







MVP: Unified Motion and Visual Self-Supervised Learning for Large-Scale Robotic Navigation
核心;基于mvp的方法,使用在大型环境中收集的运动估计和视觉数据进行训练。MVP方法是通过将局部运动估计与紧凑的视觉表现联系起来,从而有效地训练我们的政策网络。利用这些数据,强化学习政策可以学会以一种自我监督的方式将运动表象与视觉观察联系起来,从而使系统对视觉变化条件和糟糕的GPS数据都具有鲁棒性。
摘要
自主导航产生于现实环境中的运动和局部视觉感知。然而,最成功的机器人运动估计方法(如VO, SLAM, SfM)和视觉系统(如CNN,视觉位置识别- vpr)通常分别用于建图和定位任务。相反,最近的基于增强学习(RL)的视觉导航方法依赖于GPS数据接收的质量,当在大环境中直接使用它作为跨越多个月间隔的遍历的地面真值时,它可能不可靠。在这篇论文中,我们提出了一种新的运动和视觉感知方法,称为MVP,它将这两种传感器模式结合起来,用于大规模的、目标驱动的导航任务。我们的基于mvp的方法比相应的视觉导航方法学习更快,对极端的环境变化和较差的GPS数据更准确和健壮。MVP临时地将使用VPR获得的紧凑图像表示与优化的运动估计数据(包括但不限于VO或优化的雷达测程(RO)的数据)结合起来,通过RL有效地学习自监督导航策略。我们在两个大型的真实世界数据集上评估我们的方法, Oxford
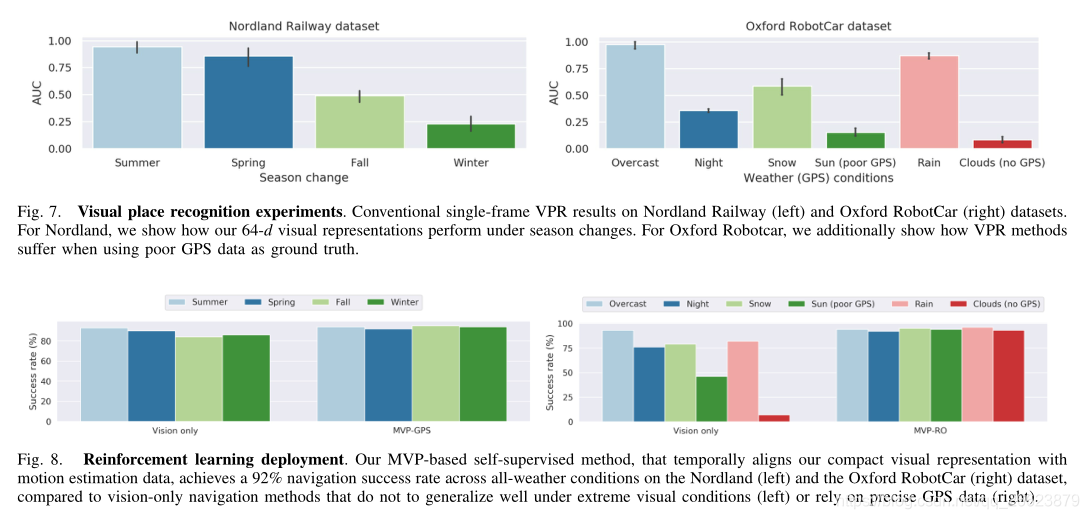
RobotCar dataset ,在一系列的天气(如阴天、夜晚、雪、太阳、雨、云)和季节(如冬季、春季、秋季、夏季)条件下使用新的CityLearn框架;一个有效训练导航代理的交互式环境。我们的实验结果表明,在没有GPS数据的情况下,使用VO和RO, MVP可以分别获得53%和93%的导航成功率,相比之下,只有视觉的方法只能获得7%的导航成功率。此外,我们还提出了RL成功率和运动估计精度之间的权衡,这表明纯视觉导航系统可以受益于使用精确的运动估计技术来提高整体性能。
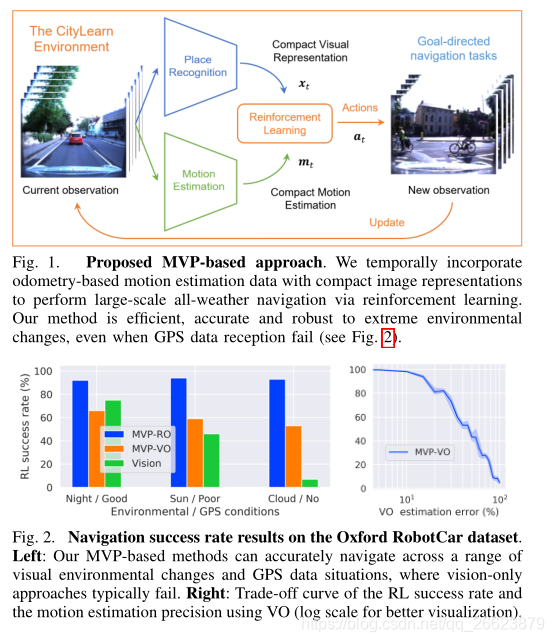
贡献
本文的主要贡献如下:
1利用成功的机器人运动估计方法,包括VO或雷达,通过可用于执行目标驱动导航任务的环境捕获紧凑的运动信息(见图1)。这使得我们的系统在极端环境变化下更加高效和健壮,即使GPS数据可用性有限或没有(图2-左)。
2对于大规模全天候导航任务,使用RL在时间上将紧凑的运动表示与通过基于深度学习的VPR模型获得的同等紧凑的图像观测结合起来。
3关于RL导航成功率和VO运动估计精度权衡的实验结果(图2-右)。这说明了我们提出的导航系统是如何在精确运动估计技术(如VO)的基础上提高其整体性能的。
方法
总体方案
在本文中,提出了一种不同的方法,克服了以往工作对大规模、全天候导航任务的限制。统一了两个基本和高度相关的传感器模式:运动和视觉感知(MVP)信息。基于mvp的方法建立在之前的工作中提出的主要思想之上,即使用紧凑的图像表示,使用实际数据实现基于rl的高效采样视觉导航,并演示了如何利用VPR任务的运动信息。提出了一种网络结构,可以通过RL将运动信息与视觉观测结合起来,在极端环境变化和有限或没有GPS数据的情况下执行精确的导航任务;
问题模型

实验方法
在视觉位置识别和导航任务中提供了大量的实验结果,使用了两个大型的真实世界数据集,展示了我们的方法如何有效地克服了那些视觉导航管道的限制
为了给我们的代理提供运动数据,我们在实验中分别使用了三种不同的传感器模式:原始GPS数据、视觉测程(VO)和优化的雷达测程(RO)。对于牛津RobotCar数据集,它已经提供了GPS和VO传感器数据。对于RO,我们使用了扩展的牛津RobotCar雷达数据集[9]中提供的优化的地面真RO传感器数据——这已经被证明在具有挑战性的视觉转换下更准确——仔细选择,以在视觉上匹配我们选择的遍历
RL agent设计
本文目标是训练一个RL代理在一系列真实环境条件下执行目标驱动的导航任务,特别是在GPS数据条件差的情况下。因此,本文开发了一种基于mvp的方法,可以使用在大型环境中收集的运动估计和视觉数据进行训练。MVP方法是通过将局部运动估计与紧凑的视觉表现联系起来,从而有效地训练我们的政策网络。利用这些数据,政策可以学会以一种自我监督的方式将运动表象与视觉观察联系起来,从而使系统对视觉变化条件和糟糕的GPS数据都具有鲁棒性。
基本agents模型

评价指标VPR实验
我们报告广泛的VPR结果,使用我们的紧凑图像表示(xt),以提供一个指标,视觉组件的性能基础上,我们的整个基于rl的MVP系统。在每个引用遍历上训练一个线性分类器,然后在剩下的查询遍历上对它求值。每个图像的分类分数被用来计算精确回忆曲线,最后被用来计算曲线下的面积(AUC)结果。
结果
基于视觉得导航

基于MVP方法导航结果















 1221
1221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









