







摘要
三维目标通常表示为点云中的3D框。这种表示模仿了经过充分研究的基于图像的2D边界框检测,但也带来了额外的挑战。3D世界中的目标不遵循任何特定的方向,基于框的检测器难以枚举所有方向或将轴对齐的边界框拟合到旋转的目标。在本文中,我们建议将3D目标表示、检测和跟踪为点。我们的框架CenterPoint首先使用关键点检测器检测目标的中心,然后回归到其他属性,包括3D大小、3D方向和速度。在第二阶段,它使用目标上的附加点特征来细化这些估计。在CenterPoint中,3D目标跟踪简化为贪婪的最近点匹配。由此产生的检测和跟踪算法简单、高效且有效。 CenterPoint在nuScenes基准测试中实现了3D检测和跟踪的最佳性能,单个模型的 NDS为65.5和AMOTA为63.8。在Waymo开放数据集上,CenterPoint大大优于所有以前的单一模型方法,并且在所有仅使用激光雷达的提交中排名第一。代码和预训练模型可在https://github.com/tianweiy/CenterPoint获得。
1.介绍
强大的3D感知是许多最先进的驾驶系统的核心成分[1, 50]。与经过充分研究的2D检测问题相比,点云上的3D 检测提出了一系列有趣的挑战:首先,点云是稀疏的,并且3D空间的大部分区域都没有测量值[23]。其次,生成的输出是一个三维框,通常与任何全局坐标系都没有很好地对齐。第三,3D目标的大小、形状和纵横比范围很广,例如,在交通领域,自行车接近平面,公共汽车和豪华轿车拉长,行人高大。 2D和3D检测之间的这些显着差异使得两个领域之间的思想转移更加困难[45,47,60]。关键在于轴对齐的2D框[16, 17]不能很好地代表自由形式的3D目标。一种解决方案可能是为每个目标方向分类不同的模板(anchor)[58, 59],但这会不必要地增加计算负担,并可能引入大量潜在的误报检测。我们认为,连接2D和3D领域的主要潜在挑战在于目标的这种表示。
在本文中,我们展示了将目标表示为点(图 1)如何极大地简化3D识别。我们的two-stage 3D检测器CenterPoint使用关键点检测器[64]找到目标的中心及其属性,第二阶段改进所有估计。具体来说,CenterPoint 使用标准的基于激光雷达的backbone网络,即VoxelNet[56, 66]或PointPillars[28],来构建输入点云的表示。然后,它将这种表示扁平化为俯视图视图,并使用标准的基于图像的关键点检测器来查找目标中心[64]。对于每个检测到的中心,它会从中心位置的点特征回归到所有其他目标属性,例如3D大小、方向和速度。此外,我们使用轻量级的第二阶段来细化目标位置。第二阶段在估计的目标3D边界框的每个面的3D中心提取点特征。它恢复了由于跨步和有限的感受野而丢失的局部几何信息,并以较小的成本带来了不错的性能提升。
图1:我们提出了一个基于中心的框架来表示、检测和跟踪目标。先前基于锚的方法使用相对于自我车辆坐标的轴对准锚。当车辆在直路上行驶时,基于anchor的方法和基于中心的方法都能够准确地检测到物体(上图)。然而,在安全关键的左转(底部),基于anchor的方法很难适应轴对齐的边界框旋转目标。我们的基于中心的模型通过旋转不变点精确地检测物体。

基于中心的表示有几个关键优势:首先,与边界框不同,点没有内在的方向。这极大地减少了目标检测器的搜索空间,同时允许backbone学习目标的旋转不变性和它们相对旋转的旋转等效性。其次,基于中心的表示简化了跟踪等下游任务。如果目标是点,那么轨迹就是空间和时间的路径。 CenterPoint预测目标在连续帧之间的相对偏移(速度),然后贪婪地链接起来。第三,基于点的特征提取使我们能够设计一个比以前的方法快得多的有效的two-stage细化模块[44-46]。
我们在两个流行的大型数据集上测试了我们的模型:Waymo Open数据集[48]和nuScenes数据集[6]。我们表明,在不同的backbones[28,56,66,67]下,从框表示到基于中心的表示的简单切换产生3-4个mAP增加的3D检测。两阶段优化进一步带来额外的2 mAP提升,而计算开销很小(<10%)。我们最好的单一模型在Waymo上获得了71.8和66.4的2级mAPH,在nuScenes上达到了58.0 mAP和65.5 NDS,在这两个数据集上的表现都好于所有已发表的方法。值得注意的是,在NeurIPS 2020 nuScenes 3D检测挑战赛中,前4名获奖作品中有3名采用了CenterPoint。对于3D跟踪,我们的模型在nuScenes上的性能为63.8 AMOTA,比以前最先进的模型高8.8 AMOTA。在Waymo 3D跟踪基准上,我们的模型对车辆和行人的跟踪分别达到了59.4和56.6级2 MOTA,比以前的方法提高了50%。我们的端到端3D检测和跟踪系统几乎实时运行,Waymo上的FPS为11 FPS,nuScenes上为16 FPS。
2.相关工作
2D目标检测从图像输入预测轴算法边界框。RCNN系列[16, 17, 21, 43]找到与类别无关的候选边界框,然后对其进行分类和细化。 YOLO[42]、SSD[33]和RetinaNet[32]直接找到特定类别的候选框,回避后面的分类和细化。基于中心的检测器,例如CenterNet[64]或CenterTrack[63],直接检测隐式目标中心点,无需候选框。许多3D目标检测器[20, 45, 47, 60]从这些2D目标检测器演变而来。我们认为,与轴对齐框相比,基于中心的表示[63, 64]更适合3D应用。
3D目标检测旨在预测三维旋转边界框[15、28、31、39、56、60、61]。它们不同于输入编码器上的二维检测器。 Vote3Deep[12]利用以特征为中心的投票[51]来有效处理等间距3D体素上的稀疏3D点云。 VoxelNet [66]在每个体素内部使用PointNet[40]生成统一的特征表示,具有3D稀疏卷积[18]和2D卷积的头部从中产生检测。 SECOND[56]简化了VoxelNet并加速了稀疏的3D卷积。 PIXOR[57]将所有点投影到具有3D占用率和点强度信息的2D特征图上,以消除昂贵的3D卷积。PointPillars[28]用柱表示代替了所有的体素计算,即每个地图位置一个单独的细长体素,提高了backbone效率。MVF[65]和Pillar-od[52]结合多个视图特征来学习更有效的柱表示。我们的贡献集中在输出表示上,并且与任何3D编码器兼容并且可以改进它们。
VoteNet[38]通过使用点特征采样和分组的投票聚类来检测目标。相比之下,我们通过中心点处的特征直接回归到3D边界框,而无需投票。Wong等人[55]和Chen等人[8]在目标中心区域使用类似的多点表示法(即point-anchors)并回归到其他属性。我们对每个目标使用单个正单元,并使用关键点估计损失。
Two-stage 3D目标检测。最近的工作考虑将RCNN风格的2D检测器直接应用于3D领域[9, 44–46, 61]。他们中的大多数应用RoIPool[43]或RoIAlign[21]来聚合3D空间中特定于RoI的特征,使用基于PointNet的点[45]或体素[44]特征提取器。这些方法从3D激光雷达测量值(点和体素)中提取区域特征,由于大量点而导致运行时间过长。相反,我们从中间特征图中提取5个表面中心点的稀疏特征。这使得我们的第二阶段非常高效并保持有效。
3D目标跟踪。许多二维跟踪算法[2, 4, 27, 54]都可以轻易地跟踪三维物体。然而,基于3D卡尔曼滤波器[10, 53]的专用3D跟踪器仍然具有优势,因为它们更好地利用了场景中的3D运动。在这里,我们采用了一种更简单的方法,遵循CenterTrack[63]。我们使用速度估计和基于点的检测来通过多个帧跟踪目标的中心。该跟踪器比专用3D跟踪器[10, 53]更快、更准确。
3.Preliminaries
2D CenterNet[64]将目标检测改写为关键点估计。它采用输入图像并为 K K K个类别中的每一个预测一个 w × h w × h w×h heatmap Y ^ ∈ [ 0 , 1 ] w × h × K \hat{Y} \in[0,1]^{w \times h \times K} Y^∈[0,1]w×h×K。输出热图中的每个局部最大值(即值大于其8个邻域的像素)对应于检测到的目标的中心。为了检索2D框,CenterNet回归到所有类别之间共享的尺寸图 S ^ ∈ R w × h × 2 \hat{S} \in \mathbb{R}^{w \times h \times 2} S^∈Rw×h×2。对于每个检测目标,尺寸图将其宽度和高度存储在中心位置。CenterNet架构使用标准的全卷积图像backbone,并在顶部添加了密集预测头。在训练期间,CenterNet学习在每个类 c i ∈ { 1 … K } c_{i} \in\{1 \ldots K\} ci∈{1…K}的每个注释目标中心 q i \mathbf{q}_{i} qi处使用渲染的高斯核预测heatmaps,并回归到带注释边界框中心的目标大小 S S S。为了弥补backbone架构跨步引入的量化误差,CenterNet还回归到局部偏移 O ^ \hat{O} O^。
在测试时,检测器产生K个heatmaps和密集的类不可知回归图。heatmaps中的每个局部最大值(峰值)对应一个目标,置信度与峰值处的热图值成正比。对于每个检测到的目标,检测器从对应峰值位置的回归图中检索所有回归值。根据应用领域,可能需要非极大值抑制 (NMS)。
3D检测令 P = { ( x , y , z , r ) i } \mathcal{P}=\left\{(x, y, z, r)_{i}\right\} P={(x,y,z,r)i}为3D位置 ( x , y , z ) (x, y, z) (x,y,z)和反射率 r r r测量的无序点云。3D目标检测旨在从该点云预测鸟瞰图中的一组3D目标边界框 B = { b k } \mathcal{B}=\left\{b_{k}\right\} B={bk}。每个边界框 b = ( u , v , d , w , l , h , α ) b=(u, v, d, w, l, h, \alpha) b=(u,v,d,w,l,h,α)由相对于目标地平面的中心位置 ( u , v , d ) (u, v, d) (u,v,d)和3D大小 ( w , l , h ) (w, l, h) (w,l,h)组成,以及由偏航角 α α α表示的旋转。不失一般性,我们使用以 ( 0 , 0 , 0 ) (0, 0, 0) (0,0,0)处的传感器和yaw = 0的传感器为中心的坐标系。
现代3D物体检测器[20, 28, 56, 66]使用3D编码器将点云量化为常规bins。然后,基于点的网络[40]提取bin所有点的特征。然后3D编码器将这些特征汇集到它的主要特征表示中。大多数计算发生在backbone网络中,它仅在这些量化和池化的特征表示上运行。backbone网络的输出是在地图-视图参考帧中具有F个通道宽度为W和长度为L的地图-视图特征图 M ∈ R W × L × F \mathbf{M} \in \mathbb{R}^{W \times L \times F} M∈RW×L×F。宽度和高度都与单个体素bins的分辨率和骨干网络的步幅直接相关。常见的主干包括VoxelNet[56, 66]和PointPillars[28]。
使用地图视图特征图 M \mathbf{M} M,检测头,最常见的是one-[32]或two-stage[43]边界框检测器,然后从锚定在此overhead feature-map上的一些预定义边界框产生目标检测。由于3D边界框具有各种尺寸和方向,基于anchor的3D检测器难以将轴对齐的2D框拟合到3D目标。此外,在训练过程中,以前的基于anchor的3D检测器依赖2D Box IoU进行目标分配[44, 56],这为不同类别或不同数据集选择正/负阈值带来了不必要的负担。在下一节中,我们将展示如何基于点表示构建一个原则性的3D目标检测和跟踪模型。我们引入了一种新颖的基于中心的检测头,但依赖于现有的3D主干(VoxelNet或PointPillars)。
4.CenterPoint
图2显示了CenterPoint模型的总体框架。令 M ∈ R W × H × F \mathbf{M} \in \mathbb{R}^{W \times H \times F} M∈RW×H×F为3D backbone的输出。 CenterPoint的第一阶段预测特定类别的heatmap、目标大小、子体素位置细化、旋转和速度。所有输出都是密集预测。
图2:我们的CenterPoint框架概述。我们依赖于从激光雷达点云中提取地图视图特征表示的标准3D backbone。然后,2D CNN架构检测头找到目标中心并使用中心特征回归到完整的3D边界框。此框预测用于提取估计的3D边界框每个面的3D中心的点特征,将其传递到MLP以预测IoU引导的置信度得分和框回归细化。
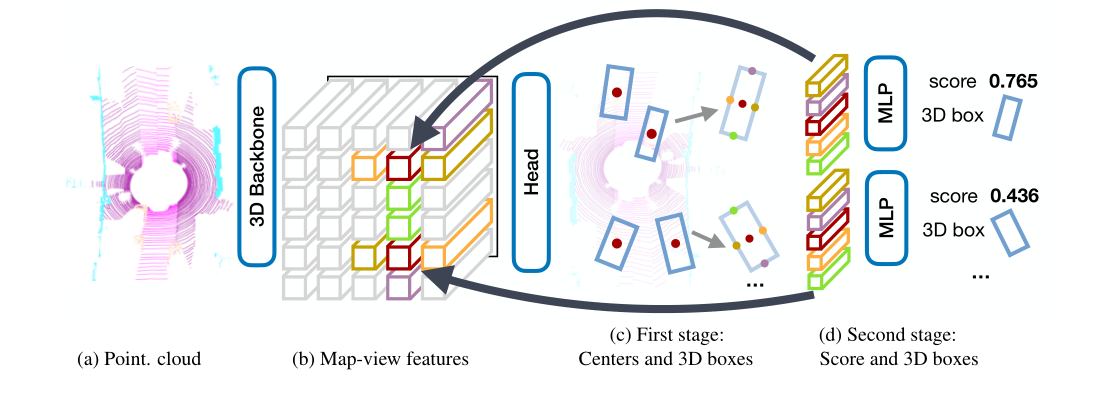
中心heatmap头。 center-head的目标是在任何检测到的目标的中心位置产生一个热图峰值。这个头产生一个 K K K通道热图 Y ^ \hat{Y} Y^,每个 K K K类一个通道。在训练期间,它的目标是通过将带注释的边界框的3D中心投影到地图视图中产生的2D高斯。我们使用焦点损失[29, 64]。自上而下的地图视图中的目标比图像中的目标稀疏。在地图视图中,距离是绝对的,而图像视图会通过透视扭曲它们。考虑一个道路场景,在地图视图中车辆占据的区域很小,但在图像视图中,一些大物体可能占据大部分屏幕。此外,透视投影中深度维度的压缩自然地使目标中心在图像视图中彼此更接近。遵循CenterNet[64]的标准监督会产生非常稀疏的监督信号,其中大多数位置都被视为背景。为了解决这个问题,我们通过扩大在每个ground truth目标中心呈现的高斯峰值来增加对目标heatmap Y Y Y的positive监督。具体来说,我们将高斯半径设置为 σ = max ( f ( w l ) , τ ) \sigma=\max (f(w l), \tau) σ=max(f(wl),τ),其中 τ = 2 \tau=2 τ=2是允许的最小高斯半径, f f f是CornerNet[29]中定义的半径函数。这样,CenterPoint保持了基于中心的目标分配的简单性;该模型从附近的像素中获得更密集的监督。
回归头。我们在目标的中心特征处存储了几个目标属性:子体素位置细化 o ∈ R 2 o \in \mathbb{R}^{2} o∈R2、地高 h g ∈ R h_{g} \in \mathbb{R} hg∈R、3D尺寸 s ∈ R 3 s \in \mathbb{R}^{3} s∈R3和偏航旋转角 ( sin ( α ) , cos ( α ) ) ∈ R 2 (\sin (\alpha), \cos (\alpha)) \in \mathbb{R}^{2} (sin(α),cos(α))∈R2。子体素位置细化减少了来自backbone网络的体素化和跨步的量化误差。 地面高度 h g h_{g} hg有助于在3D中定位目标,并添加由mapview投影移除的缺失高度信息。方向预测使用偏航角的正弦和余弦作为连续回归目标。结合框大小,这些回归头提供了3D边界框的完整状态信息。每个输出都使用自己的头部。在训练时,仅使用L1回归损失监督ground truth中心。我们回归对数大小以更好地处理各种形状的框。在推理时,我们通过在每个目标的峰值位置索引密集回归头输出来提取所有属性。
速度头和跟踪。为了随时间跟踪目标,我们学习预测每个检测到的目标的二维速度估计 V ∈ R 2 \mathbf{V} \in \mathbb{R}^{2} V∈R2,作为附加的回归输出。速度估计是特殊的,因为它需要当前和先前时间步的两个输入地图视图。它预测当前帧和过去帧之间的目标位置差异。像其他回归目标一样,速度估计也是使用当前时间步长的ground truth目标位置处的L1损失来监督的。
在推理时,我们使用这个偏移量以贪婪的方式将当前检测与过去的检测相关联。具体来说,我们通过应用negative速度估计将当前帧中的目标中心投影回前一帧,然后通过最近距离匹配将它们与被跟踪的目标进行匹配。在SORT[4]之后,在删除它们之前,我们保留不匹配的轨迹直到 T = 3 T=3 T=3帧。我们用最后已知的速度估计来更新每个不匹配的轨迹。详细的跟踪算法框图见附录。
CenterPoint将所有heatmap和回归损失结合在一个共同目标中,并共同优化它们。它简化并改进了以前基于anchor的3D检测器(参见实验)。然而,目前物体的所有属性都是从物体的中心特征推断出来的,这可能不包含足够的信息来进行准确的目标定位。例如,在自动驾驶中,传感器通常只能看到物体的侧面,而不能看到它的中心。接下来,我们通过使用带有轻量级点特征提取器的第二个细化阶段来改进CenterPoint。
4.1.Two-Stage CenterPoint
我们使用不变的中心点作为第一阶段。第二阶段从backbone的输出中提取额外的点特征。我们从预测边界框的每个面的3D中心提取一个点特征。请注意,边界框中心、顶面和底面中心都投影到地图视图中的同一点。因此,我们只考虑四个向外的框面和预测的目标中心。对于每个点,我们使用双线性插值从backbone地图视图输出 M M M中提取一个特征。接下来,我们连接提取的点特征并将它们传递给MLP。第二阶段在one-stage CenterPoint的预测结果之上预测与类别无关的置信度分数和框细化。
对于与类别无关的置信度分数预测,我们遵循[26, 30, 44, 46]并使用由框的3D IoU引导的分数目标和相应的ground truth边界框:
I
=
min
(
1
,
max
(
0
,
2
×
I
o
U
t
−
0.5
)
)
(
1
)
I=\min \left(1, \max \left(0,2 \times I o U_{t}-0.5\right)\right) \quad\quad\quad\quad(1)
I=min(1,max(0,2×IoUt−0.5))(1)
其中
I
o
U
t
I o U_{t}
IoUt是第
t
t
t个proposal框和ground-truth的IoU。训练由二元交叉熵损失监督:
L
s
c
o
r
e
=
−
I
t
log
(
I
^
t
)
−
(
1
−
I
t
)
log
(
1
−
I
^
t
)
(
2
)
L_{s c o r e}=-I_{t} \log \left(\hat{I}_{t}\right)-\left(1-I_{t}\right) \log \left(1-\hat{I}_{t}\right) \quad(2)
Lscore=−Itlog(I^t)−(1−It)log(1−I^t)(2)
其中 I ^ t \hat{I}_{t} I^t是预测的置信度得分。在推断期间,我们直接使用来自一阶段中心点的类别预测,并将最终置信度得分计算为两个得分的几何平均值 Q ^ t = Y ^ t ∗ I ^ t \hat{Q}_{t}=\sqrt{\hat{Y}_{t} * \hat{I}_{t}} Q^t=Y^t∗I^t,其中, Q ^ t \hat{Q}_{t} Q^t是目标t的最终预测置信度, Y ^ t = max 0 ≤ k ≤ K Y ^ p , k \hat{Y}_{t}=\max _{0 \leq k \leq K} \hat{Y}_{p, k} Y^t=max0≤k≤KY^p,k和 I ^ t \hat{I}_{t} I^t分别是目标t的第一阶段和第二阶段置信度。
对于框回归,模型预测在第一阶段proposals,之上的改进,我们用L1损失训练模型。我们的two-stage CenterPoint简化并加速了之前使用昂贵的基于PointNet的特征提取器和RoIAlign操作的two-stage 3D检测器[44, 45]。
4.2.Architecture
所有第一阶段的输出共享第一个3 × 3卷积层、批量归一化[25]和ReLU。然后每个输出使用它自己的两个3 × 3卷积分支,由批归一化和 ReLU 分隔。我们的第二阶段使用共享的两层MLP,具有批归一化、ReLU和Dropout[22],丢弃率为0.3,然后是三个全连接层的两个分支,一个用于置信度得分,一个用于框回归预测。
5.实验
我们在Waymo Open Dataset和nuScenes数据集上评估CenterPoint。我们使用两个3D编码器实现CenterPoint:V oxelNet[56,66,67]和PointPillars[28],分别称为CenterPoint-Voxel和CenterPoint-Pillar。
Waymo开放数据集。 Waymo开放数据集[48]包含798个训练序列和202个车辆和行人验证序列。使用64车道激光雷达捕获点云,每0.1秒产生约18万个激光雷达点。官方的3D检测评估指标包括标准的3D边界框平均精度(mAP)和航向精度加权的mAP(mAPH)。 mAP和mAPH基于车辆的0.7和行人的0.5的IoU阈值。对于3D跟踪,官方指标是多目标跟踪精度 (MOTA) 和多目标跟踪精度 (MOTP) [3]。官方评估工具包还提供了两个难度级别的性能细分:LEVEL 1用于具有超过5个激光雷达点的框,而LEVEL 2用于具有至少一个激光雷达点的框。
我们的Waymo模型对X和Y轴使用[−75.2m, 75.2m]的检测范围,对Z轴使用[−2m, 4m]的检测范围。CenterPoint-Voxe使用PV-RCNN[44]之后的(0.1m, 0.1m, 0.15m)体素尺寸,而CenterPoint-Pillar使用(0.32m, 0.32m)的网格尺寸。
nuScene数据集。 nuScenes[6]包含1000个驱动序列,分别有700、150、150个序列用于训练、验证和测试。每个序列大约 20秒长,激光雷达频率为20FPS。该数据集为每个激光雷达帧提供校准的车辆姿态信息,但仅每十帧(0.5 秒)提供一次框注释。 nuScenes使用32车道激光雷达,每帧产生大约30k点。总共有28k、6k、6k、带注释的帧,分别用于训练、验证和测试。注释包括10个具有长尾分布的类。官方评估指标是各类别的平均值。对于3D检测,主要指标是平均平均精度(mAP)[13]和nuScenes 检测分数(NDS)。 mAP使用 < 0.5m、1m、2m、4m的鸟瞰中心距,而不是标准的box-overlap。 NDS 是mAP和其他属性量的加权平均值,包括平移、比例、方向、速度和其他框属性[6]。在我们提交测试集后,nuScenes团队添加了一个新的神经规划指标(PKL)[37]。PKL指标根据规划者路线的KL散度(使用3D检测)和ground truth轨迹来衡量3D目标检测对下游自动驾驶任务的影响。因此,我们还报告了在测试集上评估的所有方法的PKL指标。
对于3D跟踪,nuScenes使用AMOTA[53],它惩罚ID切换、假阳性和假阴性,并在各种召回阈值之间进行平均。
对于nuScenes上的实验,我们将X和Y轴的检测范围设置为[51.2m,51.2m],Z轴的检测范围设置为[5m,3m]。CenterPoint-Voxel使用(0.1m,0.1m,0.2m)体素大小,CenterPoint-Pillars使用(0.2m,0.2m)网格。
训练和推理。我们使用与先前工作相同的网络设计和训练计划[44, 67]。有关详细的超参数,请参阅补充。在两阶段中心点的训练过程中,我们从第一阶段的预测中以1:1的正负比[43]随机抽取128个框。如果proposal与至少0.55 IoU[44]的ground truth注释重叠,则该proposal是肯定的。在推理过程中,我们在非极大值抑制(NMS)之后对前500个预测运行第二阶段。推理时间是在Intel Core i7 CPU和Titan RTX GPU上测量的。
5.1.主要结果
3D检测。我们首先在Waymo和nuScenes的测试集上展示我们的3D检测结果。两个结果都使用单个CenterPoint-Voxel模型。表1和表2总结了我们的结果。在Waymo测试集上,我们的模型在车辆检测方面达到了71.8的2级mAPH,在行人检测方面达到了66.4的2级mAPH,超过了之前的方法,车辆的mAPH为7.1%,行人的mAPH为 10.6%。在nuScenes(表2)上,我们的模型以5.2%的mAP和2.2%的NDS的多尺度输入和多模型集成优于去年的挑战冠军CBGS[67]。我们的模型也快得多,如下所示。补充材料中包含按类别细分。我们的模型在所有类别中都显示出一致的性能改进,并且在小类别(交通锥+5.6mAP)和极端纵横比类别(自行车 +6.4 mAP和工程车辆+7.0mAP)中显示出更显着的改进。更重要的是,我们的模型明显优于神经平面度量(PKL)下的所有其他提交,PKL是组织者在我们提交排行榜后评估的隐藏度量。这突出了我们框架的泛化能力。
表1:Waymo测试集上3D检测的最新比较。我们展示了1级和2级基准的mAP和mAPH。
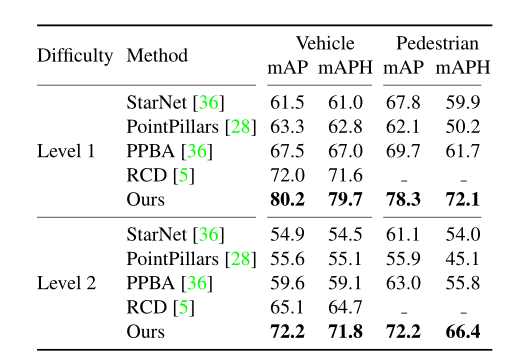
表2:nuScenes测试集上3D检测的最新比较。我们展示了nuScenes检测分数(NDS)和平均平均精度(mAP)。

表3:Waymo测试集上3D跟踪的最新比较。我们展示了MOTA和MOTP。 ↑ 代表越高越好,↓ 代表越低越好。
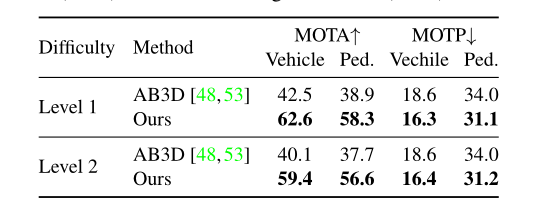
3D追踪 表3显示了CenterPoint在Waymo测试集上的跟踪性能。我们在第4节中描述的基于速度的最近距离匹配显着优于Waymo 论文[48]中使用基于卡尔曼滤波器的跟踪器[53]中的官方跟踪基线。我们观察到车辆和行人跟踪的MOTA分别提高了19.4和18.9。在nuScenes(表 4)上,我们的框架优于最后一个挑战获胜者Chiu等人。[10]8.8AMOTA。值得注意的是,我们的跟踪不需要单独的运动模型,并且运行时间可以忽略不计,检测时间为1毫秒。
表4:nuScenes测试集上3D跟踪的最新比较。我们展示了AMOTA、误报数(FP)、误报数(FN)、id切换(IDS)和每个类别的AMOTA。 ↑代表越高越好,↓代表越低越好。
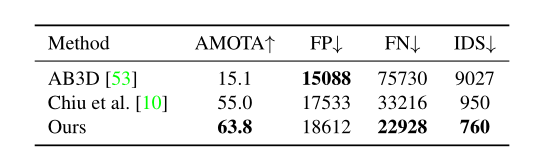
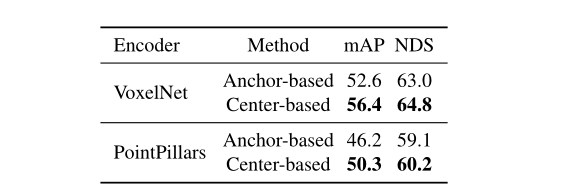
表5:Waymo验证中基于anchor和基于中心的3D检测方法的比较。我们显示了每个级别和平均LEVEL 2的mAPH。
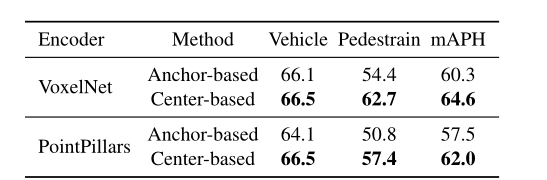
表6:nuScenes验证中基于anchor和基于中心的3D检测方法的比较。我们展示了平均精度(mAP)和nuScenes检测分数(NDS)。
5.2.消融研究
Center-based vs Anchor-based 我们首先将我们的基于中心的one-stage检测器与其基于anchor的对应物进行比较[28, 56, 67]。在Waymo上,我们遵循最先进的PV-RCNN[44]来设置anchor超参数:我们每个位置使用两个anchor,分别为0°和90°;车辆的正/负IoU阈值设置为0.55/0.4,行人设置为0.5/0.35。在nuScenes上,我们遵循最后挑战获胜者CBGS[67]的anchor分配策略。所有其他参数与我们的CenterPoint模型相同。
如表5所示,在Waymo数据集上,简单地从锚点切换到我们的中心,VoxelNet和PointPillars编码器分别提高了4.3mAPH和4.5mAPH。在nuScenes(表 6)上,CenterPoint在不同的主干上将基于anchor的对应物提高了3.8-4.1mAP和1.1-1.8 NDS。为了了解改进的来源,我们进一步展示了基于Waymo验证集上的目标大小和方向角度的不同子集的性能细分。
我们首先根据它们的航向角将ground truth实例分为三个bins:0°到15°、15°到30°和30°到45°。该部门测试检测器在检测严重旋转的框方面的性能,这对于自动驾驶的安全部署至关重要。我们还将数据集分为三个部分:小、中和大,每个部分包含 1/3个整体的ground truth框。
表7和表8总结了结果。当框旋转或偏离平均框大小时,我们的基于中心的检测器的性能比基于anchor的基线要好得多,这证明了模型在检测目标时捕获旋转和大小不变性的能力。这些结果令人信服地突出了使用基于点的3D目标表示的优势。
One-stage vs. Two-stage 在表9中,我们展示了在Waymo验证中使用2D CNN特征的单阶段和两阶段CenterPoint 模型之间的比较。具有多个中心特征的两阶段细化以较小的开销(6ms-7ms)大大提高了两个3D编码器的精度。我们还与在RoI[44, 46]中密集采样6 × 6点的RoIAlign进行比较,我们基于中心的特征聚合实现了相当的性能,但更快更简单。
体素量化限制了两阶段(two-stage)CenterPoint对PointPillars行人检测的改进,因为行人通常只驻留在模型输入中的1个像素中。
在我们的实验中,两阶段(Two-stage)细化并没有对nuScenes上的单阶段(single-stage)CenterPoint模型带来改进。我们认为原因是nuScenes数据集使用32车道激光雷达,每帧产生约30k激光雷达点,约为Waymo数据集中点数的1/6 ,这限制了两阶段(Two-stage)细化的潜在改进。在之前的两阶段方法(如PointRCNN[45]和PV-RCNN[44])中也观察到了类似的结果。
表7:基于锚点和基于中心的方法检测不同航向角目标的比较。第2行和第3行列出了旋转角度的范围及其对应的目标部分。我们在 Waymo验证中显示了这两种方法的LEVEL 2 mAPH。
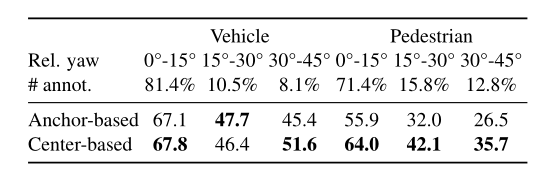
表8:目标大小对基于anchor和基于中心的方法性能的影响。我们展示了不同大小范围内目标的每类LEVEL 2 mAPH:小33%、中33%和大33%
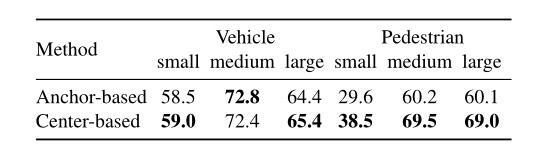
表9:在Waymo验证中使用单级、具有3D中心特征的两级以及具有3D中心和表面中心特征的两级比较VoxelNet和PointPillars编码器的3D LEVEL 2 mAPH。
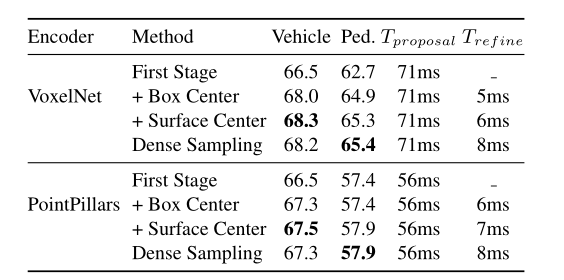
表10:两阶段细化模块的不同特征组件的消融研究。 VSA代表Voxel Set Abstraction,这是PV RCNN[44]中使用的特征聚合方法。 RBF使用径向基函数对3个最近邻进行插值。我们在Waym 验证中使用LEVEL 2 mAPH比较鸟瞰图和3D体素特征。
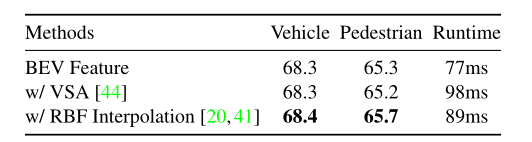
不同特征成分的影响 在我们的两阶段CenterPoint模型中,我们仅使用2D CNN特征图中的特征。然而,以前的方法建议也利用体素特征进行第二阶段细化[44,46]。在这里,我们与两个体素特征提取baselines进行比较:
Voxel-Set Abstraction. PV-RCNN[44]提出了Voxel-Set Abstraction(VSA)模块,它扩展了PointNet++[41]的集合抽象层,以聚合固定半径球中的体素特征。
径向基函数(RBF)插值。 PointNet++[41]和SA-SSD[20]使用径向基函数从三个最近的非空3D特征体积聚合网格点特征。
对于这两个基线,我们使用它们的官方实现将鸟瞰图特征与体素特征相结合。表10总结了结果。它表明鸟瞰图特征足以获得良好的性能,同时与文献[20, 41, 44]中使用的体素特征相比更有效。
为了与之前未对Waymo测试进行评估的工作进行比较,我们还在表11中报告了Waymo验证拆分的结果。我们的模型大大优于所有已发布的方法,特别是对于具有挑战性的行人类别(+18.6 mAPH)2级数据集,其中框仅包含一个激光雷达点。
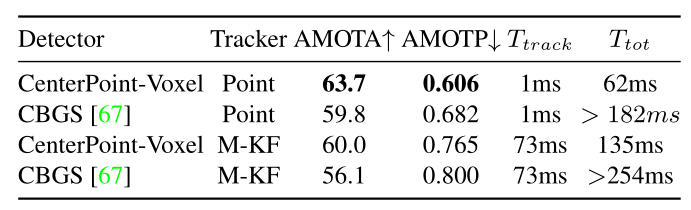
3D追踪。表12显示了3D跟踪在nuScenes验证上的消融实验。我们与去年的挑战冠军Chiu等人进行了比较。[10]它使用基于马氏距离的卡尔曼滤波器来关联CBGS的检测结果[67]。我们将评估分解为检测器和跟踪器,以使比较严格。给定相同的检测目标,使用我们简单的基于速度的最近点距离匹配比基于卡尔曼滤波器的马氏距离匹配[10]高3.7 AMOTA(第1行与第3行和第2行与第 4行)。有两个改进来源:1)我们使用学习的点速度对目标运动进行建模,而不是使用卡尔曼滤波器对3D边界框动态建模; 2) 我们通过中心点距离而不是框状态的马氏距离或3D边界框IoU来匹配目标。更重要的是,我们的跟踪是一个简单的最近邻匹配,没有任何隐藏状态计算。这节省了3D卡尔曼滤波器[10]的计算开销(73ms vs. 1ms)。
图3:Waymo验证中CenterPoint的示例定性结果。我们以蓝色显示原始点云,以绿色边界框显示我们检测到的目标,以红色显示边界框内的激光雷达点。
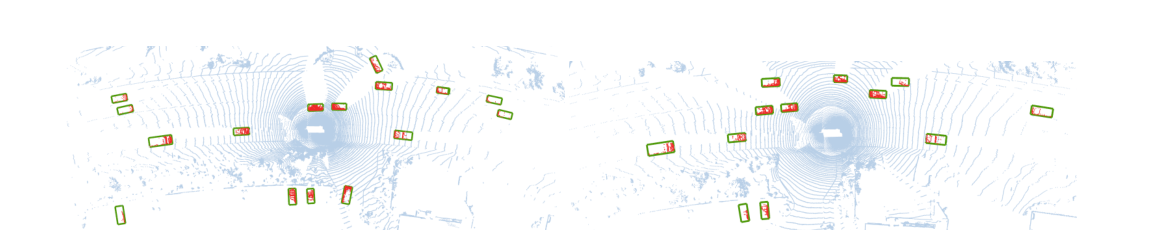
表11:Waymo验证中3D检测的最新比较。
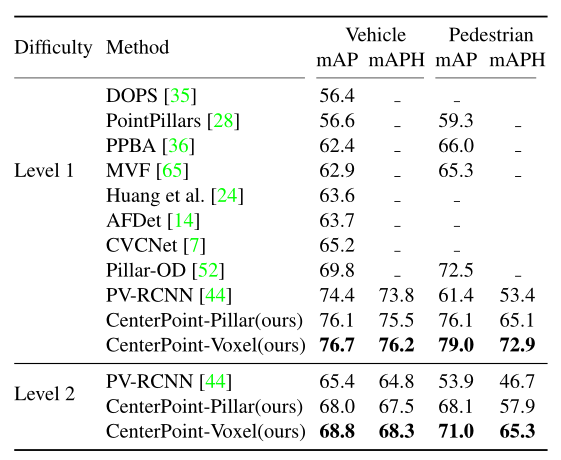
表12:对nuScenes验证进行3D跟踪的消融研究。我们展示了不同检测器和跟踪器的组合。 CenterPoint-* 是我们的探测器。 Point是我们提出的跟踪器。 M-KF是基于Mahalanobis距离的卡尔曼滤波器的缩写,用于上届挑战赛冠军Chiu等人。[10]。 T t r a c k T_{track} Ttrack表示跟踪时间, T t o t T_{tot} Ttot表示检测和跟踪的总时间。
6.结论
我们提出了一个基于中心的框架,用于从激光雷达点云同时检测和跟踪3D目标。我们的方法使用一个标准的3D点云编码器,头部有几个卷积层来生成鸟瞰热图和其他密集回归输出。检测是一种简单的局部峰值提取和细化,而跟踪是一种最近距离匹配。 CenterPoint简单、近乎实时,并在Waymo和nuScenes基准测试中实现了最先进的性能。
参考文献
[1] Mayank Bansal, Alex Krizhevsky, and Abhijit Ogale. Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst. RSS, 2019. 1
[2] Philipp Bergmann, Tim Meinhardt, and Laura Leal-Taixe. Tracking without bells and whistles. ICCV, 2019. 2
[3] Keni Bernardin, Alexander Elbs, and Rainer Stiefelhagen. Multiple object tracking performance metrics and evaluation in a smart room environment. Citeseer. 5
[4] Alex Bewley, Zongyuan Ge, Lionel Ott, Fabio Ramos, and Ben Upcroft. Simple online and realtime tracking. ICIP, 2016. 2, 4
[5] Alex Bewley, Pei Sun, Thomas Mensink, Dragomir Anguelov, and Cristian Sminchisescu. Range conditioned dilated convolutions for scale invariant 3d object detection. arXiv preprint arXiv:2005.09927, 2020. 6
[6] Holger Caesar, V arun Bankiti, Alex H. Lang, Sourabh V ora, V enice Erin Liong, Qiang Xu, Anush Krishnan, Y u Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. CVPR, 2020. 2, 5, 11
[7] Qi Chen, Lin Sun, Ernest Cheung, Kui Jia, and Alan Y uille. Every view counts: Cross-view consistency in 3d object detection with hybrid-cylindrical-spherical voxelization. NeurIPS, 2020. 6, 8, 12
[8] Qi Chen, Lin Sun, Zhixin Wang, Kui Jia, and Alan Y uille. Object as hotspots: An anchor-free 3d object detection approach via firing of hotspots. ECCV, 2020. 2
[9] Yilun Chen, Shu Liu, Xiaoyong Shen, and Jiaya Jia. Fast point r-cnn. ICCV, 2019. 2
[10] Hsu-kuang Chiu, Antonio Prioletti, Jie Li, and Jeannette Bohg. Probabilistic 3d multi-object tracking for autonomous driving. arXiv:2001.05673, 2020. 2, 3, 6, 8
[11] Jifeng Dai, Haozhi Qi, Y uwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. Deformable convolutional networks. ICCV, 2017. 11
[12] Martin Engelcke, Dushyant Rao, Dominic Zeng Wang, Chi Hay Tong, and Ingmar Posner. V ote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. ICRA, 2017. 2
[13] Mark Everingham, Luc V an Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. IJCV, 2010. 5
[14] Runzhou Ge, Zhuangzhuang Ding, Yihan Hu, Y u Wang, Sijia Chen, Li Huang, and Y uan Li. Afdet: Anchor free one stage 3d object detection. arXiv preprint arXiv:2006.12671, 2020. 8
[15] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. CVPR, 2012. 2
[16] Ross Girshick. Fast r-cnn. ICCV, 2015. 1, 2
[17] Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. CVPR, 2014. 1, 2
[18] Benjamin Graham, Martin Engelcke, and Laurens van der Maaten. 3d semantic segmentation with submanifold sparse convolutional networks. CVPR, 2018. 2
[19] Sylvain Gugger. The 1cycle policy. https://sgugger. github.io/the-1cycle-policy.html, 2018. 11
[20] Chenhang He, Hui Zeng, Jianqiang Huang, Xian-Sheng Hua, and Lei Zhang. Structure aware single-stage 3d object detection from point cloud. CVPR, 2020. 2, 3, 7, 8
[21] Kaiming He, Georgia Gkioxari, Piotr Doll´ar, and Ross Girshick. Mask r-cnn. ICCV, 2017. 2
[22] Geoffrey E Hinton, Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, and Ruslan R Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. JMLR, 2012. 5
[23] Peiyun Hu, Jason Ziglar, David Held, and Deva Ramanan. What you see is what you get: Exploiting visibility for 3d object detection. CVPR, 2020. 1, 6, 12
[24] Rui Huang, Wanyue Zhang, Abhijit Kundu, Caroline Pantofaru, David A Ross, Thomas Funkhouser, and Alireza Fathi. An lstm approach to temporal 3d object detection in lidar point clouds. ECCV, 2020. 8
[25] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. ICML, 2015. 5
[26] Borui Jiang, Ruixuan Luo, Jiayuan Mao, Tete Xiao, and Y uning Jiang. Acquisition of localization confidence for accurate object detection. ECCV, 2018. 4
[27] H. Karunasekera, H. Wang, and H. Zhang. Multiple object tracking with attention to appearance, structure, motion and size. IEEE Access, 2019. 2
[28] Alex H. Lang, Sourabh V ora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. Pointpillars: Fast encoders for object detection from point clouds. CVPR, 2019. 2, 3, 5, 6, 8, 11, 12
[29] Hei Law and Jia Deng. Cornernet: Detecting objects as paired keypoints. ECCV, 2018. 3
[30] Buyu Li, Wanli Ouyang, Lu Sheng, Xingyu Zeng, and Xiaogang Wang. Gs3d: An efficient 3d object detection framework for autonomous driving. CVPR, 2019. 4
[31] Ming Liang, Bin Yang, Y un Chen, Rui Hu, and Raquel Urtasun. Multi-task multi-sensor fusion for 3d object detection. CVPR, 2019. 2
[32] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. Focal loss for dense object detection. ICCV, 2017. 2, 3
[33] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Y ang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. ECCV, 2016. 2
[34] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. ICLR, 2019. 11
[35] Mahyar Najibi, Guangda Lai, Abhijit Kundu, Zhichao Lu, Vivek Rathod, Thomas Funkhouser, Caroline Pantofaru, David Ross, Larry S Davis, and Alireza Fathi. Dops: Learning to detect 3d objects and predict their 3d shapes. CVPR, 2020. 8
[36] Jiquan Ngiam, Benjamin Caine, Wei Han, Brandon Yang, Y uning Chai, Pei Sun, Yin Zhou, Xi Yi, Ouais Alsharif, Patrick Nguyen, et al. Starnet: Targeted computation for object detection in point clouds. arXiv preprint arXiv:1908.11069, 2019. 6, 8
[37] Jonah Philion, Amlan Kar, and Sanja Fidler. Learning to evaluate perception models using planner-centric metrics. CVPR, 2020. 5
[38] Charles R. Qi, Or Litany, Kaiming He, and Leonidas Guibas. Deep hough voting for 3d object detection in point clouds. ICCV, 2019. 2
[39] Charles R Qi, Wei Liu, Chenxia Wu, Hao Su, and Leonidas J Guibas. Frustum pointnets for 3d object detection from rgb-d data. CVPR, 2018. 2
[40] Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. CVPR, 2017. 2, 3
[41] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In NeurIPS, 2017. 7, 8
[42] Joseph Redmon and Ali Farhadi. Y olo9000: better, faster, stronger. CVPR, 2017. 2
[43] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. NIPS, 2015. 2, 3, 5
[44] Shaoshuai Shi, Chaoxu Guo, Li Jiang, Zhe Wang, Jianping Shi, Xiaogang Wang, and Hongsheng Li. Pv-rcnn: Pointvoxel feature set abstraction for 3d object detection. CVPR, 2020. 2, 3, 4, 5, 6, 7, 8, 11
[45] Shaoshuai Shi, Xiaogang Wang, and Hongsheng Li. Pointrcnn: 3d object proposal generation and detection from point cloud. CVPR, 2019. 1, 2, 5, 7
[46] Shaoshuai Shi, Zhe Wang, Jianping Shi, Xiaogang Wang, and Hongsheng Li. From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network. TPAMI, 2020. 2, 4, 7
[47] Martin Simony, Stefan Milzy, Karl Amendey, and HorstMichael Gross. Complex-yolo: An euler-region-proposal for real-time 3d object detection on point clouds. ECCV, 2018. 1, 2
[48] Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Y uning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: An open dataset benchmark. CVPR, 2020. 2, 5, 6
[49] Sourabh V ora, Alex H Lang, Bassam Helou, and Oscar Beijbom. Pointpainting: Sequential fusion for 3d object detection. CVPR, 2020. 6, 11, 12
[50] Dequan Wang, Coline Devin, Qi-Zhi Cai, Philipp Kr¨ahenb¨uhl, and Trevor Darrell. Monocular plan view networks for autonomous driving. IROS, 2019. 1
[51] Dominic Zeng Wang and Ingmar Posner. V oting for voting in online point cloud object detection. RSS, 2015. 2
[52] Y ue Wang, Alireza Fathi, Abhijit Kundu, David Ross, Caroline Pantofaru, Tom Funkhouser, and Justin Solomon. Pillarbased object detection for autonomous driving. ECCV, 2020. 2, 8
[53] Xinshuo Weng and Kris Kitani. A Baseline for 3D MultiObject Tracking. IROS, 2020. 2, 3, 5, 6
[54] Nicolai Wojke, Alex Bewley, and Dietrich Paulus. Simple online and realtime tracking with a deep association metric. ICIP, 2017. 2
[55] Kelvin Wong, Shenlong Wang, Mengye Ren, Ming Liang, and Raquel Urtasun. Identifying unknown instances for autonomous driving. CORL, 2019. 2
[56] Yan Yan, Y uxing Mao, and Bo Li. Second: Sparsely embedded convolutional detection. Sensors, 2018. 2, 3, 5, 6, 11
[57] Bin Y ang, Wenjie Luo, and Raquel Urtasun. Pixor: Real-time 3d object detection from point clouds. CVPR, 2018. 2
[58] Xue Yang, Qingqing Liu, Junchi Yan, Ang Li, Zhiqiang Zhang, and Gang Y u. R3det: Refined single-stage detector with feature refinement for rotating object. arXiv:1908.05612, 2019. 1
[59] Xue Y ang, Jirui Y ang, Junchi Y an, Y ue Zhang, Tengfei Zhang, Zhi Guo, Xian Sun, and Kun Fu. Scrdet: Towards more robust detection for small, cluttered and rotated objects. ICCV, 2019. 1
[60] Zetong Yang, Yanan Sun, Shu Liu, and Jiaya Jia. 3dssd: Point-based 3d single stage object detector. CVPR, 2020. 1, 2, 11
[61] Zetong Y ang, Y anan Sun, Shu Liu, Xiaoyong Shen, and Jiaya Jia. Std: Sparse-to-dense 3d object detector for point cloud. ICCV, 2019. 2
[62] Junbo Yin, Jianbing Shen, Chenye Guan, Dingfu Zhou, and Ruigang Yang. Lidar-based online 3d video object detection with graph-based message passing and spatiotemporal transformer attention. CVPR, 2020. 6, 12
[63] Xingyi Zhou, Vladlen Koltun, and Philipp Kr¨ahenb¨uhl. Tracking objects as points. ECCV, 2020. 2, 3
[64] Xingyi Zhou, Dequan Wang, and Philipp Kr¨ahenb¨uhl. Objects as points. arXiv:1904.07850, 2019. 2, 3
[65] Yin Zhou, Pei Sun, Y u Zhang, Dragomir Anguelov, Jiyang Gao, Tom Ouyang, James Guo, Jiquan Ngiam, and Vijay V asudevan. End-to-end multi-view fusion for 3d object detection in lidar point clouds. CORL, 2019. 2, 8
[66] Yin Zhou and Oncel Tuzel. V oxelnet: End-to-end learning for point cloud based 3d object detection. CVPR, 2018. 2, 3, 5, 11
[67] Benjin Zhu, Zhengkai Jiang, Xiangxin Zhou, Zeming Li, and Gang Y u. Class-balanced grouping and sampling for point cloud 3d object detection. arXiv:1908.09492, 2019. 2, 5, 6, 7, 8, 11, 12
[68] Xinge Zhu, Y uexin Ma, Tai Wang, Y an Xu, Jianping Shi, and Dahua Lin. Ssn: Shape signature networks for multi-class object detection from point clouds. ECCV, 2020. 6, 12
A.跟踪算法

B.实施细节
我们的实现基于CBGS[67]的开源代码(https://github.com/poodarchu/Det3D)。 CBGS在nuScenes上提供PointPillars[28]和VoxelNet[66]的实现。对于Waymo实验,我们对VoxelNet使用相同的架构,并根据数据集的参考实现将PointPillars [28]的输出步幅增加到1(https://github.com/tensorflow/lingvo/tree/master/lingvo/tasks/car)。
nuScenes中的一种常见做法[6, 49, 60, 67]是将未标注帧的激光雷达点转换并合并到其后续标注帧中。这会产生更密集的点云并实现更合理的速度估计。我们在所有nuScenes实验中都遵循这种做法。
对于数据增强,我们使用沿X和Y轴的随机翻转,以及具有[0.95, 1.05]随机因子的全局缩放。对于nuScenes[67],我们使用 [−π/8, π/8]和Waymo[44]的[−π/4, π/4]之间的随机全局旋转。我们还使用nuScenes上的ground-truth采样[56]来处理长尾类分布,它将注释框中的点从一帧复制并粘贴到另一帧。
对于nuScenes数据集,我们遵循CBGS [67]使用具有单周期学习率策略[19]的AdamW[34]优化器优化模型,最大学习率1e-3,权重衰减0.01,动量0.85到0.95。我们在4个V100 GPU上训练批量大小为16的模型20个epoch。
我们对Waymo模型使用相同的训练计划,除了学习率3e-3,我们在PV-RCNN[44]之后训练模型30个epoch。为了节省大规模Waymo数据集的计算,我们使用第二阶段细化模块对模型进行了6个epoch的微调,用于各种消融研究。所有消融实验都是在相同的环境中进行的。
对于nuScenes测试集提交,我们使用0.075m × 0.075m的输入网格大小,并在检测头中添加两个单独的可变形卷积层[11],以学习用于分类和回归的不同特征。这将CenterPoint-Voxel在nuScenes验证中的性能从64.8 NDS提高到65.4 NDS。对于nuScenes跟踪基准,我们提交了我们最好的具有翻转测试的CenterPoint-Voxel模型,在nuScenes验证中产生了66.5 AMOTA的结果。
C.nuScenes Performance across classes
我们在表 13 中展示了与最先进方法的每类比较。
D. nuScenes检测挑战
作为一个通用框架,CenterPoint是对当代方法的补充,并被NeurIPS 2020 nuScenes检测挑战的前4个条目中的三个使用。在本节中,我们将描述我们获胜提交的详细信息,该提交将2019年挑战赛获胜者CBGS [67]显着提高了14.3 mAP和8.1 NDS。我们在表14中报告了一些改进的结果。我们使用PointPainting[49]用在nuImages3上训练的Cascade RCNN模型生成的基于图像的实例分割结果来注释每个激光雷达点。这将NDS从65.4提高到68.0。然后我们执行两个测试时间增强,包括双翻转测试和围绕偏航轴的点云旋转。具体来说,我们使用[0°, ± 6.25°, ± 12.5°, ± 25°]进行偏航旋转。这些测试时间增加将 NDS从68.0提高到70.3。最后,我们集成了五个模型,输入网格大小在[0.05m, 0.05m]到[0.15m, 0.15m]之间,并过滤掉点数为零的预测,这在nuScenes验证中产生了我们最好的结果,具有68.2 mAP和71.7 NDS。
















 3312
3312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











