






来着:NLP日志
提纲
1 简介
2 NATURAL-INSTRUCTIONS
3 FLAN
4 FLAN finetune
5 SUPER-NATURALINSTRUCTIONS
6 总结
参考文献
进NLP群—>加入NLP交流群
1 简介
相信大家都体验ChatGPT的功能,任意给定一个任务指令,ChatGPT基本能按照要求生成对应的回复。ChatGPT之所以可以理解这些任务指令,在于语言模型在对应的任务指令数据上进行过训练,也就是instruction tuning,这里的instruction包括任务相关描述定义以及相关的示例。Instruction tuning仿照人类学习的模式,通过简单看下任务定义以及对应示例,就能很好地理解任务要求,从而完整对应的任务指令。Instruction tuning旨在提升语言模型面对NLP任务指令的响应能力,通过监督训练教会语言模型学习按照指令去完成任务,从而语言模型能学会遵循指令的能力,即便是从未见过的任务。Instruction tuning目前是值得研究的方向,可以显著增强语言模型in-context learning能力。
回顾下以前的监督学习范式,训练好的模型只使用于特定领域,特定任务,遇到训练数据中不涉及的领域或者任务时大概率会歇菜。而通过instruction tuning,语言模型会去学习follow instruction,学习该如何遵循命令,在具体推理时,只要写清楚任务命令(即便是新任务,新领域),语言模型就会去解读in-context中的任务命令,生成合适的回复,从而提高in-context learning的能力。
2 NATURAL-INSTRUCTIONS
NATURAL-INSTRUCTIONS是一个instruction相关的任务集,它包括61个不同任务,以及19万+个训练数据。该数据集是通过外包标注获得,为了更好的知道外包人员的标注工作,每个任务对应的任务指令instruction都遵循同一个模版,包含几个部分,具体如下,其中加粗部分是相对重要的元素。
a) TITLE,对任务跟相关技能的高层次描述,类似于一句话概括任务。
b) PROMPT,简单的句子命令,经常出现在instruction跟具体输入之间,起到一个衔接的作用。
c) DEFINITION,关于任务的具体描述。
d) THING TO AVOID,必须要避免的人工标注事宜。
e) EMPHASIS AND CAUTION,标注相关的重要声明。
f) POSITIVE EXAMPLES,该任务下期望的input-output示例,特定任务正样本,规范的任务示例,可以帮助外包人员更好的理解任务
g) NEGATIVE EXAMPLES,不符合预期的input-output示例,不规范的任务示例,THING TO AVOID的具体示例。
h) REASON,关于该示例是正样本或者负样本的解释说明。
i) SUGGESTION,关于如何将该负样本修改成正样本的建议。
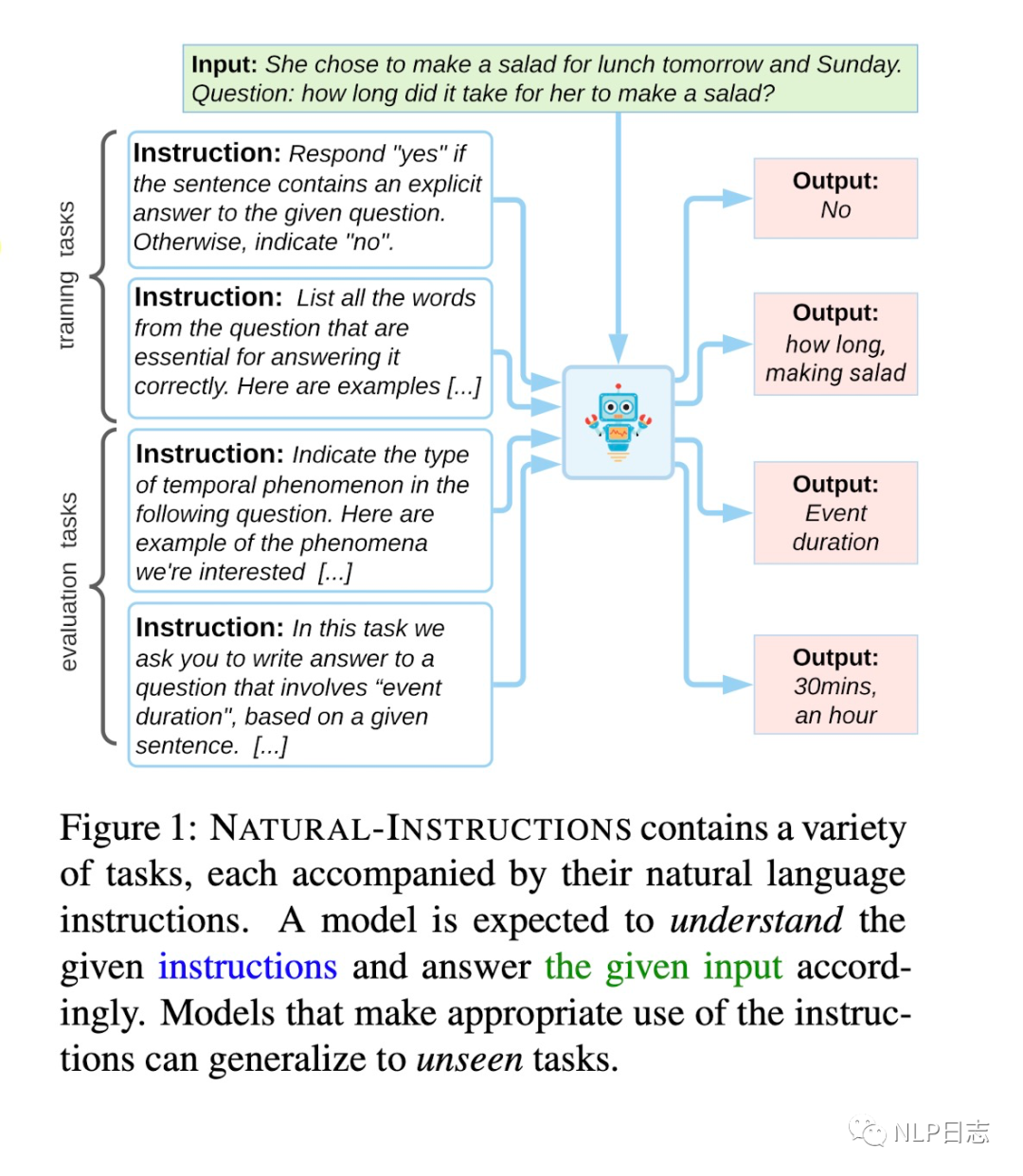
图1: NATUAL-INSTRUCTIONS介绍
这里需要注意的是,通过预先设置好的instruction模版,可以将原有的10个数据集转换成instruction相关的数据集,每个训练数据包括instruction跟对应的input-output示例。为什么这里的任务数量是61,远超原始数据的任务类型数,instruction tuning会将每个数据集上的每种任务类型都会被视作一种任务。例如question-generation这一任务在N个原先数据集上有差异,转换为instruction就可以会变成N个任务了。

图2: instruction示例以及instance示例
在完成instruction数据集的制作后,就让语言模型在该数据上进行有监督的finetune,给定任务指令instruction跟input作为语言模型输入,去生成对应的output。采用的模型包括encoder-decoder的BART跟纯decoder的GPT3(其中GPT3没有finetune),有以下相关发现。
a) 关于instruction里各个元素的作用,实验发现任务指令中的PROMPT跟POSITIVE EXAMPLES非常有用,大部分任务下,PROMPT+DEFINITION+POSITIVE EXAMPLES的效果最好,挡在不同任务下收益有所差异,其他instruction中的元素除了NEGATIVE EXAMPLES也有一定帮助。
b) 无论是在新任务,新数据集上,instruction tuning的效果都有明显提升。随着训练任务数量的增加,泛化性能也逐步提升。但是统一instruction tuning后的模型在新数据集上的性能依旧比不上在该数据上的监督学习模型
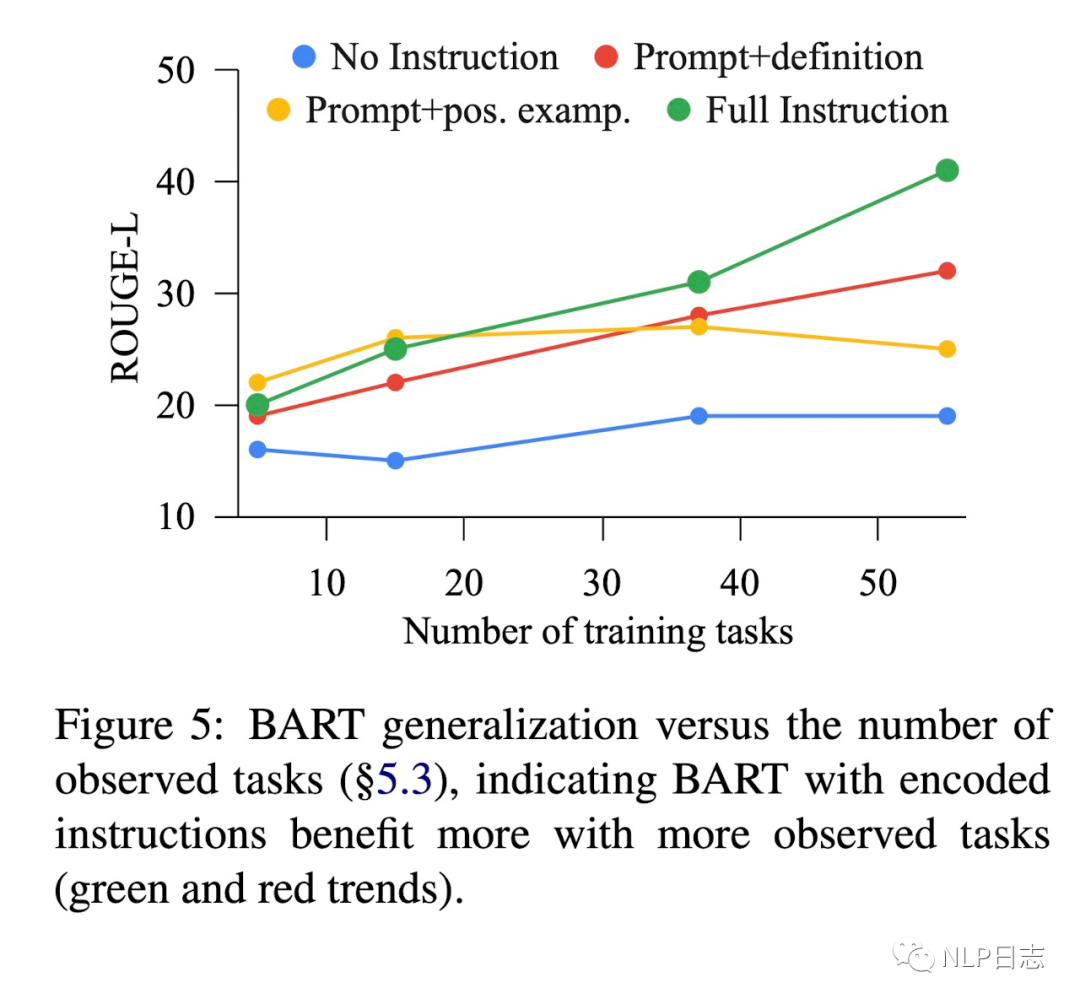
图3:模型泛化能力跟训练任务数的关系
3 FLAN
谷歌的手笔,以DeepMind的LaMDA模型为基底模型,在60多个任务上进行instruction tuning的到FLAN的zero-shot能力得到明显提升。对于每个任务,利用人工撰写10个得到对应的instruction模版,并要保证模版的多样性,对于每个任务下样本,通过随机选择instruction模版转换成新的instruction数据。在训练时,为了保证数据均衡,对于每个任务下的样本数也做了一定限制。
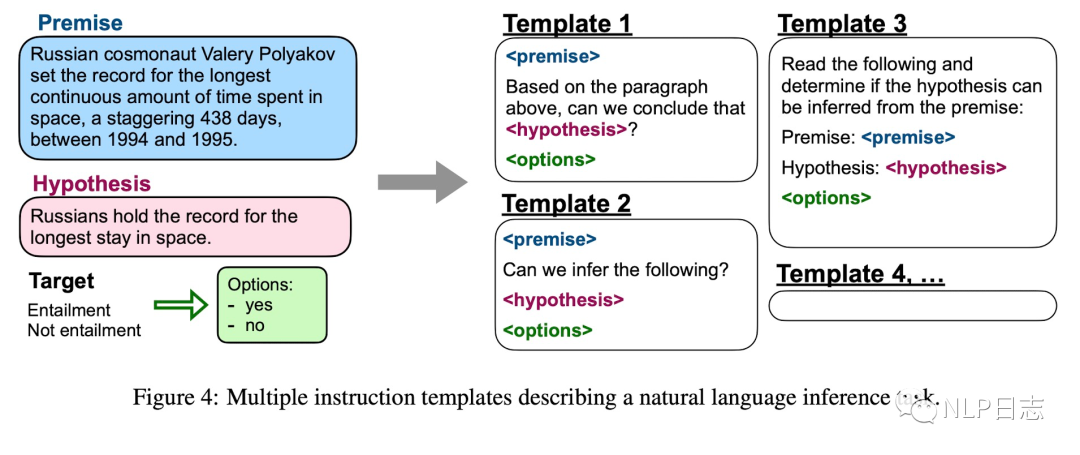
图4: FLAN的instruction模版
a) 无论选择哪种instruction模版,FLAN zero-shot在多个数据集上效果都显著优于zero-shot甚至few-shot的GPT3,甚至在部分数据集超过了在特定数据集上finetune的监督学习模型。
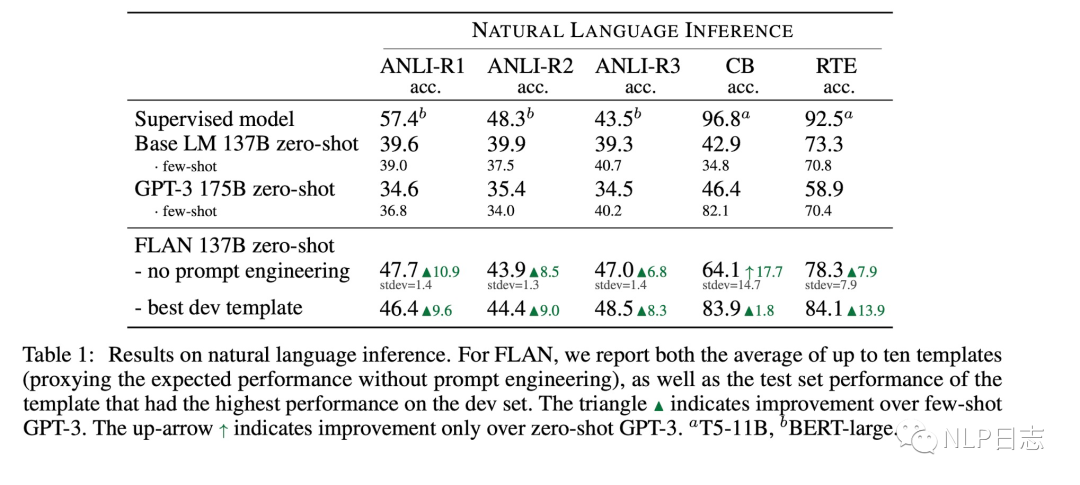
图5: FLAN的效果
b) 增加训练数据中instruction粗粒度任务数量有利于提升模型在新任务下的zero-shot效果。
c) 无论是何种规模的语言模型,在旧任务下instructions tuning都能带来显著提升。而对于新任务,只有在模型规模达到一定程度时,instruction tuning才能带来实质提升,在模型规模不够时,instruction tuning反而会给新任务带来损失,一种可能猜测是模型容量不够,导致在新任务下表现糟糕。
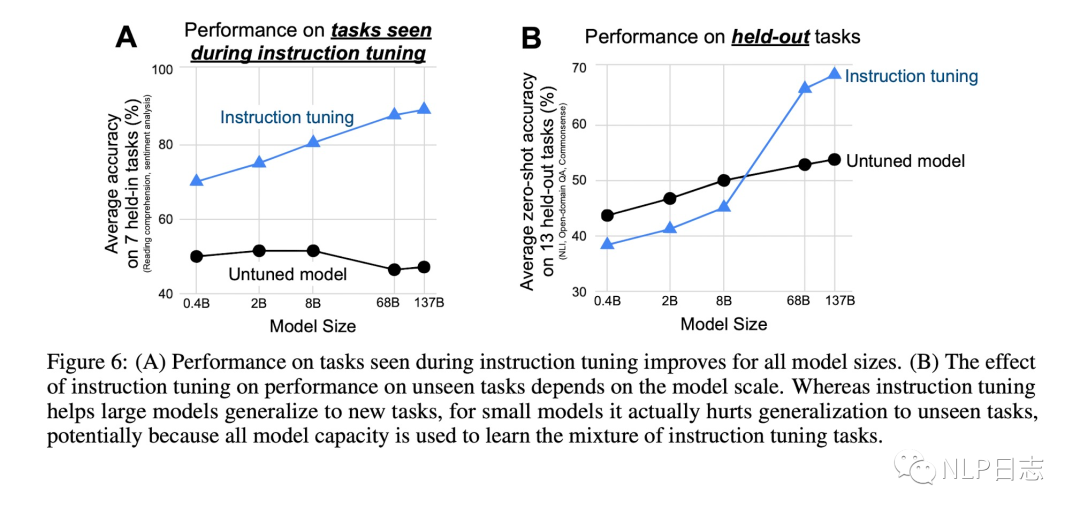
图6: FLAN模型规模的影响
d) Instruction tuning促进了prompt tuning的效果,在所有场景下,FLAN的prompt tuning效果有明显提升,在低资源设置下更是如此。
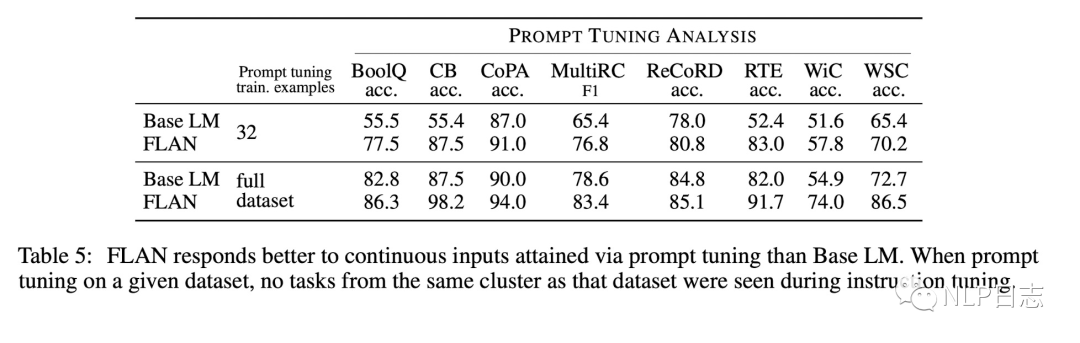
图7: instruction tuning对于prompt tuning的促进
4 FLAN finetune
经过前面的工作后,大家发现了收集大量数据集然后整理成instruction形式给语言模型finetune可以提升模型提升以及在新任务上的泛化能力,于是谷歌进一步探究了任务数量,模型规模以及chain-of-thought数据对于instruction tuning的影响。
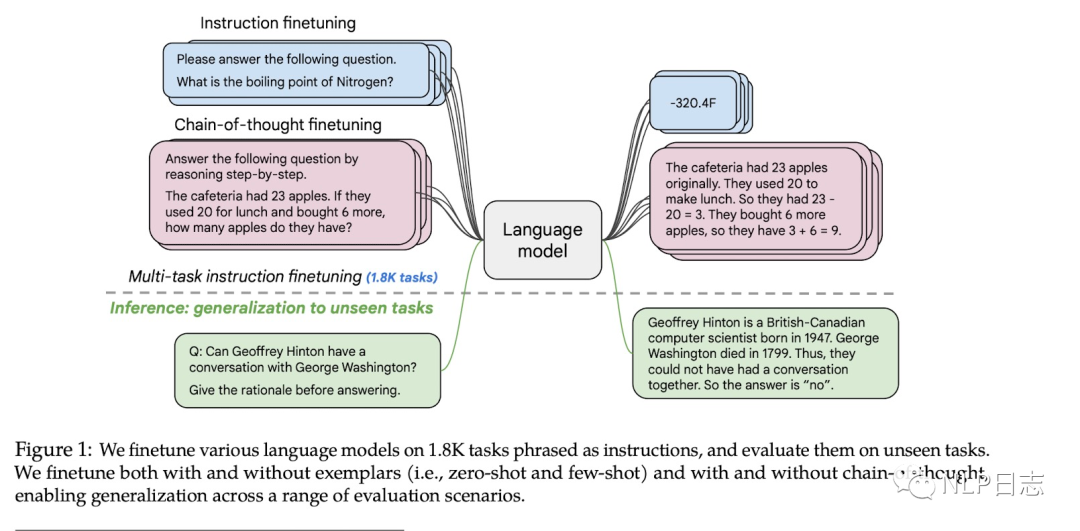
图8: FLAN finetune总体概况
a) 跟前面的方法的区别在于,这个方法instruction tuning涉及的任务数量高达1800多个,随着模型规模跟instruction tuning任务数的增加,模型性能逐步提升。这里可以看到当任务数超过282个,模型性能就没有明显变化,一种解释在于后续的任务跟前面的任务存在雷同,不能为模型带来更多多样性,不能给模型提供新的知识。
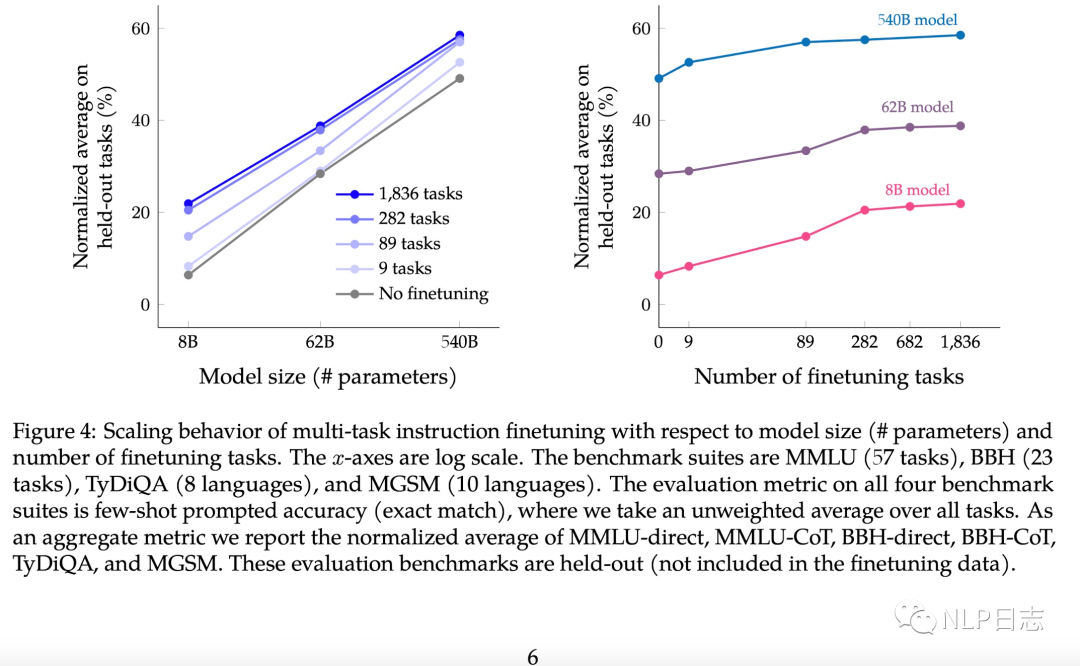
图9: instruction任务数量跟模型规模对于模型性能的影响
b) 加入COT数据可以提升模型推理能力,也能通过“let’s think step by step”进一步解锁zero-shot能力。另外instruction tuning不加入COT数据会损害在COT数据集上的表现,而混合COT跟非COT数据的instruction tuning得到的模型在COT跟非COT数据集上都有很好的表现。
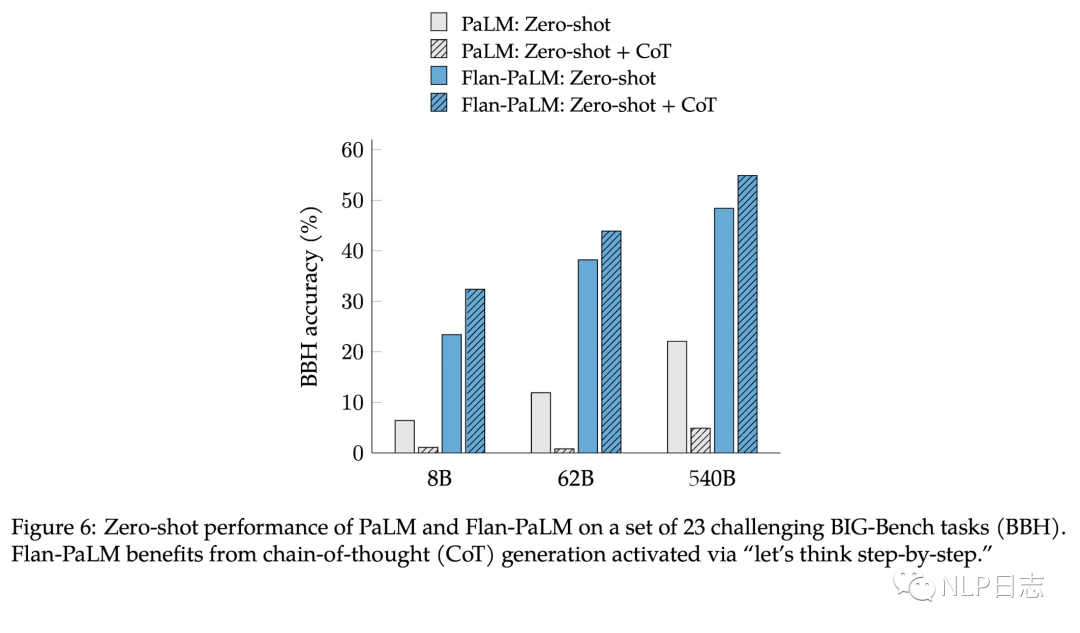
图10: 不同训练方式的zero-shot表现
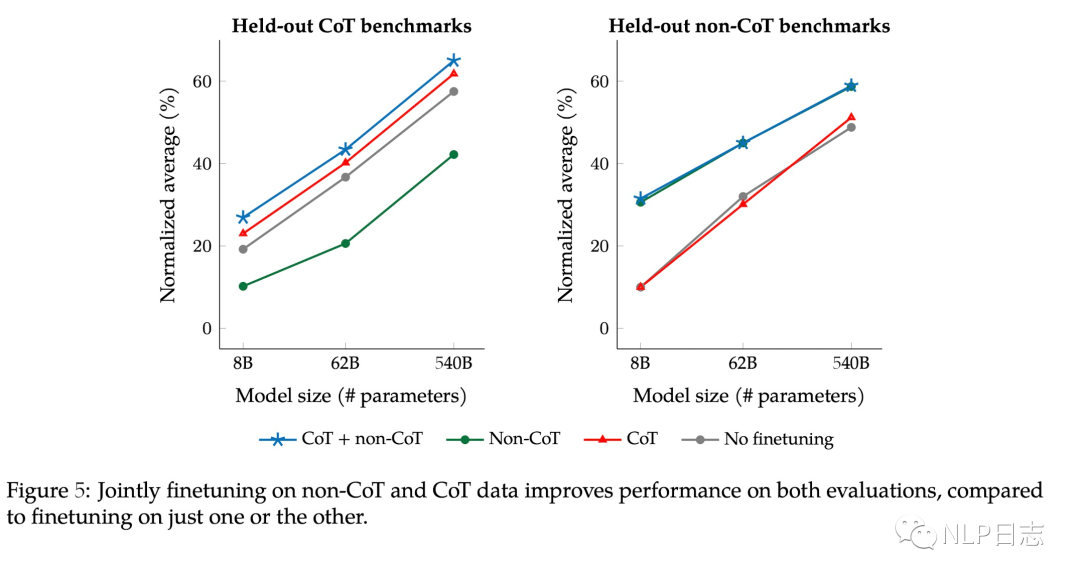
图11: COT跟非COT训练数据不同组合的差异
c) UL2预训练+ instruction tuning的配置取得最好性能。在前面的章节我们也提到过UL2这种预训练能在模型规模是有数十亿的情况出现能力涌现,而普通的预训练方式方式需要在千亿级别的模型下才出现能力涌现,这里的结果也进一步说明这种预训练目标的优势所在。
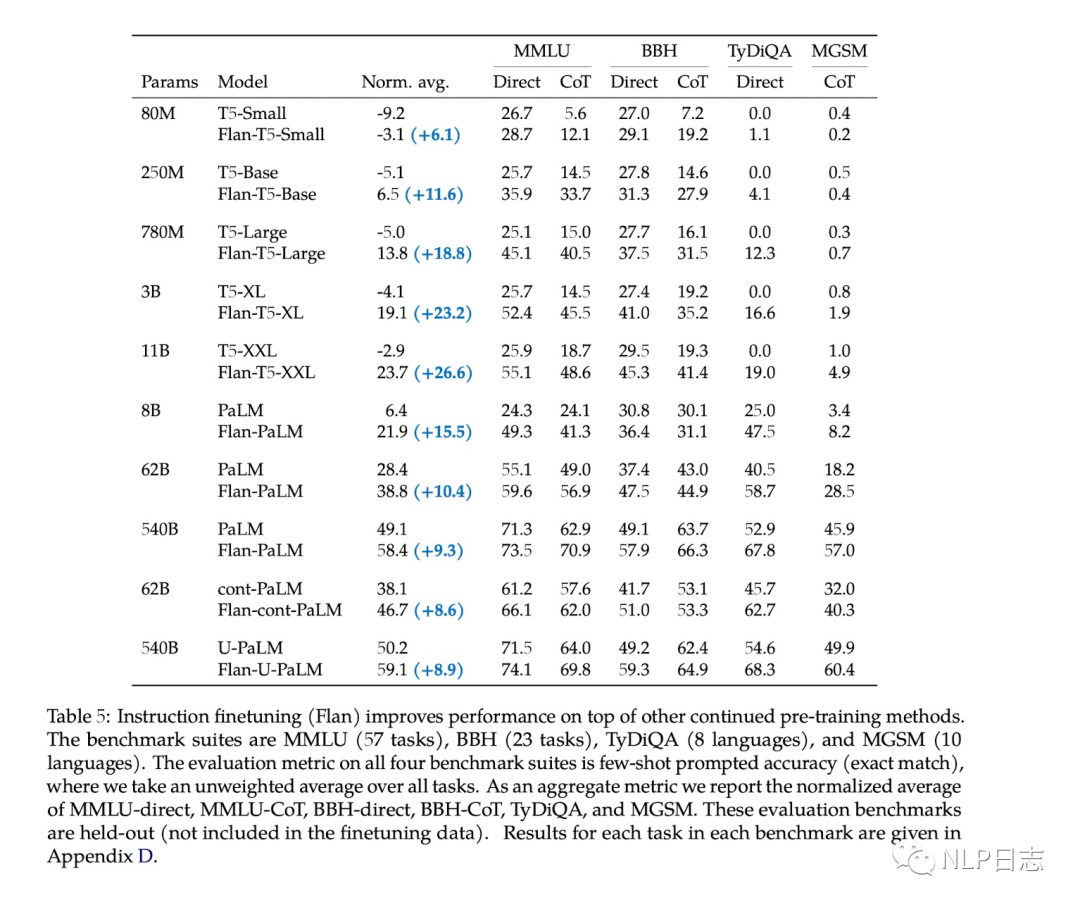
图12: 不同模型设置性能对比
5 SUPER-NATURAL INSTRUCTIONS
SUPER- NATURALINSTRUCTIONS是NATURAL-INSTRUCTIONS的进阶版本,是一个包括1600多个任务的任务指令数据集,它的任务指令模版是NATURAL-INSTRUCTIONS的简化版本,只包含DEFINITION,POSITIVE EXAMPLES,NEGATIVE EXAMPLES。根据任务类型(是问答还是分类),语言,以及领域将数据集划分为1600多个任务。以T5为基底,在该数据集上instruction tuning后得到模型Tk_INSTRUCT。

图13: SUPER- NATURALINSTRUCTIONS任务类型
a) 经过instruction tuning的Tk-INSTRUCT的泛化能力明显优于其他模型,包括InstructGPT,当在新任务上表现依旧不及在该数据集上的监督学习模型。
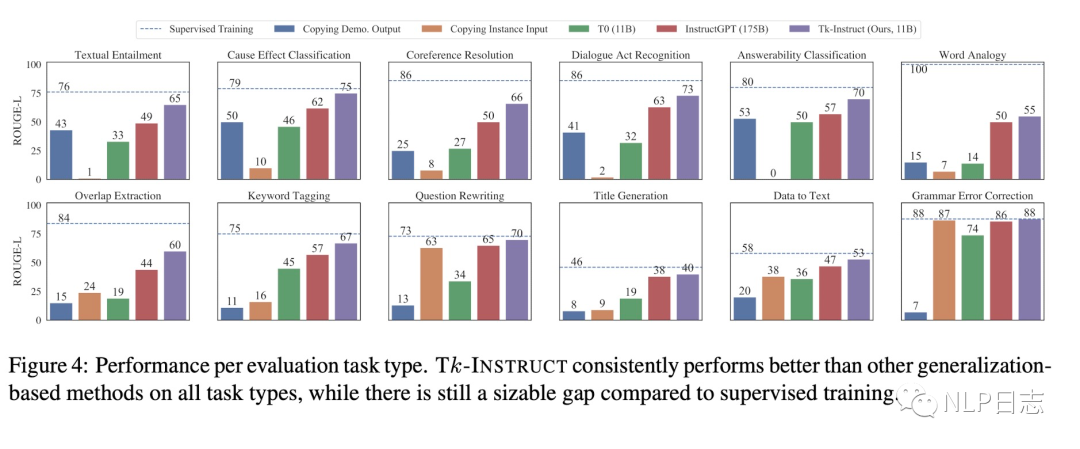
图14: Tk_INSTRUCT性能对比
b) 模型泛化能力跟instruction数据集中任务数量呈现一个对数线性关系。增加特定任务下的训练数据不会有太大帮助,训练时每个任务包含64个样本是一个比较合理的设置。模型规模跟模型泛化能力是正相关。
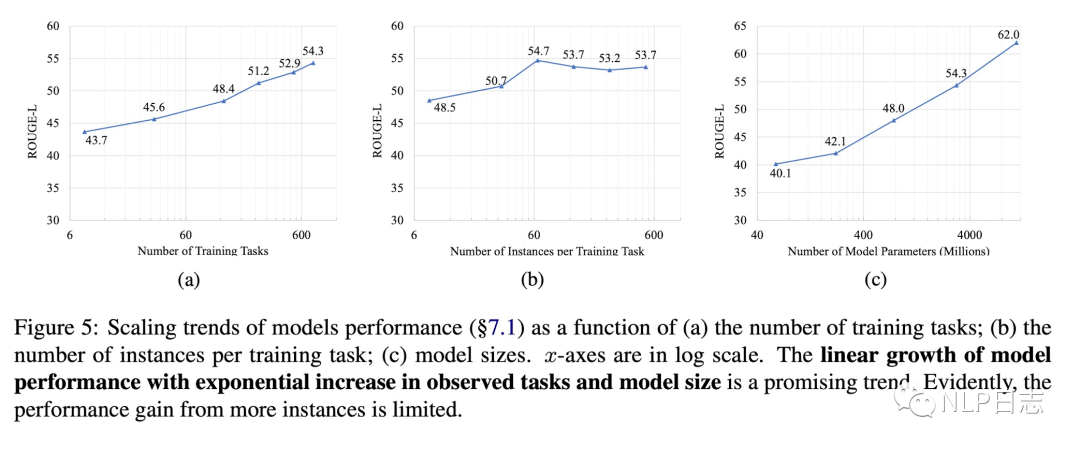
图15: 任务数,样本数,模型规模对于模型性能的影响
c) Instruction指令模版对于模型性能有明显影响。DEFINITION能帮助模型更好泛化,加入POSITIVE EXAMPLES也有提升,但是增加正样本数量就没少影响。此外,训练跟推理时的instruction指令设置也会影响具体推理效果。例如训练时用的instruction指令模版只涉及DEFINITION,推理时的模版只涉及POSITIVE EXAMPLES,那么推理效果会比较差。但是如果训练时struction指令模版涉及DEFINITION跟POSITIVE EXAMPLES,推理时的模版只涉及DEFINITION跟POSITIVE EXAMPLES其中之一,那么推理效果都还不错。
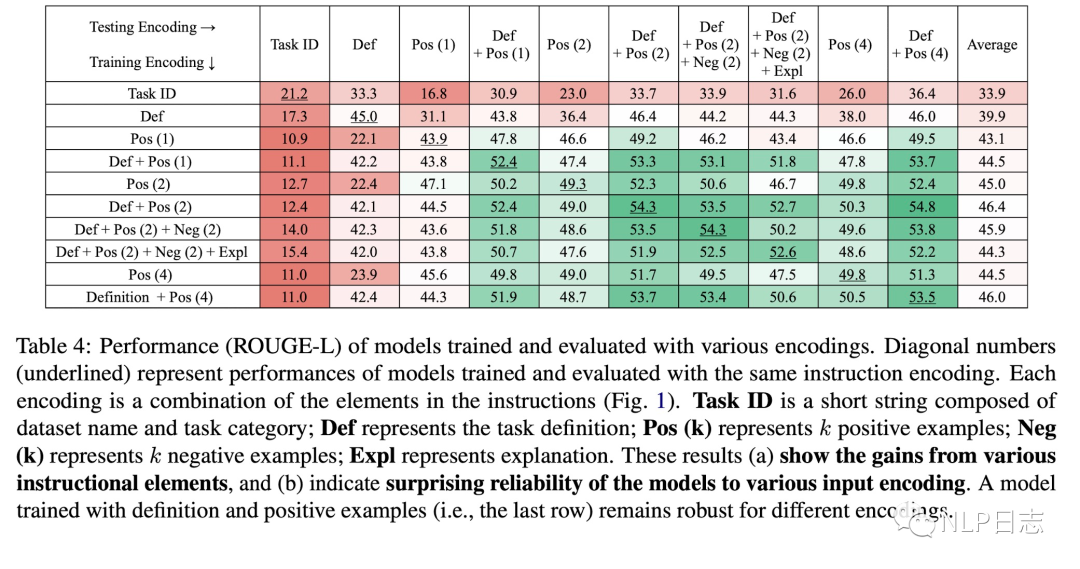
图16: 训练跟推理的instruction指令模版设置影响
6 总结
instrction tuning也属于in-context learing的范畴,跟传统的in-context learning的区别在于引入了任务指令instruction,可以通过让模型在instrcution数据上训练从而提高语言模型的ICL能力,通过提升语言模型理解任务指令的能力,进一步提升泛化能力,在新任务下往往有出人意外的效果。对于instruction的获取方式,除了人工撰写的方式外,目前也有一些工作利用语言模型去生成。除此之外,前面这几个工作都得出了一些相对一致的结论,具体如下:
a) 增加instruction任务数,增加模型规模,都能提升模型的泛化能力,提升在新任务上的性能跟zero-shot能力
b) 加入COT数据可以提升模型的推理能力,混合COT跟非COT数据的instruction tuning可以保证模型在所有数据集上的表现。
c) Instruction指令模版很重要,其中的DEFINITION跟POSITIVE EXAMPLES必不可少,而NEGATIVE EXAMPLES则可有可无。同时需要注意训练跟推理时instruction指令模版设置的差异。
d) 注意不同任务下的数据均衡,每个任务下的训练样本数不需要太多。
e) Instruction tuning的模型在新任务上的表现依旧不及在该数据集finetune的监督学习模型。
参考文献
1. Cross-Task Generalization via Natural Language Crowdsourcing Instructions
https://arxiv.org/abs/2104.08773v4
2. FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS
https://openreview.net/pdf?id=gEZrGCozdqR
3. Scaling Instruction-Finetuned Language Models
https://arxiv.org/pdf/2210.11416.pdf
4. SUPER-NATURALINSTRUCTIONS: Generalization via Declarative Instructions on 1600+ NLP Tasks
https://aclanthology.org/2022.emnlp-main.340.pdf
进NLP群—>加入NLP交流群














 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









