







对于二分类问题,分类器在测试数据集上的预测要么对要么错,4种情况出现的总数分别记作:
1. TP(True Positive)————将正类预测为正类数
2. FN(False Negative)————将正类预测为负类数
3. FP(False Positive)————将负类预测为正类数
4. TN(True Negative)————将负类预测为负类
TP,FN,FP,TN有些难记,可以这样理解,T代表分类正确,F代表分类错误,后面的P和N分别代表预测成的类别分别是正类和负类。
对于二分类问题常用的指标有精确率(Precision),召回率(Recall),真阳性率(True Positive Rate),假阳性率(False Positive Rate),ROC(Receiver Operator Charastic),AUC(Area Under Curve)
精确率:P=TP/(TP+FP)
召回率:R=TP/(TP+FN)
真阳性率:TPR=TP/(TP+FN) 分类器预测的正类中实际正类占所有实际正类的比例,也称击中率,灵敏度
假阳性率:FPR=FP/(FP+TN) 分类器预测的正类中实际上是负类的个数占所有实际负类的比例,也称虚报率
ROC: 受试者工作特征(Receiver Operator Characteristic),ROC曲线以家阳性率为横坐标,真阳性率为纵坐标,得此名的原因在于曲线上个点反映相同的感受性,它们都是对同一信号刺激的反应。
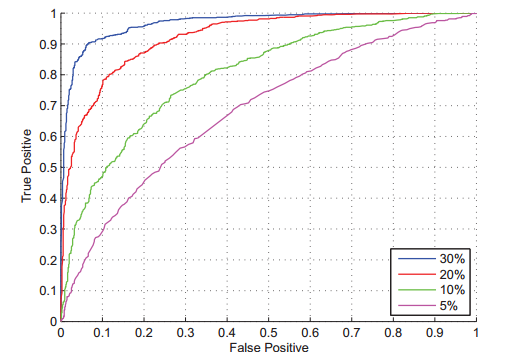
显然,我们希望真阳性率越接近1越好,假阳性率越接近0越好,反映在图中就是ROC曲线越靠近左上角,分类的准确率越高。最靠近左上角的ROC曲线上的点是错误最少的最好阈值。ROC有一个非常优良的特性:当测试样本集中正负样本的比例发生变化时,ROC曲线能够保持不变。这对于解决正负样本比例不平衡且测试样本集正负比例发生变化的现实问题很有帮助。
AUC:Area Under Curve,曲线下的面积,数值越大分类器性能越好。实际上AUC是一个概率值,指的是将一个正样本放入分类器输出的score值将正样本排在负样本前面的概率。















 5531
5531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









