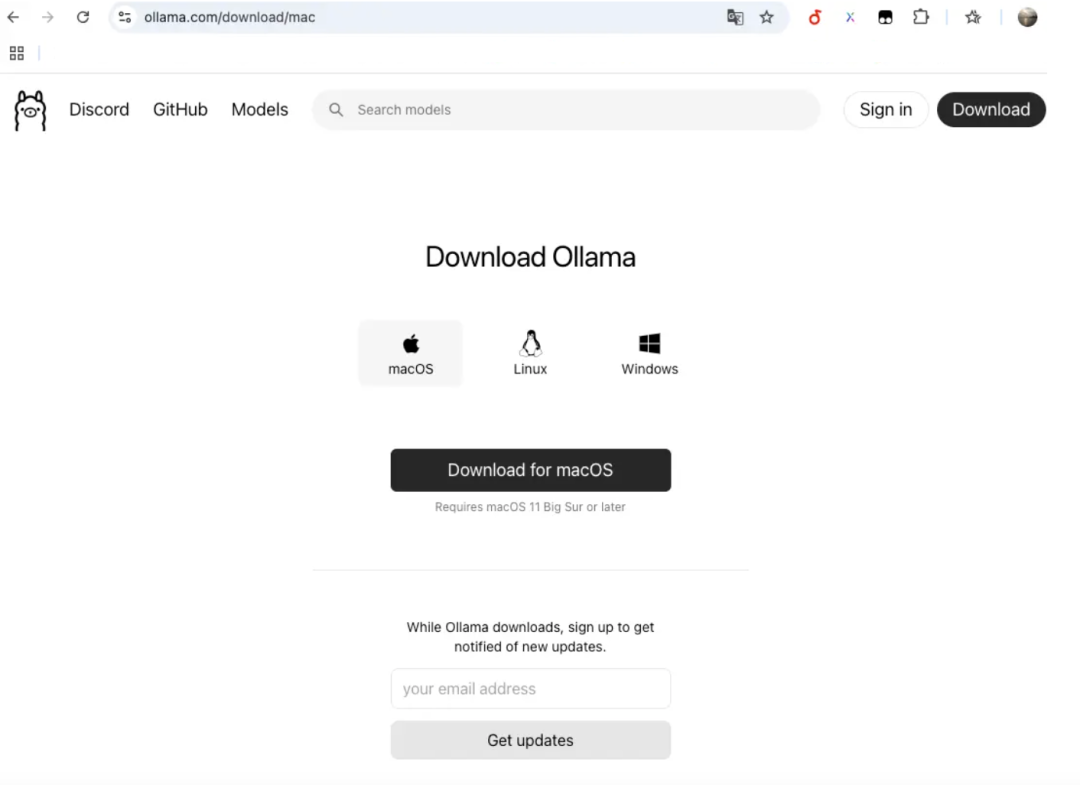
我使用的是 Mac 电脑,因此选择了 Mac OS,当然您也可以下载 Windows 版本,后续操作步骤相同。
下载完成后,按照默认设置进行安装,成功安装后,您的电脑上方会出现对应的图标。

❝注意:MacOS 对系统版本有要求 macOS 11 Big Sur+,Requires macOS 11 Big Sur or later
关于下载速度慢的问题,如下图,速度太慢,导致下载不成功,我试了几次也没能成功!
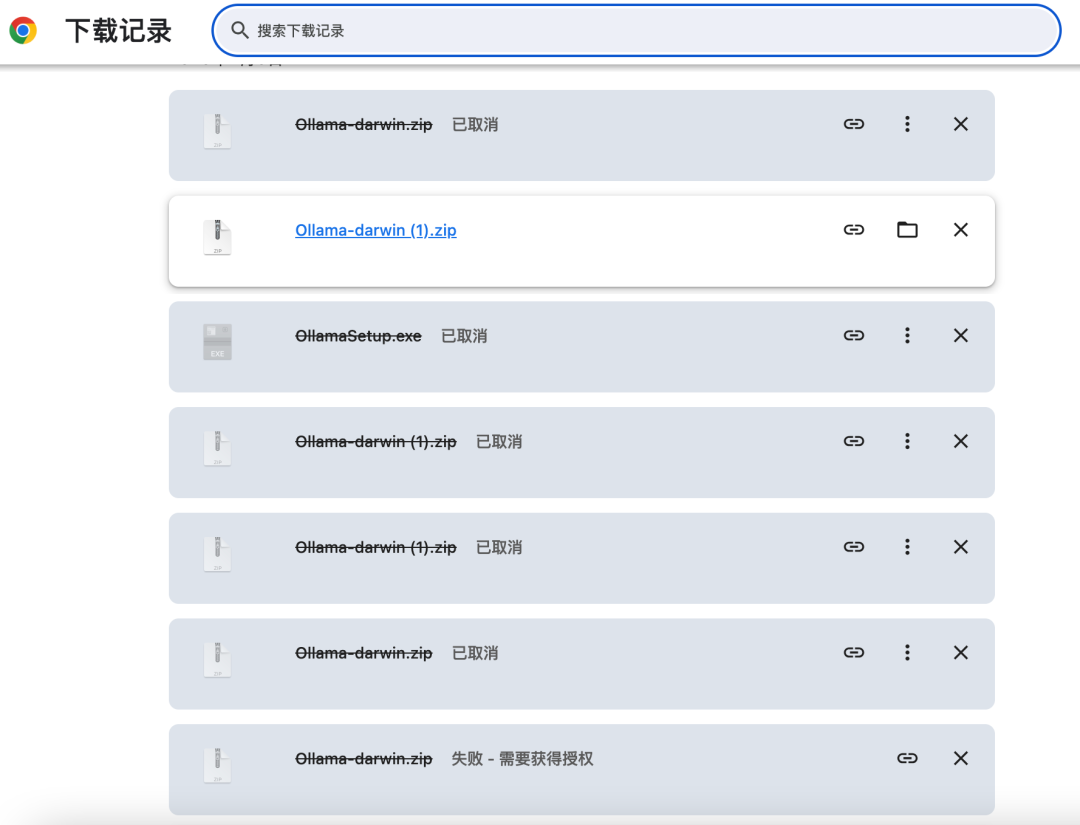
可以通过 GitHub Proxy 代理加速下载,速度很快,秒下载完成,点击下面链接可以下载:
https://ghfast.top/https://github.com/ollama/ollama/releases/download/v0.5.7/Ollama-darwin.zip
2.2 安装 DeepSeek 模型
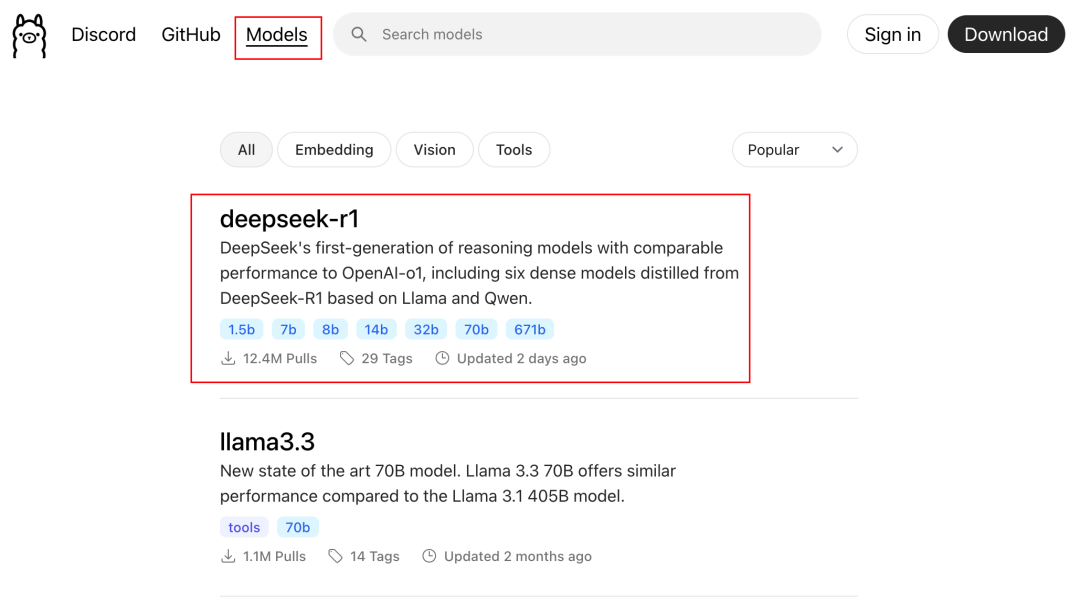
在 Ollama 的主页,点击页面上的 “Models” 菜单,可以看到这里有许多热门的开源大模型。
我们选择第一个 DeepSeek R1 模型即可。这里有多个版本可供选择,您需要根据自己的电脑配置选择合适的版本,数字越大,对电脑配置的要求越高。
打开链接:https://ollama.com/search
DeepSeek 模型参数类型 根据搜索结果,DeepSeek 模型有多种参数类型,不同的参数规模适用于不同的应用场景和资源需求。以下是主要的几种模型参数类型:
DeepSeek-R1 系列:
-
1.5B:适用于资源有限的环境,能在较低的计算资源下提供较好的性能。
-
7B:适用于中等资源需求的环境。
-
8B:在 7B 基础上进一步优化性能。
-
14B:提供更高的理解和生成能力。
-
32B:适用于需要较高计算资源的环境,性能显著提升。
-
70B:高性能模型,适用于复杂问题解决。
-
671B:超大规模模型,专为高性能场景设计,如科研和复杂问题解决,可能采用 MoE(混合专家模型)架构优化效率。
DeepSeek-V3 系列:
-
6710B(6710 亿):采用 MoE 架构,每个 token 仅激活 370 亿参数,提供了极高的计算效率和性能。 这些参数类型涵盖了从小规模到超大规模的模型,适应不同的应用需求和资源条件。
关于 DeepSeek-R1 系列,我整理了不同版本的模型配置要求,表格详细如下:
| 模型大小 | Windows 配置 | Mac 配置 | 服务器配置 | 适用场景 | 选择建议 |
|---|---|---|---|---|---|
| 1.5B | - RAM: 4GB | - 内存: 8GB(统一内存) | - | 简单文本生成/基础代码补全 | 适合个人开发者或轻量级任务,低配置设备即可运行。 |
| 7B | - RAM: 8-10GB | - 内存: 16GB | - | 中等复杂度问答/代码调试 | 适合中等需求场景,如代码调试或简单问答,需中端显卡支持。 |
| 8B | - RAM: 12GB | - 内存: 24GB | - | 多轮对话/文档分析 | 适合需要多轮交互或文档分析的场景,需较高显存和内存支持。 |
| 14B | - RAM: 24GB | - 内存: 32GB | - | 复杂推理/技术文档生成 | 适合技术文档生成或复杂逻辑推理任务,需高端显卡和大内存。 |
| 32B | - RAM: 48GB | - 内存: 64GB | - | 科研计算/大规模数据处理 | 适合科研或大规模数据处理,需顶级消费级显卡(如 RTX4090)。 |
| 70B | - RAM: 64GB | - 内存: 128GB(需外接显卡) | - 服务器级多 GPU(如双 RTX4090) | 企业级 AI 服务/多模态处理 | 需企业级硬件支持,适合多模态处理或高并发 AI 服务,推荐服务器部署。 |
| 671B | - GPU: 8×H100(通过 NVLINK 连接) | 暂不支持 | - GPU 集群(8×H100) | 超大规模云端推理 | 仅限云端部署,需超大规模计算资源,适用于超大规模模型推理或训练场景,普通用户无法本地部署。 |
如何选择模型?
-
轻量级任务(如文本生成):选择 1.5B 或 7B,对硬件要求低。
-
中等复杂度任务(如代码调试):选择 7B 或 8B,需中端显卡。
-
多轮交互或文档处理:选择 8B 或 14B,需较高显存和内存。
-
复杂推理/科研计算:选择 14B 或 32B,需高端显卡和大内存。
-
企业级应用:选择 70B,需多 GPU 服务器支持。
-
超大规模云端服务:仅 671B 支持,需专业 GPU 集群。
❝注意:
Mac 配置中“内存”为统一内存,需结合芯片性能选择(如 M3Ultra 支持更高负载)。
70B 及以上模型建议服务器部署,普通设备难以满足资源需求。
根据您选定的模型,打开终端运行对应命令,例如:选择安装 8b 模型。
ollama run deepseek-r1:8b
接下来,打开命令行终端,将刚刚复制的代码粘贴进去并回车。第一次运行时,可能速度会稍慢,因为它需要下载模型。
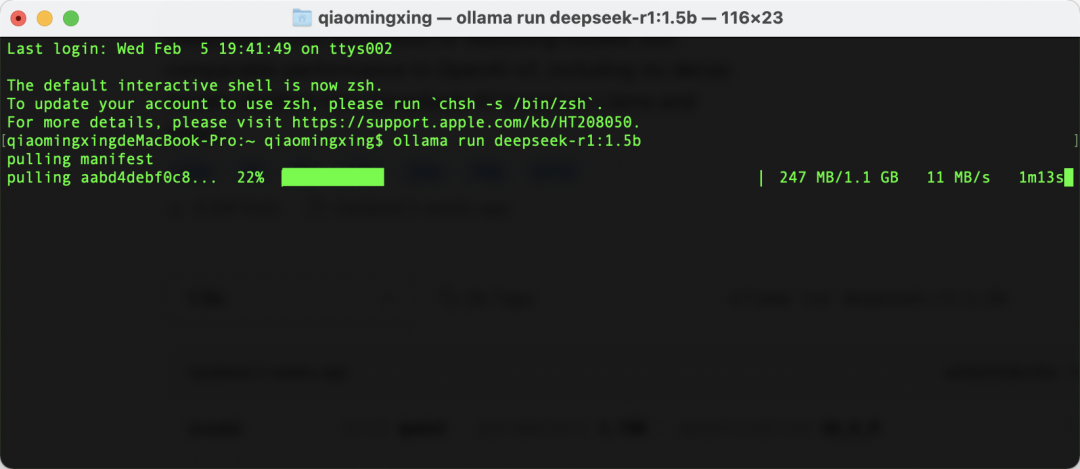
等待进度条完成后,模型就会安装在您的本地。
安装完成后,我们可以和它进行对话了,输入文字,按下回车。现在它开始思考,您可以看到速度相当快,当然这主要取决于您的电脑配置,配置越好,速度越快。
结果出来后,上面是思考过程,下面是输出结果。
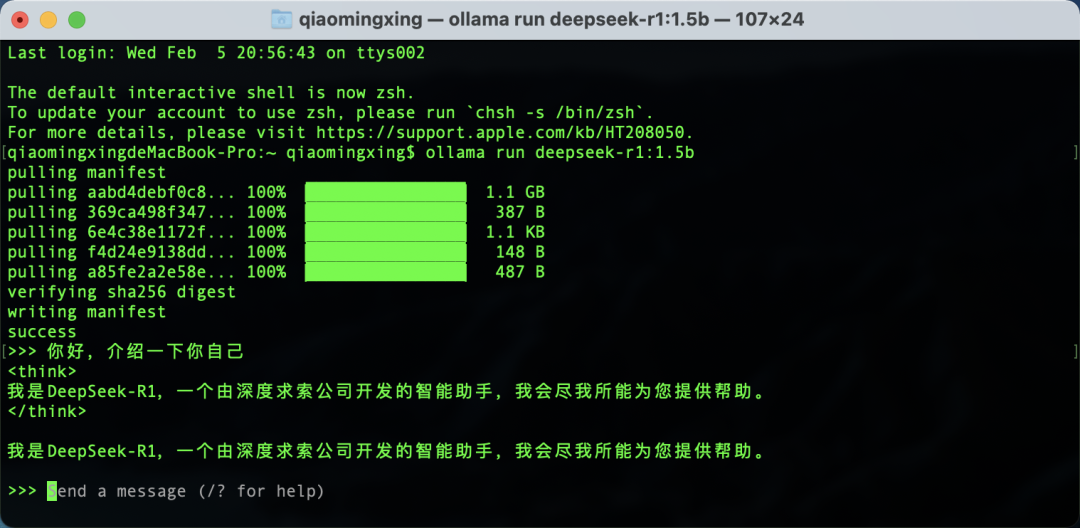
虽然现在已经可以直接使用,但每次都要打开终端工具,还是显得有些麻烦,非技术人员使用起来也不太习惯。
接下来,我们将介绍两种可视化的图文交互界面供您使用。
三. 配置集成工具
和大模型搭配使用的工具有不少,接下来我介绍一下常用的几种!供大家参考。
3.1 使用 Chatbox 集成
第一种方案是使用 Chatbox,也是比较通用的方案。你可以通过浏览器直接访问 Chatbox 的官网,使用在线版或下载到电脑上进行安装。
打开链接:https://chatboxai.app/zh
Chatbox 可以很好地连接到 Ollama 服务,让你在使用本地模型时可以获取 Chatbox 提供的更多强大功能,比如 Artifact Preview、文件解析、会话话题管理、Prompt 管理等。
进入 Chatbox 主页后,使用本地的 API,选择 Ollama API。请注意,为了确保 Ollama 服务能够远程连接,您需要查看相关教程,在这里,我简单写一下。
❝注意:运行本地模型对你的电脑配置有一定要求,包括内存、GPU 等。如果出现卡顿,请尝试降低模型参数。
如何在 Chatbox 中连接本地 Ollama 服务?
在 Chatbox 中打开设置,在模型提供方中选择 Ollama,在模型下拉框中选择你运行的本地模型。
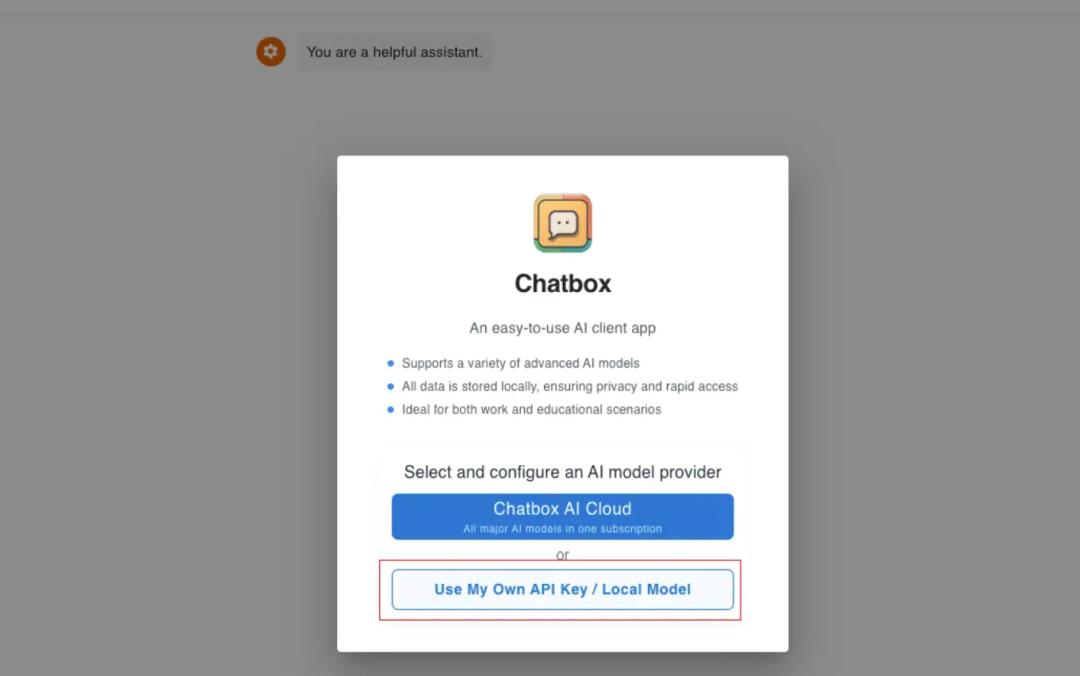
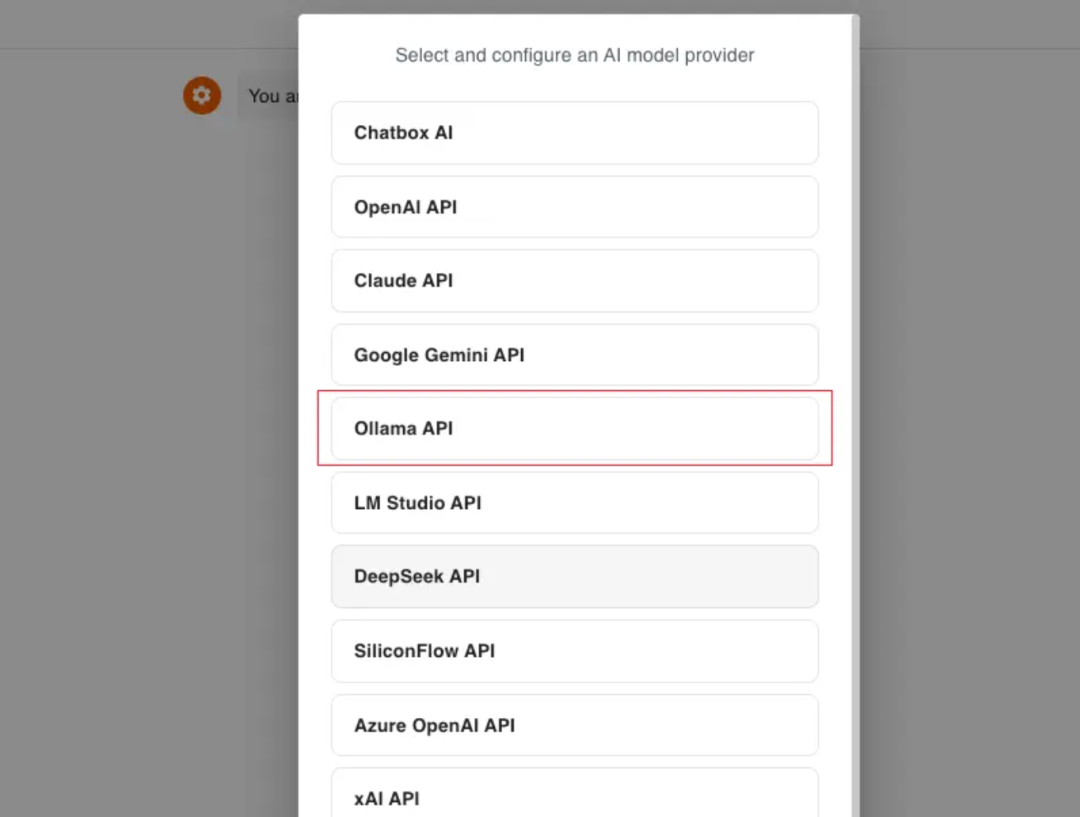
打开 Chatbox Settings,您也能看到 DeepSeek R1 模型,选择后点击保存。
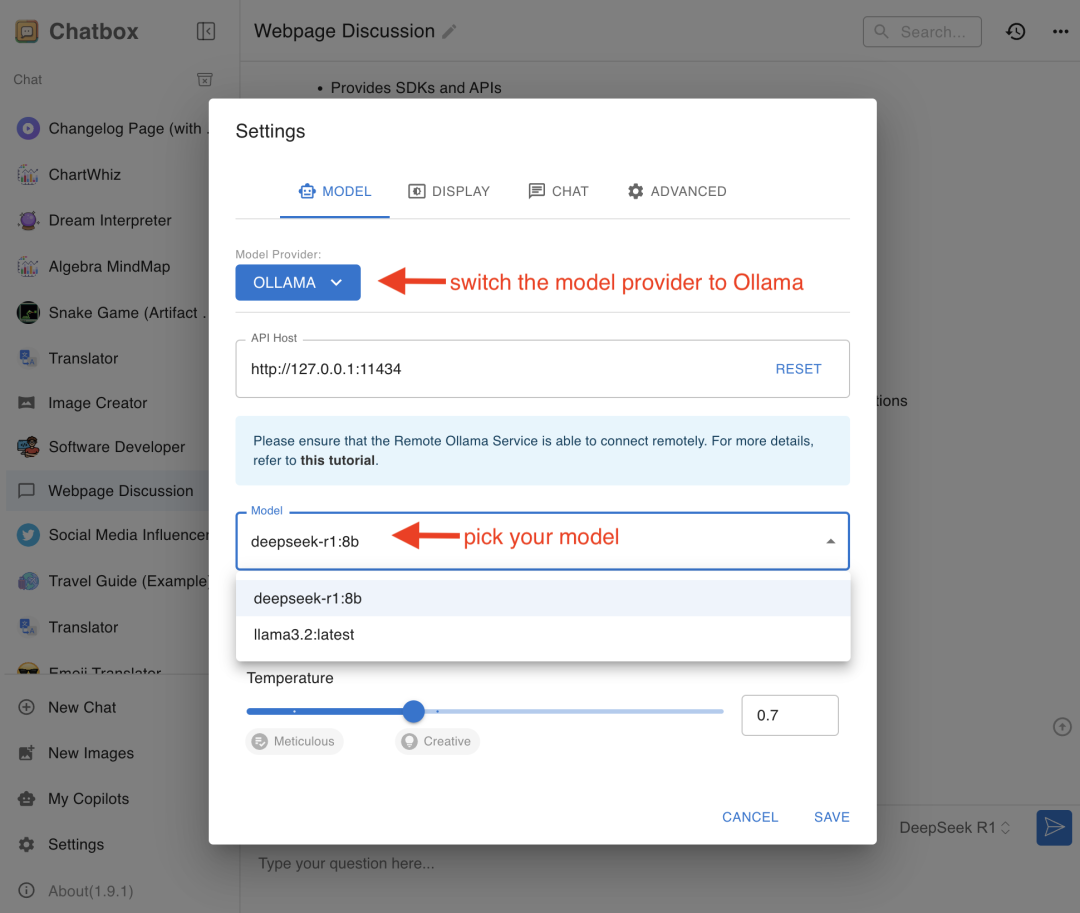
❝注意:如果没有看到本地模型,可能需要在安装完成 DeepSeek R1 模型后,重启 Ollama
现在,您可以在可视化界面中与 DeepSeek 进行对话,随便输入问题,它现在已经可以和您进行对话了。
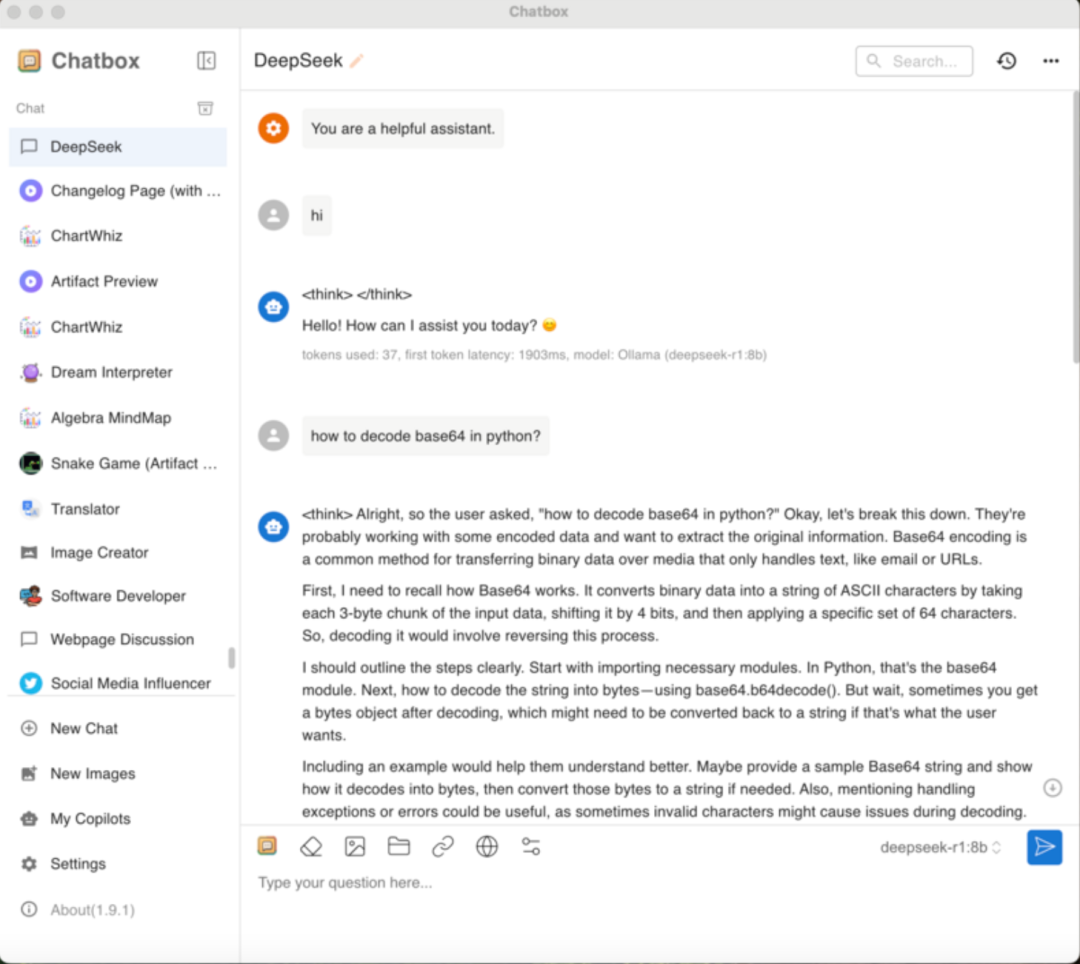
上面是它的思考过程,下面是它给我们的答案。完全免费,人机交互流畅无卡顿,并且无需联网,您可以在本地使用。这就是我们部署到本地的 Chatbox 方案。
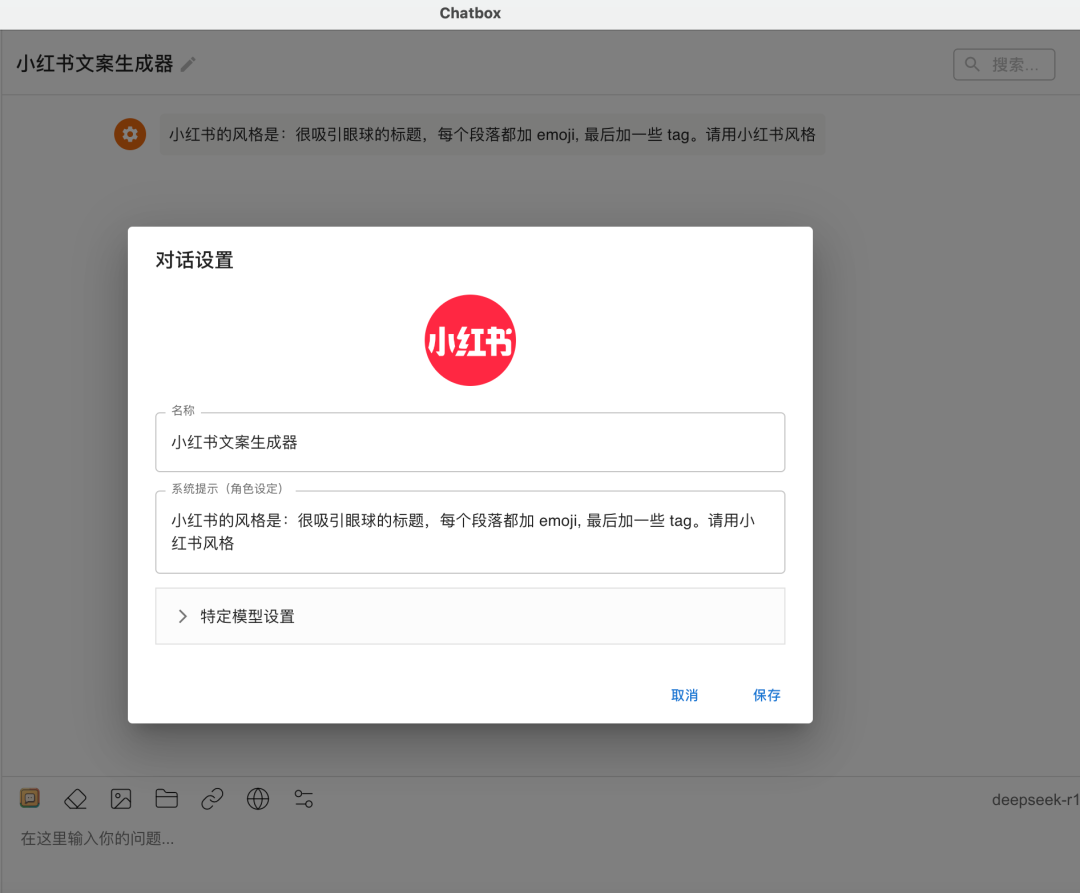
Chatbox 还有一个特点,就是可以自定义创建新搭档,设定您的专属智能体。按照功能命名,并输入智能体的角色设定,例如:“您是一个专业的小红书文案生成器助手。”完成后,您的智能体就创建好了,接下来您可以使用这个智能体来帮助您撰写文案,它内部使用的正是 DeepSeek 模型。
3.2 使用 Docker 集成
上面介绍了 Chatbox 方案,它可以创建智能体。接下来我们将重点介绍一个支持语音的部署方案:Docker 集成。
首先,访问 Docker 官网,下载适合您电脑的版本,选择默认安装方式。如果您是第一次使用该软件,需要注册并登录。我们选择一个账号登录。
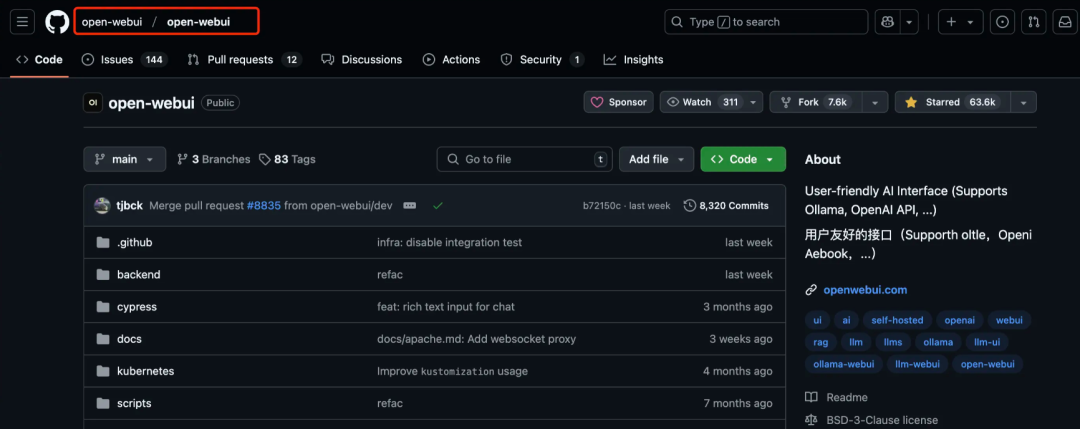
接下来,我们需要在 GitHub 上找到 open-webui 项目,向下滑动,找到 Docker 安装步骤。
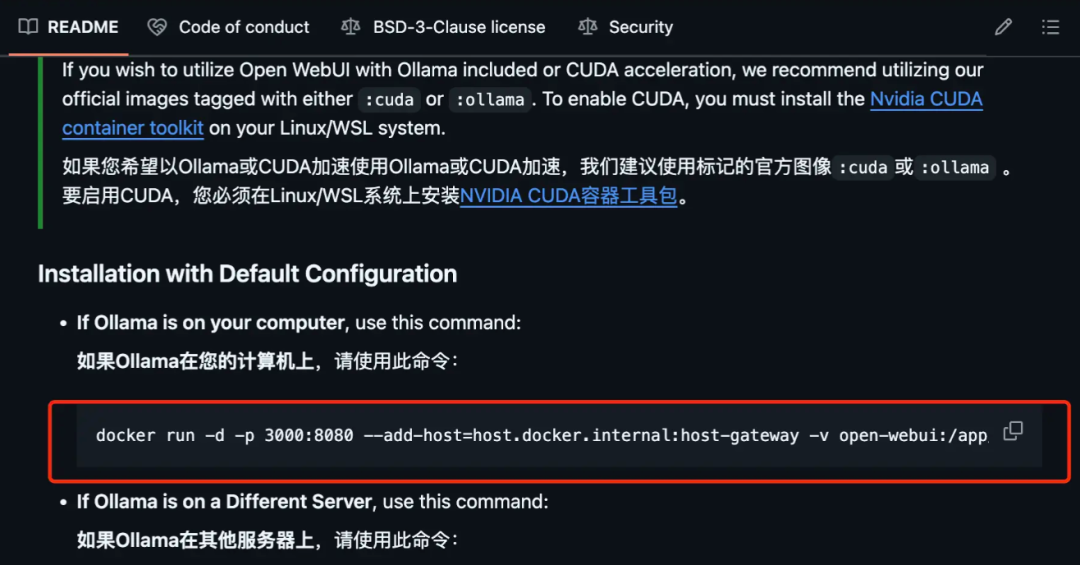
复制这行代码,打开终端,将其粘贴进去。回车后安装完成,接着打开刚刚的 Docker。
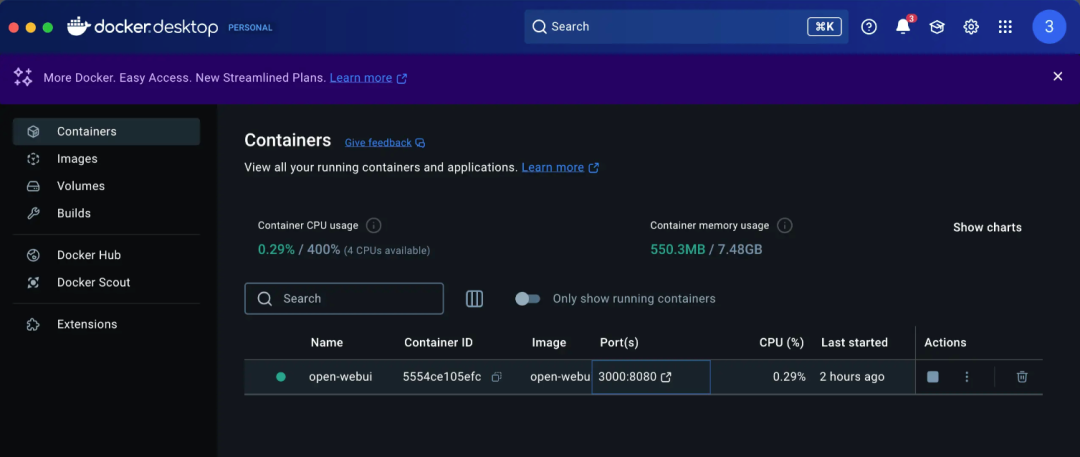
您会发现多了一个 open-webui 的选项。
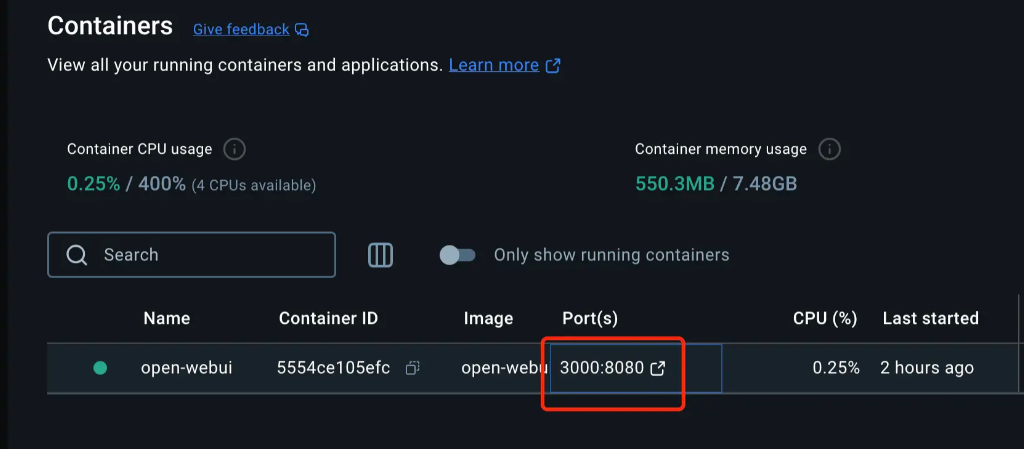
点击打开后:
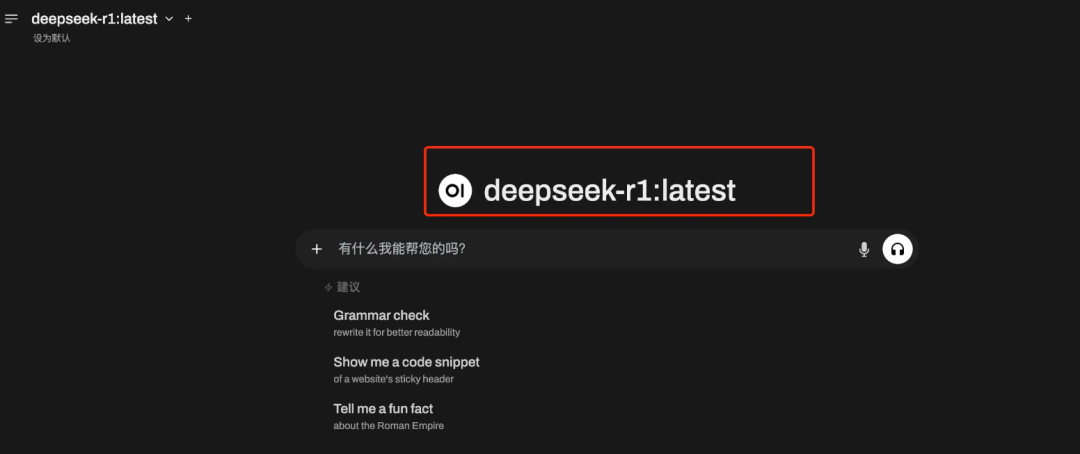
您将看到刚刚下载的 DeepSeek R1 模型。在这里,您可以直接提问,并且支持语音输入。
3.3 使用 VSCode 集成
除了上述介绍的两个工具使用 DeepSeek 以外,还可以集成到我们开发编辑器里面,作为一个前端开发人员,VSCode 重度使用者,怎么能缺少了它呢,接下来以 VSCode 为例,看一下如何集成 DeepSeek。
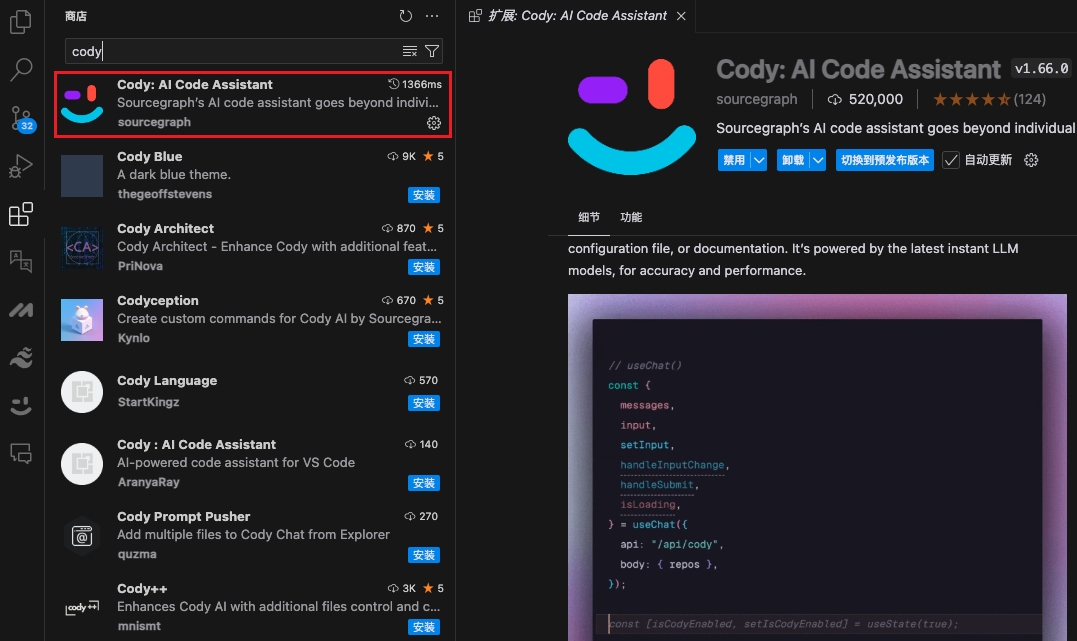
在 VSCode 扩展中,可以使用的 AI 插件有很多,我比较习惯用 Cody,在商店中搜索到安装登录 Cody 即可!
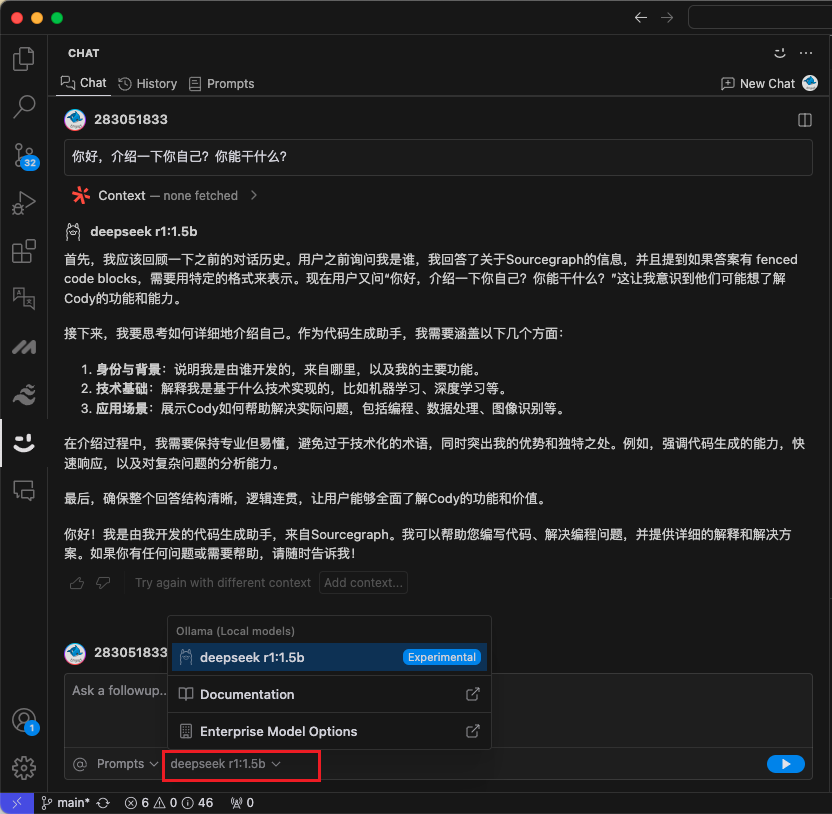
然后我们配置一下本地 Ollama 模型,就可以和 DeepSeek 对话了!
好了,以上就是 DeepSeek 的本地部署方案。我已经将所有步骤整理成文档分享给大家了,感兴趣的朋友,快去使用吧!
四. 拓展:在 Chatbox 中连接远程 Ollama 服务
除了可以轻松连接本地 Ollama 服务,Chatbox 也支持连接到运行在其他机器上的远程 Ollama 服务。
例如,你可以在家中的电脑上运行 Ollama 服务,并在手机或其他电脑上使用 Chatbox 客户端连接到这个服务。
你需要确保远程 Ollama 服务正确配置并暴露在当前网络中,以便 Chatbox 可以访问。默认情况下,需要对远程 Ollama 服务进行简单的配置。
如何配置远程 Ollama 服务?
默认情况下,Ollama 服务仅在本地运行,不对外提供服务。要使 Ollama 服务能够对外提供服务,你需要设置以下两个环境变量:
OLLAMA_HOST=0.0.0.0
OLLAMA_ORIGINS=*
4.1 在 MacOS 上配置
1.打开命令行终端,输入以下命令:
launchctl setenv OLLAMA_HOST "0.0.0.0"
launchctl setenv OLLAMA_ORIGINS "*"
2.重启 Ollama 应用,使配置生效。
4.2 在 Windows 上配置
在 Windows 上,Ollama 会继承你的用户和系统环境变量。
1.通过任务栏退出 Ollama。
2.打开设置(Windows 11)或控制面板(Windows 10),并搜索“环境变量”。
3.点击编辑你账户的环境变量。
为你的用户账户编辑或创建新的变量 OLLAMA_HOST,值为 0.0.0.0; 为你的用户账户编辑或创建新的变量 OLLAMA_ORIGINS,值为 * 。
4.点击确定/应用以保存设置。
5.从 Windows 开始菜单启动 Ollama 应用程序。
4.3 在 Linux 上配置
如果 Ollama 作为 systemd 服务运行,应使用 systemctl 设置环境变量:
1.调用 systemctl edit ollama.service 编辑 systemd 服务配置。这将打开一个编辑器。
2.在 [Service] 部分下为每个环境变量添加一行 Environment:
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
3.保存并退出。
4.重新加载 systemd 并重启 Ollama:
systemctl daemon-reload
systemctl restart ollama
4.4 服务 IP 地址
配置后,Ollama 服务将能在当前网络(如家庭 Wifi)中提供服务。你可以使用其他设备上的 Chatbox 客户端连接到此服务。
Ollama 服务的 IP 地址是你电脑在当前网络中的地址,通常形式如下:
192.168.XX.XX
在 Chatbox 中,将 API Host 设置为:
http://192.168.XX.XX:11434
4.5 注意事项
-
可能需要在防火墙中允许 Ollama 服务的端口(默认为 11434),具体取决于你的操作系统和网络环境。
-
为避免安全风险,请不要将 Ollama 服务暴露在公共网络中。家庭 Wifi 网络是一个相对安全的环境。
五. 拓展:DeepSeek 其他推荐
本地部署的好处不言而喻,稳定速度快,灵活可配置,不会报服务器繁忙。但是作为个人电脑,硬件性能有限,普通电脑难以满足其需求。因此可能你始终体验的是 “阉割版 DeepSeek”,无法体验到 “满血版 DeepSeek” 的强大能力。
面对这个情况,除了官网的 DeepSeek,也有其他的替代方案,我仅仅提供几个免费的方案,仅供参考!
5.1 纳米 AI 搜索
-
纳米 AI 搜索由 360 集团推出的一款综合性的 AI 搜索应用,旨在通过先进的技术手段,为用户提供更加高效、便捷的搜索体验。它支持 DeepSeek R1 模型。
-
官方地址:https://www.n.cn/
5.2 秘塔 AI 搜索
-
秘塔 AI 搜索是一个专注于中文搜索的 AI 搜索引擎,它结合了强大的搜索功能和 AI 对话能力。
-
官方地址: https://metaso.cn/
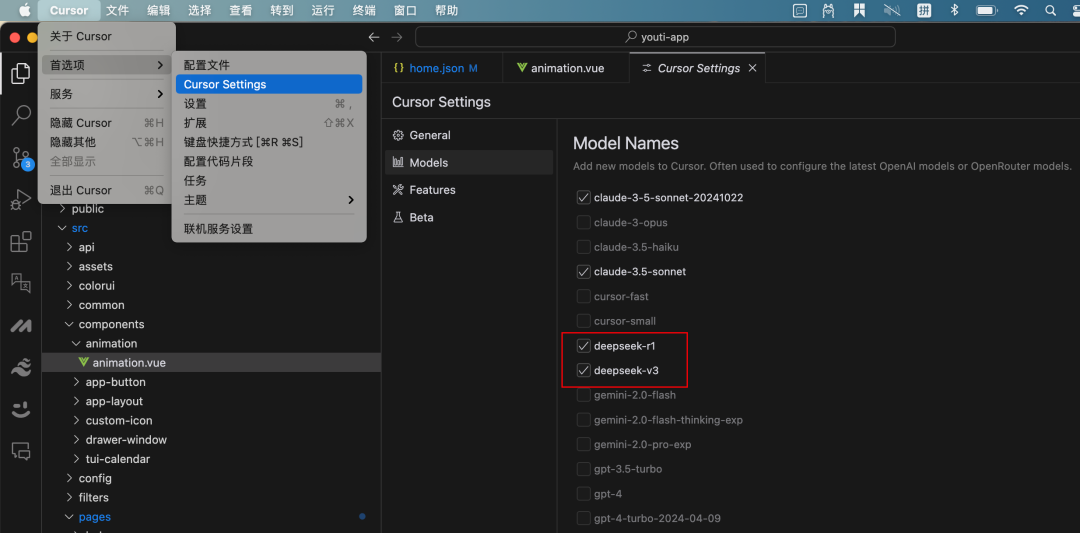
5.3 Cursor 开发工具
强烈推荐!
使用过 Cursor 工具的开发者应该了解它的强大,它是一款专为程序员打造的新一代 AI 编程助手,它目前不仅支持了 DeepSeek R1,同时也支持 DeepSeek V3 模型。
要使用 Cursor 的 DeepSeek R1 模型进行联网搜索和回答,非常简单:
-
在 Cursor > 首选项 > Cursor Settings > Models 中开启
deepseek-r1选项 -
在对话框中选择 DeepSeek 作为对话模型
❝其他的还有很多,不再一一列举,蹭热度的不少,请谨慎甄别!还是要以 DeepSeek 官网为主,其他为辅,快快使用起来吧!
六. 文档链接
-
DeepSeek 官网:https://www.deepseek.com/
-
Ollama 官网:https://ollama.com/
-
Chatbox 官网:https://chatboxai.app/
-
Chatbox 连接 Ollama 指南:https://chatboxai.app/zh/help-center/connect-chatbox-remote-ollama-service-guide
-
Ollama 服务配置:https://github.com/ollama/ollama/blob/main/docs/faq.md#how-can-i-expose-ollama-on-my-network
-
Docker 官网:https://www.docker.com/
-
Github 下载加速:https://ghproxy.link/



















 187
187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











