






每天给你送来NLP技术干货!
来自:哈工大讯飞联合实验室
本期导读:本文是对受控文本生成任务的一个简单的介绍。首先,本文介绍了受控文本生成模型的一般架构,点明了受控文本生成模型的特点。然后,本文介绍了受控文本生成技术在故事生成任务和常识生成任务上的具体应用,指出了受控文本生成技术在具体应用场景下的改进方向。
•••
0. 什么是受控文本生成
文本生成任务是自然语言处理领域十分重要的一类任务。文本摘要、语法纠错、人机对话等很多自然语言处理任务都可以被视为文本生成任务。GPT-2、BART、T5等文本生成相关的技术也在这些任务上取得了较好的效果。受控文本生成任务与常规的文本生成任务有一些不同。常规的文本生成任务对生成文本的内容(Content)通常没有强制性的约束,而受控文本生成任务会要求生成文本的内容必须满足一些既定的约束条件,如风格(Style)、主题(Topic)等。例如,文本风格转换(Text Style Transfer)就是一类十分经典的受控文本生成任务,该任务要求生成文本的内容在语义上需要与转换前保持一致,在风格上需要转换为预定义好的目标风格。从应用的角度来看,受控文本生成技术更有希望构建出场景适配的、用户可接受的文本生成系统。因此,受控文本生成技术已经被越来越多的研究者关注。
1. 受控文本生成模型的一般架构
CMU的一些研究者们发表在COLING 2020的一篇论文对受控文本生成模型的一般架构(见图1)进行了比较细致的描述。受控文本生成模型在生成受控文本时可以通过5个子模块对生成文本进行控制。
第一个模块称为额外输入模块(External Input module),该模块负责提供生成受控文本时的初始信号。
第二个模块称为序列输入模块(Sequential Input module),该模块负责提供生成受控文本时每个时间步上的输入。
第三个模块称为生成操作模块(Generator Operations module),该模块决定每个时间步向量表示的计算方式,即是使用RNN计算,还是使用Transformer计算,亦或是使用其他计算方式。
第四个模块称为输出模块(Output module),该模块负责将每个时间步的向量表示映射为输出结果。
第五个模块称为训练目标模块(Training Objective module),该模块负责损失函数的计算。
其中额外输入模块,是受控文本生成模型中比较特殊且重要的一个模块,该模块通常会提供一个与控制目标相关的向量表示作为受控文本生成的初始信号,从而保证生成的文本满足预定义的控制目标。另外,输出模块也是受控文本生成模型致力于改进的一个模块。常规的文本生成任务只需要将每个时间步的向量表示映射为词表分布作为输出空间即可,而在受控文本生成模型中就需要通过某种方式改变输出空间的分布去获得期望的输出结果。
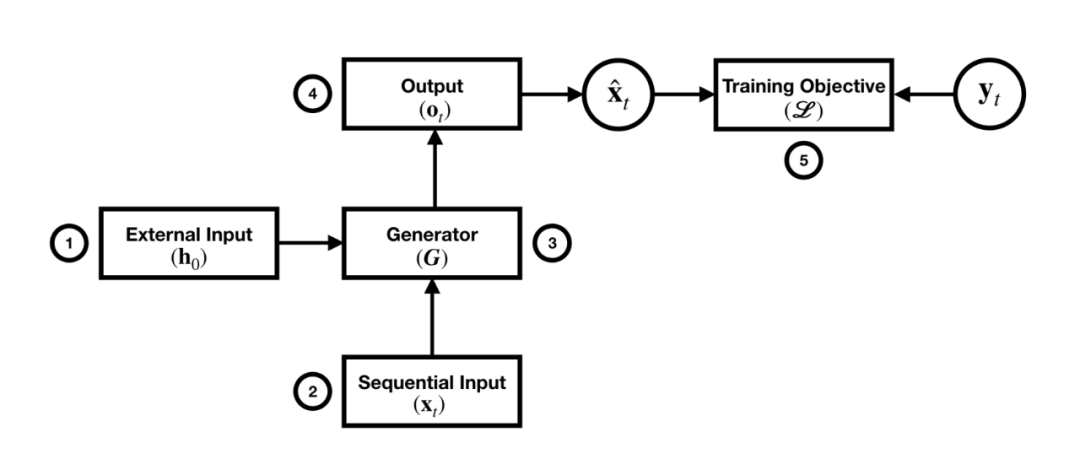
图1 受控文本生成的一般架构
2. 受控文本生成技术在故事生成任务上的应用
本节介绍一个发表在EMNLP 2020上的利用受控文本生成技术改进故事生成的工作。该工作使用的数据集为ROCStories dataset(该数据集中的每个故事都由5个句子组成),其任务设定为给定故事的第一个句子,机器自动生成后面的句子。如果不使用受控文本生成技术,该任务就是一个简单的语言模型式的文本生成任务,直接使用GPT-2就可以完成。但是,直接使用GPT-2生成的故事很难保证生成的结果是语义连贯且逻辑自洽的。因此,将受控文本生成技术引入到故事生成任务中就有可能控制故事生成的内容,从而改进故事生成的效果。
该工作首先使用一个基于GPT-2的关键词预测模型预测出与下一句相关的关键词,然后使用这些关键词去大规模的知识库中检索出与这些关键词相关的三元组,这些三元组会通过一些模板被转化为句子。由于这些由三元组转化的句子数量较多且可能存在大量的噪音,因此,还需要一个与下一句信息相关联的基于BERT的排序模型对这些句子进行排序,从而选择出与下一句信息最相关的TopN个句子。在获得这些来源于知识库的句子后,我们就可以将这些句子作为控制信息并与当前句进行拼接一起作为GPT-2的输入去生成下一句。上述流程需要循环进行直到生成故事中所有的句子。图2是该工作整体的流程图。
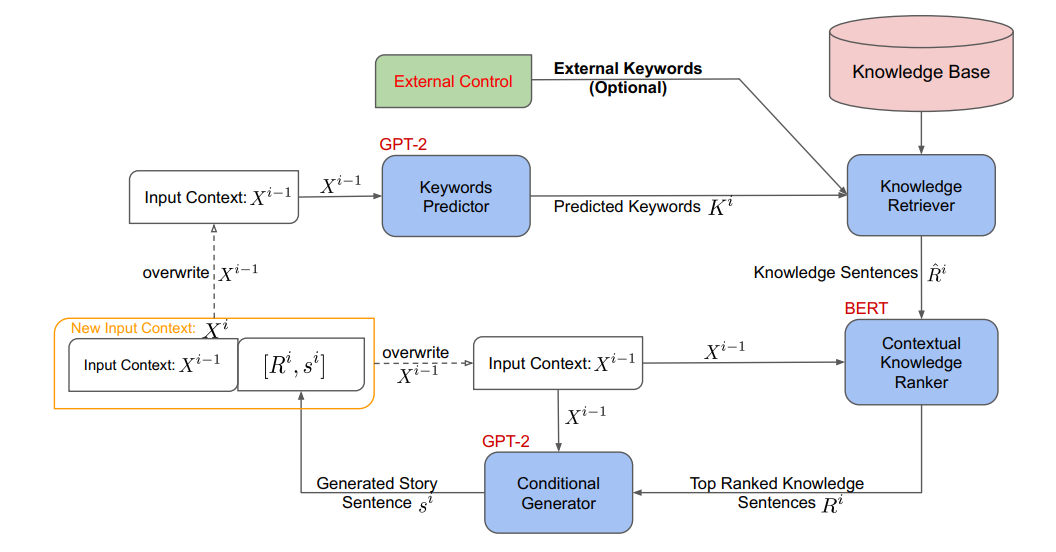
图2 基于知识库信息控制的故事生成流程图
这个工作虽然没有对受控文本生成模型进行改进,但是从大规模知识库中获取控制信息进行文本生成的思路还是有一定借鉴意义的。
3. 受控文本生成技术在常识生成任务上的应用
本节介绍一个发表在ACL 2021上将受控文本生成技术应用在常识生成任务上的工作。常识生成任务是一项比较新颖的文本生成任务。该任务的设定为给定一个概念集合,机器需要自动生成一个能够描述这个概念集合的句子,并且生成的句子不能违背常识。例如,给定一个概念集合{apple, bag, put},理想情况下机器应该生成“A girl puts an apple in her bag”这样的句子。如果机器生成了“A girl eats an apple”或者“A girl puts a bag in her apple”,都不能算是一个合格的生成结果。因此,要想获得一个较好的生成结果,我们首先需要保证的就是概念集合里的概念都要出现在输出结果中。
本节介绍的工作提出了一种名为“Mention Flags”的方法,通过在解码端引入一个提及标记矩阵(Mention Flag Matrix)来标记输入项与输出项的提及关系,从而控制每个时间步解码时的输出。提及标记矩阵中的元素共有3种不同的取值,取0时表示该输入项不是控制项,取1时表示该输入项是控制项,但在输出项中未出现。取2时表示该输入项是控制项,并已经在输出项中出现。以输入为{apple, bag, put},输出为“A girl puts an apple in her bag”为例,其转换为提及矩阵后如图3所示:
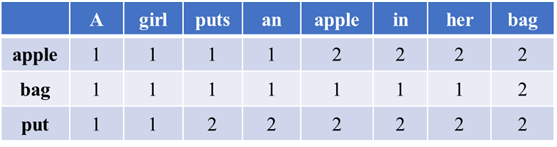
图3 提及标记矩阵
在训练时,提及标记矩阵可以通过输入与输出的对齐数据直接转换得到。在推理时,我们只需要在每个时间步递增式地扩充提及标记矩阵的每一列即可。
最后是如何将提及标记矩阵融入到模型中的问题。由于该工作使用的是基于Transformer的文本生成模型,其作者将提及标记矩阵视为输入项与输出项的相对位置(Relative Position),在计算输出项与输入项的交叉注意力(Cross Attention)时将相对位置信息融入到模型计算中(见图4,细节可参考论文Self-Attention with Relative Position Representations)。
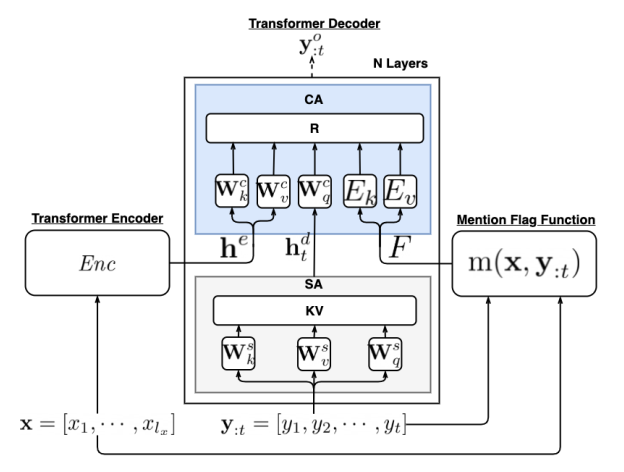
图4 融入相对信息的交叉注意力计算
4. 小结
本文简单介绍了受控文本生成与常规文本生成任务的区别,并对受控文本生成模型的一般架构进行了阐述。受控文本生成的特殊点主要在于受控信息的获取以及对输出结果的控制。因此,要想获得一个较好的受控文本生成系统,就可以从这两点上对文本生成的模型或方案进行改进。另外,文本还介绍了受控文本生成技术在故事生成任务和常识生成任务上的应用,这些方法和思想同样可以借鉴到其他受控文本生成任务中。
参考文献
[1] Prabhumoye S, Black A W, Salakhutdinov R. Exploring Controllable Text Generation Techniques[C]//Proceedings of the 28th International Conference on Computational Linguistics. 2020: 1-14.
[2] Xu P, Patwary M, Shoeybi M, et al. Controllable Story Generation with External Knowledge Using Large-Scale Language Models[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 2831-2845.
[3] Mostafazadeh N, Vanderwende L, Yih W, et al. Story Cloze Evaluator: Vector Space Representation Evaluation by Predicting What Happens Next[J]. ACL 2016, 2016: 24.
[4] Lin B Y, Zhou W, Shen M, et al. CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings. 2020: 1823-1840.
[5] Wang Y, Wood I D, Wan S, et al. Mention Flags (MF): Constraining Transformer-based Text Generators[J].
[6] Shaw P, Uszkoreit J, Vaswani A. Self-Attention with Relative Position Representations[C]//Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018: 464-468.
原文:申资卓
编辑:HFL编辑部
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!

















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









