






来自:老刘说NLP
进NLP群—>加入NLP交流群
如何将ChatGPT的能力蒸馏到另一个大模型,是当前许多大模型研发的研发范式。当前许多模型都是采用chatgpt来生成微调数据,如self instruct,然后加以微调,这其实也是一种数据蒸馏的模拟路线。
不过,这种数据蒸馏的方式,只是单向的,并没有进行数据反馈。
最近的一篇文章《Lion: Adversarial Distillation of Closed-Source Large Language Model》 提出了一个将知识从一个复杂的、闭源的大型语言模型(LLM)转移到一个紧凑的、开源的LLM的做法,其中加入了数据反馈的闭环机制,将蒸馏的指令分成困难和简单两类指令,并且逐步来生成困难指令有偏的引导开源LLM模型的学习,取得了较好的效果。
论文地址:https://arxiv.org/pdf/2305.12870.pdf
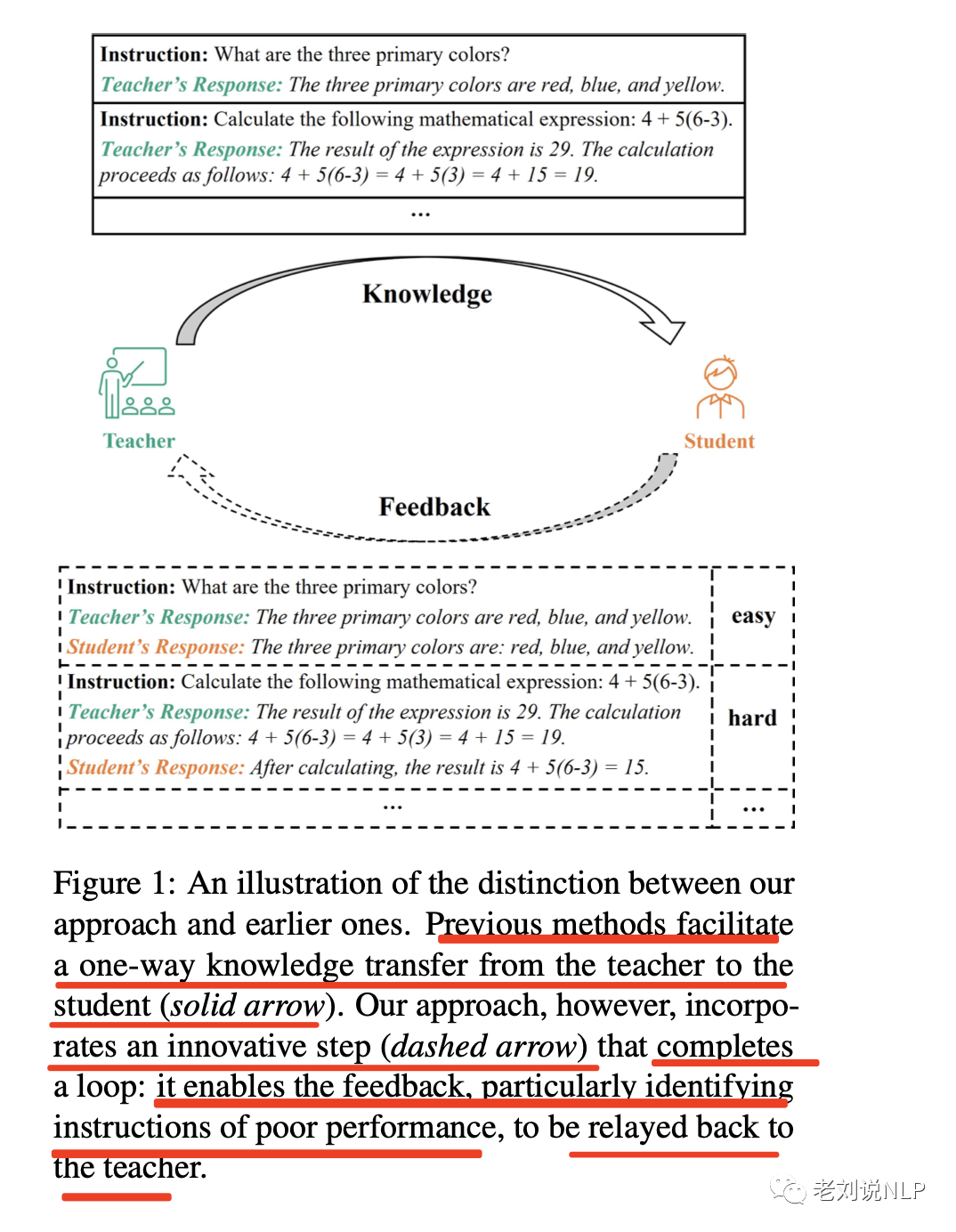
整体框架AKD的工作如图2所示,在一个迭代中分成三个阶段: 1)模仿阶段,使学生的反应与教师的反应保持一致;2)辨别阶段,识别困难指令;3)生成阶段,产生新的困难指令,以升级对学生模型的挑战。
该对抗性知识蒸馏框架可以被解释为一个动态的最小-最大游戏:在模仿阶段,对学生进行微调,使其与教师在硬样本上的模型差异最小;在辨别和生成阶段,根据学生模型的学习进度,制作新的困难样本,使模型差异最大化。
从教育的角度上来看,这种框架推动了学生模型去发现原本隐藏的知识,为完全理解铺平道路,随着训练的进行,经过几次迭代,系统能够最好能达到平衡状态。这时,学生模型已经掌握了所有的硬样本,裁判员R不再能够区分学生S和教师T的模型。
为了验证方法的有效性,该框架将ChatGPT的知识转移到LLaMA上,选择Alpaca的训练数据(仅由175条手动选择的种子指令生成)作为初始训练指令,并执行三次AKD的迭代,总共训练了70K数据,最终得到模型Lion,实验结果表明,7B模型Lion都表现出较好的性能。
本文对该工作的具体算法思想进行介绍,供大家一起参考,其中关于各种prompt,包括打分prompt,指令扩充prompt都是可以关注的点。
一、算法思想方法
利用一个复杂的教师模型T(x; θT)的知识,目标是制作一个更轻便的学生模型S(x; θS)。
理想情况下,如果模型差异的期望值(表示教师T和学生S之间的预测差异)在统一数据分布上达到最小,那么学生模型就是最优的。
受对抗性知识提炼(AKD)的启发,该框架转向优化期望值的上限--"难样本 "上的模型差异期望值,其中教师T和学生S的表现差距相对较大。
这些 "难样本 "倾向于主导模型差异的期望值。因此,通过在这些 "难样本 "上对学生模型S进行优化,可以有效和高效地重新控制整体预期模型差异。
其基本原理是相当直接,可以类比于现实世界的教育场景:持续关注学生认为难以掌握的 "难 "知识,是提高学生能力的最有效方法。
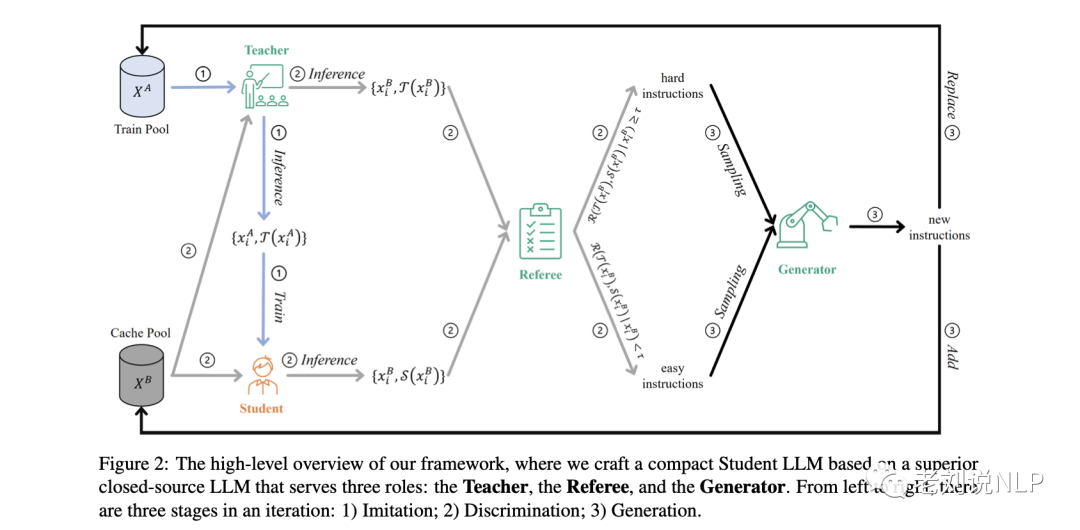
图2描述了对抗性知识蒸馏的整个框架,它包含了一个迭代的三个阶段:
1)模仿阶段,使学生的反应与教师的反应相一致;
2)辨别阶段,识别难样本;
3)生成阶段,产生新的硬样本,以升级学生模型所面临的挑战。
1、初始化
如图2所示,框架中建立了四个角色和两个数据池,并使用使用LLaMA来初始化学生模型S。
通过使用ChatGPT来初始化教师模型T、裁判员R和生成器G,
该框架从一个给定的初始Train Pool XA = {xAi }i∈[1,NA]开始迭代,其中xAi是XA中的第i条指令,NA是XA中的样本数。
Cache Pool XB的初始化与XA相同,由评估S和T性能的指令组成。
注意,这里的指令是由指令提示和实例输入组成的,如下表所示:

2、模仿阶段
损失函数采用Kullback-Leibler Divergence,即KL散度,用于量化教师模型T和学生模型S的输出概率分布的差异。
因此,为了将教师的知识传递给学生,通过教师T向前传播训练池XA中的指令,构建训练数据{xAi, T (xAi )}i∈[1,N A]。
有了这些训练数据,其中xAi作为输入,T(xAi )作为目标,通过最小化交叉熵损失来微调我们的学生模型S。
3、识别阶段
图2展示了从缓存池开始的判别阶段,表示为XB。
大型语言模型如ChatGPT,有可能作为无偏见的裁判来衡量两个不同的人工智能助手产生的回复质量,也就是使用chatgpt进行打分。
在具体实现上,将缓存池XB中的每条指令xBi通过教师T和学生S反馈,分别产生输出T(xBi)和S(xBi)。然后要求裁判员R量化教师的响应T(xBi)和学生的响应S(xBi)之间的质量差异,di用来表示这两个分数之间的差异。di的计算公司如下:
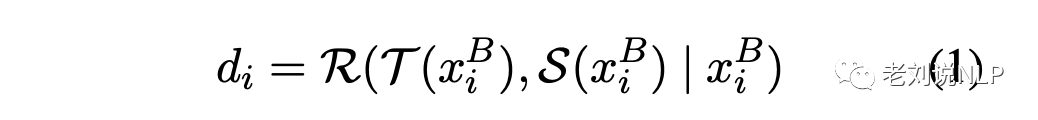

上述过程是通过使用表2的提示模板来完成,该模板要求LLM考虑两个回答的有用性、相关性、准确性和详细程度,并输出两个分数。
两个分数之差,就是di,可以通过设置一个阈值τ(在实验中使用的是1.0),将困难的指令划分为那些di≥τ的指令,而其他的则被识别为简单的指令。
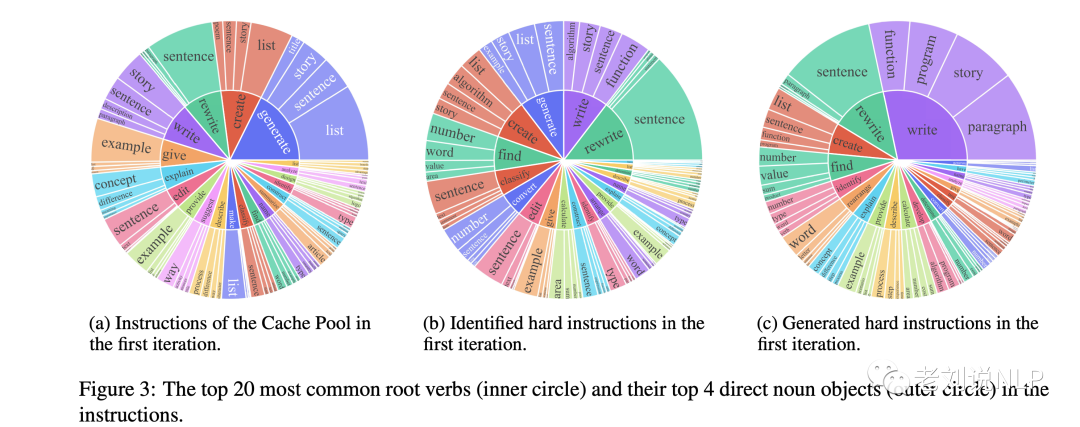
图3直观地展示了在第一次迭代中哪些类型的指令被识别为困难指令。与cache池中的指令相比,被识别的罗曼指令的分布是非常不同的,它们更侧重于复杂的任务,如数学、编码等。
4、生成阶段
在仔细识别了困难指令之后,生成阶段的目标是产生反映这些困难指令所对应的数据分布的样本。
这个过程通过使用复杂的LLM作为生成器G来实现,并从困难指令中随机抽取一条指令,并提示生成器G生成一条新指令。新生成的指令需要与同一领域有关,并与抽样指令的任务类型相匹配,如下表3显示了用于该提示的模板。

如图3所示,指令要求新生成的硬性结构的分布似乎与先前确定的硬性指令的分布相类似。为了减轻灾难性遗忘的问题并增加生成指令的多样性,还从简单指令中随机抽出一条指令,并提示生成器G生成一条新的指令,该指令与抽出的指令属于同一领域,但也呈现出更多的长尾分布,使用的指令模板如下所示:

为了控制迭代的比率,在每个迭代中,将N定义为新生成指令的总数量,然后在生成的困难指令和简单指令之间保持1:1的比例。
为了保证多样性,只有当一条新指令与缓存池中任何现有结构的ROUGE-L重叠度低于0.7时,才会被视为有效。
最后,将对Train Pool进行更新,用新生成的指令替换现有指令。同时通过加入这些新生成的指令来扩充缓存池。
在具体训练过程中,该学生模型是用预先训练好的LLaMA 7B进行初始化。Train Pool和Cache Pool用Alpaca的52K in-struction数据集进行初始化。迭代总次数设置为3次,每次迭代增加6K新生成的指令,最终形成训练了70K数据。
在花费方面,学生模型在8个A100 GPU上训练了3个epochs,请求使用gpt-3.5-turbo API大约36万次,这个数字大约是WizardLM使用量624k的一半,产生了相当大的费用,接近500美元。
二、测试数据集与实验模型
1、数据集
评估LLM在各种任务中的功效是一个相当大的挑战,因为不同的任务需要相当不同的专业知识,而且许多任务不能用自动指标来评估,在实验中采用了两个著名的数据集:
Vicuna-Instructions:一个由GPT-4合成的数据集,包含80个基线模型认为具有挑战性的问题。该数据集横跨九个不同的类别,即通用、知识、角色扮演、常识、费米、反事实、编码、数学和写作。以用户为导向的指导。
User oriented Instructions:一个人工组装的数据集,包括252个结构,其动机是71个面向用户的应用,如Grammarly、StackOverflow、Overleaf。
2、对比模型
对比实验选用五个模型:
LLaMA:一个基础语言模型的集合,参数范围从7B到65B。它在公开可用的数据集上训练了数万亿个标记,并被证明在多种基准中优于较大尺寸的LLM,如GPT-3(175B)。使用LLaMA 3的7B参数版本。
Alpaca:以LLaMA为基础,通过查询OpenAI的text-davinci-003模型产生的52K个指令跟随实例进行微调。使用Alpaca 4的7B参数版本。
Vicuna:以LLaMA为基础,并根据从ShareGPT收集的7万个用户共享对话进行了微调。使用FastChat 5的7B参数版本。
WizardLM:使用Evol-Instruct方法,将Alapca的52000条指令的例子引导到250000条更复杂的指令集中。使用WizardLM 6中的7B参数版本。
ChatGPT:通过监督和强化学习技术进行微调,由人类培训师提供必要的反馈和指导。使用ChatGPT3.5 turbo版本。
3、评测结果
首先看自动化评估,使用GPT-4的方式进行模型自动打分,用于评价在给定封闭集合上的性能表现,对应的prompt如下,采用与识别困难样本的prompt一致。

实现结果如下,GBS评测来看,Lion除了与ChatGPT有差距外,均好于其他模型。
再看使用人工评价的方式,进行对齐能力,如果一个聊天助手的特点是乐于助人、诚实和无害(HHH),则被认为是一致的。这些标准被用来衡量人工智能(AI)系统与人类价值观一致的程度。结果如下:
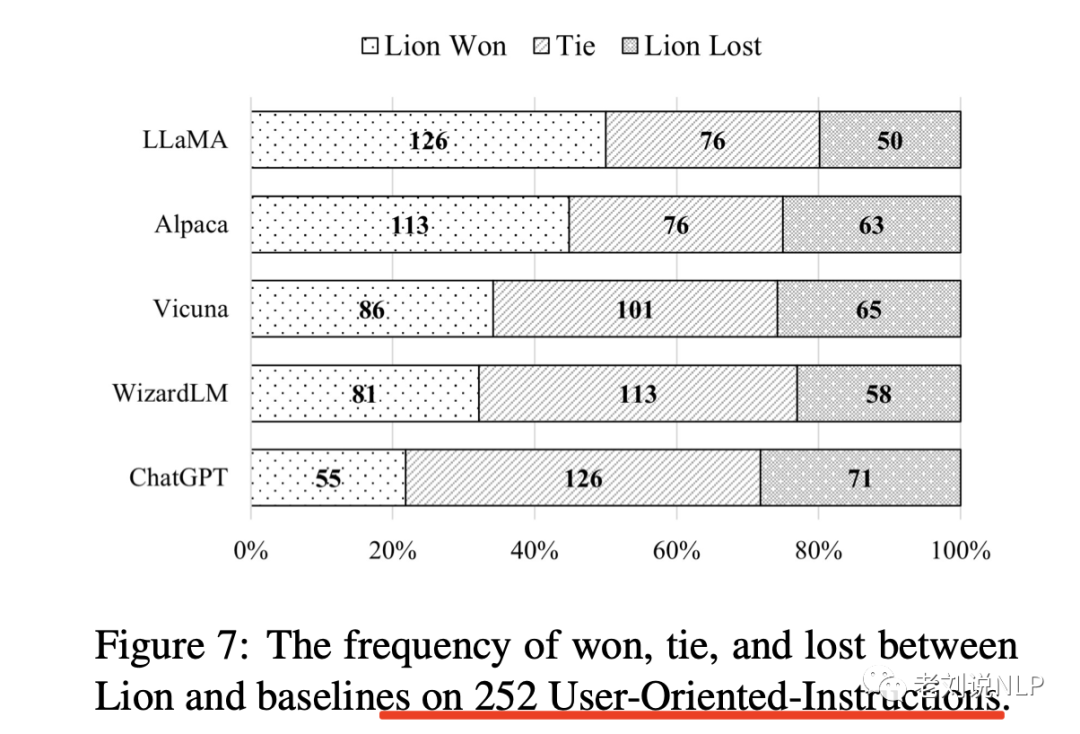
我们可以看到,Lion也能得到一个与自动化评测一致的效果。
下面再看一个具体的模型预测效果,这是个比较好的case:

总结
本文对《Lion: Adversarial Distillation of Closed-Source Large Language Model》这一工作进行了介绍。
与Alpaca和WizardLM这样只对学生模型进行一次微调的方法相比,该工作提出的对抗性知识蒸馏方法采用了对学生模型的迭代更新,得到了更好的效果。
不过这种迭代方法也有一些现实问题,例如:
首先,不可避免地导致了较慢的迭代速度。
其次,与传统的对抗性知识蒸馏方法不同的是,该方法使用一个黑箱和参数冻结的ChatGPT来扮演这个角色,LLM的质量在新指令的生成中相当重要。
另外,在评估方面,尽管利用GPT-4进行的自动评估在评估聊天机器人的表现方面展示了良好的前景,但该技术尚未达到成熟和准确的水平,特别是考虑到大型语言模型容易产生不存在的或 "幻觉 "的信息。此外,缺乏一个统一的标准来评估大型语言模型,这降低了基于人类的评估的说服力。
最后,为聊天机器人创建一个全面的、标准化的评估系统是一个普遍的研究挑战,需要进一步的探索和研究。当前,已经出现了很多鱼龙混杂的各类榜单,而且排名的结果还不不一样,这其实又是另一个混沌状态,这需要引起我们的重视,并擦亮眼睛。
参考文献
1、https://arxiv.org/pdf/2305.12870.pdf
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
进NLP群—>加入NLP交流群















 862
862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









