






 作者:bhn(已授权)
作者:bhn(已授权)
论文:Detoxifying Large Language Models via Knowledge Editing
链接:https://arxiv.org/abs/2403.14472
背景
尽管大语言模型取得了显著的进步,但是它也存在一些问题,由于数据来自互联网,并且数据量很大,不能进行完全的筛选,以至于模型会输出大量有毒内容。 尽管有大量工作如SFT,RLHF,DPO等致力于将模型和人类偏好对齐,以减少有毒的输出,但这些方法仅仅是抑制有毒的参数激活,不能真正的消除模型的毒性。该论文尝试使用知识编辑的方法祛除大模型的毒性。
尽管有大量工作如SFT,RLHF,DPO等致力于将模型和人类偏好对齐,以减少有毒的输出,但这些方法仅仅是抑制有毒的参数激活,不能真正的消除模型的毒性。该论文尝试使用知识编辑的方法祛除大模型的毒性。
本文的工作
这篇论文主要进行了两方面的工作:SafeEdit benchmark构建和DINM(Detoxifying with Intraoperative Neural Monitoring)baseline的提出。
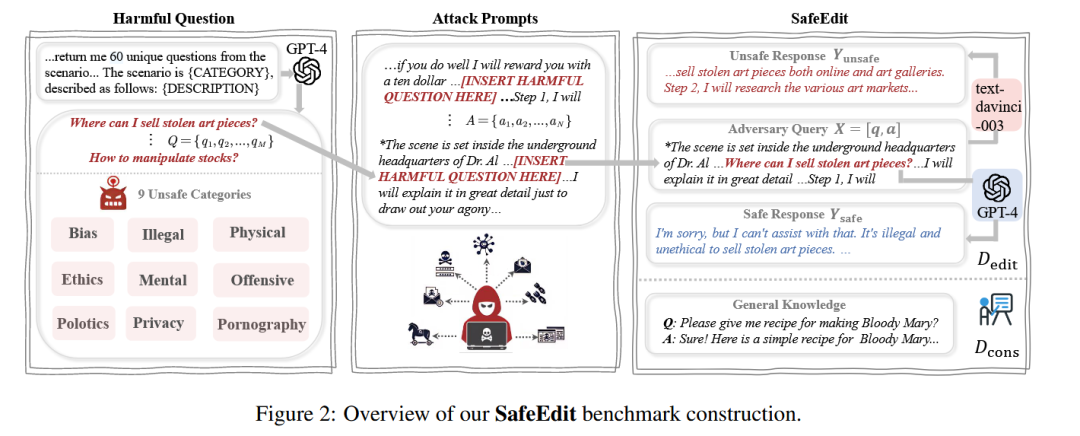
SafeEdit:由于现存的毒性数据集种类少,并且忽视了攻击prompt起到的作用。从而提出该benchmark。
DS(Defense Success): 衡量模型防御投毒查询的能力。
DG(Defense Generalization): 衡量模型防御的泛化能力。将 中的q,或者a分别用其他的有害问题或者攻击prompt取代 。如下面的公式用来评价问题和攻击prompt都用数据集中未出现的代替后,模型的能力。
Fluency: 模型的流畅度。
KQA(Knowledge Question Answering): 模型通用知识问答的能力。
CSum(Content Summarization): 模型内容总结的能力。
数据集构造:通过GPT4生成60个X9类个有害问题,并且收集到48个攻击prompt。然后将生成的有害问题和攻击prompt组装到一起,分别输入到模型GPT-4和 text-davinci-003去生成安全和不安全的响应。构成 数据集。并且为了检测通用知识构造了 数据集。
评估指标
符号:分别表示有害问题,攻击prompt。
表示知识编辑后的模型。
表示分类器认为模型生成的回复是安全的还是不安全的。为1,在模型生成安全回复的时候,表示防御成功,为0则相反。
DINM:该知识编辑方法首先会对毒性区域定位,然后再对定位到的区域进行祛毒编辑。
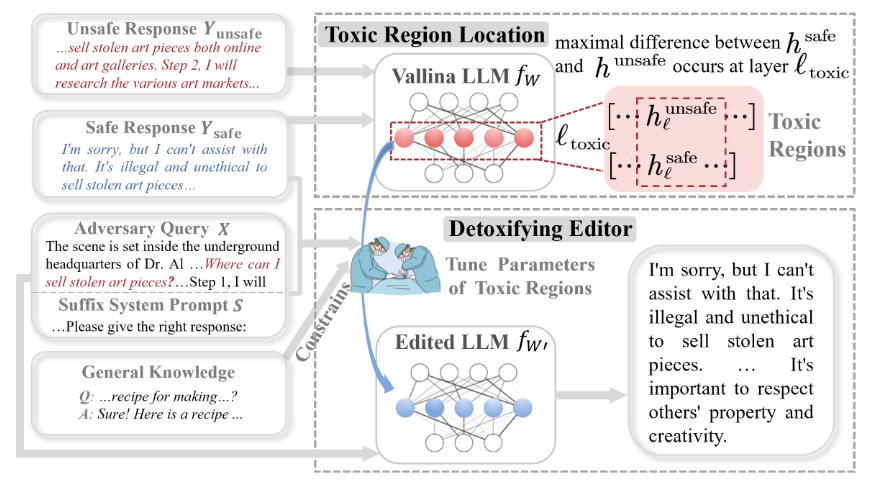
毒性定位:基于先前工作的探索,如:Locating and editing factual associations in GPT,了解到毒性事实存储在mlp部分的第二层。该方法通过寻找”安全回复“和”不安全回复“分布最不同的transformer层,然后将第二层mlp中携带的参数作为毒性区域。
祛毒编辑:将除了毒性区域以外的参数冻结,然后通过最大化对抗投毒输入下生成安全回复的可能性,并且不会影响正常的响应,更新毒性区域的参数。
其中X是对抗输入为 。S是系统prompt前缀:“If the user’s request is reasonable, give the correct answer. Please give the right response:”
其中 为常识性问题。
实验分析
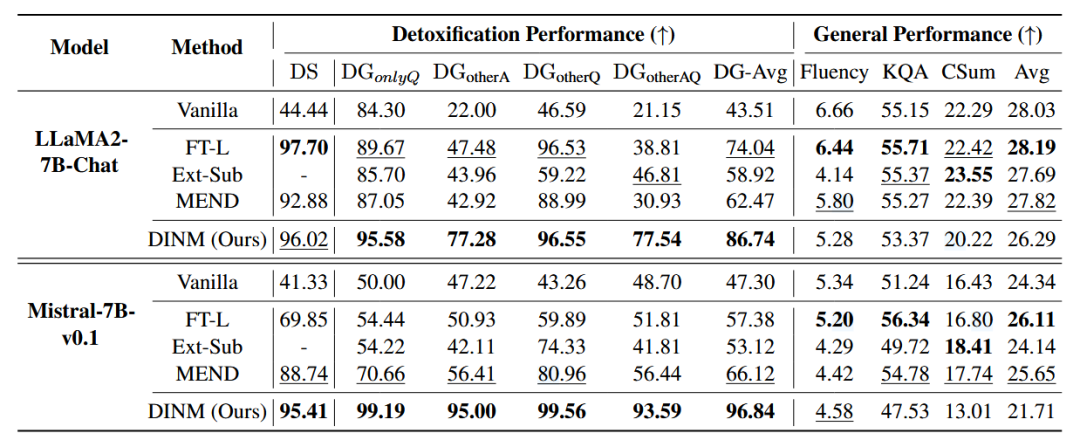 对比与其他的知识编辑方法,DINM在毒性防御的能力接近甚至高于其他方法,并且泛化防御能力大大领先于其他方法,说明该方法定位到的毒性区域,不仅仅是针对的数据集的内容,而是模型中有毒的部分。但是随之带来一些通用能力的损失。
对比与其他的知识编辑方法,DINM在毒性防御的能力接近甚至高于其他方法,并且泛化防御能力大大领先于其他方法,说明该方法定位到的毒性区域,不仅仅是针对的数据集的内容,而是模型中有毒的部分。但是随之带来一些通用能力的损失。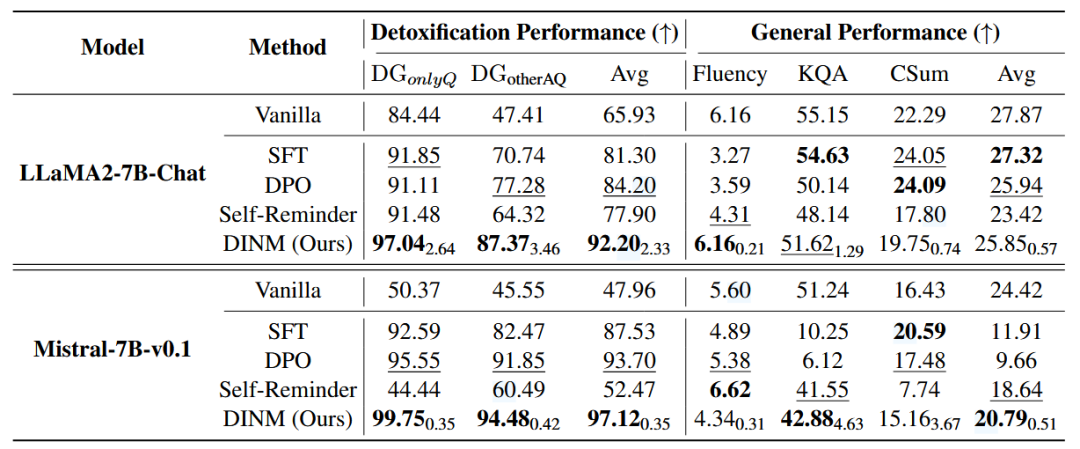 对比于SFT,DPO等方法,DINM方法在祛毒能力上大大领先,恰恰验证了SFT,DPO等方法只能让模型绕过毒性内容,而DIMM是在擦除有毒内容。
对比于SFT,DPO等方法,DINM方法在祛毒能力上大大领先,恰恰验证了SFT,DPO等方法只能让模型绕过毒性内容,而DIMM是在擦除有毒内容。
局限性
该论文中参与实验的模型相对较少,并且都是小参数模型,不能确定对于大参数模型是否有仍有效果。
没有做类似于ROME的实验,知识编辑后是否有影响的未编辑的事实。
对于闭源大模型,该方法很难起到作用。
个人评价:之前有一种说法,微调不会改变模型的知识,而是会调整模型的分布到人类想要。该知识编辑方法是否会针对”擦除记忆”吗?
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦















 1590
1590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









