






每天给你送来NLP技术干货!
来自:NLP日志
提纲
1. 简介
2. Encoding Input Representations
2.1 Unstructured Input(非结构化输入)
2.2 Structured Inpu(结构化输入)
2.3 Multimedia Input(多模态输入)
3. Designing Plms for Text generations(设计文本生成的预训练模型)
4. Optimizing Plms For Text Generation(优化文本生成预训练模型)
4.1 Fine-Tuning
4.2 Prompt-Tuning
4.3 Property-Tuning
参考文献
(本周日需要补班,所以周日就不发了)
1. 简介
文本生成旨在从输入数据中生成从人类语言角度上可信并且可读的文本, 深度学习的兴起逐渐占据了这个领域,无论是学术界还是工业界,依赖于预训练模型的文本生成正在被视为一个有潜力的方向,将预训练模型应用到文本生成领域主要有以下三个关键点。
a). 如何将输入数据编码到一种可以保留语义的表征。
b). 如何设计一种通用并且性能优化的基于预训练模型的生成模型。
c). 在给定参考文本下如何优化预训练模型并保证生成质量。
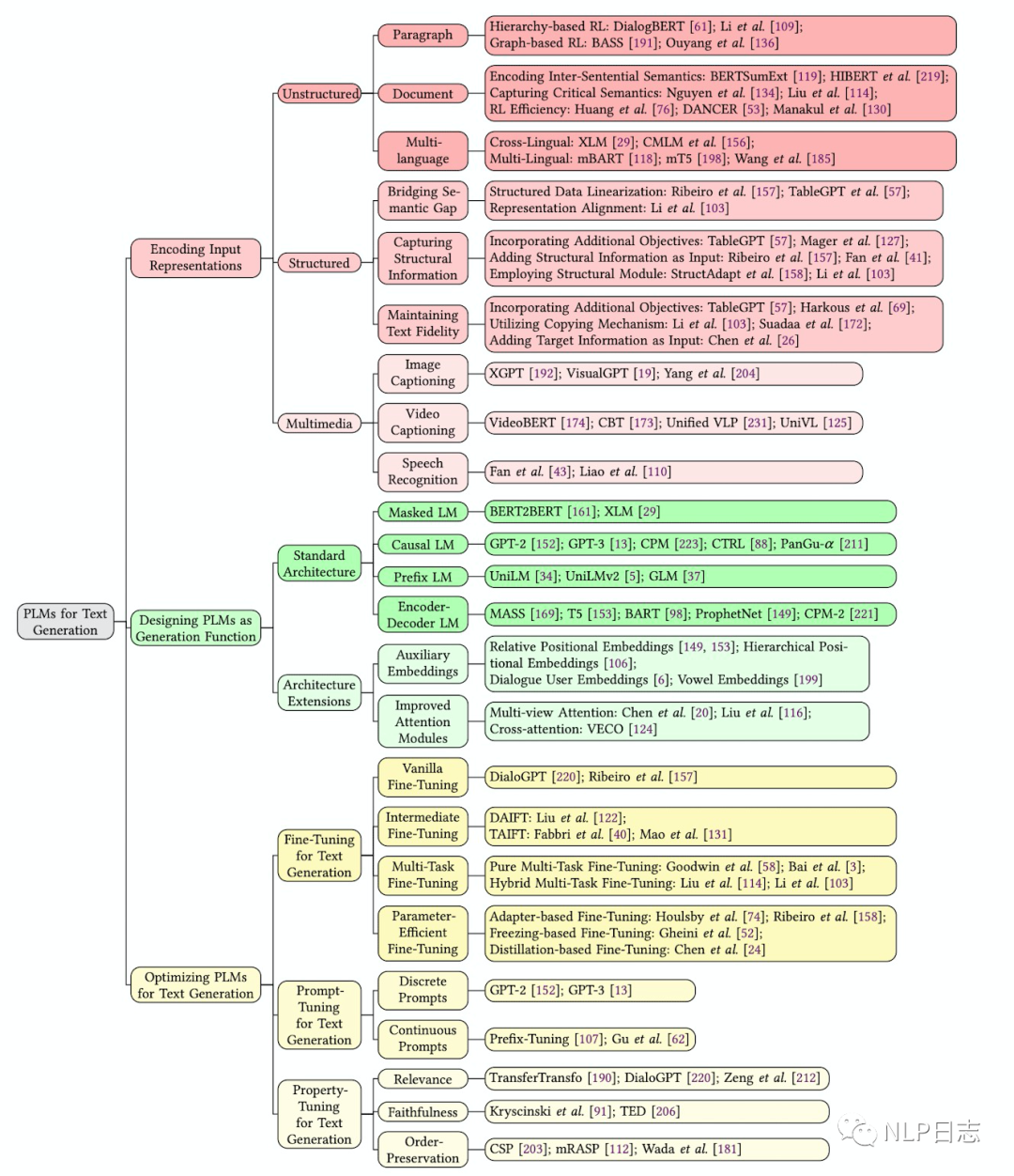
图1: 文本生成预训练模型框架
2. Encoding Input Representations
2.1 Unstructured Input(非结构化输入)
对于文本生成任务而言,大多数研究都集中于对非结构化文本输入建模,包括但不限于句子,段落和文档等。
2.1.1 Paragraph Representation Learning(段落表示学习)
一个段落通常包含多个句子,为了捕捉一个段落中低维度的词义和高维度的主题语义,可以使用基于层次或者基于图的方法去学习段落表征。其中,基于层次的表征学习方法主要是避免直接拼接带来的无视语义动态变化和信息损失导致的解码错误,主要是先对每一个句子进行编码,然后将句子的表征通过另一个编码器进行编码从而得到整体的表征。相比于基于序列的方法,基于图的表征方法可以通过节点跟边的表示聚合不相关的上下文信息。
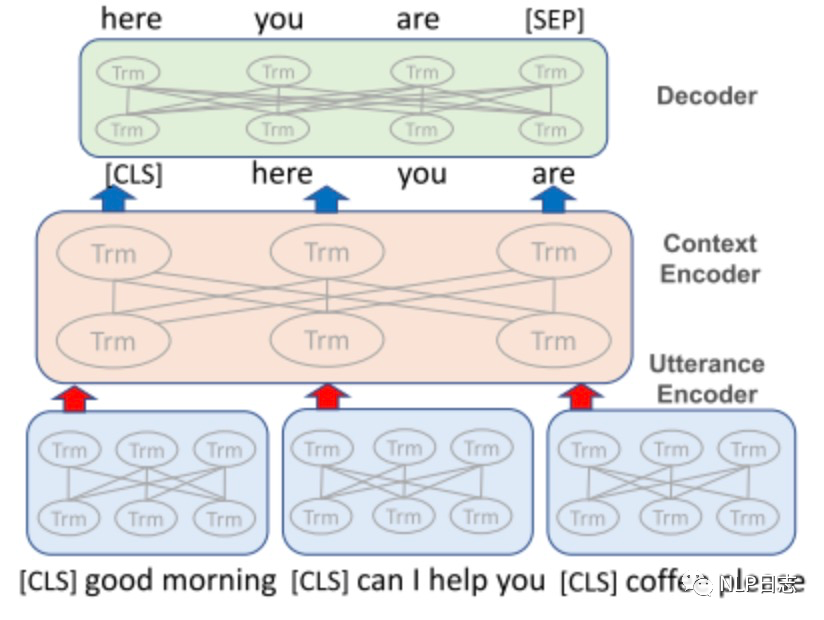
图2: 基于层次的表征学习方法
2.1.2 Document Representation Learning(文档表征学习)
在文档编码过程中,一个挑战就是如何对这些跨句的语义进行编码并捕捉最重要的语义。
a). 使用层次化的方法,例如在每个句子的开始插入[CLS]去收集低层次的句子特征,然后在更高层次使用attention机制将它们合并起来。
b). 捕捉关键语义,文档中的多个句子或者段落难免有重复的内容,所以更重要的是去捕捉关键的语义,可以通过主题模型等方式去抽取全局关键语义并控制如何将语义输入到文本生成相关模块。
c). 学习效率,由于attention机制的计算复杂度跟文本长度的增加是平方关系(计算相似度的时候需要考虑所有两两之间的组合),所以可以通过局部注意力机制和抽取式摘要可以减少内存和计算要求,也可能通过将一个长的文档跟摘要的任务分解成数个短的段落跟摘要的pair对来解决。
2.1.3 Multi-language Representation Learning(多语言表示学习)
大多数的预训练模型都集中在英文文本,而那些低资源的语言则很少被问津。这个问题导致很难直接将单语种的预训练模型应用到多语言的文本生成任务中。
a). Cross-lingual Representation(跨语种表示)
可以学习一个多语种共享的词嵌入空间,可以通过共享BPE或者ngram从而提高模型在多语种翻译中的能力,例如XLM。
b). Multi-Lingual Representations(多语种表示)
多语种旨在学习任何一种语种pair的表示,相比于跨语种表示的共享词嵌入,多语种每个语种都有各自的词嵌入,只是共享encoder而已,例如mT5和mBART.
2.2 Structured Inpu(结构化输入)
结构化数据包括表,图和树等,利用预训练模型对结构化输入建模有三个问题
a). 结构化输入跟预训练模型所使用自然语言输入之间存在语义gap。
b). 缺乏对结构化输入编码的方法。
c). 要求保证文本保有输入信息。
2.2.1 Bridging the Semantic Gap(缩小语义差距)
预训练模型都是都非结构化数据上训练的,现在要用结构化数据作为输入,需要缩小其中的差距。可以通过结构化数据序列化将结构化的数据转化成序列化的文本,或者对齐表示,将非结构化的输入先转换成embedding然后再输入到预训练模型实现。
2.2.2 Capturing Structural Information(捕捉结构化信息)
与非结构化的数据不同,结构化的数据包含结构信息,这些结构信息能帮助模型去理解输入信息从而更好地生成文本。例如表格里设计的<属性,值>或者知识图谱里的<实体,关系,实体>。
a). 加入额外的训练目标,将结构信息作为额外的训练目标,使得预训练模型能对结构信息进行编码。
b). 将结构信息作为额外的输入,例如在输入中可以在知识图谱的三元组前分别加入<H>,<R>,<T>来表示相应的结构信息。
c). 应用结构化编码模块,由于预训练模型一开始是为序列化输入设计的,所以可以使用额外的模块去对结构化输入进行编码。例如可以利用图神经网络GNN对知识图谱里的结构进行编码。
2.2.3 Maintaining Text Fidelity
生成高保真的文本(准确描述结构化输入的信息)是文本生成的核心。
a). 加入额外的训练目标,例如新增一个损失函数去度量输入信息跟输出文本之间的距离。
b). 利用复制机制,可以通过指针网络将重要的信息从输入复制到输出中去。(之前写的“文本生成系列之文本编辑”主要聚焦的就是这个问题。)
c). 增加目标信息作为输入,为了缓解低保真问题,可以使用目标文本的逻辑pattern加入到输入中。
2.3 Multimedia Input(多模态输入)
除了上面的文本数据,文本生成还能用多模态数据作为输入,例如Image Captionsing(图片说明),Video Captioning(视频说明),Speech Recognition(语音识别),输入的多模态的信息需要被编码到特定空间去跟解码器decoder进行对齐。
3. Designing Plms for Text generations(设计文本生成的预训练模型)

图3: 文本生成模型公式
现存的预训练模型都是依赖于Transformers结构,分为分为四种类型。
a). Masked Language Models,使用完整的attention mask矩阵,也就是每个token都看得到其他位置的token,例如Bert。但是由于预训练跟下游任务的不匹配(预训练任务时预测[MASK],下游任务没有[MASK]),很少应用到文本生成任务中,更多的是可以作为文本生成任务中encoder来对输入进行编码。
b). Causal Language Models,使用单向的attention mask矩阵,每个token只能看到在它之前的token,看不到在它之后的token,例如GPT(GPT是第一个应用到文本生成任务的深度预训练模型)。这种模型可以直接应用到文本生成,根据之前的词直接预测下一个位置的词。但是这种方法还有一些结构上的问题,比如只能从左到右进行编码,没办法用到输入的双向信息,。同时也没有解决seq2seq的问题,在包括摘要跟翻译任务上没取得令人满意的效果。
c). Prefix Language Models,是为了解决前面两种类型方法的缺点而被提出的,通过混合的attention mask矩阵,可以实现输入的token可以看到其他输入的token,输出的token可以看到到所有输入的token和在它之前的其他输出的token。例如UniLM。虽然这种方法是特地为文本生成任务设计的,但是实际效果还是赶不上encoder-decoder语言模型
d). Encoder-Decoder Language Models,这是大多数预训练模型所遵循的框架,由encoder跟decoder两部分堆叠形成。
除了依赖于标准的Transformer结构的上述几种方案外,也可以将某些模块做一定的调整适配下游任务。
a). Auxiliary Embeddings, 虽然大多数transformer结构都用了position embedding, 但是相比CNN和RNN,self-attention的操作是不依赖于顺序的,但是对于序列化文本生成而言,顺序是非常关键的,所以可以加入额外的embedding去表征位置信息。
b). Improved Attention Modules, 为了适应长文本,同时缓解attention计算带来的平方复杂度,提出了sparse attention等改进的attention模块。除此之外,还提出了如何处理多个输入改进方法。
4. Optimizing Plms For Text Generation(优化文本生成预训练模型)
在完成对输入数据的编码和设计好预训练模型后,接下来就需要考虑怎么优化预训练模型了。
4.1 Fine-Tuning
虽然预训练模型可以从大量语料中学到通用知识,但是要学到特定任务下的知识还是需要进一步的微调。根据参数的更新方式可以将Fine-Tuning分为以下几种。
a). Vanilla Fine-Tuning, 预训练模型根据特定任务的损失(例如交叉熵)在文本生成任务下作微调,但在数据量少的情况下容易陷入过拟合。
b). Intermediate Fine-Tuning, 利用一个中间任务先对预训练模型微调,有两种不同的方式。Domain Adaptive是先利用同一批数据在另一个任务上微调,然后再在文本生成的任务上微调。Task Adaptive是先用一个领域的数据在文本生成任务上微调,然后再用另一个领域的数据在同一个任务上微调。
c). Multi-Task Fine-Tuning,在微调过程中加入额外的任务,通过利用跨任务的知识,从而提升文本生成的效果。
d). Parameter-Efficient Fine-Tuning, 通过adapter或者固定预训练模型的部分参数或者蒸馏的方式,得到的一种更加高效的微调方案。
4.2 Prompt-Tuning
大部分生成式预训练模型预训练遵循的是语言模型的目标,但是微调过程遵循的是文本生成任务的特定目标,预训练跟微调的不匹配会影响预训练模型在文本生成任务中的表现。而Prompt-Tuning则可以消除这种不匹配。根据prompt的类型可以分为discrete prompts跟continuous prompts两种类型。其中discrete prompts包括手动设置的模版或者自动选择的模版相关的办法,而continuous prompts指的是一个模版的嵌入空间,更加soft。
4.3 Property-Tuning
文本生成任务中我们希望生成的文本可以满足相应的一些需要,所以反过来可以根据希望生成的文本的一些特性去做对应的微调。
a). Relevance(相关性)
保证输入跟输出之间话题变化的相关,例如通过TF-IDF相关的方法选择mask掉更相关的token,迫使预训练模型可以生成更加条件相关的结果。
b).Faithfulness(可信性)
保证输入跟输出之间内容的一致,例如可以在微调时加入跟文本生成相关的损失来迫使预训练模型生成更加一致的内容。
c). Order-Preservation(次序)
保证输入跟输出之间语义的顺序,例如可以通过特定的设计包括词语的pair去对齐输入跟输出。
参考文献
1.(2022)A Survey of Pretrained Language Models Based Text Generation
https://arxiv.org/pdf/2201.05273.pdf
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!














 5718
5718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









