







目录
1.简介
TOPSIS法 —— python :传送门
灰色关联法 —— python:传送门
2.算法详解
2.1 指标正向化及标准化
设有m个待评对象,n个评价指标,可以构成数据矩阵X=(xij)m*n,设数据矩阵内元素,经过指标正向化处理过后的元素为xij'
- 若xj为负向指标(越小越优型指标)
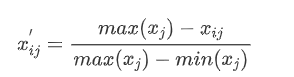
- 若xj为正向指标(越大越优型指标)

2.2 找到最大最小参考向量
设正向化标准化后的数据矩阵![]() 。
。
最大参考向量由各个指标的最大值构成
![]()
最小参考向量由各个指标的最小值构成
![]()
2.3 计算与参考向量的相关系数
求出标准化后数据矩阵X和最大参考向量Vmax和最小参考向量Vmin的灰色相关系数。
该过程仿照灰色关联度分析法做就行
- 参考向量的选择
例如研究x2指标与x1指标之间的灰色关联度。所以将x1列作为参考向量,即要研究与谁的关系,就将谁作为参考。设参考向量为Y1=x1,生成新的数据矩阵 X1=x2.
- 生成绝对值矩阵
设生成的绝对值矩阵为A
A=[X1-Y1],亦是A=[x2-x1]
设dmax为绝对值矩阵A的最大值,dmin为绝对值矩阵A的最小值。
-
计算灰色关联矩阵
设灰色关联矩阵为B
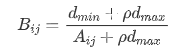
- 计算灰色关联度
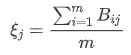
2.4 求评分

3.实例分析
数据来源:蓝奏云

3.1 读取数据
#导入数据
data=pd.read_excel('D:\桌面\TOPSIS.xlsx') #横坐标为评价指标,纵坐标为评价对象
# print(data)
#提取变量名 x1 -- x7
label_need=data.keys()[1:]
# print(label_need)
#提取上面变量名下的数据
data1=data[label_need].values.T
print(data1)返回:

3.2 数据标准化
#0.002~1区间归一化
data2=data1.astype('float')
data3=data2
ymin=0.002
ymax=1
for j in range(0,n):
d_max=max(data2[:,j])
d_min=min(data2[:,j])
data3[:,j]=(ymax-ymin)*(data2[:,j]-d_min)/(d_max-d_min)+ymin
print(data3)返回:

3.3 得到最大最小参考行
# 得到最大最小参考行
data3=data3.T
V_max=np.max(data3,axis=0) #最大参考行,指标最大
V_min=np.min(data3,axis=0) #最小参考行,指标最小3.4 与最大值的灰色相关系数
# 与最大值的灰色相关系数
[m,n]=data1.shape #得到行数和列数
data4=data3;
for i in range(m):
data4[i,:]=abs(data3[i,:]-V_min);
#得到绝对值矩阵的全局最大值和最小值
d_max=np.max(data4)
d_min=np.min(data4)
#灰色关联矩阵
a=0.5; #分辨系数
data5=(d_min+a*d_max)/(data4+a*d_max);
xi_min=np.mean(data5.T,axis=1)
print(xi_min)返回:

3.5 与最小值的灰色相关系数
# 与最小值的灰色相关系数
[m,n]=data1.shape #得到行数和列数
data4=data3;
for i in range(m):
data4[i,:]=abs(data3[i,:]-V_max);
#得到绝对值矩阵的全局最大值和最小值
d_max=np.max(data4)
d_min=np.min(data4)
#灰色关联矩阵
a=0.5; #分辨系数
data5=(d_min+a*d_max)/(data4+a*d_max);
xi_max=np.mean(data5.T,axis=1)
print(xi_max)返回:
![]()
3.6 计算综合评分
# 综合评分
#与最大指标行相关系数越大,最小指标构成的行相关系数越小得分大
s=xi_min/(xi_max+xi_min)
Score=100*s/max(s)
for i in range(len(Score)):
print(f"第{i+1}个投标者百分制得分为:{Score[i]}")返回:

完整代码
#导入数据
data=pd.read_excel('D:\桌面\TOPSIS.xlsx')
# print(data)
#提取变量名 x1 -- x7
label_need=data.keys()[1:]
# print(label_need)
#提取上面变量名下的数据
data1=data[label_need].values.T
print(data1)
#0.002~1区间归一化
data2=data1.astype('float')
data3=data2
ymin=0.002
ymax=1
for j in range(0,n):
d_max=max(data2[:,j])
d_min=min(data2[:,j])
data3[:,j]=(ymax-ymin)*(data2[:,j]-d_min)/(d_max-d_min)+ymin
print(data3)
# 得到最大最小参考行
V_max=np.max(data3) #最大参考行,指标最大
V_min=np.min(data3) #最小参考行,指标最小
# 与最大值的灰色相关系数
[m,n]=data1.shape #得到行数和列数
data4=data3;
for i in range(m):
data4[i,:]=abs(data3[i,:]-V_min);
#得到绝对值矩阵的全局最大值和最小值
d_max=np.max(data4)
d_min=np.min(data4)
#灰色关联矩阵
a=0.5; #分辨系数
data5=(d_min+a*d_max)/(data4+a*d_max);
xi_min=np.mean(data5.T,axis=1)
print(xi_min)
# 与最小值的灰色相关系数
[m,n]=data1.shape #得到行数和列数
data4=data3;
for i in range(m):
data4[i,:]=abs(data3[i,:]-V_max);
#得到绝对值矩阵的全局最大值和最小值
d_max=np.max(data4)
d_min=np.min(data4)
#灰色关联矩阵
a=0.5; #分辨系数
data5=(d_min+a*d_max)/(data4+a*d_max);
xi_max=np.mean(data5.T,axis=1)
print(xi_max)
# 综合评分
#与最大指标行相关系数越大,最小指标构成的行相关系数越小得分大
s=xi_min/(xi_max+xi_min)
Score=100*s/max(s)
for i in range(len(Score)):
print(f"第{i+1}个投标者百分制得分为:{Score[i]}")














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









