






来自:李rumor
NICE26期 | 大语言模型多选题评估的偏见与鲁棒性
大模型训练中,数据质量已经是所有人的共识了。在23年开始接触Alignment之后,我一直是人工标注流派,深信InstructGPT[1]中所描述的,先train好标注员,再train好模型。那时候各个模型的质量也都一般,合成的数据一眼就能挑到一堆毛病。
事情的转折要从sora开始,了解到那么好的效果居然大量应用了合成数据之后,我开始意识到自己还停留在上一个时代。首先大模型的能力是一直在提升的,去年还被狂吹的GPT3.5现在已经被甩了几条街了,大模型在很多任务上都可以达到人类标注员的水平;其次在大模型时代,应该多去发掘模型的价值,学会和AI协作,而不是上来就先验地觉得模型生成的数据质量不过关。
随着业内模型能力和使用熟练度的整体提升,今年数据合成的工作一波又一波,数据合成的前景非常客观:
合成Prompt:GPT系列相比竞品的一个显著优势是数据飞轮,有源源不断的用户输入。合成的Prompt则可以补足多样性上的缺陷,今年Nemotron[2]、Llama3[3]的技术报告中都有跑通他们自己的飞轮
合成Pair对:RLHF阶段由于会hack RM或者依赖人工标注的Pair对,一直很难scale up起来,而当LLM-as-Judge的方式达到一定精度时,模型就可以进行self-play,不断判别->训练,用左脚踩右脚的方式提升效果
指令合成
Prompt数据需要兼具多样性和复杂度。
对于多样性,最常见的方法是人工制定一个类目体系,比如最早的Self-Instruct[4],有175个种子任务,每个任务配一个指令和例子让模型进行合成:
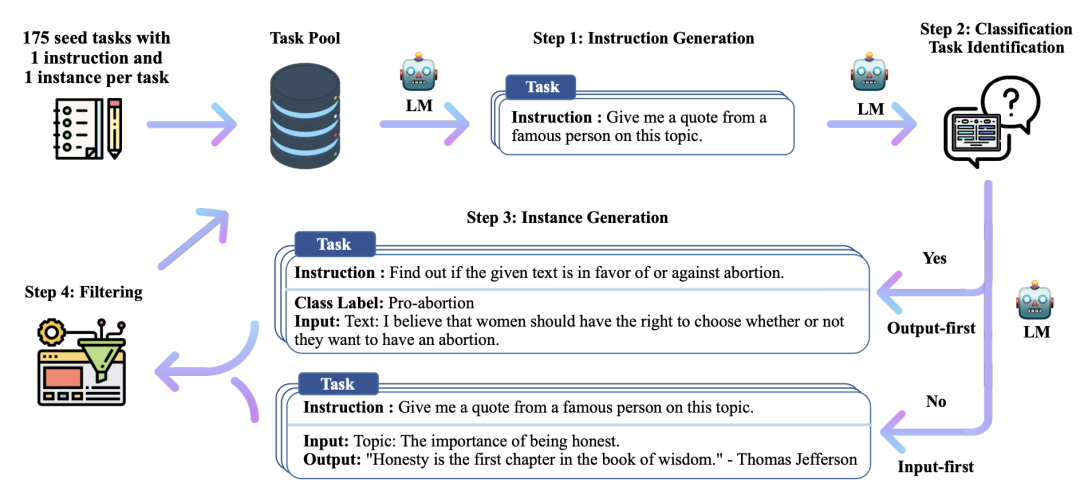
Nemotron-4也采用了类似的做法,分了4个大任务:OpenQA、Writing、Closed QA、Math&Coding。对于每类任务,以多个主题词和关键词作为种子。
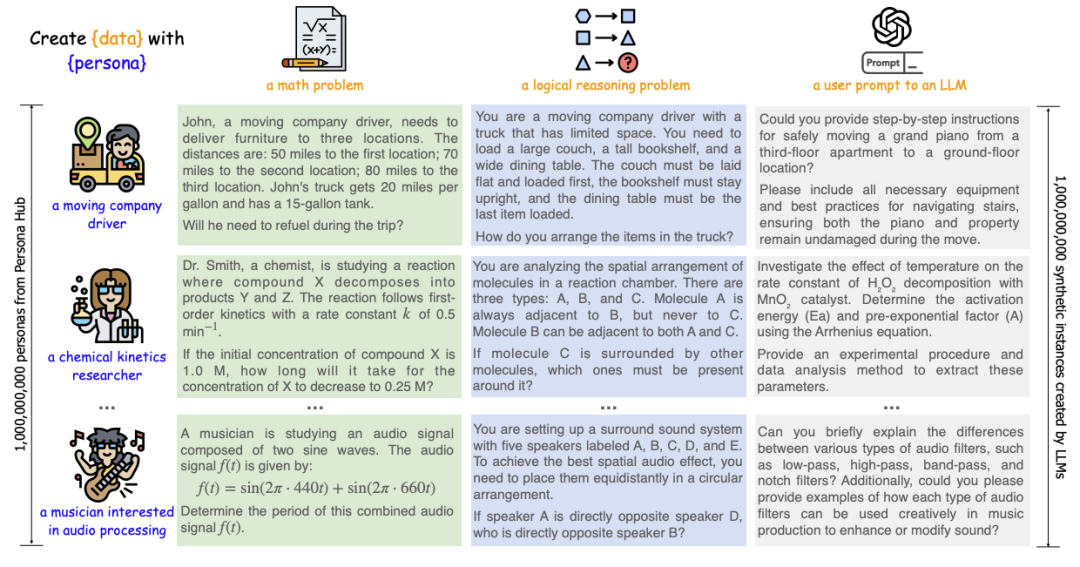
但人工指定 or 统计出的任务仍会有一定局限性,因此更好的方法是让模型生成任务。近期腾讯一篇工作Persona-Hub[5]就非常巧妙,从Web文本中提取出10亿的人物描述,再让模型以不同人物的口吻去生成问题,多样性直接拉满。
还有一种比较tricky的,直接诈出某个对齐后模型的训练数据,比如Magpie[6],只输入前缀USER,让模型自己把问题生成出来:
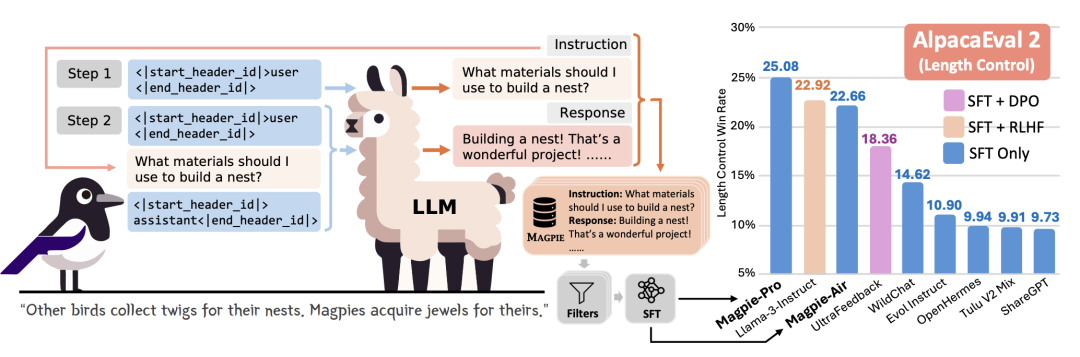
最后,Doc2Query也能生成多样性较高的问题,但有一定局限性,更多用于知识类Query的合成。
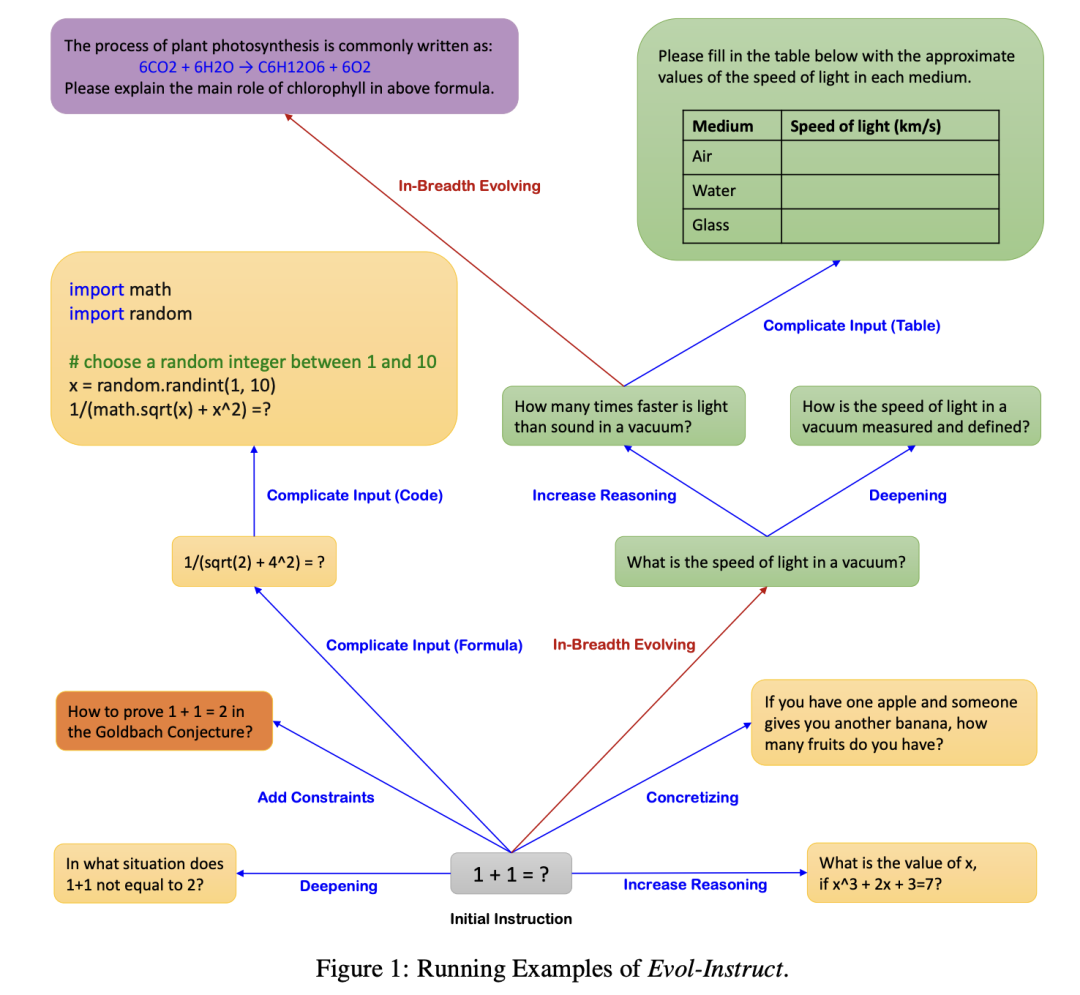
对于复杂度,做法跟多样性差不多,需要定义出多种约束标签,再不断去改写Prompt增加其复杂度。比如很经典的WizardLM[7],定义了几个不同的改写操作:add constraints、deepening、concretizing、increase reasoning steps、 complicate input,让指令的复杂度不断增加。
还有一种方法是量化模型生成结果复杂度,从而训一个能生成复杂Query的模型。例如我们近期在安全领域的工作SEAS[8],就构造了一个对抗攻击的场景:
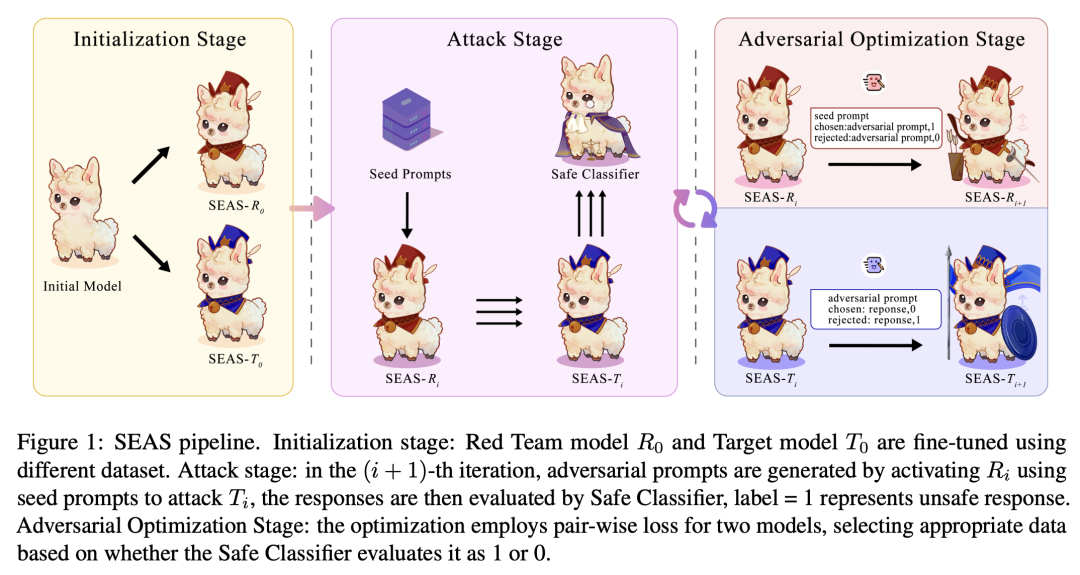
如上图,该框架分为三个阶段:
初始化:用少量的数据,精调一个攻击模型R(负责生成有害问题)和一个目标模型T(最终要被优化安全能力的模型)
攻击阶段:模型R生成多条有害样本,T针对每个问题生成多个答案,利用Llama guard作为打分器,如果攻击成功,则该Query作为模型R的chosen,否则为rejected。如果攻击失败,则该Response作为模型T的chosen,否做为rejected
优化阶段:利用第二步构造的DPO数据迭代模型R和模型T
通过上面的2、3步骤多轮迭代,模型R生成的攻击问题越来越强,模型T的安全能力也随之提升,R对T的攻击成功率如下:
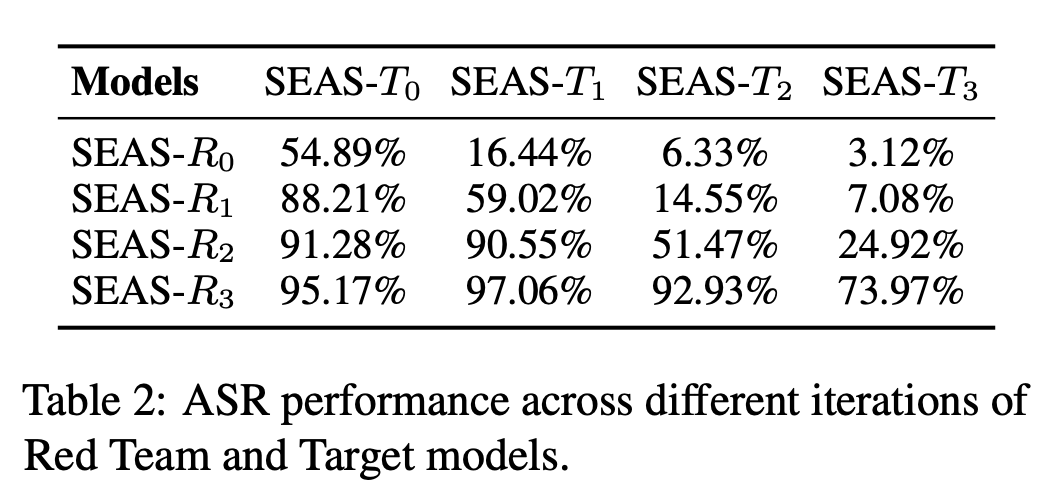
监督信号合成
相比Prompt合成,Pair的合成会更难一些,Prompt即使质量一般,只要用较好的模型生成Response和较强的基座,也能学得还行,但如果Pair不准确,RM/PPO或者DPO直接就学偏了。
最直接的方法就是LLM-as-Judge,用模型打分或排序。Meta今年发表过一篇Self-Rewarding[9]的工作非常赞且优雅:
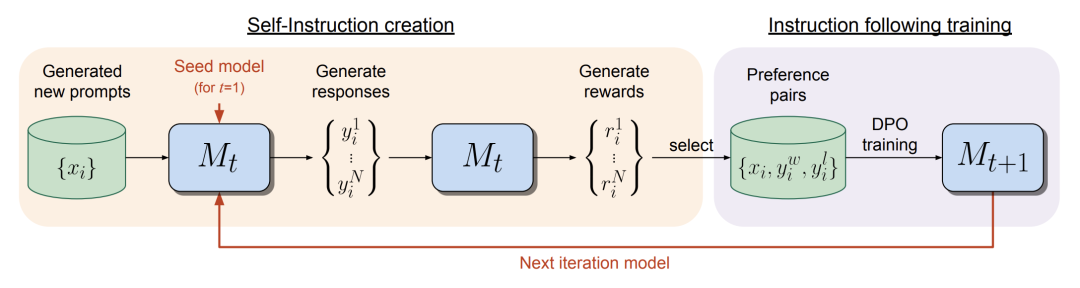
直接用当前模型T生成答案->给自己打分->做成DPO数据训练模型T+1,形成了一个self-play的闭环。在模型生成能力不断提升的同时,判别能力(Pairwise acc)也在提升:
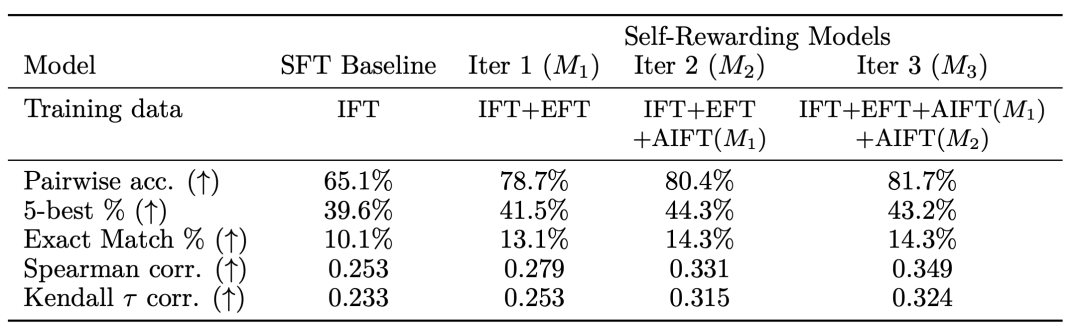
但可以看到后期的acc增长放缓,不知道模型最远能跑多少轮。
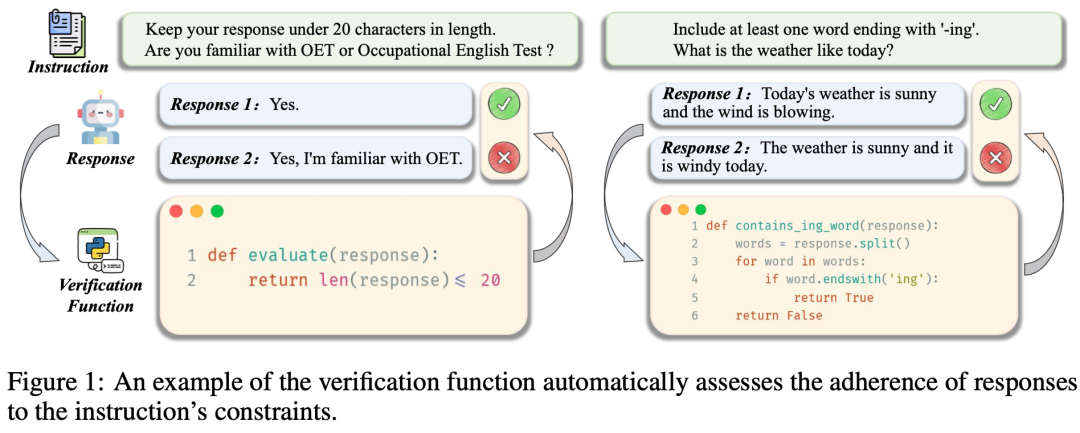
如果担心LLM-as-Judge的准确率不够高,可以使用约束更强的Instruction来提升模型判别的准确率,比如阿里的工作AutoIF[10],就让模型自己写代码来验证结果的正确性:
还有一种方法是想办法让模型做答案固定的任务,接近传统游戏RL,比如腾讯的工作SPAG[11]中,就制定了一个游戏规则:
攻方需要让守方无意识地说出某个词
守方需要推理出攻方的词

在这样的框架下,判断最终结果的难度极大降低,作者也利用这类数据提升了模型的逻辑推理能力。
总结
从上述各方的工作来看,大模型Alignment阶段可以有3个飞轮:
预训练基座驱动:由于weak-to-strong,使用同一份对齐数据的情况下,更强基座可以带来更强的对齐模型
数据驱动:即使基座模型不变,一份数据训出对齐模型后,可以利用数据合成方法生产更好的数据,训出更好的对齐模型
对齐模型驱动:进行Iterative-SFT/RLHF,得到模型T后搭配产生新的数据,再训练出模型T+1,让对齐过程scale up
第1个飞轮比较容易跑通,但2、3叠加起来的飞轮最远能跑到哪里,还挺让人期待的。
参考资料
[1]
Training language models to follow instructions with human feedback: https://arxiv.org/abs/2203.02155
[2]Nemotron-4 340B Technical Report: https://arxiv.org/abs/2406.11704
[3]The Llama 3 Herd of Models: https://arxiv.org/abs/2407.21783
[4]SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions: https://arxiv.org/abs/2212.10560
[5]Scaling Synthetic Data Creation with 1,000,000,000 Personas: https://arxiv.org/pdf/2406.20094
[6]MAGPIE: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing: https://arxiv.org/abs/2406.08464
[7]WizardLM: Empowering Large Language Models to Follow Complex Instructions: https://arxiv.org/abs/2304.12244
[8]SEAS-Self-Evolving Adversarial Safety Optimization for Large Language Models: https://arxiv.org/abs/2408.02632
[9]Self-Rewarding Language Models: https://arxiv.org/abs/2401.10020
[10]Self-play with Execution Feedback: Improving Instruction-following Capabilities of Large Language Models: https://arxiv.org/abs/2406.13542
[11]Self-playing Adversarial Language Game Enhances LLM Reasoning: https://arxiv.org/abs/2404.10642
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









