







前言
因为之前一直关注langchain,现在DeepSeek又非常的火爆,所以尝试在langchain项目中使用DeepSeek。
我在查询资料时,发现国外小哥已经提供了一套开源代码。于是本着图省事儿的原则,我立即下载并使用了这套代码,它基于DeepSeek-R1、LangChain 和 Ollama 搭建了一个隐私优先的检索增强生成(RAG)系统的文章。
按照步骤进行操作,亲测好用,分享给小伙伴们!
什么是 RAG ?
赘述一下基本概念,检索增强生成(Retrieval-Augmented Generation,简称 RAG)是一种结合信息检索和生成式 AI 的技术架构。RAG 通过从外部知识库(如文档、数据库)中检索相关信息,并将其作为上下文输入给 LLM(大型语言模型),从而提高回答的准确性,减少幻觉问题。
我们的目标是在本地运行一个 RAG 系统,能够处理 PDF 文档,保障数据隐私,并能高效回答与文档内容相关的问题。当然,通过修改代码,我们也可以实现处理其他类型的数据。
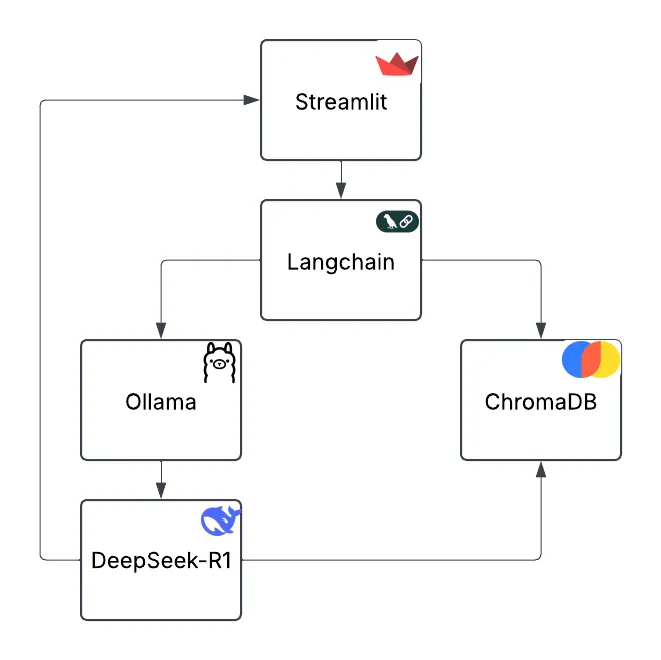
所需技术栈
本文使用了多个开源工具和框架:
-
LangChain:用于管理 RAG 工作流,支持文档加载、向量存储、检索和 LLM 交互。
-
DeepSeek-R1:众所周知,最近很火出圈的国产大语言模型。
-
Ollama:一个简化本地 LLM 部署的工具,支持 DeepSeek-R1 等多个模型,方便、快捷。
-
ChromaDB:用于存储和检索文本向量的数据库,支持高效的相似度搜索。
-
Streamlit:一个简单易用的 Python Web 框架,用于构建交互式用户界面。
使用过程
1、安装必要的工具
首先,确保你已经安装了 Python 3.8+,然后安装 Ollama:
curl -fsSL https://ollama.com/install.sh | sh
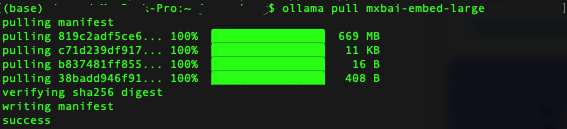
然后在命令行中使用下面的命令下载 DeepSeek-R1 模型和 mxbai-embed-large 词向量模型:
ollama pull deepseek/deepseek-r1
ollama pull mxbai-embed-large
tips: 因为我本地已经安装过Ollama,而且我在之前的文章中已经下载过deepseek-r1:1.5b模型,所以这里我只重新下载了向量模型mxbai-embed-large。
不习惯使用命令行的朋友,可以参考我之前的文章,采用手动的方式下载并按照Ollama和deepseek-r1。
文章链接:deepseek如此火爆,保姆级教程教你如何使用
2、设置 Python 项目环境
克隆 GitHub 仓库并安装依赖:
git clone https://github.com/paquino11/chatpdf-rag-deepseek-r1
cd chatpdf-rag-deepseek-r1
python -m venv venv
source venv/bin/activate # Windows 用户使用 `venv\Scripts\activate`
pip install -r requirements.txt
**提示:**如果遇到类似的错误提示
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for pyarrow
可以使用下面的命令升级pip后尝试
python3 -m pip install --upgrade pip
3、运行应用
按照步骤2操作完成后,我们就可以启动项目了,启动命令
streamlit run app.py
因为我使用的模型和代码中使用的模型不一致,所以这里我首先要修改一下模型名称,打开项目源码文件rag.py,修改模型名称为deepseek-r1:1.5b,同理我们也可以修改embedding模型:
def __init__(self, llm_model: str = "deepseek-r1:1.5b", embedding_model: str = "mxbai-embed-large"):
启动结果:

启动后,一般会自动打开浏览器页面,如果没有自动打开浏览器,也可以手动访问:http://localhost:8501
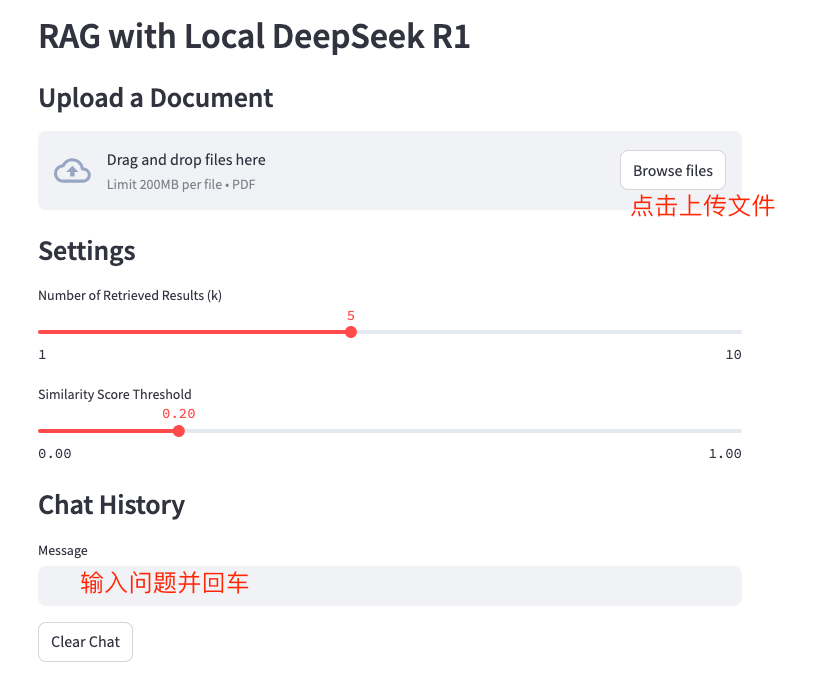
应用功能介绍
- PDF 文档上传
支持用户上传 PDF 文档,系统会自动解析并向量化存储。
- 查询系统
用户输入问题,系统会从向量数据库中检索相关段落,并结合 LLM 生成回答。
- 数据隐私保障
所有处理过程均在本地完成,数据不会上传到云端,确保敏感信息安全。
源码解析
我们简单分析一下源码,其核心代码rag.py解析如下
1、初始化 ChatPDF 类
def __init__(self, llm_model: str = "deepseek-r1:latest", embedding_model: str = "mxbai-embed-large"):
-
加载 LLM 和 Embeddings:
- ChatOllama:使用 DeepSeek-R1 进行问答。
- OllamaEmbeddings:使用 mxbai-embed-large 计算文本向量。
-
文本拆分:
- RecursiveCharacterTextSplitter 以 1024 字符块 分割文档,100 字符重叠 避免信息丢失。
-
提示词模板:
- 规定 LLM 需基于 检索到的上下文 生成 三句话内 的答案。
-
向量数据库(Chroma):
- 用于存储文档嵌入,并支持检索。
2、文档摄取(Ingest)
def ingest(self, pdf_file_path: str):
- 使用 PyPDFLoader 解析 PDF 文档
- self.text_splitter.split_documents(docs) 进行文本分块
- Chroma.from_documents() 计算 嵌入向量 并存储到 chroma_db 目录
3、问答(Ask)
def ask(self, query: str, k: int = 5, score_threshold: float = 0.2):
- 检索相关内容
- 使用 Chroma 向量数据库,以 相似度搜索 筛选 相关文本块(默认 k=5,阈值 0.2)
- 调用 RAG 处理链:
- RunnablePassthrough() 直接传递输入数据。
- self.prompt 处理查询上下文格式化。
- self.model 调用 LLM 生成答案。
- StrOutputParser() 解析 LLM 输出,返回最终答案。
相关文档:
deepseek如此火爆,保姆级教程教你如何使用
如果感觉内容对你有帮助,欢迎点赞、转发、关注~
也欢迎搜索微信公众号:AI牛码,获取更多内容

















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









