









Day5_使用神经网络拟合数据
文章目录
1. 人工神经网络
深度学习的核心是神经网络,即一种能够通过简单函数的组合来表示复杂函数的数学实体,人工神经网络和生理神经网络(我们的大脑)似乎都使用模糊相似的数学策略来逼近复杂的函数
这些复杂函数的基本构建是神经元,其输入是简单的线性变换,可以理解为 o u t p u t = t a n h ( w x + b ) output = tanh(wx+b) output=tanh(wx+b) ,即将输入乘以一个权重,加上一个常数(偏置),然后用一个固定的非线性函数(激活函数),作用是约束输出,避免产生梯度消失或梯度爆炸
从数学上来讲,我们可以把这种关系写成 o = f ( w x + b ) o=f(wx+b) o=f(wx+b) ,其中 x x x是输入, w w w是权重或比例因子, b b b是偏置或偏移量, f f f是激活函数,设为双曲正切函数,这里即 t a n h tanh tanh。通常情况下, x x x和 o o o可以是简单的标量或向量值, w w w可以是单个标量或矩阵, b b b是标量或向量
1.1 组成一个多层网络
我们可以搭建一个多层神经网络
x_1 = f(w_0 * x + b_0)
x_2 = f(w_1 * x_1 + b_1)
x_3 = f(w_2 * x_2 + b_2)
...
y = f(w_n * x_n + b_n)
其中前一层神经元的输出作为下一层神经元的输入,w_0是一个矩阵,x是一个向量,使用向量可以使w_0承载整个神经元层,而不是单一的权重
1.2 理解激活函数
在神经网络中,最简单的单元是线性运算,然后是激活函数,激活函数有两个作用:
- 在模型的内部,激活函数允许输出函数在不同的值上有不同的斜率,使其能够近似任意函数
- 在网络的最后一层,激活函数的作用是将前面的线性运算的输出集中到给定的范围内
1.2.1 限制输出范围
一种可能的情况是,我们希望将线性操作的输出严格限制在一个特定的范围内,比如对输出值设置上限:
- 低于0的值设置为0
- 高于10的值设置为10
基于这种情况,PyTorch提供了一个函数torch.nn.Hardtanh(),这是一个的简单的激活函数,默认范围是
[
−
1
,
1
]
[-1,1]
[−1,1]
1.2.2 压缩输入范围
这类运行良好的函数时torch.nn.Sigmoid(),包括
1
1
+
e
−
x
\frac{1}{1+e^{-x}}
1+e−x1 ,torch.tanh()等。这些函数的曲线在x趋于负无穷大时逐渐接近0或-1,随着x逐渐接近1,函数在x=0时具有基本恒定的斜率。常见的激活函数可以参考这篇文章 常用的激活函数合集(详细版)
2. Pytorch nn模块
PyTorch提供了一个专门用于神经网络的子模块,叫做torch.nn,包含了创建各种神经网络结果所需的构建块
一个模块还可以有一个或多个子模块,使用torch.nn.Module的子类作为属性,并且还能追踪他们的参数;注意,子模块必须是顶级模块,而不是隐藏在列表或dict实例中,否则优化器将无法定位子模块以及他们的参数,对于这种情况,PyTorch提供了nn.ModuleList和nn.ModuleDict
2.1 线性模型
构造函数nn.Linear接收三个参数:
- 输入特征的数量
- 输出特征的数量
- 线性模型是否包含偏置(默认为
True)
下面是使用前文数据的一个例子:
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c).unsqueeze(1)
t_u = torch.tensor(t_u).unsqueeze(1)
n_samples = t_u.shape[0]
n_val = int(0.2 * n_samples)
shuffled_indices = torch.randperm(n_samples)
train_indices = shuffled_indices[:-n_val]
val_indices = shuffled_indices[-n_val:]
t_u_train = t_u[train_indices]
t_c_train = t_c[train_indices]
t_u_val = t_u[val_indices]
t_c_val = t_c[val_indices]
t_un_train = 0.1 * t_u_train
t_un_val = 0.1 * t_u_val
import torch.nn as nn
linear_model = nn.Linear(1, 1)
linear_model(t_un_val)
输出
tensor([[0.6018],
[0.2877]], grad_fn=<AddmmBackward>)
我们查看以下模型中的权重
print(linear_model.weight)
print(linear_model.bias)
输出
Parameter containing:
tensor([[-0.0674]], requires_grad=True)
Parameter containing:
tensor([0.7488], requires_grad=True)
2.2 批量输入
nn中的所有模块都可以同时为多个输入产生输出,假设我们需要在10个样本上运行nn.Linear,我们可以创建一个大小为
B
×
N
i
n
B \times Nin
B×Nin 的输入张量,其中
B
B
B 是批次的大小,
N
i
m
Nim
Nim 为输入特征的张量
x = torch.ones(10, 1)
linear_model(x)
输出
tensor([[0.6814],
[0.6814],
[0.6814],
[0.6814],
[0.6814],
[0.6814],
[0.6814],
[0.6814],
[0.6814],
[0.6814]], grad_fn=<AddmmBackward>)
2.3 优化批次
我们要进行批量处理的原因有以下几种:
- 确保我们要求的计算足够大,以饱和我们用于执行计算的计算资源,GPU是高度并行化的,因此一个小模型上的单个输入将使大部分单元处于空闲状态,通过提供批量输入,计算可以分散到其他空闲的单元中,这就意味着批量的结果返回的速度与单个结果返回的速度一样快
- 一些高级模型使用来自整个批处理的统计信息,并且随着批处理大小的增加,这些统计信息会变得更好
在之前的训练中,我们只考虑了一个输入特征,当我们需要考虑多个特征时,就需要增加输入特征的维度,把一个一维张量变成一个矩阵,使用unsqueeze()方法可以轻松实现这个功能
现在我们可以使用nn.Linear(1,1)代替手动构建模型,然后将线性模型参数传递给优化器
linear_model = nn.Linear(1, 1)
optimizer = optim.SGD(
linear_model.parameters(),
lr=1e-2)
当调用optimizer.step()时,它将遍历每个参数,并按其grad属性中存储的内容的比例对其进行更改
现在的训练循环:
def training_loop(n_epochs, optimizer, model, loss_fn, t_u_train, t_u_val,
t_c_train, t_c_val):
for epoch in range(1, n_epochs + 1):
t_p_train = model(t_u_train)
loss_train = loss_fn(t_p_train, t_c_train)
t_p_val = model(t_u_val)
loss_val = loss_fn(t_p_val, t_c_val)
optimizer.zero_grad()
loss_train.backward()
optimizer.step()
if epoch == 1 or epoch % 1000 == 0:
print(f"Epoch {epoch}, Training loss {loss_train.item():.4f},"
f" Validation loss {loss_val.item():.4f}")
代码实际上没有变化,只是现在不需要显式地将参数传给模型,因为模型本身在内部拥有它的参数
torch.nn中包含了几个常见的损失函数,具体可以参考:【常见的损失函数总结】
这里我们使用nn.MSELoss()(均方误差)来替换之前的loss_fn()函数
linear_model = nn.Linear(1, 1)
optimizer = optim.SGD(linear_model.parameters(), lr=1e-2)
training_loop(
n_epochs = 3000,
optimizer = optimizer,
model = linear_model,
loss_fn = nn.MSELoss(),
t_u_train = t_un_train,
t_u_val = t_un_val,
t_c_train = t_c_train,
t_c_val = t_c_val)
print()
print(linear_model.weight)
print(linear_model.bias)
输出
Epoch 1, Training loss 134.9599, Validation loss 183.1707
Epoch 1000, Training loss 4.8053, Validation loss 4.7307
Epoch 2000, Training loss 3.0285, Validation loss 3.0889
Epoch 3000, Training loss 2.8569, Validation loss 3.9105
Parameter containing:
tensor([[5.4319]], requires_grad=True)
Parameter containing:
tensor([-17.9693], requires_grad=True)
3. 完成一个神经网络
3.1 替换线性模型
由于历史原因,第一个线性模型+激活层通常被称为隐藏层,整体即:输入-隐藏层-输出,nn提供了一种通过nn.Sequential容器来连接模型的方式
seq_model = nn.Sequential(
nn.Linear(1, 13),
nn.Tanh(),
nn.Linear(13, 1))
seq_model
输出
Sequential(
(0): Linear(in_features=1, out_features=13, bias=True)
(1): Tanh()
(2): Linear(in_features=13, out_features=1, bias=True)
)
最终的结果是一个模型,它将第一个模块所期望的输入指定为nn.Sequential的一个参数,将中间输出传递给后续模块,并产生最后一个模块返回的输出;该模型从1个输入特征得到13个隐藏特征,通过tanh激活函数传递它们,并将得到的13个数字线性组合成1个输出特征
3.2 检查参数
我们可以通过调用model.parameters()将从第一个和第二个线性模块收集权重和偏置
[param.shape for param in seq_model.parameters()]
输出
[torch.Size([13, 1]), torch.Size([13]), torch.Size([1, 13]), torch.Size([1])]
同样,在我们调用model.backward()之后,所有参数都填充了它们的梯度,然后优化器在调用optimizer.step()期间相应地更新它们的值
我们可以使用named_parameters()方法检查由若干子模块组成的模型参数
for name, param in seq_model.named_parameters():
print(name, param.shape)
输出
0.weight torch.Size([13, 1])
0.bias torch.Size([13])
2.weight torch.Size([1, 13])
2.bias torch.Size([1])
Sequential可以接收OrderdDict,我们可以用其命名后传递给Sequential的每个模块
from collections import OrderedDict
seq_model = nn.Sequential(OrderedDict([
('hidden_linear', nn.Linear(1, 8)),
('hidden_activation', nn.Tanh()),
('output_linear', nn.Linear(8, 1))
]))
seq_model
输出
Sequential(
(hidden_linear): Linear(in_features=1, out_features=8, bias=True)
(hidden_activation): Tanh()
(output_linear): Linear(in_features=8, out_features=1, bias=True)
)
在这种方式下,我们可以为子模块获取更多解释性名称:
for name, param in seq_model.named_parameters():
print(name, param.shape)
输出
hidden_linear.weight torch.Size([8, 1])
hidden_linear.bias torch.Size([8])
output_linear.weight torch.Size([1, 8])
output_linear.bias torch.Size([1])
我们也可以通过将子模块作为属性来访问一个特定的参数
seq_model.output_linear.bias
输出
Parameter containing:
tensor([-0.0173], requires_grad=True)
此时我们可以修改训练循环,并输出最后一个迭代周期的梯度结果
optimizer = optim.SGD(seq_model.parameters(), lr=1e-3) # <1>
training_loop(
n_epochs = 5000,
optimizer = optimizer,
model = seq_model,
loss_fn = nn.MSELoss(),
t_u_train = t_un_train,
t_u_val = t_un_val,
t_c_train = t_c_train,
t_c_val = t_c_val)
print('output', seq_model(t_un_val))
print('answer', t_c_val)
print('hidden', seq_model.hidden_linear.weight.grad)
输出
Epoch 1, Training loss 182.9724, Validation loss 231.8708
Epoch 1000, Training loss 6.6642, Validation loss 3.7330
Epoch 2000, Training loss 5.1502, Validation loss 0.1406
Epoch 3000, Training loss 2.9653, Validation loss 1.0005
Epoch 4000, Training loss 2.2839, Validation loss 1.6580
Epoch 5000, Training loss 2.1141, Validation loss 2.0215
output tensor([[-1.9930],
[20.8729]], grad_fn=<AddmmBackward>)
answer tensor([[-4.],
[21.]])
hidden tensor([[ 0.0272],
[ 0.0139],
[ 0.1692],
[ 0.1735],
[-0.1697],
[ 0.1455],
[-0.0136],
[-0.0554]])
3.3 与线性模型对比
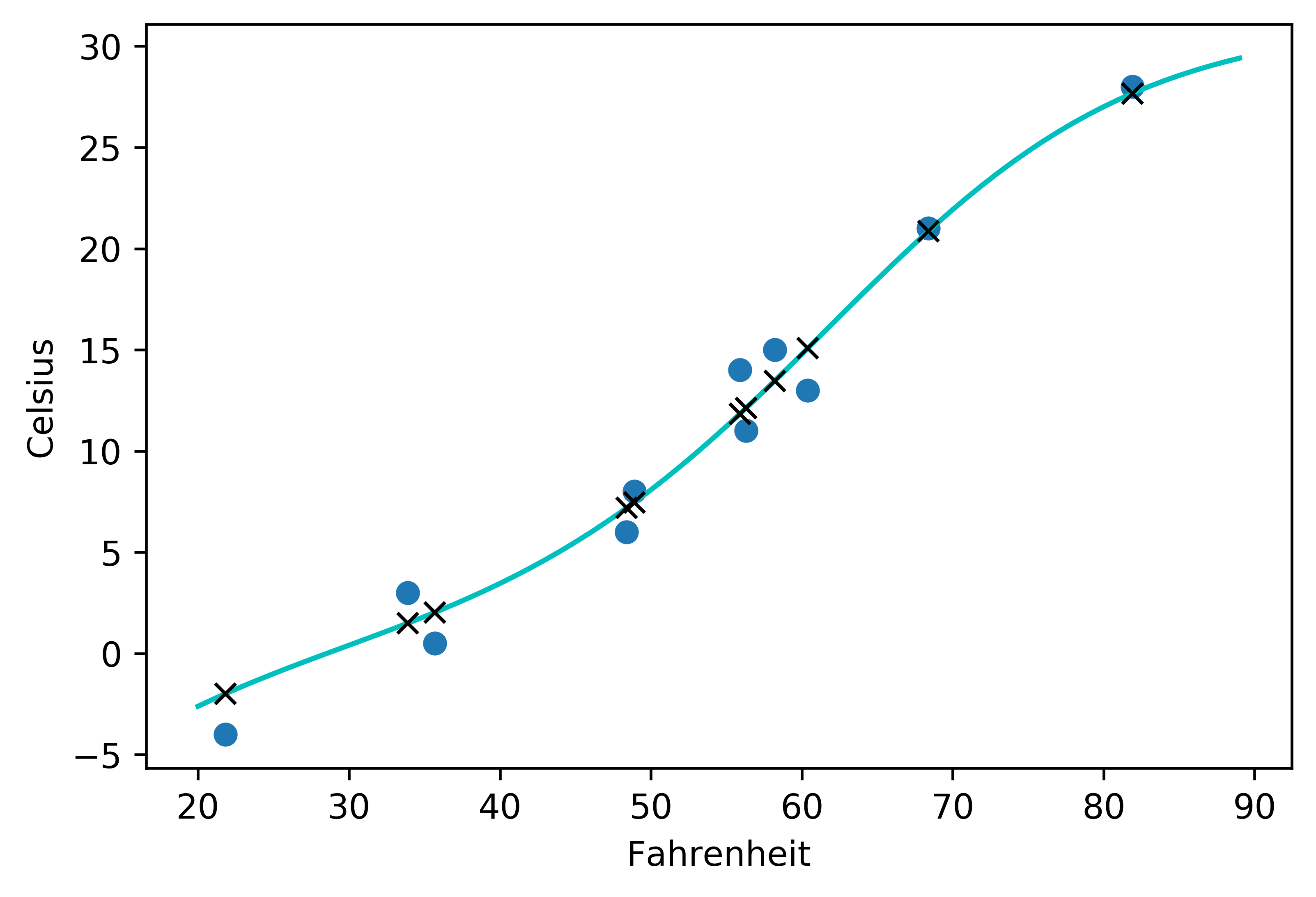
使用matplotlib绘制散点图和拟合曲线
from matplotlib import pyplot as plt
t_range = torch.arange(20., 90.).unsqueeze(1)
fig = plt.figure(dpi=600)
plt.xlabel("Fahrenheit")
plt.ylabel("Celsius")
plt.plot(t_u.numpy(), t_c.numpy(), 'o')
plt.plot(t_range.numpy(), seq_model(0.1 * t_range).detach().numpy(), 'c-')
plt.plot(t_u.numpy(), seq_model(0.1 * t_u).detach().numpy(), 'kx')
输出
















 2223
2223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











