






进NLP群—>加入NLP交流群

TJUNLP

论文名称:
X-RiSAWOZ: High-Quality End-to-End Multilingual Dialogue Datasets and Few-shot Agents
论文作者:Mehrad Moradshahi*, Tianhao Shen*, Kalika Bali,Monojit Choudhury, Gaël de Chalendar, Anmol Goel, Sungkyun Kim, PrashantKodali, Ponnurangam Kumaraguru, Nasredine Semmar , Sina J. Semnani, Jiwon Seo,Vivek Seshadri, Manish Shrivastava, Michael Sun, Aditya Yadavalli, Chaobin You, Deyi Xiong+,Monica S. Lam+(*为共同第一作者,+为共同通讯作者)
论文单位:Stanford University (斯坦福大学), Tianjin University (天津大学), Microsoft (微软), Université Paris-Saclay (巴黎-萨克雷大学), International Institute of Information Technology (印度海得拉巴国际信息技术研究所), Hanyang University (汉阳大学), Karya Inc (Karya公司).
录用会议:ACL 2023 Findings
论文链接:https://arxiv.org/abs/2306.17674
数据链接:https://github.com/stanford-oval/dialogues
1.
引言
由于构建任务型对话数据集的成本较高,目前任务型对话的研究主要集中在少数流行语言上(如英语和中文)。为了降低新语言的数据采集成本,我们通过结合纯人工翻译和人工编辑机器翻译结果的方式创建了一个新的多语言基准——X-RiSAWOZ,该数据集将中文RiSAWOZ翻译成4种语言:英语、法语、印地语、韩语,以及1种语码混合场景(印地语-英语混合)。X-RiSAWOZ中每种语言都有超过18,000个经过人类验证的对话语句,与之前大多数多语言工作不同的是,它是一个端到端的数据集,可用于建立功能齐全的对话代理。除数据集外,我们还构建了标注和处理工具,使得向现有数据集中添加新语言变得更快、更经济。
2.
数据集介绍
任务定义:端到端任务型对话通常被分解为若干子任务,这些任务可以由流水线系统或单个神经网络执行。下图展示了这些子任务及其输入和输出:
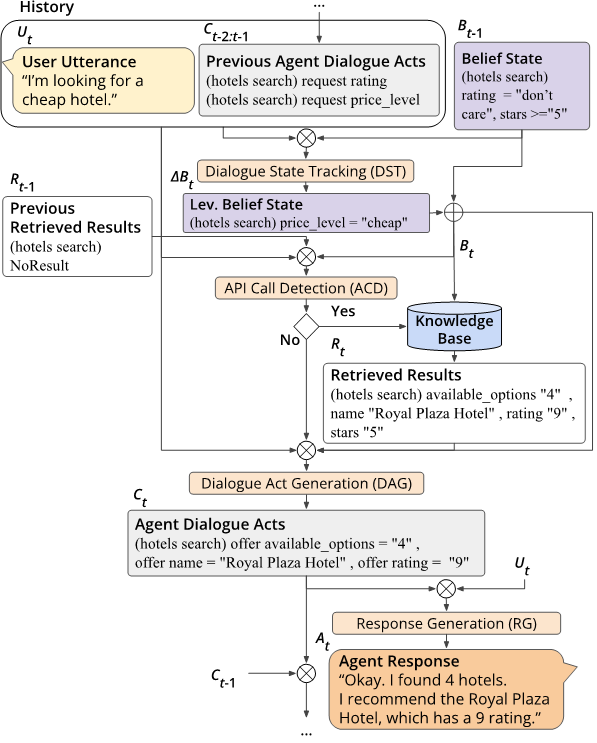
图1:端到端任务型对话流程
数据来源:我们翻译了RiSAWOZ数据集的验证集与测试集,同时为了促进少样本对话系统的研究,我们还随机选取了1%的训练集进行翻译,统计数据如下表所示:
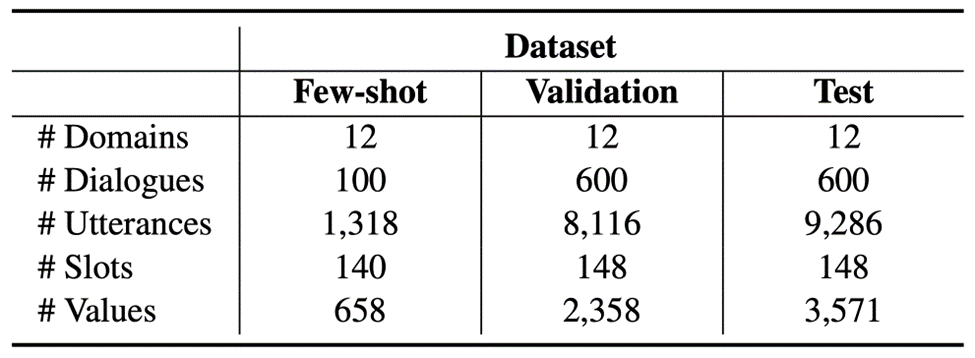
图2:X-RiSAWOZ数据集统计
数据集构建方案:为了实现低成本和高质量的多语言端到端任务型对话数据构建,我们使用以下几种技术从源语言数据(中文RiSAWOZ数据集)创建目标语言的训练数据:
1. 翻译:为了在质量和成本之间取得平衡,我们使用纯人工翻译从中文翻译成英文,并使用机器翻译和后期编辑将英语数据翻译成其他语言,以尽可能避免两次翻译过程中可能的错误传播。
2. 对齐:我们提出了一种混合对齐策略,以确保实体在话语和信念状态中都能被替换为所需的翻译。具体而言,我们首先尝试使用基于实体标注构建的字典对齐,如果输出中没有匹配的翻译,则退回到神经对齐(即使用encoder-decoder cross-attention权重匹配源语言和目标语言中相对应的实体)。
3. 自动标注检查:我们开发了一个标注检查器来自动标记和纠正可能存在的错误,包括1)实体检查阶段——确保在实体的英语翻译中所做的更改传播到其他目标语言的翻译,以及2)API检查阶段——通过将翻译后API调用的结果与提供的真实值进行比较来检查API的一致性。
数据构建与检查的流程如下图所示:
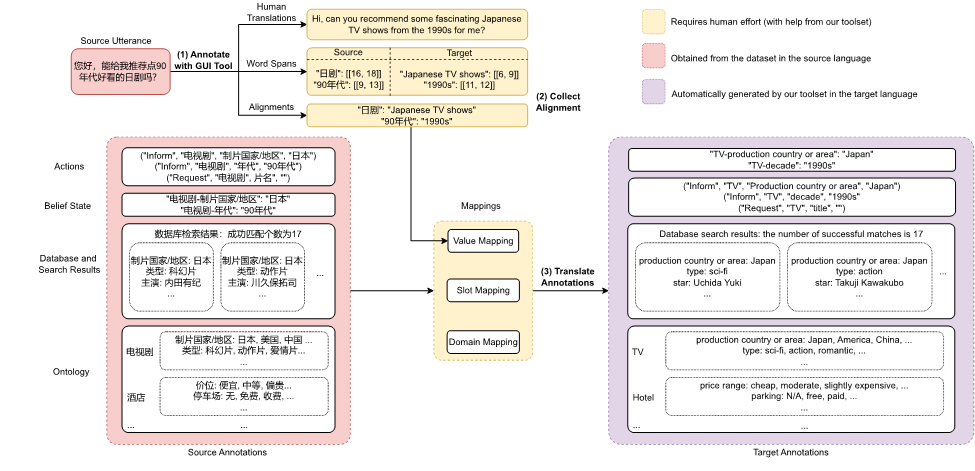
图3:数据集构建流程(以汉语到英语为例)
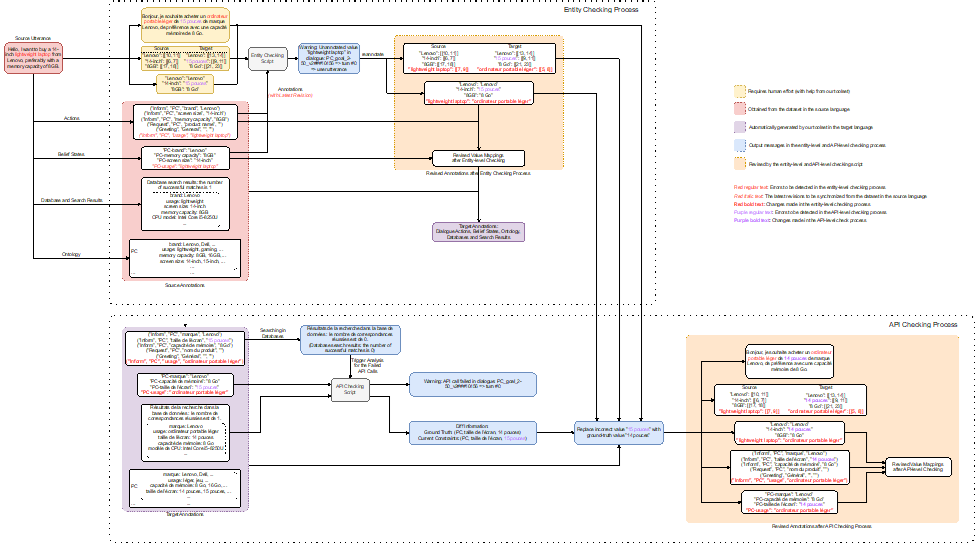
图4:数据集检查流程(以汉语到法语为例)
3.
实验结果
我们使用了mBART和m2m100 (for Korean only) 进行实验。对于零样本实验,我们不使用任何人工创建的目标语言数据,只使用基于机器翻译自动创建训练数据。对于少样本实验,我们从零样本模型开始,并在目标语言的少样本数据集上进一步对其进行微调。实验的评估方式有两种:Turn by Turn Evaluation和Full Conversation Evaluation。
Turn by Turn Evaluation:在这种设定下,我们在评估中使用所有先前轮次和子任务的ground truth数据作为输入。结果表明,在零样本设置中,性能因添加的语言而异,各个语言在对话状态追踪 (DST)达到了34.6%-84.2%的准确率,在对话动作生成 (DA)上达到了42.8%-67.3%的准确率,而在回复生成 (RG)上达到10.2-29.9的BLEU值,这意味着零样本任务型对话在低资源语言场景下仍然是极具挑战的任务。在少样本数据上进行微调可以改善所有语言的所有指标,其中DST提高到60.7%-84.6%,DA提高到38.0%-70.5%,而BLEU则提高到了28.5-46.4。从下图的数据中可以看到,在印地语、韩语和英语-印地语中,DST的改进尤其明显,因为在这些语言中,机器翻译的质量可能不太好。尽管如此,将自动翻译的数据添加到训练中也能够大大提高这些语言上任务型对话系统的准确性,超过了仅用少量人工构建数据训练的效果。
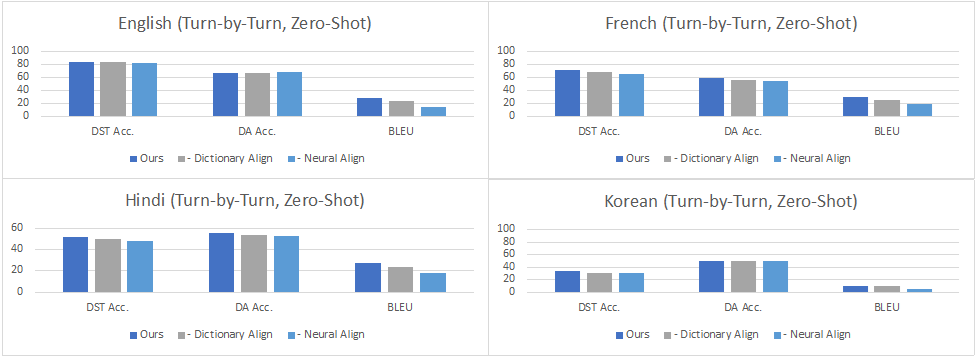
图5:零样本Turn by Turn Evaluation的结果
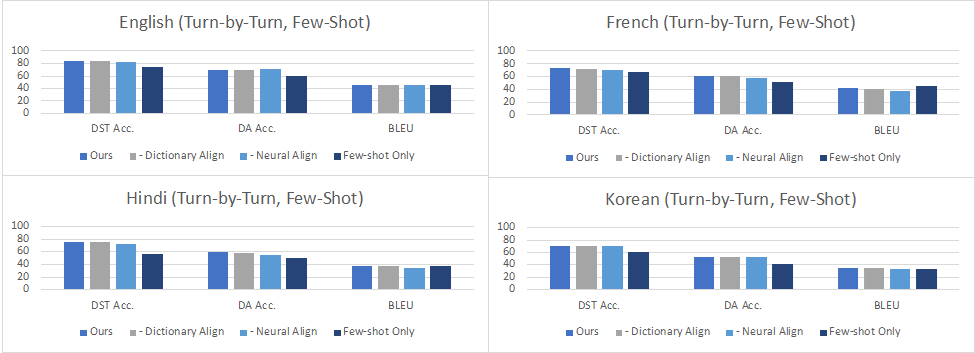
图6:少样本Turn by Turn Evaluation的结果
Full Conversation Evaluation:在这种设定下,对于每个轮次,模型从上一个子任务的输出中获取输入,用于下一个子任务。这反映了与用户进行交互式对话时的实际情况。结果显示,在零样本设置中,性能同样因语言而异,其中英语、法语、印地语、韩语和英语-印地语的对话成功率分别达到了使用完整数据训练的中文对话模型的35%、16%、9%、11%和4%。在少-shot设置中,这个比率提高到了38%、26%、25%、23%和5%。可以看到,最小和最大的改进分别在英语和印地语数据集上。这表明,当预训练数据的质量较低时,少样本数据的影响更大,这可能与中文和目标语言之间的翻译模型的质量有关。
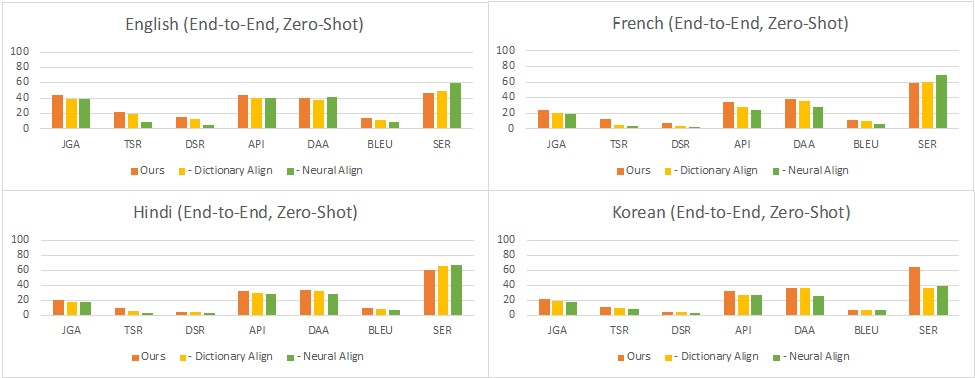
图7:零样本full conversation evaluation的结果
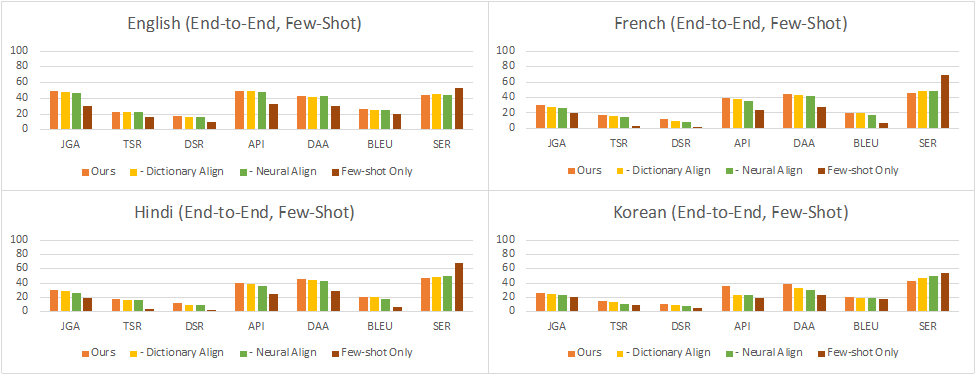
图8:少样本full conversation evaluation的结果
4.
结语
我们构建了X-RiSAWOZ,这是一个新的端到端、高质量、大规模的多领域多语种对话数据集,其涵盖了5种不同的语言和1种语码混合场景,以及一个工具包,以便将数据翻译成其他语言。我们还为跨语言迁移的零/少样本对话系统提供了强大的基线系统。总体而言,我们的工作为更高效、更具成本效益的多语言任务型对话系统的开发铺平了道路。
撰文 | 沈田浩
责编 | 黄宇霏
终审 | 熊德意


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









